
An AI agent is an autonomous software system that leverages a large language model as its core reasoning engine to perceive its environment, make decisions, and execute actions using external tools. This AI agents beginner’s guide explores their architecture, frameworks, and practical implementation for software engineers.
What are AI Agents?
The paradigm of artificial intelligence has shifted dramatically from static, stateless request-response mechanisms to dynamic, stateful, and autonomous entities known as AI agents. In traditional large language model (LLM) interactions, the system is purely reactive: a user submits a prompt, and the model generates a corresponding text output based on its pre-trained weights. While powerful, this approach limits the model to a confined, conversational sandbox devoid of agency or the ability to impact the external world.
AI agents fundamentally alter this dynamic by decoupling the reasoning engine from the execution environment. By encapsulating an LLM within an orchestration loop, an AI agent gains the capacity to continuously observe its environment, process contextual data, formulate step-by-step plans, and invoke external Application Programming Interfaces (APIs) to achieve a predefined objective. This transition transforms the LLM from a simple text generator into a robust cognitive engine capable of executing complex software engineering, data analysis, and workflow automation tasks without continuous human intervention.
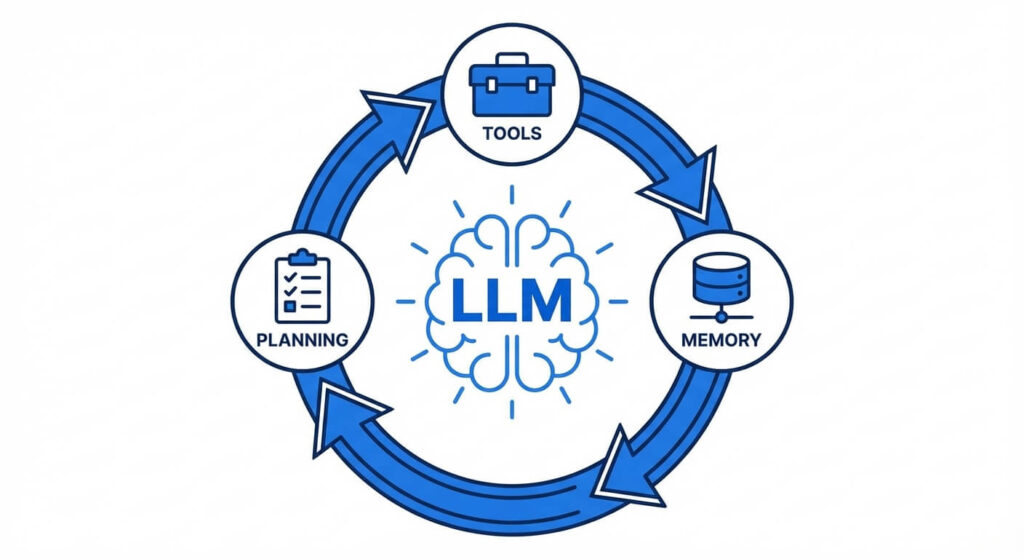
Core Architecture of AI Agents
Understanding how to engineer an AI agent requires deconstructing its internal architecture. A robust agentic system is composed of four primary pillars: the reasoning engine, the memory system, the planning module, and the tool execution environment.
1. The Reasoning Engine (The “Brain”)
At the center of any agentic system is the Large Language Model (e.g., GPT-4, Claude 3, Llama 3). In an agent architecture, the LLM is not used merely for generating human-readable text. Instead, it is heavily instruction-tuned to evaluate states, parse JSON, execute logical deductions, and determine the next optimal step in a sequence. The reasoning engine processes the input state and outputs an instruction format that the underlying execution script can parse and execute.
2. The Planning Module
Autonomous agents must solve multi-step problems. The planning module facilitates task decomposition—breaking a complex, overarching objective down into smaller, manageable sub-tasks. Modern agents utilize paradigms like ReAct (Reasoning and Acting) or Chain-of-Thought (CoT) prompting to articulate their logic step-by-step before invoking a tool. This self-reflection mechanism allows the agent to correct its own errors. For example, if an API call returns a 404 error, the planning module observes this failure, re-evaluates the parameters, and formulates a new request.
3. Memory Systems
Standard LLMs are inherently stateless. To function autonomously over prolonged periods, agents require sophisticated memory architectures:
- Short-Term Memory: This relies on the model’s context window. It maintains the immediate history of the current interaction loop (the sequence of thoughts, actions, and observations).
- Long-Term Memory: To persist information across multiple sessions, agents utilize external vector databases (such as Pinecone, Milvus, or pgvector). Textual data is converted into high-dimensional numerical vectors (embeddings). When the agent needs historical context, it performs a mathematical nearest-neighbor search—typically calculating the cosine similarity, represented as sim(A, B) = (A · B) / (|A| |B|) —to retrieve the most relevant past experiences.
4. Tools and Actuators
Tools are the functions that allow the agent to manipulate its environment. These can range from simple Python functions and shell execution scripts to complex integrations with REST APIs, SQL databases, and web scraping utilities. The LLM is provided with the schemas of these tools (often using OpenAPI specifications) and uses its reasoning capabilities to pass the correct arguments to these functions based on the current objective.
Generative AI Agents vs. Traditional Automation

Software engineers often confuse modern generative AI agents with traditional Robotic Process Automation (RPA) or standard rules-based automation pipelines. While both aim to reduce human intervention, their underlying architectures and capabilities are vastly different.
Traditional automation operates on deterministic, strictly defined rulesets (if/else logic) and requires highly structured data. Conversely, generative AI agents are non-deterministic, capable of handling unstructured data, and possess the semantic understanding required to navigate ambiguous scenarios dynamically.
| Feature / Attribute | Traditional Automation (RPA) | Generative AI Agents |
|---|---|---|
| Core Logic | Deterministic rules, predefined state machines, and rigid if/else statements. | Probabilistic reasoning, dynamic task planning, and semantic understanding via LLMs. |
| Input Data | Requires strictly structured inputs (e.g., formatted CSVs, strict JSON schemas). | Easily parses unstructured inputs (e.g., natural language emails, raw HTML, PDFs). |
| Error Handling | Fails immediately upon encountering an unexpected exception or edge case. | Capable of self-reflection, analyzing error tracebacks, and dynamically adjusting API parameters. |
| Adaptability | Zero adaptability. Workflows break if UI elements or API endpoints change slightly. | High adaptability. Can read new documentation on the fly and adjust to varying data formats. |
| Development Overhead | High initial setup for mapping exact workflows; high maintenance burden when systems change. | Requires careful prompt engineering and tool binding, but handles operational variances natively. |
Key Concepts Behind Agentic AI
To truly master the development of AI agents, engineers must understand the foundational prompt engineering techniques and system architectures that allow an LLM to behave agentically.
The ReAct Framework
The ReAct (Reasoning and Acting) framework is arguably the most critical paradigm in agent development. Introduced by researchers, ReAct interleaves reasoning traces with task-specific actions. Instead of simply predicting the final answer, the agent generates a sequence structured strictly as:
- Thought: The agent explains what it needs to do.
- Action: The agent specifies a tool to use and the input variables.
- Observation: The system executes the tool and returns the raw output to the agent.
This loop repeats continuously until the agent’s “Thought” determines that the final objective has been successfully met, at which point it executes a final “Finish” action.
Function Calling and Tool Binding
Modern LLMs, specifically those fine-tuned for agentic workflows, are trained on datasets containing API schemas. Function calling is the technical mechanism by which you provide an LLM with a JSON schema defining available tools (including function names, descriptions, and required parameter types). The LLM does not execute the code itself; rather, it outputs a highly structured JSON object dictating which function to call and what arguments to pass. The application layer (your Python or Node.js backend) parses this JSON, executes the local code, and feeds the return value back to the LLM.
Multi-Agent Orchestration
As objectives become more complex, relying on a single omnipotent agent becomes highly inefficient and prone to context-window degradation. Multi-agent systems solve this by instantiating several specialized agents, each with a specific persona, toolset, and system prompt. For instance, a software development workflow might include:
- A Product Manager Agent that breaks down user requirements.
- A Software Engineer Agent that writes the code.
- A QA Agent that writes tests and flags compilation errors. These agents communicate through a shared state or message queue, evaluating each other’s outputs until the final product meets the defined criteria.
Tools and Frameworks for Agentic AI Development
The open-source ecosystem has exploded with frameworks designed to abstract the complex orchestration logic required to build generative AI agents. Selecting the right framework depends heavily on your specific use case, ranging from simple data retrieval tasks to complex, autonomous multi-agent hierarchies.
1. LangChain and LangGraph
LangChain is the foundational framework for building LLM applications. It provides standardized interfaces for memory, tools, and vector stores. However, traditional LangChain agents rely on legacy AgentExecutor classes that can be difficult to debug. To solve this, the ecosystem introduced LangGraph. LangGraph treats agent workflows as stateful, Directed Acyclic Graphs (DAGs) or cyclic graphs. By defining nodes (functions/agents) and edges (conditional routing logic), engineers gain granular control over the agent’s execution loop, allowing for human-in-the-loop approvals and explicit infinite-loop prevention.
2. Microsoft AutoGen
Developed by Microsoft Research, AutoGen is a framework built explicitly for multi-agent conversations. It allows developers to define multiple “conversable agents” that can chat with one another to solve tasks. AutoGen natively supports code execution within Docker containers, making it exceptionally powerful for autonomous software engineering tasks. Its architecture relies heavily on message-passing, where agents parse incoming messages, execute local logic or LLM queries, and broadcast the results to the next agent in the topology.
3. CrewAI
CrewAI is a higher-level framework built on top of LangChain. It abstracts away the complex graph-routing logic of LangGraph and the raw message-passing of AutoGen, allowing developers to define workflows using a human-like organizational structure. In CrewAI, you define “Agents” (with roles and backstories), “Tasks” (specific objectives), and “Crews” (the overarching team). It is highly optimized for production environments where agents need to collaborate sequentially or hierarchically to achieve a business outcome.
4. LlamaIndex
While heavily associated with Retrieval-Augmented Generation (RAG), LlamaIndex has evolved into a formidable agentic framework. Its strength lies in “Data Agents”—agents specifically optimized to traverse, query, and synthesize massive amounts of enterprise data. LlamaIndex provides advanced query engines that function as tools, allowing an agent to dynamically decide whether to run a SQL query, perform a vector search, or scan a knowledge graph based on the user’s prompt.
How to Build Your First AI Agent: Step-by-Step Guide
To solidify these concepts, we will construct a rudimentary AI agent using Python, LangChain, and the OpenAI API. This agent will possess a simple set of tools—specifically, a mathematical calculation tool—and utilize the ReAct framework to solve a problem it otherwise could not solve using its base weights alone.
Prerequisites and Setup
First, ensure you have a modern Python environment configured. You will need to install the core LangChain libraries and the OpenAI integration package. Store your OpenAI API key in a .env file to ensure secure access.
pip install langchain langchain-openai python-dotenv
Step 1: Define the Tools
Tools are standard Python functions decorated to expose their signature and docstring to the LLM. The docstring is critical; the LLM uses this text to understand exactly when and how to use the tool.
import os
from dotenv import load_dotenv
from langchain.tools import tool
load_dotenv()
@tool
def calculate_multiply(a: float, b: float) -> float:
"""Useful for multiplying two numbers together.
Input should be two floats."""
return a * b
@tool
def calculate_add(a: float, b: float) -> float:
"""Useful for adding two numbers together.
Input should be two floats."""
return a + b
tools = [calculate_multiply, calculate_add]
Step 2: Initialize the LLM and Bind Tools
We instantiate the LLM and bind our tool schema to it. Binding tools ensures the model formats its outputs correctly when it decides a tool invocation is necessary.
from langchain_openai import ChatOpenAI
# Initialize the reasoning engine (LLM)
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0)
# Bind the tools to the LLM
llm_with_tools = llm.bind_tools(tools)
Step 3: Construct the Agent Framework
Using LangChain’s pre-built abstractions, we can quickly assemble the agent. We will pull a standard system prompt designed for tool-calling agents from the LangChain prompt hub.
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_core.prompts import ChatPromptTemplate
# Define the system prompt instructions
prompt = ChatPromptTemplate.from_messages([
("system", "You are a helpful mathematical assistant. You must use the provided tools to calculate answers accurately. Never do math in your head."),
("human", "{input}"),
("placeholder", "{agent_scratchpad}"),
])
# Create the agent logic
agent = create_tool_calling_agent(llm, tools, prompt)
# Initialize the Executor (The While Loop that runs the ReAct paradigm)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
Step 4: Execute the Agentic Workflow
When we pass a complex query to the agent executor, it will analyze the request, realize it needs to perform addition and multiplication, invoke the local Python functions sequentially, and formulate a final response.
query = "If I have 15 apples and buy 23 more, and then I multiply my total by 4, how many apples do I have?"
response = agent_executor.invoke({"input": query})
print("Final Answer:", response["output"])
When this code executes, the verbose output will reveal the agent’s internal reasoning. It will first call calculate_add(15, 23), observe the result (38), and then call calculate_multiply(38, 4), observing the final result (152) before returning the human-readable answer.
Evaluating the Cost of Building an Agentic AI System
Deploying an AI agents beginner’s guide into production requires a strict understanding of token economics. Unlike standard LLM implementations where one prompt equals one completion, agentic architectures are iterative. A single user request may trigger a cascade of internal reasoning loops, tool invocations, and memory retrievals.
Token Consumption Multipliers
In a standard RAG pipeline, a user prompt and retrieved context might consume 1,500 input tokens and generate 300 output tokens. In an agentic pipeline relying on the ReAct framework, the context window grows continuously with every step.
- Step 1: System Prompt + User Query + Tool Schemas (Input: 1,000 tokens) -> Thought + Action (Output: 100 tokens).
- Step 2: System Prompt + User Query + Tool Schemas + Step 1 Output + Tool Observation (Input: 1,300 tokens) -> Thought + Action (Output: 100 tokens).
- Step 3: Cumulative History + New Observation (Input: 1,600 tokens) -> Final Answer (Output: 200 tokens).
Because the agent must ingest the entire “scratchpad” (the history of its thoughts and observations) at every step, input token consumption scales quadratically with the number of steps required to complete the task. Engineers must implement strict safeguards, such as max_iterations, to prevent rogue agents from draining API budgets in infinite loops.
Infrastructure and Hosting Costs
Beyond API costs paid to foundational model providers (OpenAI, Anthropic), the infrastructure supporting the agent carries significant weight. Memory architectures demand high-performance Vector Databases. While open-source solutions like ChromaDB run locally, enterprise deployments require managed services like Pinecone or Qdrant, which charge based on index size and read/write operations. Furthermore, executing untrusted code generated by agents (especially in software engineering use cases) necessitates sandboxed environments, adding the cost of dynamic Docker container provisioning and ephemeral compute resources.
Real-World Use Cases of Agentic AI Solutions
The theoretical power of generative AI agents is currently being translated into massive enterprise value across diverse engineering and operational domains. Their ability to autonomously navigate complex environments is disrupting traditional software paradigms.
1. Autonomous Software Engineering
AI agents are rapidly becoming integral to the DevOps and Software Development Life Cycle (SDLC). Systems like SWE-agent and Devin are capable of autonomously resolving GitHub issues. Given a repository and an issue description, the agent clones the code, navigates the file structure using a sandboxed bash terminal, reads the relevant files, writes the patch, runs the test suite, evaluates compilation errors, refactors its code based on those errors, and ultimately submits a pull request.
2. Cybersecurity and Automated Threat Hunting
In Security Operations Centers (SOCs), agents are deployed to triage security alerts. When a SIEM (Security Information and Event Management) system flags anomalous network behavior, an AI agent can autonomously query server logs, reverse-engineer suspicious executable payloads in a secure sandbox, cross-reference threat intelligence databases, and write a comprehensive incident report. This drastically reduces the Mean Time to Respond (MTTR) for security engineers.
3. Dynamic Data Engineering and Analytics
Data analysts traditionally spend hours writing boilerplate SQL and Python pandas code to extract insights. Data agents streamline this process. Connected directly to a read-only replica of a data warehouse, an agent can accept a natural language query such as, “Determine the root cause of our Q3 revenue dip in the European market.” The agent autonomously discovers the correct database schema, writes and executes the SQL query, retrieves the data, analyzes it for statistical anomalies, generates Python code to plot the data via Matplotlib, and delivers a finalized analytical report.
The Future of Agentic AI
As the ecosystem matures, the trajectory of agentic AI points firmly toward Artificial General Intelligence (AGI) precursors. The current generation of agents, while powerful, is highly fragile; they suffer from compounding errors where a single hallucination early in the reasoning chain derails the entire execution.
The future will likely be dominated by improvements in two key areas: Model fine-tuning and hierarchical architectures. Foundation models are increasingly being trained explicitly for agentic capabilities—specifically, function calling, JSON parsing, and self-correction—rather than simple conversational text.

Furthermore, we will see the rise of asynchronous, edge-deployed multi-agent systems. Instead of relying entirely on massive cloud-based LLMs, smaller, highly quantized open-source models (like Llama 3 8B) deployed directly on local hardware will handle rapid, specialized agent tasks. These edge agents will coordinate with “manager” models in the cloud only when high-level cognitive planning or complex data synthesis is required. The orchestration of these agents will mirror human organizational structures, creating digital workforces that dynamically scale compute resources to solve problems in real-time.
Frequently Asked Questions (FAQ)
What is the difference between an AI Agent and a RAG pipeline?
A Retrieval-Augmented Generation (RAG) pipeline is a linear, read-only process where a system retrieves relevant documents from a database and provides them to an LLM to generate an informed answer. An AI agent, however, is cyclical and capable of writing/acting. An agent can utilize RAG as just one of many tools, actively deciding if, when, and how to search for information before taking further actions like sending an email or executing code.
How do you prevent AI agents from getting stuck in infinite loops?
Infinite loops occur when an agent repeatedly uses a tool incorrectly, receives the same error, and fails to adjust its strategy. Engineers mitigate this by implementing a hard max_iterations limit (e.g., terminating the run after 5 steps). Additionally, injecting explicit system prompt instructions like, “If a tool fails twice with the same error, you must stop and report the failure,” helps the agent self-correct.
Can generative AI agents execute malicious code?
Yes, if an agent is granted access to an unconstrained bash terminal or Python REPL, it can inadvertently (or maliciously, if prompt-injected) execute destructive commands (like rm -rf /). Agents must always be deployed in strictly sandboxed environments (e.g., ephemeral Docker containers with limited network access) and operate under the principle of least privilege regarding API keys and database permissions.
Are there open-source models capable of agentic workflows?
Yes. While proprietary models like GPT-4 and Claude 3.5 Sonnet dominate complex agentic tasks due to their massive parameter counts and reasoning depth, open-weight models like Meta’s Llama 3 (70B) and Mistral’s Mixtral 8x22B are highly capable of function calling and multi-agent orchestration when paired with the right system prompts and frameworks.