
Roughly 34 million AI images get generated every day across Midjourney, DALL-E, Stable Diffusion, and the rest, which means somewhere out there, right now, someone is asking for “a cat but make it epic” and then wondering why the result looks nothing like what was in their head.
Prompt engineering for text-to-image models is just the practice of writing prompts that actually describe what you want clearly enough for the model to get there, structured subject, details, style, lighting, composition, and the technical parameters that fine-tune the result.
None of this is about finding a magic incantation. There isn’t one, despite what half the “100 secret prompts” listicles out there would have you believe. It’s closer to writing a really specific creative brief for someone who’s extremely capable, weirdly literal, and has never seen the inside of your head.
This guide covers how these models actually read your prompt (briefly, no maths), what a well-structured prompt looks like, the practices that consistently help, negative prompts and the parameters worth knowing, before-and-after rewrites, a troubleshooting table for when the output and the prompt clearly disagree, and a template you can reuse across tools. If you want the broader context first, Scaler’s prompt engineering page covers the concept beyond just images.
How Text-to-Image Models Interpret Your Prompt
You don’t need to understand diffusion math to write good prompts, but a rough mental model helps explain why some things work and others quietly don’t.
Your text prompt first gets converted into a numerical representation, an embedding, that captures meaning rather than exact wording. The model then starts from an image that’s essentially pure visual noise and gradually “denoises” it over many steps, nudging the pixels at each step toward something that matches your prompt’s embedding. This is the diffusion process that underlies Stable Diffusion, and the original latent diffusion paper is the technical root of most of what’s running under the hood today, including, in spirit, the architectures behind Midjourney and DALL-E.
A few things fall out of this naturally. First, the model is matching overall meaning, not parsing your prompt like a checklist, so vague or contradictory phrases get “averaged” in ways that can look odd. Second, words near the front of the prompt tend to carry more weight in most tools, which is why subject-first ordering matters. And thirdly, the model has no idea what you meant, only what you wrote, so “a person” with no other description is a coin flip on basically everything about that person.
The Anatomy of a Strong Image Prompt
Strong prompts tend to follow a loose but consistent structure: subject, then key descriptors, then setting and composition, then style and medium, then lighting and mood, then any technical parameters. You don’t need every category every time, but skipping straight from “subject” to “parameters” is how you end up with a technically correct image of absolutely the wrong thing.
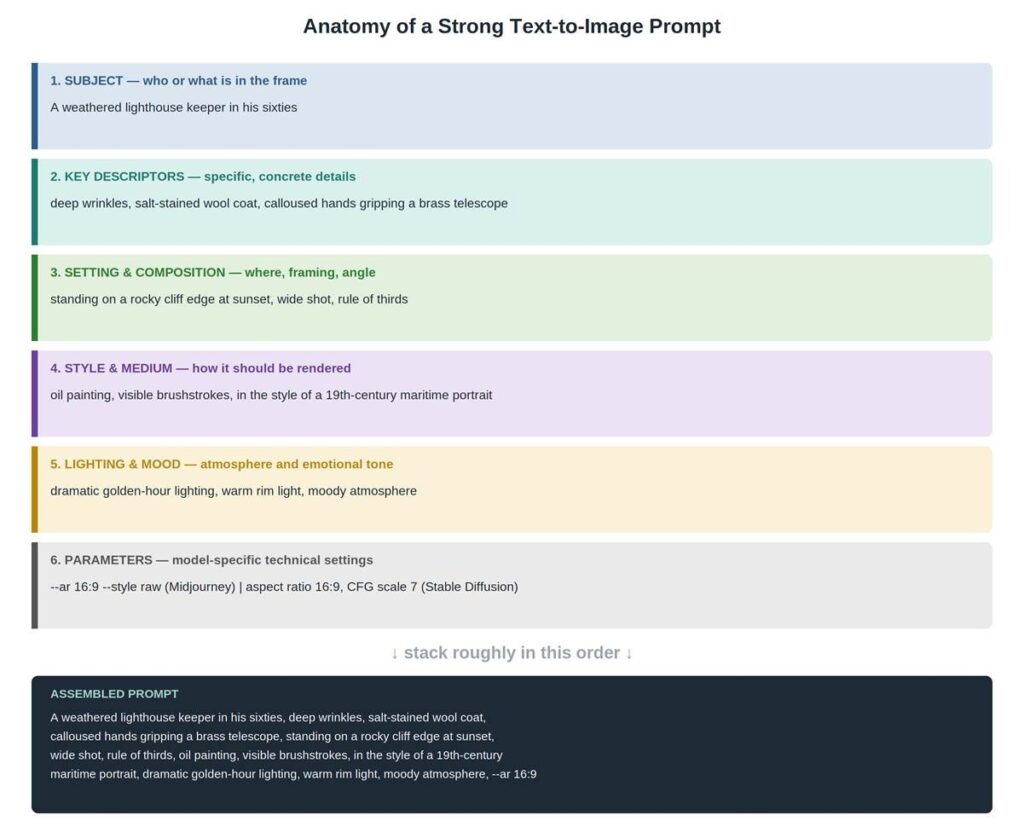
Notice that the “assembled” version at the bottom isn’t dramatically longer than a vague one-liner, it’s just specific in the right places. “A portrait of an old sailor” and the lighthouse keeper prompt above are roughly the same length to type, and one of them gives the model almost nothing to work with. For more on how this connects to generative AI concepts more broadly, Scaler’s generative AI overview is a useful companion read.
Best Practices and Pro Techniques
These are the habits that consistently move prompts from “close enough, I guess” to “yes, that’s the one.” None of them are exotic, which is sort of the point.
• Be specific, not just descriptive: “red dress” and “deep crimson silk slip dress with a frayed hem” both describe a dress, but only one of them gives the model a fighting chance of matching what’s in your head.

• Put the important stuff first: most tools weight earlier tokens more heavily, so lead with the subject and the details you absolutely care about, and push “nice to have” style flourishes toward the end.
• Name a style or reference, don’t just describe a vibe: “moody and atmospheric” is doing a lot of unpaid work; “in the style of film noir cinematography, high contrast, deep shadows” gives the model something concrete to anchor to.
• Iterate in small steps: change one or two things between generations (lighting, then composition, then style) rather than rewriting the whole prompt each time, otherwise you can’t tell what actually moved the needle.
• Use seeds for consistency: if you liked a result and want variations on it rather than a totally different image, lock the seed and change smaller details around it. Most tools expose this as a –seed or similar parameter.
• Lean on reference images where the tool supports it: for consistent characters or styles across a set, an image prompt or style reference usually does more than any amount of extra adjectives ever will.
For the underlying “why,” a lot of this maps onto general patterns from artificial intelligence and how these models are trained, models learn associations from captioned image datasets, so prompts that read like plausible captions (specific, descriptive, in roughly natural language) tend to land closer to what’s in the training distribution, and therefore closer to what you’re picturing.
Using Negative Prompts and Parameters
Beyond the words describing what you want, most tools give you a second layer of control: negative prompts (what to avoid) and parameters (technical knobs). These aren’t optional extras once you’re past the casual-tinkering stage, they’re where a lot of the “why does it keep adding extra fingers” problems actually get solved.
A negative prompt tells the model what to steer away from, separate from the main description. If your portraits keep coming out with mangled hands, blurry backgrounds, or text watermarks that don’t exist anywhere in your prompt (yes, that happens), a negative prompt like “extra fingers, blurry, watermark, text, deformed” often cleans things up more reliably than rewording the main prompt again.
| Parameter | What It Controls | Typical Use |
| Negative prompt | Concepts, objects, or qualities to actively avoid | Removing common artefacts (extra limbs, watermarks, blur) or unwanted elements (“no text, no people in background”) |
| Aspect ratio | Width-to-height shape of the output | 16:9 for banners/wallpapers, 1:1 for social posts, 2:3 for portraits or print |
| CFG / guidance scale | How strictly the model follows the prompt vs. its own “creativity” | Lower values (~3-6) for looser, more artistic results; higher (~8-12) for closer prompt adherence |
| Seed | The starting noise pattern for generation | Lock it to reproduce or make small variations on a result you liked |
| Prompt weighting | Emphasis on specific words or phrases | Used to push certain elements (e.g., a specific colour or object) to dominate more, syntax varies by tool |
Per-tool quirks worth knowing: Midjourney leans on flags like –ar, –seed, and –style, and documents these in its own prompt reference. Stable Diffusion-based tools usually expose CFG scale, sampler choice, and step count as separate sliders rather than inline flags. DALL-E, through OpenAI’s image API and ChatGPT, leans more on natural-language prompting and tends to need fewer technical parameters, at the cost of slightly less fine-grained control. None of these are better in some absolute sense, they just trade control for convenience differently. If you want the underlying language-model concepts that prompt structure borrows from, Scaler’s large language models page is a relevant detour.
Before & After: Fixing Weak Prompts
Here’s where the structure from earlier actually earns its keep. Same intent, very different odds of getting what you wanted.
1. The “too vague to mean anything” prompt
• Before: “a futuristic city”
• After: “a dense futuristic city skyline at dusk, neon signage in Japanese and English, rain-slicked streets reflecting light, cyberpunk illustration, wide-angle, cinematic lighting”
“Futuristic city” could mean anything from a clean Scandinavian utopia to a Blade Runner knockoff, and the model will pick essentially at random. The rewrite removes that randomness by naming the era, mood, lighting, and composition.
2. The “everything, everywhere, all at once” prompt
• Before: “a beautiful epic amazing dragon fantasy magical landscape masterpiece 8k highly detailed”
• After: “a red dragon perched on a crumbling stone tower, overlooking a misty mountain valley at dawn, fantasy concept art, dramatic backlighting, painterly digital style”
The “before” version is mostly filler words that every image generator has seen a billion times and that don’t actually describe anything. “8k” and “masterpiece” aren’t doing what people think they’re doing, they’re close to noise. The rewrite swaps adjectives for an actual scene.
3. The “forgot the medium exists” prompt
• Before: “a woman drinking coffee by a window”
• After: “a woman in her 30s drinking coffee by a rain-streaked window, soft natural morning light, 35mm film photography, shallow depth of field, candid mood”
Without a medium, the model defaults to whatever’s statistically most common for that phrase, which is often a generic, slightly stock-photo-ish illustration. Naming the medium and a few camera-like terms (focal length, depth of field) nudges it toward a specific visual language.
4. The “fighting itself” prompt
• Before: “a minimalist, ultra-detailed, busy but simple poster design”
• After: “a minimalist poster design, large negative space, single bold geometric shape as focal point, muted two-colour palette, clean sans-serif typography”
“Minimalist” and “ultra-detailed, busy” are directly opposed, so the model splits the difference into something that’s neither, which is the visual equivalent of a meeting that ends with no decision. Pick a direction and describe that direction specifically.
Why Your AI Images Don’t Match Your Prompt (Troubleshooting)
When the output and the prompt clearly aren’t on speaking terms, it’s rarely because the model is “broken.” It’s almost always one of a handful of patterns.
| Symptom | Likely Cause | Quick Fix |
| Image looks generic, ignores key details | Prompt too short or vague, important details buried at the end | Move key details earlier; replace vague adjectives with concrete, specific ones |
| Wrong style entirely (e.g. asked for photo, got illustration) | No explicit medium specified, or conflicting style terms | Name the medium directly (“photograph,” “3D render,” “watercolour painting”) early in the prompt |
| Extra limbs, mangled hands, distorted faces | Common diffusion artefact, not addressed by the prompt | Add a negative prompt targeting these terms; try a different sampler or model version if it persists |
| Composition or framing is off (cropped subject, wrong angle) | No composition guidance given, model defaults to its own bias | Add explicit framing terms: “wide shot,” “close-up,” “centered composition,” “full body” |
| Same result every time, no useful variation | Seed locked when you didn’t mean to, or prompt too rigid | Unlock or randomize the seed; vary one descriptive element at a time |
| Text in the image is garbled or nonsensical | Most diffusion models are weak at rendering legible text | Avoid relying on the model for text; add it in post-production, or use a tool with dedicated text rendering |
A Reusable Text-to-Image Prompt Framework
Once the anatomy above feels familiar, it collapses into a template you can fill in for almost anything, tool-agnostic, copy-paste, adjust as needed:
[Subject], [key descriptors], [setting/composition], [style/medium], [lighting/mood] [– parameters]
Before hitting generate, a quick checklist:
• Does the subject line read like an actual scene, not just a noun?
• Have I named a medium or style, or am I letting the model guess?
• Are any descriptors contradicting each other (minimalist vs. busy, realistic vs. cartoon)?
• If results have unwanted artefacts, do I have a negative prompt addressing them?
• Have I set an aspect ratio appropriate for where this image is going?
• If I liked a previous result, have I noted the seed before changing anything?
Worth saying plainly: getting genuinely good at this is less about memorising magic phrases and more about developing an eye, for composition, lighting, and style language, that transfers across tools and even into other generative AI work. If that’s the direction you’re heading, Scaler’s courses and Academy programs cover generative AI and the broader machine learning and deep learning foundations underneath it, useful context even if your goal is purely creative rather than technical.
The FAQs
Q1. What is the best practice for prompting text-to-image models?
Structure the prompt as subject, then specific descriptors, then setting and composition, then style or medium, then lighting and mood, followed by any technical parameters. Be concrete rather than vague, name a medium explicitly, and avoid stacking contradictory adjectives like “minimalist but detailed.”
Q2. What is a negative prompt and when should I use one?
A negative prompt lists things the model should avoid, separate from the main description, things like “blurry, extra fingers, watermark, text.” Use one whenever results keep showing the same unwanted artefacts or elements that aren’t in your prompt at all but keep showing up anyway.
Q3. How do I get consistent characters or styles across images?

Lock the seed from a result you liked and vary only smaller details for related images. Where the tool supports it, reference-image or image-prompt features (uploading an existing image as a style or character anchor) usually do more for consistency than prompt wording alone.
Q4. Why doesn’t the image match my prompt?
The most common causes are a prompt that’s too vague or has important details buried at the end, no explicit medium or style specified, contradictory descriptors, or a locked seed producing the same result repeatedly. The troubleshooting table above maps specific symptoms to fixes.
Q5. Which model is best for beginners?
There isn’t a single “best,” it depends on what you’re optimising for. DALL-E (via ChatGPT) tends to be the most forgiving for natural-language prompts and needs the fewest technical parameters. Midjourney generally produces strong aesthetics with relatively short prompts but runs on Discord and has its own flag syntax. Stable Diffusion-based tools offer the most control (and the steepest learning curve), and power roughly 80% of all AI-generated images by some estimates, largely because the underlying model is open and widely deployed across countless interfaces.