
What are MCP RAG AI Agents? MCP RAG AI Agents represent the convergence of the Model Context Protocol (MCP), Retrieval-Augmented Generation (RAG), and autonomous AI agents. MCP standardizes how AI agents securely access external RAG databases, eliminating bespoke integrations and enabling seamless, real-time data retrieval for complex reasoning tasks.
The Evolution of AI System Architecture
The transition from monolithic Large Language Models (LLMs) to modular, agentic AI systems represents a fundamental paradigm shift in software engineering. Early LLM deployments relied heavily on the static weights of the model, which inevitably led to knowledge cutoffs, hallucination vulnerabilities, and an inability to interact with live enterprise systems. To mitigate this, developers introduced Retrieval-Augmented Generation (RAG) to provide dynamic context. However, as systems evolved from reactive RAG pipelines into proactive AI Agents capable of multi-step reasoning, the infrastructure connecting these components became increasingly fragmented.
Every new data source, vector database, and enterprise API required bespoke integration code, custom authentication handling, and proprietary tool-calling schemas. This fragmentation created massive technical debt. The introduction of the Model Context Protocol (MCP) by Anthropic established a universal, open standard for AI-to-tool communication. By unifying MCP, RAG, and AI Agents, engineers can now architect highly decoupled, scalable, and secure systems where reasoning engines (Agents) can dynamically discover and query vast knowledge bases (RAG) using a standardized communication layer (MCP).
Demystifying the Core Components
Before analyzing the intersection of these technologies, it is critical to understand the precise mechanics of each component in isolation. A high-performance AI architecture relies on the distinct, non-overlapping responsibilities of RAG, Agents, and the MCP layer.
Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation is a system architecture designed to ground an LLM’s responses in verifiable, external data. Rather than relying solely on the parametric memory stored within a model’s neural network, a RAG pipeline intercepts a user prompt, queries an external datastore for relevant context, and injects that context into the model’s context window.
From a technical perspective, modern RAG implementation relies on dense vector retrieval. Text data is chunked and passed through an embedding model (such as text-embedding-3-small), which maps the semantic meaning of the text into a high-dimensional continuous vector space.
When a query is received, it is embedded into the same vector space. The system then calculates the distance between the query vector and the document vectors. The most common metric used is Cosine Similarity, represented mathematically as:

Cosine Similarity(A, B) = (A · B) / (|A| * |B|)
Where A and B are the vector arrays, A · B is the dot product, and |A| and |B| are the magnitudes of the vectors. The nearest neighbors are retrieved, re-ranked, and passed to the LLM.
AI Agents
An AI Agent is an autonomous or semi-autonomous system where an LLM acts as the central reasoning engine. Unlike standard text-in/text-out LLM queries, an agent utilizes control flow loops—most commonly the ReAct (Reasoning and Acting) framework—to iteratively solve problems.
Agents are defined by their ability to use tools. When presented with a complex objective, the agent will:
- Observe the current state and the user prompt.
- Reason about the necessary steps to achieve the goal.
- Act by selecting a tool from its available tool schema, formatting the required JSON arguments, and pausing its execution to await the tool’s output.
Agents maintain a short-term memory (the current context window) and execute loops until a terminal condition is met. The effectiveness of an agent is strictly bottlenecked by the quality, latency, and reliability of the tools it has access to.
Model Context Protocol (MCP)
The Model Context Protocol (MCP) is an open standard designed to simplify and unify how AI models connect to external data sources and tools. Prior to MCP, if an engineer wanted an agent to access a GitHub repository, a PostgreSQL database, and a Pinecone vector index, they had to write and maintain three distinct API wrappers, manage three different authentication flows, and translate the data into three different LLM-specific tool-calling formats.
MCP operates on a client-server architecture utilizing JSON-RPC 2.0 over standard input/output (stdio) or Server-Sent Events (SSE).
- MCP Servers: Lightweight programs that expose specific capabilities (like querying a vector database).
- MCP Clients: The interface integrated into the AI Agent or LLM application that maintains 1:1 connections with servers.
- The Protocol Layer: Handles the standardized lifecycle of discovering available tools, executing them, and returning resources.
The Synergy: MCP vs RAG vs AI Agents
The framing of “MCP vs RAG vs AI Agents” is a common misconception in industry discourse. They are not competing frameworks; they are complementary layers of a modern AI stack.
When combined, they form a cohesive architecture: The AI Agent provides the logic, RAG provides the memory, and MCP provides the infrastructure to connect them.
| Technology | System Layer | Primary Function | Input / Output |
|---|---|---|---|
| AI Agent | Application / Orchestration | Reasoning, planning, and executing actions based on user intent. | Input: Natural Language / State Output: API calls, final text response |
| RAG | Data / Retrieval | Fetching semantically relevant data to augment the prompt. | Input: Embedded query vector Output: Raw context documents |
| MCP | Network / Protocol | Standardizing the transport layer between the Agent and the RAG/Tools. | Input: Standardized JSON-RPC request Output: Standardized JSON-RPC response |
How MCP Supercharges RAG for AI Agents
Historically, integrating RAG into an AI agent involved tight coupling. The agent’s application code was directly responsible for initializing the vector database client, constructing the dense vector query, handling network retries, and formatting the returned documents. This tightly coupled architecture scaled poorly as enterprise systems grew to include dozens of disparate data sources.
Resolving Infrastructure Headaches
Hosted MCP servers provide a solution to these infrastructure headaches. By encapsulating the entire RAG pipeline within an MCP Server, the complex retrieval logic is abstracted away from the Agent.
When an AI Agent is equipped with an MCP Client, it simply asks the network: “What tools are available?” The MCP Server responds with a standardized schema, for example, a tool named search_enterprise_knowledge_base. The agent does not need to know whether the backend uses Pinecone, Milvus, or pgvector. It simply invokes the tool via MCP with the search parameters, and the MCP Server handles the vectorization, the semantic search, the re-ranking, and returns the strictly formatted text to the agent.
A Standard for AI Connectors
This standardization is revolutionary for deployment. Developers can build an MCP Server for their internal Confluence documents once, and any agent framework—whether it is LangChain, LlamaIndex, or AutoGen—can connect to it seamlessly as long as it supports the MCP standard. This drastically reduces the surface area for bugs and significantly accelerates the deployment of specialized agentic workflows.
Architectural Implementation: Building an MCP-Powered RAG Agent
To thoroughly understand the data flow, we must examine the system architecture of an MCP-powered RAG Agent.
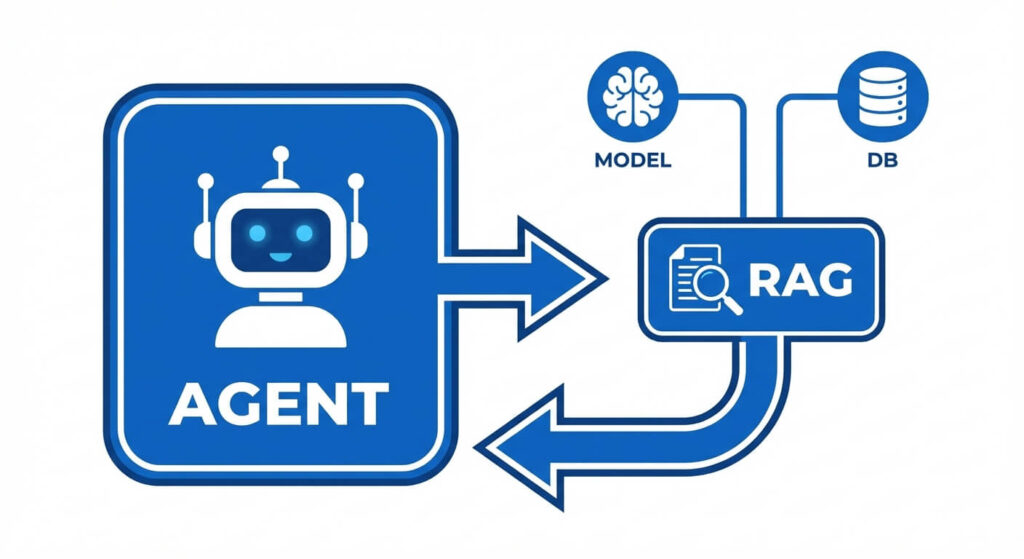
The System Design Data Flow
- Initialization: The AI Agent boots up and initializes its MCP Client.
- Discovery: The MCP Client connects to the configured MCP Servers and sends a
tools/listJSON-RPC request. - Registration: The MCP Server replies with the available RAG capabilities. The Agent registers these capabilities into its LLM’s system prompt (e.g., using OpenAI’s Function Calling format).
- Execution Loop:
- The user prompts the agent with a highly specific technical question.
- The LLM determines it lacks the internal knowledge and halts generation, emitting a tool call for the RAG MCP Server.
- The MCP Client formats a
tools/callrequest and dispatches it. - The MCP Server receives the request, embeds the query, queries the vector database, formats the retrieved documents, and returns a standard MCP response.
- The Agent ingests the new context and generates the final, hallucination-free answer.
Conceptual Implementation
Below is a conceptual Python implementation demonstrating how an MCP Server exposes a RAG pipeline. This illustrates the server-side logic handling the standardized protocol.
from mcp.server import FastMCP
import vector_database_sdk
# Initialize the MCP Server
mcp_server = FastMCP("Enterprise_RAG_Server")
@mcp_server.tool()
def retrieve_internal_docs(query: str, top_k: int = 5) -> str:
"""
RAG Tool to retrieve relevant internal documentation.
The AI Agent will automatically discover this tool and its schema via MCP.
"""
# 1. Embed the textual query into a vector
query_vector = embed_text(query)
# 2. Perform Cosine Similarity search in the Vector DB
results = vector_database_sdk.search(
collection="engineering_docs",
vector=query_vector,
limit=top_k
)
# 3. Format and return context. MCP handles the JSON-RPC wrapping.
context_string = ""
for idx, doc in enumerate(results):
context_string += f"Document {idx+1}:\n{doc.text}\n\n"
return context_string
if __name__ == "__main__":
# Run the server over standard I/O (often used for local agent processes)
mcp_server.run(transport="stdio")
Because the RAG logic is wrapped in the @mcp_server.tool() decorator, any MCP-compliant agent can now leverage this vector search without needing the vector_database_sdk installed in its own environment.
Deployment and Infrastructure Considerations
When deploying MCP RAG AI Agents into production, engineering teams must navigate several critical architectural decisions, particularly concerning how services are hosted, how state is managed, and how access controls are enforced.
Self-Hosted vs. Hosted MCP Servers
Self-Hosted MCP: Running MCP servers alongside the agent process (often communicating via stdio) is highly effective for localized tasks or desktop environments (like Cursor or Claude Desktop). It provides zero network latency and maximum data privacy, as the vectors and documents never leave the local machine or virtual private cloud (VPC).
Hosted MCP Servers: As enterprise AI adoption scales, hosted MCP servers have become the standard. Communicating via SSE (Server-Sent Events) over HTTPS, hosted servers allow multiple disparate agents across different microservices to query the same centralized RAG infrastructure. This eliminates redundant vectorizations and ensures that all agents are retrieving from the most up-to-date embeddings index.
Security and Access Control
Integrating RAG into AI agents via MCP introduces unique security challenges. By abstracting the database behind a universal protocol, developers risk granting an agent overly broad read access to sensitive data.
To mitigate this, robust implementations must utilize Contextual Access Control. The MCP request from the client should carry the user’s identity context. The MCP RAG Server must then apply Role-Based Access Control (RBAC) at the retrieval layer, filtering the vector search results (e.g., using metadata filtering in Pinecone or Qdrant) so that the agent only receives documents the end-user is authorized to view.
Latency Optimization
Agentic workflows are notoriously slow due to multiple LLM inference round-trips. Adding a network hop to an external MCP RAG Server can exacerbate this latency. Engineers should optimize by:
- Caching Embeddings: Implementing an LRU (Least Recently Used) cache for common query embeddings at the MCP Server layer.
- Streaming: Utilizing SSE transport to stream RAG results back to the agent in chunks, allowing the LLM to begin processing early tokens if the agent framework supports streaming tool execution.
Future-Proofing AI Systems: The Road Ahead
The widespread adoption of the Model Context Protocol signifies the end of the “wild west” era of custom AI integrations. As founders and researchers predict the maturation of AI technologies, the differentiation between platforms will no longer be determined by who can write the best API wrapper, but by the quality of the underlying data and the sophistication of the agent’s reasoning capabilities.
By standardizing RAG via MCP, organizations can decouple their data layer from their compute layer. If a newer, faster LLM is released tomorrow, the engineering team simply swaps out the agent’s reasoning engine; the MCP RAG Server and all its valuable enterprise context remain entirely unchanged. This architectural modularity is essential for building resilient, future-proof AI systems.
Frequently Asked Questions (FAQs)

How does an AI Agent handle context window limits when an MCP RAG server returns too much data? If an MCP RAG server returns a massive payload that exceeds the agent’s LLM context window, the agent will typically throw a token limit error. To handle this, the MCP server should implement strict pagination and token-aware truncation. Alternatively, the agent can be programmed to use a multi-step summarization loop, pulling chunks of the RAG data via MCP sequentially rather than in a single request.
Can an MCP server support write operations, or is it exclusively for RAG retrieval? MCP fully supports write operations. While RAG implies retrieval (read-only), an MCP server can expose tools that allow the AI agent to write to databases, commit code, or trigger CI/CD pipelines. This makes MCP the backbone for full-stack autonomous agents, not just localized search bots.
What is the difference between JSON-RPC via stdio and SSE in the context of MCP? stdio (Standard Input/Output) is typically used for local, strictly coupled deployments where the Agent and the MCP server run on the same physical machine or container. SSE (Server-Sent Events) over HTTPS is used for remote, distributed architectures where an Agent hosted in one cloud environment needs to securely communicate with a managed RAG MCP server hosted elsewhere.
Does using MCP introduce performance bottlenecks compared to native RAG integration? The overhead introduced by the MCP JSON-RPC serialization is negligible (typically less than a few milliseconds). In fact, decoupled MCP servers often improve overall system performance, as the RAG workload (embedding generation and vector math) can be offloaded to specialized, GPU-accelerated microservices rather than blocking the main agentic process.