



What is AI Agent Architecture? AI agent architecture refers to the structural framework that empowers artificial intelligence systems, specifically Large Language Models (LLMs), to operate autonomously. By integrating reasoning, memory, planning, and external tool execution, this architecture transforms static AI into dynamic, goal-oriented LLM agents capable of solving complex, multi-step problems.
Fundamentals of AI and Autonomous Agents
The landscape of artificial intelligence is undergoing a foundational paradigm shift. Historically, AI systems functioned as passive oracles—processing static inputs to generate probabilistic outputs based on pre-trained data weights. However, the introduction of autonomous capabilities has redefined this dynamic. In modern software engineering, an AI agent is not merely a conversational model; it is an intelligent system capable of perceiving its environment, formulating multi-step plans, retaining contextual memory, and executing physical or digital actions through external APIs.
This evolution marks the transition toward the agentic AI era, where the focus shifts from simple text generation to complex task automation. Understanding the underlying mechanisms of these systems is critical for engineers tasked with building reliable, scalable, and autonomous applications in production environments. An effective llm agent architecture bridges the gap between natural language understanding and programmatic execution, forming the backbone of next-generation intelligent software.
Core Components of an LLM Agent Architecture
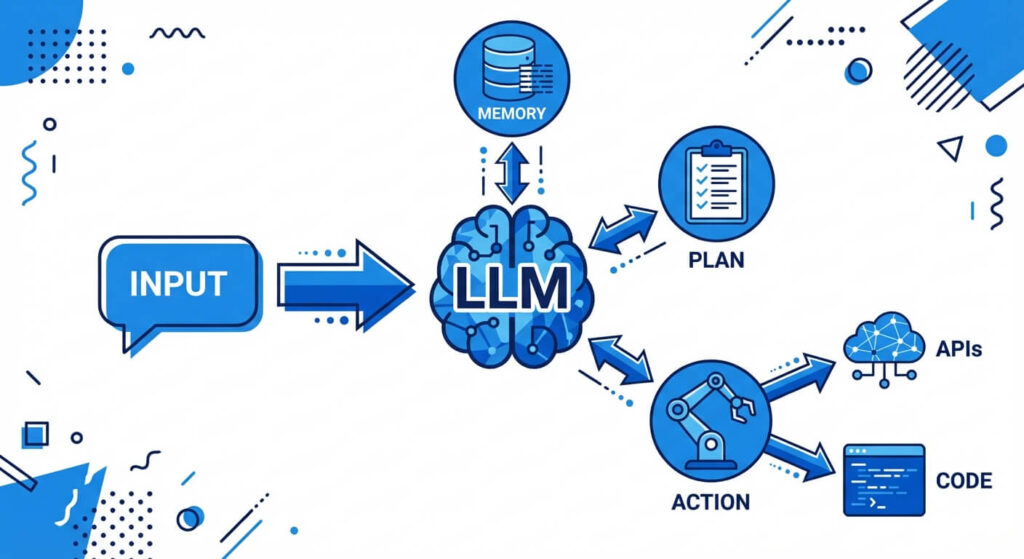
At the highest level of abstraction, an LLM agent architecture operates similarly to a central processing unit combined with peripheral sensory and execution modules. The architecture decouples the reasoning engine from the operational logic, allowing the system to interact seamlessly with external databases, code interpreters, and APIs. To achieve autonomous goal resolution, the architecture is typically divided into four distinct pillars: the cognitive engine, memory subsystems, planning mechanisms, and tool execution.
Mastery of these four components is required to design systems that do not merely predict the next token, but actively manage state, correct their own errors, and interact with the real world. By orchestrating these components securely, developers can build agents capable of long-running, asynchronous task execution.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification



1. The Cognitive Engine (The LLM Core)
The foundational layer of any AI agent is the Large Language Model itself, which functions as the central controller or “brain.” Unlike traditional deterministic software, the LLM processes non-deterministic natural language to interpret instructions, decompose tasks, and dictate the control flow. The model relies on its vast pre-training to understand context and syntax, functioning as a semantic router that decides when to trigger a specific sub-routine or external tool.
At a mathematical level, the LLM generates a sequence of tokens where the probability of the next token ti is dependent on the preceding tokens: P(ti | t1, t2, …, t_i-1). In an agentic framework, this output is strictly formatted (often via JSON schemas) so that downstream application logic can parse the model’s textual output into executable code functions.
2. Memory Systems (Short-Term and Long-Term)
For an AI agent to operate over extended periods, it requires robust state management. Memory in an llm agent architecture is bifurcated into short-term and long-term components.
- Short-Term Memory: This is analogous to a computer’s RAM and is constrained by the LLM’s context window. It contains the immediate prompt, the current system instructions, and the ongoing conversation history. Engineers must meticulously manage short-term memory using techniques like sliding window truncation to prevent exceeding token limits.
- Long-Term Memory: To persist knowledge across sessions, agents utilize long-term memory, typically backed by a Vector Database (e.g., Pinecone, Milvus, or pgvector). Information is converted into high-dimensional mathematical vectors (embeddings). When the agent needs historical context, it performs a similarity search. For instance, calculating the cosine similarity between a query vector A and a stored document vector B is represented as: cos(θ) = (A · B) / (|A| |B|). The closest matching vectors are retrieved and injected into the short-term memory as context.
3. Planning and Reasoning Modules
Autonomous execution requires the agent to break down a high-level directive into a sequential plan of action. The planning module dictates how an agent approaches a problem, utilizing various cognitive frameworks:
- Chain of Thought (CoT): Forces the model to generate intermediate reasoning steps before arriving at a final answer. This drastically reduces logical errors in complex arithmetic or coding tasks.
- Self-Reflection / Reflexion: The agent evaluates its own previous actions. If an executed code block returns a traceback error, the reflection module analyzes the error and adjusts the subsequent prompt to attempt a different approach.
- Sub-goal Decomposition: The agent breaks a broad command (“Deploy this application to AWS”) into a directed acyclic graph (DAG) of smaller tasks (e.g., “Write Dockerfile,” “Build Image,” “Push to ECR”).
4. Tool Integration and Action Space
An AI agent without tools is constrained to the knowledge it acquired during training. The action space defines the array of external capabilities an agent can leverage. By defining tools via OpenAPI specifications or explicit function signatures, the agent can structure its output to trigger external Python functions, SQL queries, or RESTful API calls. Standard tools include web browsers (for real-time data retrieval), code interpreters (for executing generated Python scripts in sandboxed environments), and file I/O operations.
Technical Approaches: Frameworks and Paradigms
To standardize the development of autonomous agents, the AI engineering community has developed several core architectural paradigms. The most prominent among these is the ReAct (Reason + Act) framework.
The ReAct Framework
The ReAct framework forces the LLM to output a specific structural loop: Thought → Action → Observation.
- Thought: The agent explains its current understanding of the state and what it needs to do next.
- Action: The agent outputs a strictly formatted command to invoke a specific tool.
- Observation: The system executes the tool and feeds the raw output (or error message) back into the agent’s context.
This iterative loop continues until the agent’s “Thought” dictates that the final goal has been achieved, terminating the execution cycle.
Tree of Thoughts (ToT) and Graph of Thoughts (GoT)
For exceedingly complex problems, linear reasoning (CoT) is insufficient. The Tree of Thoughts (ToT) architecture allows the AI to explore multiple reasoning paths simultaneously. It evaluates the viability of different branches, abandons paths that lead to logical dead-ends, and backtracks to previous states—much like a breadth-first search (BFS) or depth-first search (DFS) algorithm used in traditional computer science. Graph of Thoughts (GoT) extends this by allowing disparate reasoning branches to merge, synthesizing information from multiple independent logical streams into a cohesive final solution.
Single-Agent vs. Multi-Agent Architectures
As task complexity scales within enterprise applications, software engineers must decide whether to deploy a monolithic single-agent architecture or a distributed multi-agent system (MAS). A single LLM agent handles all reasoning, tool execution, and memory management within a solitary context window. While straightforward to implement, a single agent frequently suffers from context dilution and compounding errors during extended, multi-step execution loops.
Conversely, multi-agent architectures distribute the cognitive load across multiple specialized models. In a multi-agent system, disparate agents are initialized with specific personas, distinct system prompts, and limited toolsets. Frameworks such as AutoGen, LangGraph, and CrewAI facilitate this modular approach. In these systems, a “Manager” agent might decompose a task and delegate sub-tasks to a “Researcher” agent and a “Coder” agent. These agents can debate, peer-review code, and pass outputs sequentially, vastly improving accuracy and system resilience.
| Feature | Single-Agent Architecture | Multi-Agent Systems (MAS) |
|---|---|---|
| Complexity & Implementation | Low overhead; simpler to orchestrate and debug. | High overhead; requires robust routing and state management between nodes. |
| Context Window Utilization | High risk of context exhaustion; all steps flood a single memory stream. | Optimized; context is distributed, meaning each agent only sees data relevant to its specific role. |
| Error Mitigation Strategy | Relies entirely on self-reflection (Reflexion) to catch and correct its own mistakes. | Utilizes peer-review, supervisor agents, and multi-model consensus to ensure output validity. |
| Execution Speed (Latency) | Generally faster for simple tasks as no network routing between agents is required. | Slower due to inter-agent communication, token generation across multiple models, and consensus delays. |
| Best Use Cases | Straightforward data retrieval, basic customer support, simple linear workflows. | Complex software development, deep scientific research, dynamic data engineering pipelines. |
Applications and Economic Impacts of AI Agents
The deployment of robust llm agent architecture is profoundly altering enterprise software development, data analysis, and operational workflows. By moving beyond text generation into autonomous task execution, organizations are experiencing significant shifts in productivity and economic impact.
- Autonomous Software Engineering: AI agents are now capable of operating entirely within Integrated Development Environments (IDEs). Given a GitHub issue, an engineering agent can clone a repository, navigate the file system, read existing codebase logic, formulate a patch, run unit tests, and submit a pull request. Tools leveraging this architecture are reducing the time-to-resolution for routine bug fixes.
- Data Analysis and Engineering: In data pipelines, AI agents can dynamically interface with SQL databases and Pandas dataframes. Instead of writing static query scripts, a data scientist can ask an agent to “Identify the cause of customer churn in Q3.” The agent autonomously queries the database, writes Python scripts to visualize the data, and outputs a comprehensive statistical report.
- Cloud Infrastructure and Orchestration: Cloud providers are actively pushing toward the agentic AI era. Organizations are utilizing AI services to dynamically manage AWS deployments, optimize server loads, and autonomously execute disaster recovery protocols based on anomalous network telemetry.
Societal and Ethical Dimensions: Building AI Responsibly
The transition from passive AI to active, autonomous agents introduces profound ethical and technical risks. Because agents operate dynamically and possess the ability to alter external systems (e.g., executing code, modifying databases, sending emails), the margin for error is critically low. Building AI responsibly requires strict adherence to safety frameworks and deterministic guardrails.
Managing Hallucinations and Unbounded Execution
The most pressing technical risk in agent deployment is the potential for unbounded execution loops. If an agent hallucinates an incorrect API parameter, receives an error, and fails to self-correct, it may repeatedly attempt the same flawed action. Without proper safeguards, this can lead to infinite loops that drain computational resources, exhaust API credit limits, and disrupt connected services.
Engineers must implement strict deterministic constraints within their llm agent architecture. This includes:
- Max Iteration Limits: Hardcoding a maximum number of ReAct loop iterations (e.g., terminating the process after 5 failed tool calls).
- Human-in-the-Loop (HITL): Requiring explicit human authorization before an agent can execute high-stakes actions, such as dropping a database table or executing financial transactions.
- Sandboxing: Executing all agent-generated code inside secure, ephemeral Docker containers with restricted network access to prevent malicious code execution or data exfiltration.
Future Trajectories: The Agentic AI Era
The architectural evolution of AI is moving rapidly toward continuous, asynchronous agents. Future trajectories indicate a shift from prompt-based interactions to goal-oriented delegations. As foundational scaling laws continue to improve the underlying reasoning capabilities of models, the reliance on rigid scaffolding (like strict ReAct loops) will likely decrease, giving way to fluid, native reasoning capabilities.
Major cloud ecosystems are also adapting to support this paradigm shift. The integration of managed vector databases, secure tool-calling APIs, and serverless compute optimized for LLM inference will democratize the ability to build and deploy complex multi-agent systems. As these infrastructures mature, AI agents will transition from experimental prototypes into the standard abstraction layer for modern software interaction.
Frequently Asked Questions (FAQ)
What is the difference between an AI model and an AI agent? An AI model (like a base LLM) is a mathematical algorithm trained to predict the next word based on an input prompt. An AI agent is a broader system that wraps the AI model in an architecture capable of memory management, logical planning, and executing actions using external tools.
How does an LLM agent architecture handle memory? Agents handle memory by splitting it into short-term and long-term storage. Short-term memory utilizes the LLM’s immediate context window to track the current conversation. Long-term memory involves storing historical data in a vector database as high-dimensional mathematical embeddings, which the agent can retrieve later via similarity search.
What is the ReAct framework in AI? ReAct stands for “Reason + Act.” It is an orchestration paradigm that prompts the LLM to process tasks in a continuous loop consisting of a Thought (reasoning about the problem), an Action (calling an external tool or API), and an Observation (analyzing the tool’s output to plan the next step).
How do you prevent an AI agent from entering an infinite loop? Engineers prevent infinite loops by implementing deterministic guardrails outside of the LLM. This includes setting a max_iterations limit on the execution loop, enforcing a timeout constraint, or requiring Human-in-the-Loop (HITL) approval if the agent attempts to repeat the same failed action multiple times.