
An autonomous AI agent is a sophisticated artificial intelligence system capable of understanding an objective, independently formulating a sequence of tasks, and executing them without continuous human intervention. These systems utilize advanced cognitive models to perceive their environment, reason, and interact with external tools.
Introduction to Autonomous AI Agents
The paradigm of artificial intelligence has shifted rapidly from purely reactive machine learning models to proactive, goal-oriented systems. Historically, artificial intelligence operated on a request-response basis. A user inputs a prompt, and the model generates a response. The system processes the transaction and immediately halts, maintaining no persistent operational state. An autonomous system, however, fundamentally alters this interaction. By integrating a cognitive engine—typically a Large Language Model (LLM)—with memory management, dynamic planning capabilities, and the ability to execute code or call external Application Programming Interfaces (APIs), the system becomes capable of executing open-ended objectives over extended periods.
In computer science, a system is described as autonomous if it operates without direct external control, adapting to changes in its environment and managing its own state to achieve a predefined objective. In the context of modern software engineering, autonomous AI agents represent the convergence of natural language understanding, directed acyclic graph (DAG) execution, and reinforcement learning. These agents can write code, debug software, manage cloud infrastructure, and orchestrate complex enterprise workflows, transitioning AI from a conversational novelty into a deeply integrated component of automated systems architecture.
Core Architecture of Autonomous Agents
The underlying architecture of an autonomous AI agent can be conceptualized similarly to a traditional computer operating system. While an operating system relies on a Central Processing Unit (CPU) for computation, Random Access Memory (RAM) for active state management, and a file system for persistent storage, an autonomous agent utilizes an LLM as its cognitive engine, context windows for short-term memory, and vector databases for long-term semantic retrieval.
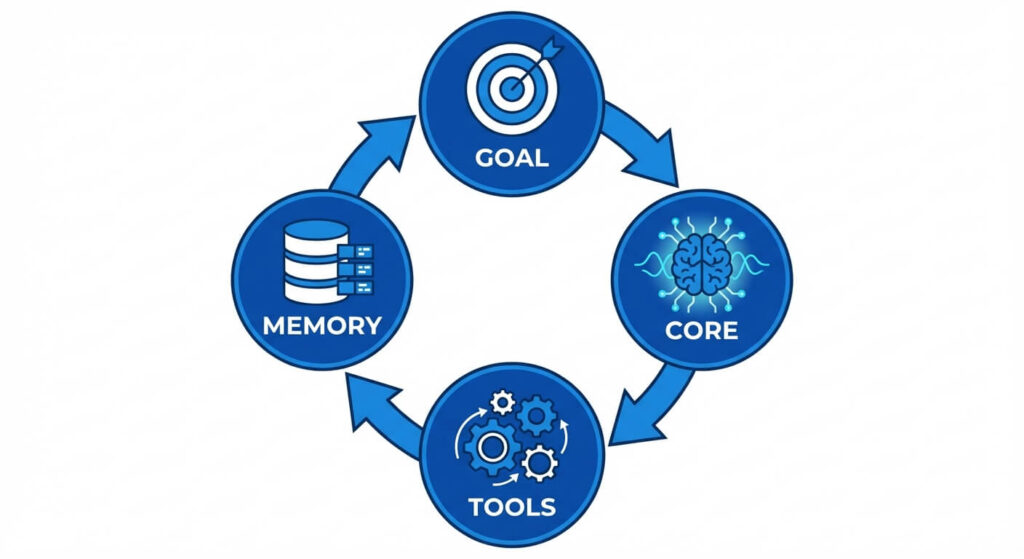
Perception and Environment Mapping
Before an agent can act, it must perceive its environment. In robotics, perception relies on sensors. In software engineering and autonomous AI, perception relies on data ingestion and environmental context. This context is often provided via structured JSON objects, API responses, terminal output, or DOM elements from a web page.
When an agent executes an action—for example, querying a database—it must parse the returned data (the perception phase) to determine its next step. This requires robust parsing algorithms that map unstructured or semi-structured environmental data into a structured schema that the core cognitive engine can process. If an agent executes a Python script and receives a traceback error, it must “perceive” this error, map it to the expected outcome, and recognize that the previous action failed.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification



Memory Management: Short-Term vs. Long-Term
Memory is the differentiating factor between a stateless function and an autonomous entity. Without memory, an agent cannot engage in multi-step reasoning, as it will forget the context of step one by the time it reaches step three.
Short-Term Memory (Context Window): This is analogous to system RAM. It represents the immediate sequence of prompts, thoughts, and actions retained within the LLM’s context window. Because LLMs have a strict token limit (e.g., 8k, 128k, or 1M tokens), short-term memory must be heavily optimized. Techniques such as rolling context buffers and token summarization are employed to prevent the agent from exceeding its maximum sequence length.

Long-Term Memory (Vector Databases): To persist knowledge across sessions, autonomous agents utilize long-term memory via Vector Databases (such as Pinecone, Milvus, or pgvector). When an agent acquires new information, the text is converted into a high-dimensional mathematical vector using an embedding model. These vectors are stored in the database. When the agent encounters a new problem, it converts the current state into a vector and performs a similarity search to retrieve relevant past experiences.
The mathematical foundation of this retrieval is typically Cosine Similarity. If vector A represents the current query and vector B represents a stored memory, the similarity is calculated as: Cosine Similarity = (A · B) / (||A|| ||B||) Where (A · B) is the dot product of the vectors, and ||A|| represents the magnitude of the vector. The agent retrieves memories where this value is closest to 1.
Planning and Reasoning
An autonomous system must decompose high-level objectives into granular, executable tasks. This is achieved through advanced prompting techniques and reasoning frameworks.
Chain of Thought (CoT): This technique forces the LLM to output its intermediate reasoning steps before arriving at a conclusion. By mapping out its logic, the model significantly reduces calculation and logic errors. ReAct (Reasoning and Acting): This framework interleaves reasoning traces with task-specific actions. The agent loops through a structured sequence:
- Thought: What do I need to do next?
- Action: Execute a specific tool.
- Observation: Analyze the output of the tool. This continuous loop prevents the agent from making assumptions, forcing it to ground its reasoning in actual environmental feedback.
Scaler Masterclasses
Learn from industry experts and accelerate your career with hands-on, interactive sessions.
Action and Execution (Tool Use)
Reasoning is useless without the ability to influence the environment. Autonomous agents are equipped with “Tools”—pre-defined functions that the agent can invoke. These tools include web search APIs, Python read-eval-print loops (REPL), SQL database connectors, and CI/CD pipeline triggers.
When defining a tool for an agent, developers provide a strict OpenAPI schema or JSON signature. The agent evaluates the required parameters, extracts the necessary arguments from its reasoning engine, and formats a request. The host application executes the function natively and returns the output to the agent’s observation loop.
How Autonomous Agents Differ from Traditional AI
Understanding the paradigm shift requires drawing strict boundaries between standard AI models and fully autonomous configurations. Traditional AI models are deterministic and state-bound. They execute a single transformation function over an input and yield an output. Autonomous configurations utilize non-deterministic routing, where the control flow of the application is decided at runtime by the model itself, rather than by hardcoded if/else statements written by a developer.
| Feature | Traditional AI / Standard LLMs | Autonomous AI Agents |
|---|---|---|
| Control Flow | Deterministic. Handled by developer-written scripts and static logic trees. | Non-deterministic. The AI routes its own logic and dictates the application state. |
| State Management | Stateless per transaction. Requires the user to re-supply context on each prompt. | Stateful. Manages its own short-term and long-term memory structures autonomously. |
| Execution Model | Request-Response. Halts immediately after generating the text output. | Loop-based execution (e.g., ReAct). Continues running until the terminal objective is met. |
| Environmental Interaction | None. Completely isolated from external systems unless hardcoded by middleware. | Extensive. Dynamically selects and invokes APIs, modifies files, and queries databases. |
| Error Handling | Fails silently or outputs an incorrect response (hallucination) to the user. | Self-correcting. Parses error logs, realizes the mistake, and formulates a new approach. |
Key Algorithms and Frameworks
To engineer autonomous systems, developers rely on specialized algorithms and orchestration frameworks designed to handle complex state machines and directed computational graphs.
Large Language Models (LLMs) as Cognitive Engines
The foundation of autonomy relies on autoregressive language models. These models calculate the probability distribution of the next token given a sequence of previous tokens. Mathematically, the model seeks to maximize the probability: P(yt | y1, y2, …, yt-1, X) where X is the input prompt and tools, and y represents the output tokens. In an autonomous setting, X is continuously updated with the output of external tools. Models optimized for autonomy (like GPT-4 or Claude 3.5 Sonnet) have been fine-tuned heavily on function-calling datasets, enabling them to reliably output structured JSON formats rather than conversational text.
Agentic Design Patterns
Building robust autonomous systems requires specific design patterns to prevent infinite loops and ensure reliability.
- Reflection: The agent is given a specific prompt that asks it to critique its own previous output before moving forward. This creates a secondary loop where the agent acts as its own unit-tester.
- Plan-and-Solve: The agent splits its processing into two distinct phases. First, it generates a comprehensive step-by-step directed acyclic graph (DAG) of the tasks required. Second, it executes those tasks sequentially, ticking them off. This minimizes context loss.
- Multi-Agent Collaboration: Instead of a single monolithic agent, developers instantiate multiple specialized agents. For instance, a “Coder Agent” writes software, while a “Reviewer Agent” analyzes the code for security flaws. They converse and pass data back and forth until a consensus is reached, operating on an actor-model architecture.
Popular Orchestration Frameworks
Developing an agent entirely from scratch requires extensive boilerplate code for parsing LLM outputs and handling HTTP requests. Several frameworks have emerged to abstract this complexity.
- LangChain / LangGraph: LangChain provides standard interfaces for memory, tools, and models. LangGraph, its extension, allows developers to build highly controllable agents using cyclical graphs, managing the state transitions between different agentic nodes explicitly.
- AutoGPT: One of the earliest open-source autonomous agents, AutoGPT demonstrated how an LLM could be placed into an infinite loop with access to web search and file writing capabilities to achieve a high-level goal.
- Microsoft AutoGen: A framework specifically designed for multi-agent conversations. AutoGen allows developers to define distinct personas and execution environments, letting agents converse to solve tasks that require multiple domains of expertise.
Implementing an Autonomous Agent: A Technical Walkthrough
To practically understand how an autonomous agent is constructed, we will build a simplified ReAct agent using Python and LangChain. This agent will be given a tool to check system metrics and will autonomously decide when and how to use it to answer a complex objective.
from langchain_openai import ChatOpenAI
from langchain_core.tools import tool
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_core.prompts import ChatPromptTemplate
import os
# 1. Define the Tools
# The @tool decorator automatically parses the docstring to create an OpenAPI schema
# that the LLM can understand. This docstring is critical for the agent's perception.
@tool
def fetch_system_uptime(server_id: str) -> str:
"""
Fetches the current uptime and CPU usage of a given server by its ID.
Always use this tool when asked about server health.
"""
# In a real enterprise system, this would make an external API call to AWS/GCP
simulated_database = {
"srv-alpha-01": "Uptime: 45 days, CPU Usage: 42%",
"srv-beta-02": "Uptime: 2 days, CPU Usage: 89%"
}
return simulated_database.get(server_id, "Server ID not found.")
tools = [fetch_system_uptime]
# 2. Initialize the Cognitive Engine (LLM)
# We use a model specifically trained on function calling.
llm = ChatOpenAI(model="gpt-4-turbo", temperature=0)
# 3. Construct the Prompt (System Instructions)
# The prompt binds the tools and variables into the agent's reasoning loop.
prompt = ChatPromptTemplate.from_messages([
("system", "You are an autonomous Site Reliability Engineering (SRE) agent. "
"You have access to tools to check system health. Use them when necessary. "
"Provide concise, technical answers."),
("human", "{input}"),
# The agent_scratchpad is where the observation loop stores its intermediate steps.
("placeholder", "{agent_scratchpad}"),
])
# 4. Bind the Agent and the Executor
agent = create_tool_calling_agent(llm, tools, prompt)
# The AgentExecutor acts as the while-loop, managing the ReAct logic and tool execution.
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True, max_iterations=5)
# 5. Execute an Open-Ended Objective
objective = "Check the health of srv-beta-02. If the CPU usage is over 80%, recommend three specific Linux commands to diagnose the spike."
# The agent will parse the objective, realize it needs the server data,
# format a JSON call to fetch_system_uptime, read the result, realize CPU is at 89%,
# and then autonomously generate the Linux commands.
response = agent_executor.invoke({"input": objective})
print(response["output"])
In this technical execution, the developer does not write the if CPU > 80% logic in Python. The control flow is entirely delegated to the LLM. The agent parses the environment (the simulated database response), holds it in its short-term memory (the scratchpad), performs a logical evaluation, and generates the final output.
Scaler Masterclasses
Learn from industry experts and accelerate your career with hands-on, interactive sessions.
Evaluating Autonomous Agents for Business
The integration of autonomous agents for business requires a rigorous evaluation of Return on Investment (ROI), security, and infrastructure alignment. In an enterprise environment, autonomous agents transition from experimental scripts to critical infrastructure components known as Agentic Workflows.
Workflow Automation and ERP Integration
Modern businesses rely on fragmented software ecosystems—Enterprise Resource Planning (ERP) systems, Customer Relationship Management (CRM) databases, and CI/CD deployment pipelines. Traditional automation relies on Robotic Process Automation (RPA). RPA is highly brittle; it operates on strict, predefined coordinates and APIs. If a UI button moves or an API schema slightly changes, the RPA pipeline shatters.
Autonomous agents for business resolve this brittleness through semantic understanding. If an API schema changes, an autonomous agent can read the new documentation or parse the JSON error dynamically, adjust its parameters, and complete the API call without human intervention. Businesses are deploying these agents for:
- Automated Customer Support Resolution: Moving beyond chatbots that simply regurgitate FAQ documents, autonomous support agents interact with secure backend APIs to process refunds, alter shipping addresses, and troubleshoot technical issues dynamically.
- Data Pipeline Engineering: Agents that autonomously map unstructured incoming data streams (like vendor PDFs) into strictly structured SQL schemas, continuously updating their parsing logic as vendor formats change.
- Cybersecurity Triaging: Security agents that monitor network logs autonomously. When an anomaly is detected, the agent isolates the node, queries threat intelligence databases, compiles a forensics report, and pages a human engineer with an actionable summary.
Dynamic Decision Making vs. Deterministic Compliance
The primary hurdle in deploying autonomous agents for business is regulatory compliance. In highly regulated sectors (finance, healthcare), non-deterministic control flow introduces unacceptable risk. If an agent hallucinates, it could theoretically execute a catastrophic trade or expose patient data.
To mitigate this, enterprises implement “Human-in-the-Loop” (HITL) architectures. The autonomous agent is granted read-only access to investigate, reason, and plan an execution path. However, before the final API POST or DELETE request is executed, the execution graph pauses and prompts a human administrator for cryptographic approval. This merges the high-speed data processing capabilities of an autonomous system with the deterministic safety requirements of enterprise compliance.
Challenges and Limitations in Autonomy
Despite rapid advancements, engineering stable autonomous agents remains highly complex due to inherent limitations in current artificial intelligence models.
Hallucinations and the Error Compounding Problem
When an LLM generates a mathematically incorrect or logically flawed output, it is referred to as a hallucination. In standard AI interactions, a single hallucination results in one bad response. In an autonomous loop, however, an agent uses its previous outputs as the foundation for its subsequent actions.
This leads to the Error Compounding Problem. Mathematically, if an agent is tasked with executing a 5-step autonomous plan, and it has a 90% success rate (probability p = 0.90) for each individual step, the overall probability of successfully completing the objective is p^n. For n = 5 steps: Success Rate = 0.90^5 = 0.59 (or 59%)
Because the errors compound multiplicatively, even highly accurate models can fail catastrophically on long-horizon tasks. To combat this, developers must implement aggressive self-reflection loops and strict validation constraints using tools like Pydantic in Python to ensure every output strictly conforms to an expected schema before the agent is allowed to proceed to the next node in the graph.
Infinite Loops and Cost Overruns
Because autonomous systems utilize while loops to continue acting until an objective is met, a failure in logic can trap the agent in an infinite loop. For instance, an agent might repeatedly call a failing API, read the error, and incorrectly formulate the exact same API call again.
Given that LLM API providers (like OpenAI, Anthropic, or Google) charge by the token, an infinite loop can rapidly consume massive amounts of API credits, leading to severe cost overruns. System architects must implement strict guardrails:
- Iteration Caps: Hardcoding a maximum number of steps (e.g.,
max_iterations=10in LangChain) before forcing the agent to halt and yield an error to a human. - Timeouts: Implementing strict wall-clock time limits on agent execution threads.
- Semantic Duplicate Detection: Implementing middleware that calculates the cosine similarity of the agent’s recent actions. If the agent executes actions with a similarity score of > 0.95 sequentially, the system interrupts the agent, assuming it is trapped in a logical loop.
Context Degradation
As an autonomous agent operates over hours or days, its context window fills with API logs, thoughts, and observations. As the prompt length approaches the model’s maximum context limit, the model’s ability to recall information from the beginning of the prompt degrades—a phenomenon known as the “Lost in the Middle” problem. Engineering autonomous systems requires robust garbage collection for memory, dynamically summarizing older logs and pushing them into vector databases while keeping the immediate context window clean and sparse.
Frequently Asked Questions (FAQ)
What is the difference between Robotic Process Automation (RPA) and an autonomous AI agent? RPA systems are rule-based software robots designed to mimic human actions by following strict, predefined paths (e.g., clicking specific coordinates or parsing fixed JSON). They possess no cognitive reasoning. Autonomous AI agents, however, use LLMs to dynamically understand goals, formulate plans, and adapt to changing interfaces or unexpected errors without requiring manual reprogramming.

Can autonomous agents learn and improve over time? In a strict machine learning sense, standard autonomous agents built on pre-trained LLMs do not update their internal neural network weights at runtime. However, they can “learn” environmentally by updating their long-term vector database memories. By saving records of failed plans and successful strategies, the agent can retrieve these experiences in future sessions, effectively improving its success rate through contextual learning rather than weight adjustment.
How do you prevent an autonomous agent from executing dangerous code? Agents should never be given unfettered access to production environments. Dangerous actions are mitigated by running the agent inside heavily restricted Docker containers or secure sandboxes (like WebAssembly environments). Additionally, the principle of least privilege must be applied to the API keys the agent uses, and “Human-in-the-Loop” approval stops should be enforced for any destructive actions (e.g., dropping a database or pushing code to main).
How do autonomous agents communicate with each other? In multi-agent systems, agents communicate by passing structured messages (often JSON) via an orchestrating message bus. One agent generates an output, the orchestrator routes that output as a system prompt to the next agent, and the cycle continues. Frameworks like Microsoft AutoGen handle the underlying thread management and conversational routing necessary for this interaction.
Are autonomous agents capable of independent thought? No. Autonomous agents do not possess consciousness, independent will, or actual understanding. They are sophisticated mathematical engines executing probabilistic text generation based on the prompts provided by their environment. The “autonomy” refers to their structural capability to execute a programmed loop of task-generation and API execution without pausing for human input, not true cognitive independence.