



AI agents are autonomous software programs driven by artificial intelligence that perceive their environment, make decisions using computational models or large language models (LLMs), and execute actions to achieve specific goals. They bridge the gap between passive data processing and active, goal-oriented system execution.
What Is an AI Agent? Defining the Paradigm Shift
In traditional software engineering, applications follow deterministic, rules-based logic. An engineer defines explicit control flows (if-then-else structures) to handle every anticipated system state. However, as software systems interface with increasingly complex, unstructured, or volatile environments, deterministic paradigms become computationally brittle. This is precisely what necessitates the evolution of the AI agent.
An AI agent is a stateful, autonomous entity that leverages a foundational machine learning model—typically a Large Language Model (LLM) or a Reinforcement Learning (RL) policy network—as its core reasoning engine. Instead of merely generating text or predicting the next token in a sequence, an AI agent operates iteratively within a closed-loop system. It observes its environment, reasons about its current state relative to a predefined goal, formulates a multi-step plan, invokes external tools (like APIs, databases, or code interpreters), and evaluates the outcome of those actions.
Understanding what defines an AI agent requires distinguishing between “intelligence” and “agency.” Intelligence refers to the model’s capacity to comprehend context, solve algorithmic problems, or classify data. Agency, on the other hand, refers to the model’s authorization and capability to alter the state of the world around it without human intervention. By granting an AI system read/write access to external environments, developers transform a passive oracle into an active agent.
Core Architecture: How Do AI Agents Work?
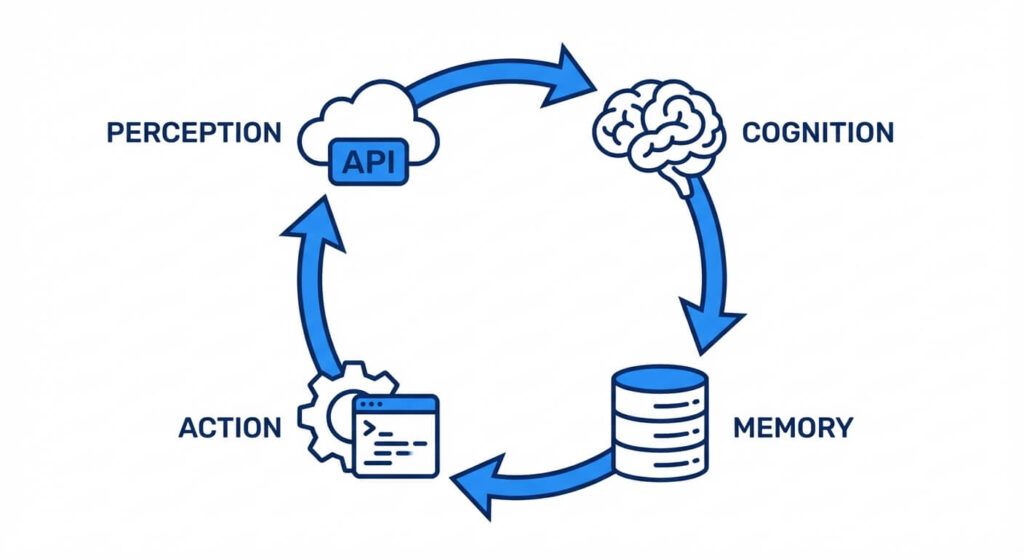
To comprehensively answer how do ai agents work, one must examine their internal architecture. Modern AI agents are built upon a cyclical framework heavily inspired by cognitive architectures and control theory. The fundamental operational loop consists of four primary pillars: Perception, Cognition, Memory, and Action.
1. Perception (State Observation)
Perception is the mechanism through which an agent receives input from its environment. In traditional robotic agents, perception involves physical sensors (LiDAR, cameras). In software engineering and LLM-based agents, perception relies on digital telemetry. The agent ingest states via API responses, user prompts, system logs, or web scraping.
When an agent executes an API call, the JSON payload returned is the “observation.” The system parses this unstructured or semi-structured data into a formatted state representation that the cognitive engine can process.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification



2. Cognition (Reasoning and Planning)
The cognitive engine acts as the central processing unit. It processes the perceived data, aligns it with the ultimate objective, and determines the next optimal step. In modern systems, this is where techniques like ReAct (Reason + Act) are deployed.
The ReAct framework forces the LLM to output an internal monolog (Thought) before it outputs an actionable command. This explicit reasoning phase allows the agent to break down complex heuristics into directed acyclic graphs (DAGs) of sub-tasks. Advanced agents utilize sophisticated planning algorithms, such as Tree of Thoughts (ToT) or Monte Carlo Tree Search (MCTS), to explore multiple potential action pathways, evaluate their probable outcomes, and backtrack if a particular logic branch proves suboptimal.
3. Memory (Context and State Retention)
Standard LLMs are stateless; they possess no inherent memory between isolated inference requests. AI agents require robust memory architectures to maintain context over prolonged execution loops. Memory is typically stratified into two categories:
- Short-Term Memory: This relies on the core LLM context window (e.g., 128k tokens). It stores the immediate history of the current interaction loop, including the original prompt, the sequence of executed tools, and the immediate observations.
- Long-Term Memory: This relies on external vector databases (such as Pinecone, Milvus, or pgvector). Information, past experiences, and large datasets are converted into high-dimensional vectors (embeddings). When the agent requires historical context, it performs a similarity search. For example, the agent uses cosine similarity to find relevant past experiences: cos(θ) = (A · B) / (||A|| ||B||).
4. Action (Tool Execution and Environmental Modification)
An agent’s utility is strictly bound by its action space. Actions are manifested through “tools,” which are strictly defined functions the agent can invoke. Developers provide the agent with a schema (often an OpenAPI specification or a JSON Schema) detailing what the tool does, what parameters it requires, and what data types it accepts.
When the cognitive engine decides to take an action, it generates a structured payload (e.g., a JSON object) matching the tool’s signature. A deterministic middleware layer parses this output, securely executes the corresponding Python function or REST API call, and feeds the resulting output back into the agent’s perception module, initiating the next iteration of the loop.
Categorization: What Types of AI Agents Exist?
The classification of AI agents stems from classical artificial intelligence texts, notably Russell and Norvig’s categorization, which remains highly applicable to modern engineering frameworks. The complexity of the agent dictates its classification.
Simple Reflex Agents
These are the most primitive agents. They operate purely on a condition-action rule base without considering the broader history of the environment. If condition X is met, execute action Y. They do not maintain an internal state and are highly susceptible to infinite loops if the environment is only partially observable.
Model-Based Reflex Agents
These agents maintain an internal state that depends on the history of their observations. They possess a “model” of how the world works and how their actions impact the world. By tracking the evolving state, they can handle partially observable environments and make decisions based on the current context combined with historical data.
Goal-Based Agents
Expanding upon model-based architectures, goal-based agents are provided with explicit objective functions. Instead of merely reacting to state changes, they project future states and evaluate whether a specific sequence of actions will move them closer to their target. Search algorithms and planning frameworks are heavily utilized here.
Utility-Based Agents
While goal-based agents only distinguish between binary states (goal achieved vs. goal not achieved), utility-based agents measure the quality of the state. They utilize a mathematical utility function to map a state to a real number, representing the degree of satisfaction or efficiency. If multiple paths lead to a goal, a utility-based agent will calculate which path maximizes performance (e.g., minimizing token usage, reducing API latency, or maximizing financial return).
Learning Agents
Learning agents are designed to operate in unknown environments and become more competent over time. They consist of a performance element (which selects actions), a learning element (which updates the agent’s logic based on feedback), and a critic (which evaluates how well the agent is doing against fixed performance standards). In the context of LLM agents, this is often implemented via automated fine-tuning, dynamic few-shot prompt optimization, or Reinforcement Learning from Task Feedback (RLTF).
Architectural Comparison: AI Agents vs. Standard LLMs
To solidify what differentiates these systems, engineers must understand the architectural boundaries. Standard LLMs are autoregressive models designed to predict the next token. Agents are wrapper architectures that embed the LLM within an orchestration layer.
| Feature | Standard LLM | AI Agent System |
|---|---|---|
| State Management | Stateless by default. Relies entirely on the user to provide the context within the prompt payload. | Stateful. Manages its own memory stores (Short-term context arrays and long-term vector embeddings). |
| Execution Flow | Linear and single-turn. Generates output and terminates the process immediately. | Cyclic and multi-turn. Engages in continuous loops (Observation -> Thought -> Action) until a termination condition is met. |
| Environment Interaction | Passive. Cannot alter the external world. Operates purely in a sandbox of text generation. | Active. Can execute API calls, run SQL queries, modify file systems, and interact with external software. |
| Error Handling | Prone to hallucination without self-correction. If an answer is wrong, it remains wrong. | Self-correcting. If an action fails (e.g., API returns a 404), the agent observes the error and reformulates an alternative strategy. |
| Autonomy Level | Zero autonomy. Strictly acts as a sophisticated text-completion function. | High autonomy. Capable of autonomous task decomposition, tool selection, and goal pursuit. |
Mathematical Foundations of Agentic Behavior
Beneath the natural language capabilities of modern agents lie robust mathematical frameworks derived from Reinforcement Learning (RL) and Decision Theory. Understanding what drives an agent’s logic requires a foundational grasp of Markov Decision Processes (MDP).
An MDP provides a mathematical framework for modeling decision-making in situations where outcomes are partly random and partly under the control of a decision-maker (the agent). An MDP is formally defined by a tuple: (S, A, P, R, γ).
- S: A finite set of states (the environment).
- A: A finite set of actions (the tools available to the agent).
- P: A state transition probability matrix. P(s’|s, a) represents the probability that taking action ‘a’ in state ‘s’ will lead to state ‘s’.
- R: A reward function. R(s, a, s’) is the immediate reward received after transitioning from state ‘s’ to state ‘s’ via action ‘a’.
- γ: The discount factor (0 ≤ γ ≤ 1), which determines the present value of future rewards.
The objective of an optimal agent is to find a policy, denoted by π, that specifies the action π(s) that the agent will choose when in state ‘s’. The goal is to maximize the expected cumulative reward. This is often solved using the Bellman Equation, which calculates the optimal value function V(s):
V(s) = max_a ( R(s,a) + γ Σ P(s’|s,a) V(s’) )
In the realm of LLM agents, explicit MDPs are not always manually coded. Instead, the LLM approximates the policy π through its pre-trained weights, leveraging semantic understanding to predict the action ‘a’ that maximizes the conceptual “reward” (i.e., successfully answering the user’s prompt). However, when fine-tuning agents via Proximal Policy Optimization (PPO), these exact mathematical principles govern the gradient updates.
Implementing a Basic AI Agent in Python
To demystify what goes into building an AI agent, we will construct a simplified ReAct (Reason + Act) loop in Python. This implementation eschews heavy orchestration libraries (like LangChain or LlamaIndex) to expose the raw mechanics of the observation-thought-action loop.
The agent will possess a simple tool—a mathematical evaluator—and will decide autonomously when to use it based on the system prompt and user input.
import re
import json
import openai
# Define a strict system prompt to enforce the ReAct framework
SYSTEM_PROMPT = """
You are an autonomous AI agent capable of logical reasoning and executing tools.
You run in a loop of Thought, Action, PAUSE, Observation.
At the end of the loop you output an Answer.
Use Thought to describe your reasoning.
Use Action to run one of the available tools. Action format MUST be:
Action: {"tool_name": "calculate", "arguments": {"expression": "math_string"}}
Observation will be provided by the system.
Available tools:
- calculate: Evaluates a mathematical expression.
"""
def calculate(expression: str) -> str:
"""A simple deterministic tool for the agent to use."""
try:
# Warning: eval is used here for demonstration purposes only.
# In production, use AST parsing or secure sandboxes.
result = eval(expression)
return str(result)
except Exception as e:
return f"Error evaluating expression: {e}"
# Tool registry maps string names to callable Python functions
TOOL_REGISTRY = {
"calculate": calculate
}
def execute_agent(user_query: str, max_iterations: int = 5) -> str:
messages = [
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": user_query}
]
for iteration in range(max_iterations):
# 1. Cognition Phase (Generate Thought and Action)
response = openai.ChatCompletion.create(
model="gpt-4",
messages=messages,
temperature=0.0
)
agent_reply = response.choices[0].message['content']
messages.append({"role": "assistant", "content": agent_reply})
print(f"--- Iteration {iteration + 1} ---")
print(agent_reply)
# Check if the agent wants to take an action
action_match = re.search(r"Action:\s*(\{.*\})", agent_reply)
if action_match:
# 2. Action Phase (Parse and execute the tool)
action_payload = action_match.group(1)
try:
action_data = json.loads(action_payload)
tool_name = action_data.get("tool_name")
arguments = action_data.get("arguments", {})
if tool_name in TOOL_REGISTRY:
# Execute the selected tool
observation = TOOL_REGISTRY[tool_name](**arguments)
else:
observation = f"Error: Tool '{tool_name}' not found."
except json.JSONDecodeError:
observation = "Error: Invalid JSON payload provided for Action."
# 3. Perception Phase (Feed the result back to the LLM)
formatted_observation = f"Observation: {observation}"
messages.append({"role": "user", "content": formatted_observation})
print(f"> {formatted_observation}\n")
else:
# If no action is taken, assume the agent has reached a conclusion
print("\nFinal Answer Reached.")
return agent_reply
return "Error: Agent exceeded maximum iterations."
# Example Usage
if __name__ == "__main__":
query = "What is the square root of 144 multiplied by 15?"
execute_agent(query)
In this architecture, the LLM acts purely as the cognitive routing engine. The Python while-loop provides the autonomous control flow, parsing the LLM’s text to trigger deterministic code (calculate), and formatting the output back into a string the LLM can process. This tight integration of probabilistic language generation and deterministic code execution is the hallmark of modern agentic engineering.
Enterprise Use Cases and Engineering Applications
AI agents are rapidly moving from research environments into enterprise production stacks. Their ability to autonomously navigate complex systems makes them invaluable for high-friction engineering tasks.
Autonomous Software Development
Agents like SWE-agent or Devin are engineered to resolve GitHub issues autonomously. They are equipped with code interpreters, shell access, and IDE integration. They can read a bug report, navigate a repository, formulate a fix, run unit tests (observing the stack trace if tests fail to iteratively correct their code), and submit a final pull request.
Dynamic Cybersecurity Defense
In cybersecurity, multi-agent systems are deployed to monitor network traffic. Instead of relying on static signature-based detection, security agents dynamically analyze anomalous behavior. If a breach is suspected, the agent can autonomously query firewall logs, trace IP origins, and execute quarantine protocols on infected subnets, drastically reducing the Mean Time to Respond (MTTR).
Data Engineering and Orchestration
Data pipelines often fail due to schema changes or corrupted payloads. Data agents integrated into orchestration tools (like Apache Airflow) can automatically detect pipeline failures, query database schemas to identify what changed, formulate SQL patches, and backfill missing data partitions without waking an on-call data engineer.
Limitations and Engineering Challenges
While highly capable, AI agents introduce significant engineering challenges that must be addressed before deployment into mission-critical systems.
- Context Fragmentation and Forgetting: As an agent’s reasoning loop grows, the token count increases. If the loop exceeds the LLM’s context window, early observations are truncated, leading to “amnesia.” Vector memory mitigates this, but retrieval-augmented generation (RAG) is prone to retrieving noisy, irrelevant embeddings.
- Infinite Action Loops: Without strict programmatic guardrails or maximum iteration limits, an agent may repeatedly attempt a failing tool call. For example, if a database requires a specific date format, and the agent continues to supply the wrong format, it will burn through token budgets rapidly.
- Security and Sandboxing (Prompt Injection): Because agents execute code and interact with APIs, they are highly vulnerable to indirect prompt injections. If an agent scrapes a webpage containing a malicious payload designed to trick the LLM, the agent might autonomously execute destructive commands (e.g., dropping database tables or exfiltrating API keys). Strict isolation (Dockerized sandboxes) and least-privilege IAM roles are mandatory.
- Non-Deterministic Outcomes: Software engineers rely on reproducible behavior. Due to the inherent stochasticity of LLMs (even at temperature 0.0, floating-point math on GPUs can introduce minor variances), agents may occasionally traverse different reasoning paths for identical inputs. This makes comprehensive unit testing exceedingly difficult.
Frequently Asked Questions (FAQ)
What is the difference between an AI agent and a multi-agent system?
A single AI agent operates independently to solve a task. A multi-agent system (MAS) involves several distinct agents—often equipped with different personas, prompts, or specialized tools—interacting with one another. Frameworks like AutoGen or CrewAI enable MAS architectures where one agent might write code, a second agent reviews it, and a third agent executes the testing suite, facilitating complex, collaborative workflows.
How do AI agents handle hallucinated tool calls?
Hallucination is a primary failure mode where the LLM attempts to use a tool that does not exist or provides fabricated parameters. Engineers mitigate this by enforcing strict JSON schema validation (using tools like Pydantic). If the agent’s output fails validation, the middleware intercepts the error and returns a formatted prompt to the agent explaining the schema violation, forcing the agent to self-correct in the next loop.
What role do embeddings and vector similarity play in an agent’s architecture?
Embeddings are numerical representations of text. Vector similarity allows agents to perform semantic searches over massive datasets without loading the entire dataset into the context window. When an agent needs to remember “what happened last time I saw this error,” it converts the error into a vector, queries the database for the closest matching vectors in its history, and retrieves only the most relevant historical context to inform its current decision.
Can AI agents operate entirely offline?
Yes. While most commercial agents rely on proprietary cloud models (like GPT-4 or Claude 3), agents can be built using open-source models (such as Llama 3 or Mistral) running entirely on local hardware. By coupling a local LLM with local tools and vector stores, engineers can create fully air-gapped AI agents suitable for highly secure, restricted enterprise environments.