
An artificial intelligence agent is an autonomous computational entity that observes its environment through sensors, processes these percepts to make decisions, and acts upon the environment using actuators to achieve specific objectives. Different types of agents range from simple reactive mechanisms to complex, predictive learning systems capable of multi-step planning.
Introduction to Artificial Intelligence Agents
In the study of artificial intelligence, the concept of an “agent” serves as the foundational abstraction for designing intelligent systems. Fundamentally, an AI agent is a programmatic implementation of an architecture that maps a sequence of environmental percepts to a set of rational actions. Mathematically, the agent function can be defined as a mapping from percept histories to actions: f: P* → A.
To build robust AI systems, software engineers must select different architectural models depending on the complexity of the task, the observability of the environment, and the computational resources available. The architecture provides the computing device, hardware, and sensory-motor infrastructure, while the agent program implements the mapping function. An agent is formally defined by the equation: Agent = Architecture + Program.
Understanding the different types of agents in AI is crucial for systems design. A self-driving car algorithm, a financial high-frequency trading bot, and a non-player character (NPC) in a video game all operate as autonomous agents, yet they utilize vastly different internal architectures to process states and calculate optimal outputs.
The PEAS Framework in Agent System Design
Before exploring the different agent architectures, engineers must define the problem space the agent will inhabit. The standard methodology for specifying an agent’s operational parameters is the PEAS framework, which stands for Performance measure, Environment, Actuators, and Sensors.
By defining these four components, developers can objectively determine which class of agent architecture is required to solve a given problem.
- Performance Measure: The objective criterion for the agent’s success. For a vacuum-cleaning robot, this might be the amount of dirt cleaned within an hour and the minimization of battery consumed. For an autonomous vehicle, it includes safety, travel time, and adherence to traffic laws.
- Environment: The external domain with which the agent interacts. Environments are classified across multiple dimensions: fully observable vs. partially observable, deterministic vs. stochastic, episodic vs. sequential, static vs. dynamic, and discrete vs. continuous. Different environmental properties necessitate different agent algorithms.
- Actuators: The mechanisms by which the agent interacts with and alters its environment. In software agents, actuators might be API calls, database writes, or network requests. In physical robotics, actuators are motors, hydraulics, and steering wheels.
- Sensors: The components that allow the agent to receive inputs (percepts) from the environment. Examples include cameras, LiDAR, microphone arrays, keyboard inputs, or incoming data streams from network sockets.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification



Different Types of Agents in AI
Artificial intelligence agents are categorized hierarchically based on their degree of perceived intelligence, state tracking, and decision-making complexity. As tasks scale in uncertainty and scope, the required architecture shifts from purely reactive to deliberative and learning-oriented. There are five primary classifications of AI agents.
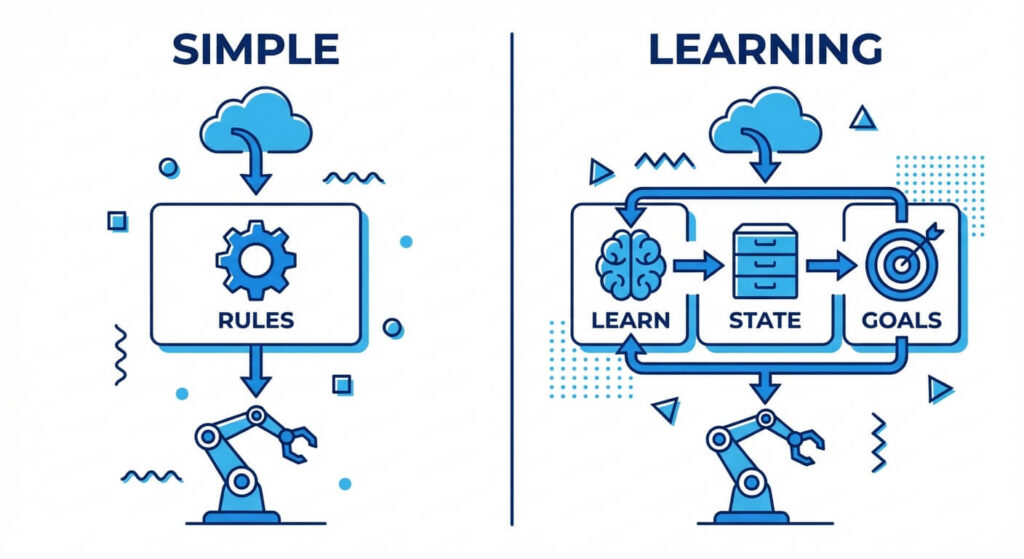
1. Simple Reflex Agents

Simple reflex agents are the most basic form of AI agents. They operate solely on the current percept, completely ignoring the rest of the percept history. Their decision-making process is driven entirely by a set of predefined Condition-Action rules (often referred to as IF-THEN rules).
Because these agents do not maintain an internal state or memory of past events, they can only succeed in fully observable environments. If the environment is partially observable, a simple reflex agent will likely suffer from infinite loops or suboptimal decision-making because it lacks the context necessary to disambiguate identical immediate percepts.
Key Characteristics:
- Architecture: Extremely lightweight with near-instantaneous execution time.
- Memory: Zero memory or historical state retention.
- Use Case: Basic thermostats, spam filters operating on single-keyword triggers, and rudimentary load balancers routing traffic based strictly on current server CPU load.
2. Model-Based Reflex Agents
When environments become partially observable, an agent can no longer rely solely on its immediate sensory input. Model-based reflex agents solve this by maintaining an internal state—a memory of past percepts and actions.
To update this internal state, the agent requires two distinct models encoded into its architecture:
- A Transition Model: Knowledge of how the environment evolves independently of the agent.
- A Sensor Model: Knowledge of how the agent’s actions affect the environment.
By mathematically updating its current state representation using the transition and sensor models (a process conceptually similar to a Kalman Filter or Hidden Markov Model updating), the model-based agent can deduce unobserved parts of the environment before applying its condition-action rules.
3. Goal-Based Agents
While model-based agents can track the current state of the world, they do not inherently know what they are trying to achieve. Goal-based agents introduce the concept of “desirable states.” In addition to state-tracking, these agents are equipped with goal information that describes scenarios that are considered successful.
Goal-based agents are fundamentally different from reactive agents because they employ deliberative reasoning. Before taking an action, they project the outcomes of entirely different sequences of actions to see which sequence reaches the goal state. This requires the use of search algorithms (such as Depth-First Search, Breadth-First Search, or A* Search) and automated planning systems.
Unlike rules-based systems, goal-based agents are highly flexible. If the environment changes or the objective shifts, the agent’s internal planning algorithm will dynamically recalculate a different path to success without requiring the engineer to rewrite hard-coded condition-action rules.
4. Utility-Based Agents
Achieving a goal is often not enough; there are usually different, competing ways to reach an objective, and some paths are safer, faster, or cheaper than others. A utility-based agent extends the goal-based architecture by introducing a utility function—an internalization of performance measures that maps a specific state (or sequence of states) to a real number indicating the agent’s “happiness” or degree of success.
In environments fraught with uncertainty, utility-based agents rely on the principle of Maximum Expected Utility (MEU). Instead of merely finding a path to a goal, they calculate probabilities of different outcomes and choose the action that maximizes the expected value of the utility function.
Mathematically, the expected utility (EU) of an action ‘a’ given an evidence sequence ‘e’ is evaluated as: EU(a|e) = Σ P(s’|a, e) * U(s’) Where P(s’|a, e) is the probability of reaching state s’ after executing action a, and U(s’) is the utility of state s’.
Scaler Masterclasses
Learn from industry experts and accelerate your career with hands-on, interactive sessions.
5. Learning Agents
The previous four types of agents operate under the assumption that their internal models, rules, and functions are hand-coded by human software engineers. Learning agents, however, are designed to operate in unknown environments and become more competent over time.
A learning agent architecture is divided into four distinct conceptual components:
- The Learning Element: Responsible for making improvements to the agent based on feedback.
- The Performance Element: The core agent architecture (which could be a reflex, goal-based, or utility-based agent) that selects actions.
- The Critic: Observes the environment and provides feedback to the learning element on how well the agent is performing relative to fixed performance standards.
- The Problem Generator: Suggests exploratory actions that lead to new, informative experiences, preventing the agent from getting stuck in local optima.
Reinforcement Learning (RL) agents are the most prominent examples of learning agents today, utilizing algorithms like Q-Learning and Proximal Policy Optimization (PPO) to master complex tasks.
Architectural Comparison of AI Agent Types
To assist systems architects in determining the appropriate AI model for their specific computational constraints, the following table provides a strict comparative analysis of the different agent architectures.
| Agent Type | Memory Requirement | Decision Basis | Ideal Environment | Computational Complexity |
|---|---|---|---|---|
| Simple Reflex Agent | None (Stateless) | Current percept only via IF-THEN rules | Fully observable, static, deterministic | O(1) execution; highly efficient and lightweight. |
| Model-Based Reflex Agent | Low (Current state history) | Current state + inferred unobserved states | Partially observable, deterministic or stochastic | Low to Medium; depends on state-updating mathematical models. |
| Goal-Based Agent | Medium to High | Future state projection and pathfinding to goals | Partially observable, sequential, static or dynamic | High; requires intensive search heuristics (e.g., A* Search). |
| Utility-Based Agent | High | Maximum Expected Utility (MEU) across probabilistic states | Stochastic, partially observable, dynamic | Very High; involves complex probability and matrix calculations. |
| Learning Agent | Very High (Models, weights, replay buffers) | Evolving policies and critic feedback | Unknown, highly dynamic, complex stochastic domains | Extreme; requires heavy parallel processing (GPUs) for training. |
Technical Implementation: Designing Goal-Based Agents
To deeply understand how different agents function in modern AI, let us examine the technical implementation of goal-based agents. These agents rely heavily on state-space search formulations.
A standard formulation of a goal-based problem consists of:
- An initial state (e.g., location coordinates).
- A set of actions applicable in the current state.
- A transition model returning the resulting state given an action.
- A goal test, which determines if a given state is the objective.
- A path cost function, assigning a numeric cost to the path taken.
Below is an abstract Python representation illustrating how a goal-based agent might use an A* (A-Star) search heuristic to process percepts, evaluate different future paths, and determine the optimal sequence of actions.
import heapq
class Node:
def __init__(self, state, parent=None, action=None, path_cost=0, heuristic_cost=0):
self.state = state
self.parent = parent
self.action = action
self.path_cost = path_cost
self.total_cost = path_cost + heuristic_cost
# Required for heapq priority queue sorting
def __lt__(self, other):
return self.total_cost < other.total_cost
class GoalBasedAgent:
def __init__(self, problem_domain, heuristic_function):
self.problem = problem_domain
self.heuristic = heuristic_function
self.action_plan = []
def formulate_plan(self, initial_state, goal_state):
frontier = []
explored = set()
# Initialize the frontier with the starting state
start_node = Node(
state=initial_state,
heuristic_cost=self.heuristic(initial_state, goal_state)
)
heapq.heappush(frontier, start_node)
while frontier:
current_node = heapq.heappop(frontier)
# Goal Test
if self.problem.is_goal(current_node.state, goal_state):
return self.extract_actions(current_node)
explored.add(current_node.state)
# Generate and evaluate different possible actions
for action, child_state, step_cost in self.problem.get_successors(current_node.state):
if child_state not in explored:
child_node = Node(
state=child_state,
parent=current_node,
action=action,
path_cost=current_node.path_cost + step_cost,
heuristic_cost=self.heuristic(child_state, goal_state)
)
heapq.heappush(frontier, child_node)
return [] # Failure to find a plan
def extract_actions(self, node):
actions = []
while node.parent is not None:
actions.append(node.action)
node = node.parent
return actions[::-1] # Reverse to get the chronological sequence
In this architecture, the agent does not impulsively react to the environment. Instead, upon receiving a percept that necessitates action, the agent builds a search tree mapping out different permutations of the future. It relies on the heuristic function—estimating the cost to reach the goal—to intelligently prune the search space and avoid a combinatorial explosion.
Scaler Masterclasses
Learn from industry experts and accelerate your career with hands-on, interactive sessions.
The Evolution of Agents: Large Language Models (LLMs) and Multi-Agent Systems
While classical definitions laid out by Stuart Russell and Peter Norvig focused heavily on strictly numerical state spaces and discrete logic grids, modern engineering has expanded the definition of agents through Large Language Models (LLMs) and multi-agent coordination frameworks.
LLM-Based Autonomous Agents
Today, developers leverage frameworks like LangChain and LlamaIndex to build modern goal-based agents where an LLM serves as the central reasoning engine (the brain). By employing paradigms such as the ReAct (Reasoning and Acting) framework, these agents are given an objective, and they iteratively “think” about what to do, select a tool (actuator) from a given toolset (e.g., executing a SQL query, scraping a webpage, calling an external API), observe the response, and generate the next step until the goal is achieved.
Multi-Agent Systems (MAS)
In enterprise AI architectures, relying on a single agent to handle complex workflows is highly inefficient. Multi-agent systems comprise several different, specialized agents operating within the same environment. For example, a software engineering multi-agent system might include:
- A Product Manager Agent: A goal-based agent tasked with turning a user prompt into a sequential list of Jira tickets.
- A Developer Agent: A utility-based agent tasked with writing Python code that fulfills the tickets while minimizing code execution latency.
- A Quality Assurance Critic Agent: A learning agent that analyzes the developer’s output, runs unit tests, and iteratively provides feedback.
The same coordination logic applies in customer-facing industries. An AI voice agent for healthcare manages patient intake calls, extracts structured data, routes it to a scheduling agent, and triggers follow-up reminders at each handoff, handled automatically across the pipeline.
These agents coordinate via message-passing protocols. Designing multi-agent systems requires engineers to solve complex problems related to game theory, Nash equilibria, and distributed state syn
Frequently Asked Questions (FAQ)
What is the primary difference between a simple reflex agent and a model-based reflex agent?
The core difference lies in state retention. A simple reflex agent evaluates only the instantaneous percept data; it has zero memory. A model-based reflex agent maintains an internal memory (state) that tracks variables outside of its current sensors based on transition models, allowing it to function effectively in partially observable environments.
Can an AI system utilize multiple different types of agent architectures simultaneously?
Yes. In modern AI systems, architectures are heavily layered. An autonomous vehicle acts as a complex Learning Agent at a macro level, updating its driving policies overnight. However, its immediate collision-avoidance braking system is a Simple Reflex Agent, executing an instantaneous hardware override when proximity sensors detect an imminent collision.

How do utility-based agents calculate maximum expected utility under uncertainty?
Utility-based agents utilize Markov Decision Processes (MDPs). To evaluate the best action, they apply the Bellman Equation to calculate the value of different states. In plain text formulation, the optimal value of a state V(s) is calculated as: V(s) = max_a Σ P(s’|s,a) [ R(s,a,s’) + γ V(s’) ] Where a is the action, P(s’|s,a) is the transition probability of reaching state s’, R is the immediate reward, and γ (gamma) is the discount factor for future utility.
Are goal-based agents capable of machine learning?
By strict classical definition, a pure goal-based agent does not learn; it simply calculates optimal paths based on pre-programmed transition models and heuristics. However, an agent can be a hybrid—a Goal-Based Learning Agent—where its transition model or search heuristic is continuously optimized via a learning element and critic system, allowing it to solve goal states faster over successive iterations.