
AI agents are autonomous software systems designed to perceive their environment, process information using artificial intelligence algorithms, and take directed actions to achieve specific goals. Unlike standard large language models that merely generate text, AI agents utilize tools, memory, and reasoning loops to execute multi-step complex tasks independently.
In the rapidly evolving landscape of artificial intelligence, large language models (LLMs) have transitioned from static prompt-response generators into dynamic, action-oriented systems. This evolution has given rise to AI agents—systems capable of orchestrating workflows, executing code, and interacting with external APIs without constant human intervention. For software engineers and computer science professionals, understanding the underlying architecture and orchestration patterns of AI agents is critical for building scalable, autonomous applications.
Overview and Key Features of AI Agents
An AI agent operates fundamentally on a continuous loop of perceiving an environment, updating its internal state, and executing actions that alter that environment. In computer science literature, particularly within the framework of artificial intelligence, an agent is defined not just by its underlying model, but by its autonomy and environmental embeddedness. To be classified as a true AI agent, a system must exhibit several defining characteristics that separate it from rigid software scripts or standard query-based models.
First, AI agents possess autonomy, meaning they can initiate processes, evaluate intermediate results, and decide on subsequent actions without requiring step-by-step human prompts. Second, they exhibit reactivity, allowing them to perceive changes in their environment—such as a failed API call or unexpected data inputs—and adjust their execution path accordingly. Third, they demonstrate proactiveness; rather than solely reacting to triggers, goal-driven agents actively seek out optimal paths to fulfill their core objective. Finally, advanced agents feature social ability, meaning they can interact with human operators or other AI agents within a multi-agent orchestration framework, passing contexts, delegating tasks, and resolving conflicts through programmed communication
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification



AI Agents vs. AI Assistants vs. Bots
A common point of confusion in modern software engineering is the distinction between bots, AI assistants, and AI agents. While the terms are frequently conflated in marketing materials, they represent distinctly different architectural paradigms, degrees of autonomy, and technical complexities.
Bots are traditionally rules-based scripts executing deterministic workflows (e.g., a standard web scraper or an IRC chat bot). AI assistants leverage machine learning to parse natural language and provide helpful outputs, but they remain strictly conversational and require a human-in-the-loop to execute external logic. AI agents combine the natural language processing capabilities of assistants with the deterministic tool execution of bots, wrapping both in an autonomous reasoning loop.

| Characteristic | Traditional Bots | AI Assistants | AI Agents |
|---|---|---|---|
| Architecture | Deterministic, rule-based (If-This-Then-That). | Large Language Models (LLMs), Natural Language Processing (NLP). | LLM as a reasoning engine + Memory + Tool Access + Orchestration loop. |
| Autonomy | None. Executes predefined scripts strictly as programmed. | Low. Responds directly to user prompts. Operates in a single-turn or simple multi-turn conversational loop. | High. Can break down a high-level goal into sub-tasks, execute them, and self-correct without human intervention. |
| State & Memory | Stateless or relies on basic external databases for static variables. | Limited to the current session’s context window. | Maintains both short-term (context window) and long-term memory (Vector databases, RAG). |
| Tool Integration | Hardcoded API integrations. Cannot dynamically choose which tool to use. | Limited. May support basic plugins (e.g., web search), but heavily relies on user direction. | Extensive. Dynamically selects APIs, writes and executes code, and parses external data autonomously. |
The Cognitive Architecture of AI Agents
To build an AI agent that is capable of deterministic execution within a stochastic environment, developers rely on structured cognitive architectures. A cognitive architecture serves as the “brain” and “nervous system” of the agent, defining how it ingests data, stores knowledge, reasons about problems, and interacts with the physical or digital world. In modern implementations—such as those based on the ReAct (Reasoning and Acting) framework—this architecture relies on a foundation model (usually an LLM) serving as the core semantic processing unit, surrounded by distinct operational modules.
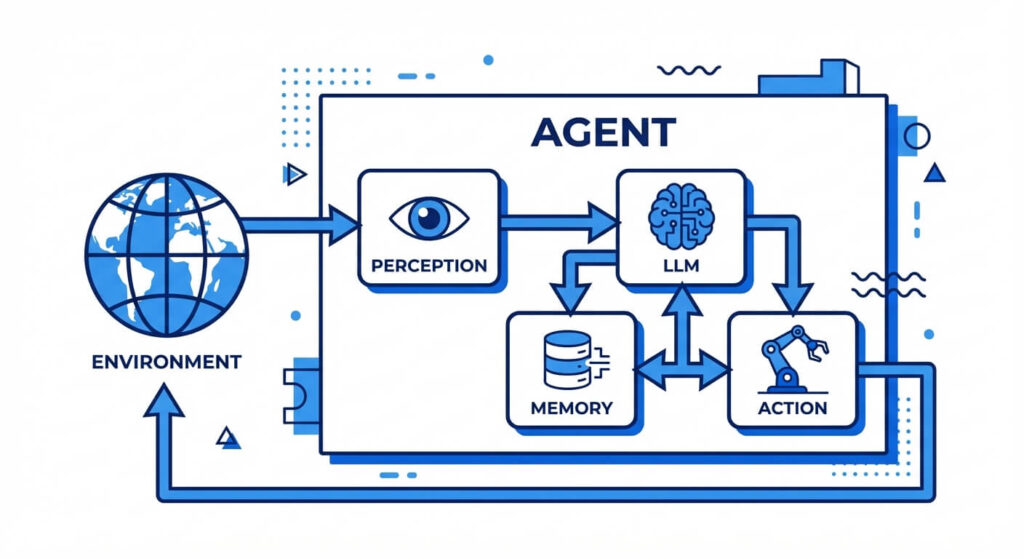
Perception (Inputs and Sensors)
In the context of software, perception refers to how an agent ingests state information from its environment. This can be as simple as receiving a JSON payload via an HTTP request or reading a user’s text prompt. In more complex multimodal systems, perception includes parsing visual data (images, UI screenshots), audio streams, or continuous telemetry data from a physical system. The agent maps these raw, unstructured inputs into an internal representation (usually vector embeddings) that its reasoning engine can process.
Master structured AI Engineering + GenAI hands-on, earn IIT Roorkee CEC Certification at ₹40,000
Memory Systems
Memory allows an agent to maintain context over time, mitigating the inherent statelessness of foundational LLMs. Agent architecture divides memory into two primary components:
- Short-Term Memory (STM): This relies on the model’s immediate context window. It stores the recent history of prompts, thoughts, and actions relevant to the current execution loop.
- Long-Term Memory (LTM): Because context windows are finite and computationally expensive, agents utilize external data stores—most commonly Vector Databases. Through Retrieval-Augmented Generation (RAG), agents query their LTM using semantic search. For instance, to retrieve the most relevant past experience, the system calculates the cosine similarity between the current query embedding and stored embeddings: cos(θ) = Σ(Ai * Bi) / ( √(ΣAi²) * √(ΣBi²) ).
Reasoning and Planning
Before taking action, an agent must deliberate. This is achieved through prompt engineering frameworks that force the LLM to output its internal reasoning steps. Techniques such as Chain of Thought (CoT) prompt the model to break a complex problem into intermediate steps. More advanced planning modules use Tree of Thoughts (ToT), allowing the agent to explore multiple reasoning paths in parallel, evaluate the viability of each path, and backtrack if a path leads to a dead end.
Action (Tools and Effectors)
An agent’s reasoning is useless without the ability to impact its environment. The Action module equips the agent with “effectors” or tools. When the reasoning engine determines that an external action is required (e.g., “I need to query the database for user X”), it generates a structured output (like JSON) matching a predefined tool schema. A deterministic execution layer parses this output, invokes the necessary API, SQL query, or Python script, and feeds the resulting data back into the agent’s perception module.
How Do AI Agents Work?
The operational mechanics of an AI agent revolve around continuous feedback loops and structured orchestration. While a standard LLM accepts a single input and generates a single output (completion), an AI agent operates iteratively. It breaks a high-level command into a sequence of operations, executes them, evaluates the results against its goal, and determines the next step. Understanding this process requires diving into the agentic loop and the orchestration patterns used to manage single and multi-agent systems.
The Agentic Loop
The core execution cycle of an AI agent is often described as the Observe-Reason-Act loop (or the OODA loop: Observe, Orient, Decide, Act).
- Observation: The agent evaluates its current state, its given goal, and any new data received from the environment or previous tool executions.
- Reasoning: The agent queries its core LLM to determine the next logical step. It asks itself: “Is the goal complete? If not, what tool must I use next, and with what parameters?”
- Action: The agent halts text generation, executes the chosen tool, and captures the output (or error log). This output is then appended to the agent’s short-term memory, triggering the next Observation phase. This loop continues recursively until the reasoning engine outputs a “Task Complete” signal.
Orchestration Patterns
When building enterprise applications, developers rarely rely on a monolithic “do-it-all” agent. Instead, they use orchestration patterns.
- Single-Agent Systems: Best suited for narrow, well-defined tasks (e.g., a customer support routing agent). The agent relies on a single prompt instruction and a limited set of tools.
- Hierarchical Multi-Agent Systems: Used for complex problem-solving. A “Manager” agent receives the primary user prompt, breaks it down into sub-tasks, and delegates them to specialized “Worker” agents (e.g., one agent writes code, another agent reviews it, and a third agent writes unit tests).
- Collaborative Systems: Agents operate as peers, using a shared blackboard or dialogue system to debate and refine outputs. Frameworks like AutoGen or LangGraph are heavily utilized to define the graph-based routing logic connecting these agents.
Types of AI Agents
In artificial intelligence theory—specifically the classification system established by Stuart Russell and Peter Norvig in “Artificial Intelligence: A Modern Approach”—agents are categorized based on their degree of perceived intelligence and their internal decision-making mechanisms. Modern LLM-based agents can be mapped onto these foundational types, representing an evolution from simple reactionary scripts to complex, goal-oriented systems.
Simple Reflex Agents
Simple reflex agents operate entirely on condition-action rules (if-then logic). They do not maintain an internal state or memory of past events; they react solely to the current percept. In modern systems, a simple reflex agent might be a basic triage bot that looks for a specific keyword in an email (e.g., “refund”) and automatically forwards it to the billing API. They are highly efficient but completely lack adaptability.
Model-Based Reflex Agents
These agents improve upon simple reflex agents by maintaining an internal state that tracks aspects of the environment that are not currently visible. They combine their current perception with their internal state to make decisions. For example, a web-scraping agent that encounters an error 429 (Too Many Requests) might maintain an internal state tracking the number of failed attempts, allowing it to apply exponential backoff rather than blindly retrying the request.
Goal-Based Agents
Goal-based agents are provided with explicit objectives and evaluate their potential actions based on whether they bring the agent closer to that goal. Modern autonomous coding agents function primarily as goal-based agents. If the goal is to “fix a bug in a specific Python file,” the agent will repeatedly write code, run tests, and evaluate the error logs until the tests pass. Their actions are dynamic, relying on search and planning algorithms rather than hardcoded if-then statements.
Utility-Based Agents
While a goal-based agent only cares about achieving a binary state (success or failure), a utility-based agent evaluates the quality of the path taken to reach that goal. They utilize a utility function to maximize efficiency, speed, or accuracy. For example, a financial trading agent might have a goal to execute a stock purchase, but its utility function ensures the action minimizes slippage and transaction fees, choosing the optimal exchange route among multiple possibilities.
Learning Agents
Learning agents possess the capability to improve their performance over time. They consist of a performance element (which dictates actions) and a learning element (which evaluates feedback and modifies the performance element). While pure learning agents are still an active area of research in LLMs (due to the high cost of continuous weight-updating), agents utilizing advanced RAG and dynamic prompt-rewriting simulate this behavior. They learn by appending successful reasoning paths to their long-term vector memory, ensuring faster, more accurate execution in future interactions.
Multimodal AI Agents
Historically, AI agents were restricted to text-based environments. However, the advent of multimodal foundation models (such as GPT-4o, Claude 3.5 Sonnet, and Gemini Pro) has fundamentally expanded agentic capabilities. A multimodal AI agent can ingest, process, and generate multiple types of data—text, images, audio, and video—simultaneously.
Under the hood, this is achieved by mapping different data types into a shared latent space. Vision encoders convert pixel data into vector representations that the core reasoning engine can process alongside text embeddings. This allows agents to perform highly complex physical and digital tasks. For example, a UI automation agent can observe a screenshot of a web application, calculate the bounding box coordinates of a specific button, and instruct a robotic process automation (RPA) tool to click that exact coordinate. Multimodal capabilities are essential for bridging the gap between digital software execution and physical robotics.
Training and Testing AI Agents
Creating an effective AI agent requires training methodologies that go beyond standard next-token prediction. Because agents interact with dynamic environments, they must be trained to utilize tools securely, reason logically, and recover from errors.
Training: Advanced foundation models are fine-tuned for agentic workflows using techniques like Reinforcement Learning from Human Feedback (RLHF) and Proximal Policy Optimization (PPO). In an agentic context, models are often trained on large datasets of tool-use trajectories. They learn to generate structured outputs (like JSON schemas) and understand the syntax required to interact with APIs.
Testing: Testing AI agents is notoriously difficult due to their non-deterministic nature. A standard unit test evaluates if Input A equals Output B. For agents, engineers must evaluate the reasoning path. Frameworks like AgentBench provide standardized testing environments where agents are dropped into sandboxed operating systems or databases and tasked with achieving a goal. Evaluators measure not only task success but also the efficiency of API calls, the agent’s ability to self-correct upon receiving an error trace, and its resilience against infinite action loops.
Applications of AI Agents in Modern Engineering
The integration of AI agents is transforming the software development lifecycle and enterprise operations by automating tasks that previously required deep cognitive focus.
- Autonomous Software Engineering: Tools like SWE-agent and Devin operate as autonomous software engineers. Given a GitHub issue, these agents can clone a repository, navigate the codebase using bash commands, read the file structure, implement fixes, run unit tests, and generate a pull request.
- DevOps and Site Reliability: AI agents are deployed to monitor infrastructure telemetry. When an alert triggers, an agent can SSH into the affected server, read the syslog, identify the root cause of a memory leak, and restart the necessary services before a human operator even acknowledges the pager alert.
- Data Pipeline Orchestration: Instead of relying on rigid ETL (Extract, Transform, Load) scripts, data agents can autonomously connect to various unstructured data sources, generate the necessary SQL to extract the data, write Python scripts to clean and normalize it, and load it into a data warehouse while dynamically handling schema changes.
Challenges in Building and Scaling AI Agents
Despite their immense potential, deploying AI agents in production environments presents significant technical and security hurdles that engineers must mitigate.

- Hallucinations and Infinite Loops: The most common failure mode for AI agents is hallucination within the reasoning step. An agent might hallucinate an API endpoint that does not exist. If the system’s error handling is poorly designed, the agent might repeatedly try to call the fake API, resulting in an infinite execution loop that drains compute resources and explodes API costs.
- Context Window Limitations: As an agent executes a multi-step task, its short-term memory fills up with intermediate outputs, system logs, and reasoning traces. Once the context window limit is reached, the agent forgets its initial instructions or the early steps of its plan, leading to catastrophic failure in task execution.
- Security and Prompt Injection: Because agents can execute code and alter databases, they introduce massive security vulnerabilities. A malicious user might submit a prompt injection attack embedded in an external website the agent is instructed to read. If the agent processes this malicious instruction, it could result in unauthorized data exfiltration or arbitrary code execution. Strict sandboxing, principle of least privilege for API keys, and human-in-the-loop validation for destructive actions are mandatory.
Frequently Asked Questions (FAQ)
Q: How does a Markov Decision Process (MDP) relate to AI agents? A: A Markov Decision Process is the foundational mathematical framework for reinforcement learning agents. An MDP is defined by a tuple (S, A, P, R, γ), where S is the set of states, A is the set of actions, P represents the transition probabilities from one state to another given an action, R is the reward function, and γ is the discount factor. It formally models the environment an agent interacts with, allowing the agent to compute an optimal policy that maximizes cumulative rewards.
Q: What is the difference between Chain of Thought (CoT) and ReAct prompting? A: Chain of Thought prompting asks the model to output a step-by-step reasoning process before arriving at a final answer, which improves logical accuracy. ReAct (Reasoning and Acting) takes this a step further by interleaving reasoning with external actions. In ReAct, the agent thinks about a step, executes an external tool to gather data, observes the result, and then initiates the next reasoning step based on that real-world observation.
Q: How do AI agents handle state management? A: AI agents handle state management by persisting their execution history. In a single session, state is managed by continually appending the environment’s feedback, the agent’s actions, and internal thoughts to the LLM’s context window. For multi-session state management, developers use external orchestrators (like LangChain or LlamaIndex) paired with relational or NoSQL databases to store session checkpoints, allowing the agent to pause, serialize its current state, and resume execution later.