What is Big Data?
Big data is a combination of structured, semistructured and unstructured data collected by organizations that can be mined for information and used in machine learning projects, predictive modeling and other advanced analytics applications.
Systems that process and store big data have become a common component of data management architectures in organizations, combined with tools that support big data analytics uses.
Why is Big Data important?
- Big data is instrumental for organizations, enabling data-driven decision-making and fostering innovation by uncovering patterns and opportunities in extensive datasets.
- Its role in personalization enhances customer satisfaction, while in healthcare, it advances research and personalized medicine.
- Predictive analytics aids in forecasting, fraud detection, and security.
- Overall, big data's impact spans business efficiency, scientific research, and societal initiatives, making it a cornerstone for progress in various fields.
Types of Big Data
So much discussion on What is Big Data, but now it’s time to understand the types of big data.
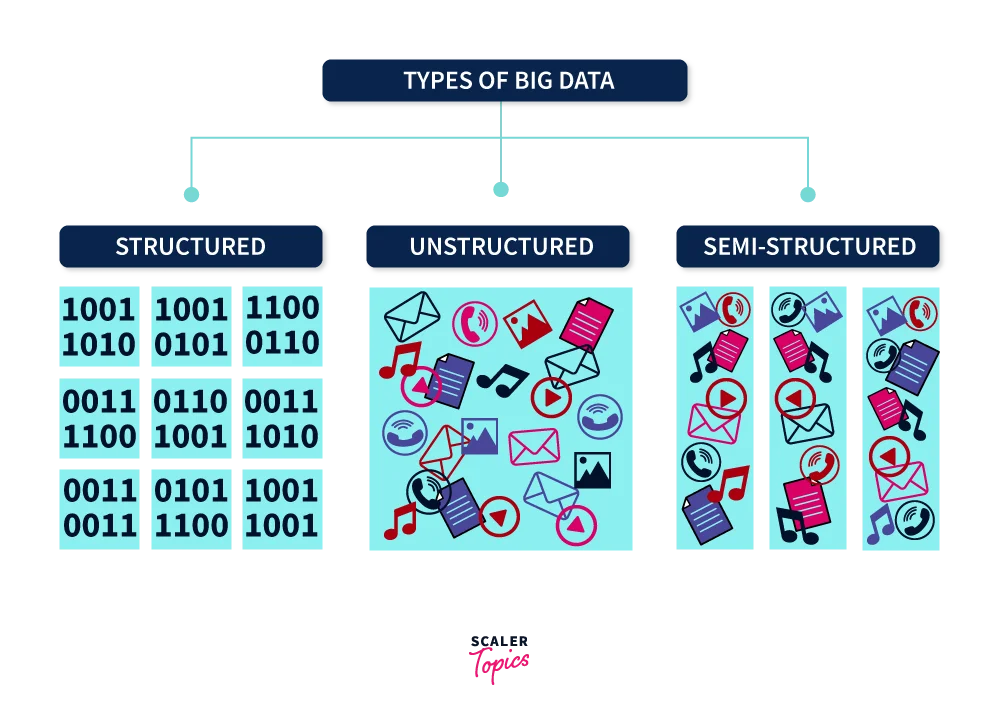
Structured Data
When the data is processed, stored, and retrieved in the desired format, and can be stored in relational databases, which makes it easier to analyze. Names, dates, addresses, credit card numbers, and other structured data are examples.
Unstructured Data
Unstructured data is information that lacks a specific format and is stored in original form without any presets. It’s demanding and time-consuming to process and analyze unstructured data. Rich media like Data from the media, entertainment industries, and surveillance data are examples of unstructured data.
Semi-Structured Data
When the data is not segregated properly but yet contains some vital information. Email, NoSQL databases, and other semi-structured data are examples.
The Six V’s of Big Data
Some say there are 3V’s and some say 5V’s but as per my knowledge, there are 6 V’s. So, what are these 6V’s? We can model the entire Big Data into 6V’s for better understanding. These are Veracity, Value, Variety, Volume, Velocity, and Variability. So, let’s discuss them one by one.

Volume
Volume is a huge set of data that may or may not be in our desired format and may need further processing to extract valuable information. An example of a high volume of data can be daily transactions through Online payment services like UPI, credit cards, etc.
Velocity
Velocity is the rate of growth of data. Since big data is rapidly changing or keeps getting updated in data storage, we need to process structured and unstructured data and keep updating our data stores to take advantage of the information. Social media posts are an example of data generated at a high Velocity.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Variety
It refers to whether the data is structured semi-structured or unstructured. Which we talked about earlier. A variety of data can be anything from email, phone number, XML file, audio, videos, etc.
Veracity
It is the quality, validity, and trustworthiness of the data. Suppose you are willing to go to a restaurant, you search on Google to find out which one will be best suited for you. However, due to excess unstructured data from all the sources, you end up getting confused. Here comes the use of hashtags which helps you to sleek down your interest, and along with suggestions, you also get the images of that place that have been shared by other customers thereby, building a sense of trust in you that other people liked it too. This is how veracity can be justified through this example and helps us understand its importance in explaining big data.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Value
It is the most important V of big data, which can be defined as the ability to transform the data into business. So, to better grasp it, let’s look at an example. If data lacks Value, we will not be able to use it in other Vs to solve problems associated with a specific hypothesis and thus won’t transform it for successful business activities.
Variability
It refers to data whose meaning changes over time. Organizations frequently need to create complex systems to comprehend context and decode the exact meaning of raw data. Let us understand this change through a real life example. Let’s understand this change through a real-life example. Every hostel student might relate to it. Suppose every week Mess serves paneer. Although that paneer does not taste good every week there is a change in taste. This change is variable, why does the taste change? Because on someday the chef pours extra spices and on other days he does not. The same is true for data, which might have an impact on the quality of your data if it is constantly changing.
The Value—and Truth—of Big Data
Two more Vs have emerged over the past few years: value and veracity. Data has intrinsic value. But it’s of no use until that value is discovered. Equally important: How truthful is your data—and how much can you rely on it?
Today, big data has become capital. Think of some of the world’s biggest tech companies. A large part of the value they offer comes from their data, which they’re constantly analyzing to produce more efficiency and develop new products.
Recent technological breakthroughs have exponentially reduced the cost of data storage and compute, making it easier and less expensive to store more data than ever before. With an increased volume of big data now cheaper and more accessible, you can make more accurate and precise business decisions.
Finding value in big data isn’t only about analyzing it (which is a whole other benefit). It’s an entire discovery process that requires insightful analysts, business users, and executives who ask the right questions, recognize patterns, make informed assumptions, and predict behavior.
History of Big Data
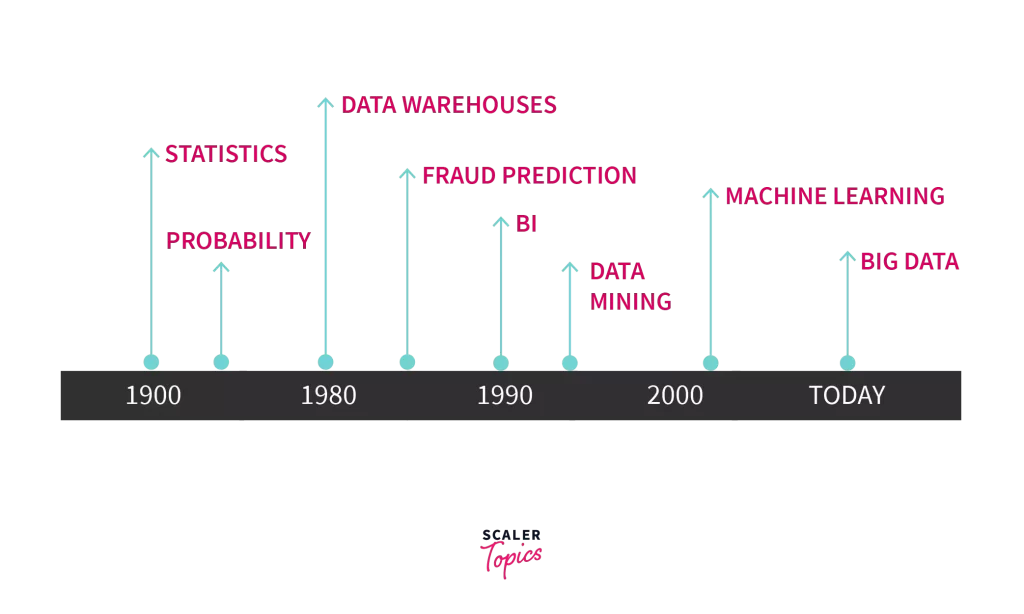
The word Big Data was coined in 1987 by John Mashey, but its roots are quite old. Ideally, if we talk about data, it dates back to the age when humans were discovered by fire or even before that because ideally, the meaning of data is storing information. It doesn’t need to be stored in a SQL or no-SQL database. Our mind is quite capable of storing information. But let’s not deviate from our topic of discussion which is “Big Data”.
Early traces of Big Data dates back to the 17th Century when John Graunt was studying the tremendous amount of data related to a disease called Bubonic Plague. But, if we technically speak in terms of technology it was 1990 during the initial days of the internet when the study of large volumes of data was started by big organizations.
How Big Data Works?
To know how big data works, let’s understand the definition once again. Big data is a large volume of data that is analyzed for better understanding. So, what is this understanding? Understanding is the result we get after the choice of decisions we make. So, the working of Big Data can be summarized in three words i.e. Big Data, Analytics, and Decisions.
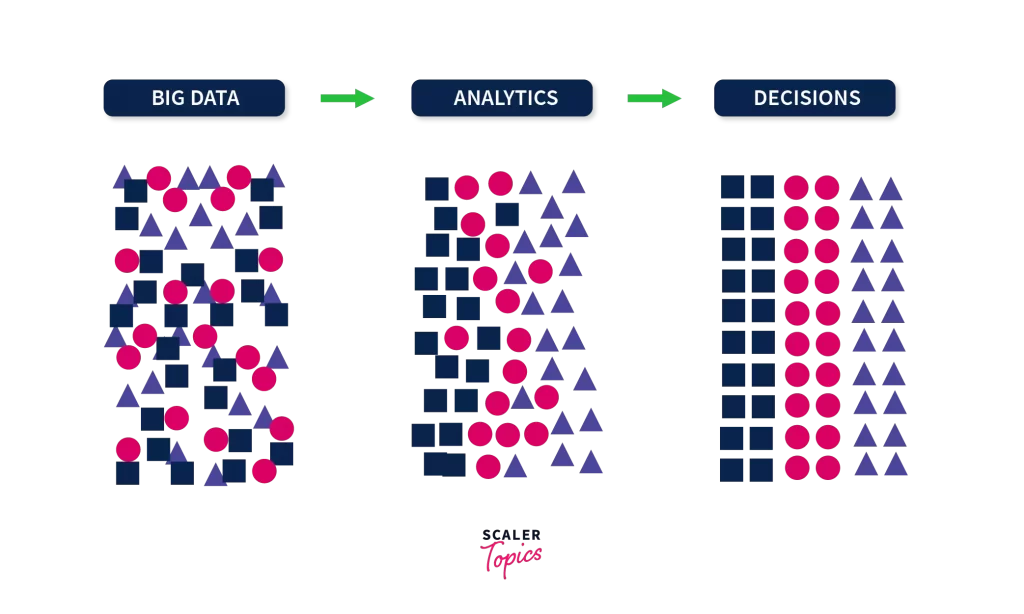
Since we know that our end goal is to analyze data and reach a decision. So, to do that there are 3 main actions so that we reach our end goal.
Integration
collected data from a variety of sources, such as Datasets. As a result, integrating that raw data will be demanding. What we do is process the data and format it correctly. Which algorithms are available to us? What kind of data is available?
Management
Storing the data is the next step. It can be done either by storing in large server rooms or the cloud.
Analysis
After the data is formatted in our desired form and then stored somewhere safe. Yeah, that decision will help us put that data to work. We start to analyze it using the required tools and reach a decision. Few most popular tool for Big-data analysis is Hadoop, Spark followed by many others. Yeah, that decision will help us put that data to work.
Big Data Use Cases
Big Data is used in different industries and domains. Let’s understand with a few example use cases.
Recommendation Engines
While watching the usual Netflix and Prime. These streaming services tend to show us a few shows under “recommended for you”. So, this recommendation system works with the help of big data where large amounts of structured and unstructured data can be gathered just from a few clicks and this information helps companies predict the recommendations for the user.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Financial Fraud Detection
With the use of Big Data and machine learning algorithms, Even if there are any subtle changes in consumer purchase or credit card activity, they can be automatically analyzed and can be marked for fraud because of this each year these financial institutes millions of dollars in fraud. Even in the Insurance sector because of big data billions of dollars are saved each year as claims can be analyzed and a similar machine learning model then detects the potential fraud.
Turn Learning into Career Growth
Health Care Sector
Doctors, Researchers, and health care companies are rapidly adopting big data solutions to solve different problems. Researchers and doctors can conduct more effective research for some of the noncurable diseases like HIV, Cancer, and Alzheimer's and can develop more effective drugs by analyzing the pattern. Even hospitals are adapting to big data solutions to do customized ways of testing as opposed to trivial ways of testing and in some countries, big data helps in faster and more efficient analysis of healthcare information.
Agriculture and Food Industries
Big data is used to improve the quality and quantity of crops by using geospatial data, graphical data, seismic activities, etc. Due to the growing population, improving the quantity of food has been a priority in the last thirty years. Due to big data, the fight against global hunger has been made possible.
There are many other use cases but to get a basic gist of how useful big data is in the 21st century this must be enough.
Big Data Challenges
Many organizations are still stuck at the initial stage of implementing big data into their organization. Let’s try to understand the issues of these challenges.
Incomplete Understanding of Big Data
Sometimes organizations are unable to understand what is data. Why is it so important? because of this integration of required algorithms to analyze the data becomes really difficult. The solution to this problem is to educate the employees regarding “big data”.
Exponential Data Growth
90 percent of the data was created in the last 2-3 years. One of the biggest challenges is the exponential growth of data as time goes on. Since most of the data is unstructured and comes in the form of the document, videos, etc. Which is difficult to analyze. Since data is growing exponentially, it’s becoming difficult to store this data.
Security of Data
Companies spend so many resources for understanding, storing, and analyzing the data they often forget to prioritize the security part. So, they try to push the security part for the later stages because of which data breach is possible. A solution for these companies is hiring cybersecurity professionals to protect their data.
Data Integration
Since data can be in any form from structured data like phone numbers to unstructured data like videos. So, integrating these data is difficult, but at the same time, data integration is crucial for processes like analysis, reporting, and forecasting. So integration has to be error-free. Companies can solve these problems by purchasing the right technologies like IBM InfoSphere, Microsoft SQL, etc.
There may be other challenges faced while implementing big data but these key challenges are really important to overcome for better analysis of data.
Big Data Best Practises
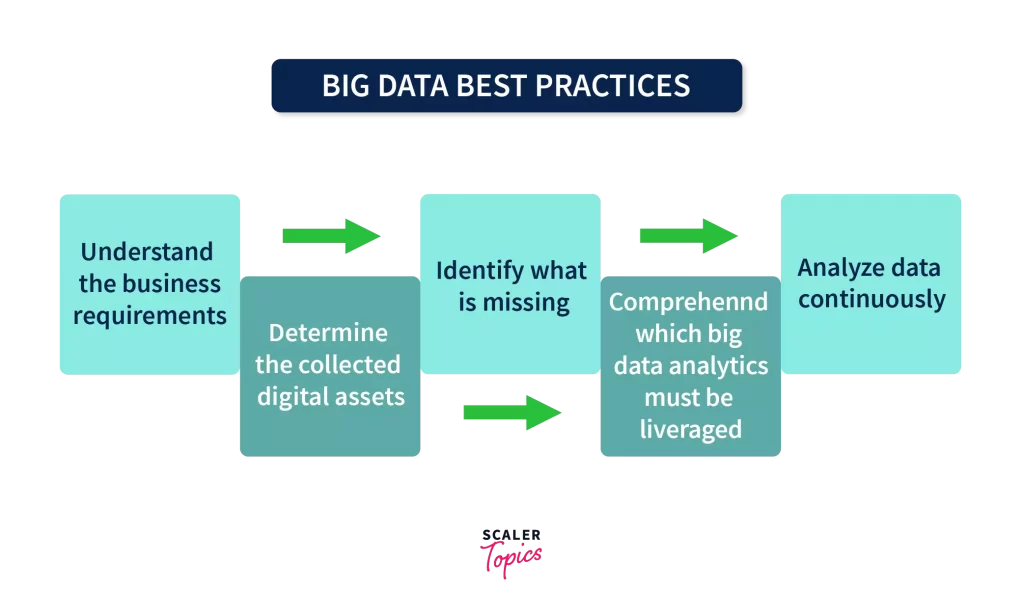
Since now we have a basic understanding of big data, let’s talk about the best practices of Big Data.
Establishing a Plan
Setting up a sense of direction for our goals and objectives.Since, According to that plan we tend to start working on the big data solution. This plan needs to start from the very foundation so that we can reach our objective. Consider this scenario: you’re a Big-data engineer, and your employer wants to develop a Netflix-style recommendation system. As a result, you won’t be able to meet all of the requirements at once. You must begin with the foundation and then establish a few benchmarks with deadlines, which you must meet to complete the project.
Learn about Your Data
Companies tend to have an ocean full of data but the problem is they need to understand their data and they’re objective to analyze that data. With that analysis, they can work on their goal. So, a Proper understanding of data will help organizations save time and resources.
Learn about the Missing Data
In the second point, we talked about the need to understand the data we have. But now let’s try to know about the data that we don’t have. In certain of the objectives, we may require more information that we may not have at the time. For that missing information, we may look into the data of past solutions. From the data gathered from the past, we can leverage its use in the future by creating different datasets.
Which Data Needs to Be Used?
After collecting and analyzing the data, we need to use technologies and tools to understand our analysis. This analysis is done based on our objective whether we want to study fraud detection, predictive analytics, etc.
Continuously Lookout for Data
The organization must be aware of the data flowing. Analyze the health of the data occasionally so that we don’t miss some vital information. Companies must be informed of the practices happening to extract data and keep their data stores updated.
Conclusion
- Big data is a large and complex collection of data that is difficult to process and analyze using traditional methods.
- It is characterized by the six Vs: volume, velocity, variety, veracity, value and variability.
- Big data can be used to make better decisions, improve products and services, and make new discoveries.
- Big data is significantly reducing the cost of storing, analyzing, and processing large amounts of data.