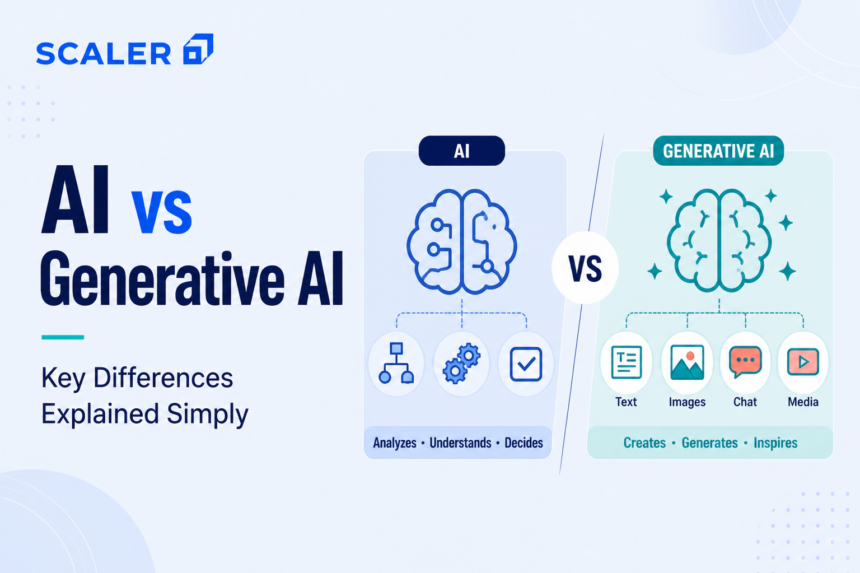
AI vs Generative AI: Key Differences Explained Simply
The primary difference between AI and generative AI lies in their fundamental objectives. Traditional AI analyzes existing data to identify patterns, make predictions, or classify information. Generative AI, a specialized subset of artificial intelligence, utilizes advanced neural networks to create entirely new content, such as text, code, or images, by learning the underlying data distribution.
Introduction to the Artificial Intelligence Landscape
In the modern software engineering ecosystem, the umbrella term “Artificial Intelligence” encompasses a vast array of computational methodologies often detailed in an Artificial Intelligence Syllabus.. From the earliest rule-based expert systems to the complex neural network architectures powering modern applications, the field has undergone massive paradigm shifts. For decades, the industry focus remained firmly on narrow, task-specific intelligence—an area yielding a high Artificial Intelligence Salary in today’s market.—algorithms designed to parse historical data, identify correlations, and output a specific classification or numerical prediction.
However, the advent of transformer architectures and large-scale foundation models has redefined the boundaries of computational capabilities. We have transitioned from an era where machines strictly analyzed the world to an era where they can autonomously synthesize novel representations of it. Understanding the difference between AI and generative AI is no longer merely an academic exercise; it is a critical architectural consideration for those on an AI Engineer Roadmap and data scientists, and system designers tasked with building robust, scalable, and intelligent applications. This comprehensive guide explores the technical distinctions, underlying mathematical frameworks, and architectural differences that separate traditional machine learning paradigms from generative models.
Understanding Artificial Intelligence (Traditional AI)
Traditional artificial intelligence, often categorized as Discriminative AI or Narrow AI, refers to systems engineered to perform specific, predefined tasks based on programmed rules or learned historical patterns. Unlike systems that create new artifacts, traditional AI models act as analytical engines. They map inputs to discrete outputs. When you build a spam filter, a recommendation engine, or a computer vision model for defect detection, you are leveraging traditional AI methodologies.
At a mathematical level, traditional AI primarily relies on discriminative modeling. These models attempt to learn the boundary that separates different classes of data. They model the conditional probability P(Y|X)—the probability of a specific label or outcome (Y) given a set of input features (X). Because the focus is strictly on the decision boundary rather than how the data itself was generated, discriminative models are highly efficient, requiring less computational overhead for inference and operating with high deterministic accuracy.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification



How Traditional AI Works: Machine Learning and Deep Learning
Traditional AI is predominantly powered by principles found in a Machine Learning Roadmap and traditional Deep Learning (DL) paradigms. These systems rely on structured learning environments, primarily:
- Supervised Learning: The model is trained on a highly curated, labeled dataset. The algorithm iteratively adjusts its internal parameters (weights and biases) to minimize a predefined loss function, thereby reducing the error between its prediction and the actual ground-truth label.
- Unsupervised Learning: The algorithm ingests unlabeled data and attempts to find hidden structures or clusters, such as grouping customers based on purchasing behavior using algorithms like K-Means or Principal Component Analysis (PCA).
- Reinforcement Learning: The system learns to make a sequence of decisions by interacting with an environment, receiving rewards or penalties based on the actions taken, to maximize a cumulative reward function.
Core Algorithms in Traditional AI
Software engineers utilize a variety of established algorithms to build traditional AI systems, optimizing for latency, accuracy, and computational efficiency:
- Support Vector Machines (SVM): Constructs hyperplanes in multidimensional space to separate distinct classes.
- Random Forests & Decision Trees: Ensemble learning methods that construct multiple decision trees during training and output the mode of the classes for classification or mean prediction for regression.
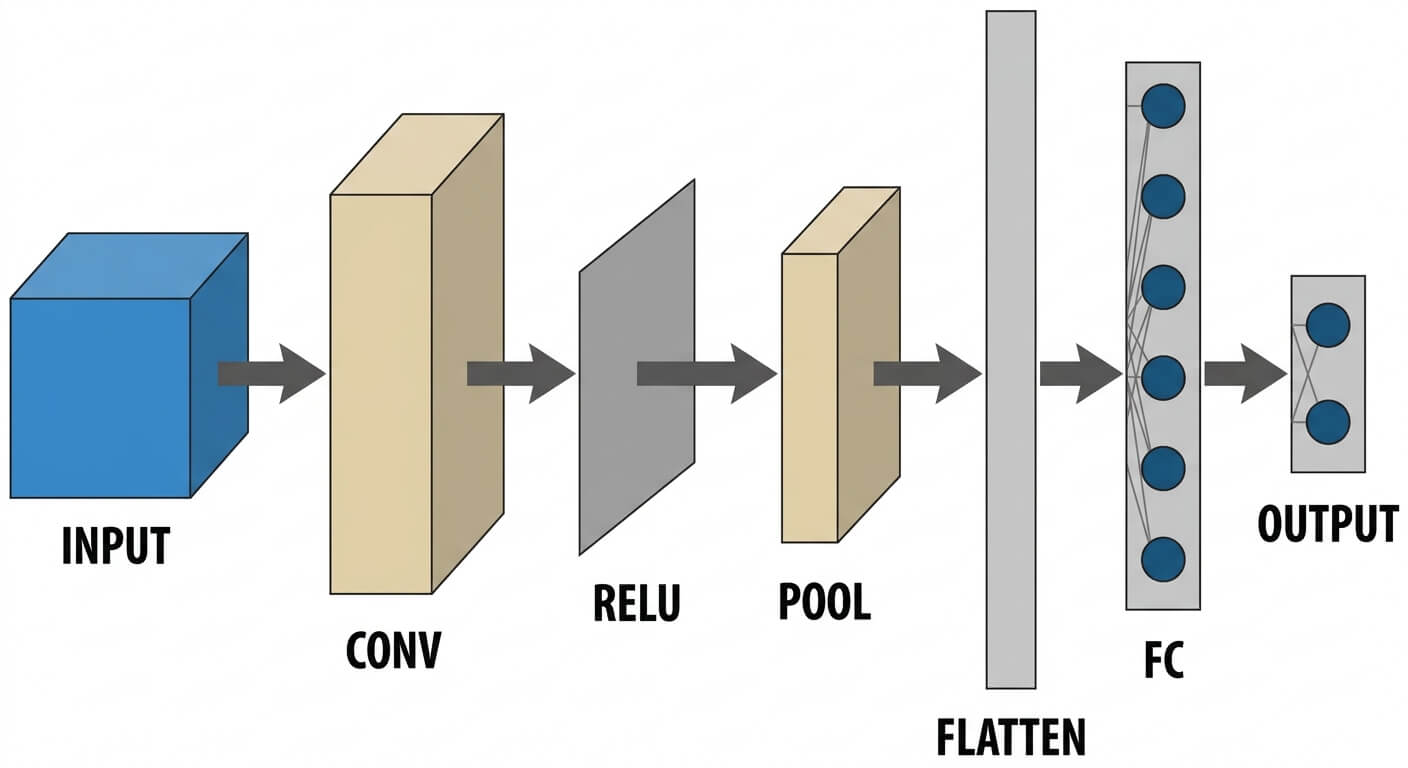
- Convolutional Neural Networks (CNNs): Feed-forward artificial neural networks designed specifically to process pixel data for image recognition and classification tasks.
To illustrate a traditional AI workflow, consider the following Python code using scikit-learn to build a traditional classification model:

from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
# Traditional AI: Analyzing existing data to classify an outcome
# X represents input features (e.g., user session duration, click rate)
# y represents discrete labels (e.g., 1 = converted, 0 = did not convert)
X = np.random.rand(1000, 5)
y = np.random.randint(2, size=1000)
# Splitting data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Instantiating and training a discriminative model
clf = RandomForestClassifier(n_estimators=100, random_state=42)
clf.fit(X_train, y_train)
# Predicting outcomes based on learned patterns
predictions = clf.predict(X_test)
accuracy = accuracy_score(y_test, predictions)
print(f"Traditional AI Classification Accuracy: {accuracy * 100:.2f}%")
Understanding Generative Artificial Intelligence
Generative artificial intelligence represents a paradigm shift from pattern recognition to pattern synthesis as detailed in our Generative AI Roadmap.. Instead of merely categorizing data, generative AI systems are capable of producing novel text, images, audio, video, and computer code. This is achieved by ingesting massive corpora of unstructured data, learning the intricate linguistic or visual rules governing that data, and generating new outputs that probabilistically align with the learned structures.
Unlike traditional AI’s focus on conditional probability, generative AI models focus on joint probability P(X, Y) or entirely on the probability distribution of the data itself, P(X). The goal is to understand the underlying data distribution so thoroughly that the model can sample from it to create synthetic instances that are statistically indistinguishable from the original training data.
Foundation Models and Self-Supervised Learning
The backbone of modern generative AI is the “Foundation Model.” These are massive neural networks trained on vast quantities of unlabeled data at scale. The primary training methodology shifts from supervised learning (requiring expensive human-annotated labels) to Self-Supervised Learning.
In self-supervised learning, the data provides its own supervision. For example, in Natural Language Processing (NLP), the model masks a word in a sentence and attempts to predict it, or it attempts to predict the next sequential token in a sequence. By iterating this process billions of times across terabytes of data, the model develops a profound internal representation of language syntax, semantics, and factual relationships.
Core Architectures in Generative AI
The rapid advancement of generative AI is largely attributed to specific, highly complex neural network architectures:
- Transformers: Introduced in 2017, the Transformer architecture utilizes a mechanism called “Self-Attention,” which allows the model to weigh the importance of different words in a sequence regardless of their positional distance. The standard self-attention mathematical formulation is computed as: Attention(Q, K, V) = softmax(QK^T / √d_k) V. This architecture underpins all modern Large Language Models (LLMs) like GPT-4, LLaMA, and Claude.
- Generative Adversarial Networks (GANs): Consists of two neural networks—a Generator and a Discriminator—locked in a zero-sum game. The Generator creates fake data (e.g., images), while the Discriminator tries to distinguish fake data from real data. The objective is formalized as: min(G) max(D) V(D,G) = E[log D(x)] + E[log(1 – D(G(z)))].
- Variational Autoencoders (VAEs): Probabilistic models that compress input data into a lower-dimensional latent space and reconstruct it, allowing for smooth interpolation and generation of new data points by sampling from this latent space.
To demonstrate how generative AI handles tasks programmatically, here is an example using the Hugging Face transformers library to generate synthetic text:
from transformers import pipeline
# Generative AI: Synthesizing novel content based on learned distributions
# We utilize a pre-trained Transformer model (e.g., GPT-2 for simplicity)
# Initialize the text-generation pipeline
generator = pipeline('text-generation', model='gpt2')
prompt = "The most significant advantage of integrating continuous deployment is"
# The model predicts the most probable sequence of tokens to follow the prompt
generated_output = generator(prompt, max_length=50, num_return_sequences=1)
print("Generated Text Output:")
print(generated_output[0]['generated_text'])
The Core Difference Between AI and Generative AI
When evaluating the difference between AI and generative AI, software engineers must view the distinction through the lens of architectural intent, mathematical formulation, and operational output. Traditional AI is fundamentally an optimization engine designed to map inputs to a predefined output space. It answers questions like “What is this?” or “What will happen next?” based on historical trajectories. Generative AI is an emulation engine designed to expand the output space infinitely. It answers the command “Create something new” based on the statistical probabilities of its training data.
To explicitly delineate these technological paradigms, we must compare their foundational characteristics across various engineering vectors.
| Feature | Traditional AI (Discriminative) | Generative AI (Generative) |
|---|---|---|
| Core Objective | Analyze, classify, predict, or cluster existing data points. | Synthesize and generate novel content (text, code, media). |
| Mathematical Focus | Models conditional probability: P(Y|X). Learns decision boundaries. | Models joint probability: P(X, Y) or data distribution: P(X). |
| Training Methodology | Primarily Supervised Learning using labeled, highly curated datasets. | Primarily Self-Supervised Learning using vast, unstructured datasets. |
| Data Output | Discrete labels, numerical values, or categorical classifications. | High-dimensional data outputs (paragraphs, images, executable code). |
| Resource Requirements | Generally lower compute; can run efficiently on standard CPUs or single GPUs. | Requires massive GPU clusters (e.g., H100s) and massive VRAM for inference and training. |
| Examples of Architectures | Random Forests, SVMs, Convolutional Neural Networks (CNNs). | Transformers, GANs, Variational Autoencoders (VAEs), Diffusion Models. |
Traditional AI vs Generative AI: Deep Dive into Technical Distinctions
To truly grasp the traditional AI vs generative AI debate, one must move beyond surface-level definitions and examine the core engineering and mathematical distinctions that dictate how these models are built, trained, and deployed in production environments.
The differences dictate everything from data pipeline architecture and a defined MLOps Roadmap to compute budgeting and latency optimization. Traditional models require strict feature engineering and hyperparameter tuning to ensure the decision boundary is precise. Generative models require massive parallel processing, advanced tokenization techniques, and complex alignment protocols (like RLHF – Reinforcement Learning from Human Feedback) to ensure the generated output is not just statistically probable, but coherent, safe, and contextually relevant.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
Objective Functions and Outputs
In traditional AI, the objective function is heavily reliant on minimizing classification error or prediction variance. For a binary classification model, engineers commonly utilize Binary Cross-Entropy (BCE) loss. The output is highly deterministic; given the exact same input, a deterministic discriminative model will consistently yield the exact same classification.
Generative AI utilizes highly complex objective functions depending on the architecture. LLMs use next-token prediction loss (often optimized via categorical cross-entropy over a vocabulary of tens of thousands of tokens). Diffusion models, used for image generation, minimize the noise-reconstruction error across iterative denoising steps. Furthermore, generative AI outputs are inherently probabilistic and stochastic. Through parameters like Temperature, Top-K, and Top-P sampling, engineers inject controlled randomness into the generation process, meaning the same prompt can yield vast variations in output.
Data Requirements and Training Methodologies
Traditional AI models are heavily bounded by the quality and quantity of labeled data. An object detection model requires thousands of images where humans have manually drawn bounding boxes around objects. This reliance on annotated datasets creates an operational bottleneck known as the “data labeling problem.”
Generative AI circumvents the labeling bottleneck by leveraging the internet as its dataset. LLMs are trained on scraped web data, books, and code repositories (often spanning trillions of tokens). Because the models use self-supervised learning—hiding parts of the data and attempting to predict the hidden parts—the raw data acts as both the input and the ground-truth label. However, this lack of strict curation introduces challenges regarding data bias, toxicity, and copyright infringement that are much harder to audit than in traditional AI datasets.
Compute Power and Resource Allocation
The resource disparity between traditional AI vs generative AI is staggering. A traditional machine learning model (like XGBoost) or a lightweight neural network can easily be trained on a consumer-grade laptop and deployed via a lightweight Docker container with minimal memory overhead.
Generative models, particularly large foundation models, operate on an entirely different scale. Training a model like GPT-3 (175 billion parameters) requires tens of thousands of specialized GPUs running continuously for months, consuming megawatts of electricity. Even at the inference stage, loading a 70-Billion parameter model requires multiple high-end GPUs simply to hold the model weights in VRAM (typically requiring ~140GB of VRAM in half-precision floating-point formats like FP16 or BF16). This has given rise to new optimization fields specifically for generative AI, such as model quantization (reducing precision to INT8 or INT4) and optimized attention mechanisms (like FlashAttention).
Real-World Use Cases: Discriminative vs. Generative Models
Understanding the architectural differences directly informs how software engineering teams deploy these technologies to solve real-world business problems. The choice between traditional and generative paradigms depends entirely on the problem space.
Traditional AI Applications
Traditional AI remains the gold standard for analytical, high-stakes environments where strict deterministic accuracy, low latency, and high interpretability are required.
- Cybersecurity and Fraud Detection: Analyzing network traffic or transaction logs in real-time to flag anomalous patterns indicative of a breach or credit card fraud.
- Predictive Maintenance: Ingesting IoT sensor data from industrial machinery to predict component failure times, allowing for scheduled maintenance before catastrophic breakdowns occur.
- Recommendation Engines: Matrix factorization and collaborative filtering algorithms used by streaming platforms and e-commerce sites to map user viewing/purchasing history to personalized product suggestions.
- Autonomous Vehicle Navigation: Using CNNs to continuously classify objects in a video feed (pedestrians, stop signs, lane markers) with ultra-low latency.
Generative AI Applications
Generative AI shines in domains requiring creativity, synthesis, unbounded problem-solving, and conversational interfaces.
- Automated Code Generation: Tools like GitHub Copilot and Cursor leverage LLMs to write boilerplate code, generate unit tests, and translate codebases between programming languages based on natural language developer intent.
- Retrieval-Augmented Generation (RAG): Integrating generative models with vector databases to allow enterprise users to “chat” with their internal documents, synthesizing complex reports from disparate unstructured data sources.
- Synthetic Data Generation: Creating highly realistic, privacy-compliant datasets (using GANs or Diffusion models) to train traditional AI models in domains where real data is scarce or heavily regulated (e.g., medical imaging).
- Dynamic Asset Creation: Generating bespoke UI/UX layouts, marketing copy, and in-game 3D assets dynamically based on user prompts.
The Evolution: From Traditional AI to Generative AI and Beyond
To fully appreciate the distinction between these paradigms, it is helpful to trace the technical lineage. The evolution of AI is not a story of one technology replacing another, but rather a stacking of capabilities.
A Brief Technical History
In the 1980s and 1990s, the field was dominated by Symbolic AI and Rule-Based Expert Systems. These systems required humans to hard-code vast logical trees (if-then statements). While functional, they lacked scalability and could not handle ambiguity.
The late 1990s and 2000s saw the rise of Statistical Machine Learning. Algorithms like Support Vector Machines and Naive Bayes allowed computers to learn these rules autonomously from data, cementing the era of Traditional AI.
The 2010s brought the Deep Learning revolution. Facilitated by the rise of parallel processing (GPUs) and massive datasets (ImageNet), deep neural networks achieved superhuman performance in traditional AI tasks like image classification and speech recognition.
In 2017, researchers at Google introduced the Transformer architecture in the seminal paper Attention Is All You Need. By overcoming the sequential processing bottlenecks of Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs), Transformers allowed models to parallel-process entire documents simultaneously. This architectural breakthrough birthed the current era of Generative AI.
Agentic AI vs Generative AI
As the industry pushes beyond basic text generation, a new subfield is emerging: Agentic AI. While generative AI excels at producing output based on a single prompt, it is generally passive. It answers when spoken to.
Agentic AI refers to systems built on top of generative models (using frameworks like LangChain or AutoGPT) that possess agency. They can break down a complex, high-level objective into sub-tasks, write their own prompts, execute code in sandboxed environments, call external APIs, self-correct errors, and iteratively work toward a goal without continuous human intervention. While generative AI represents the synthesis engine, agentic AI represents the orchestration and reasoning layer built around it.
Risks, Limitations, and Ethical Considerations
From a software engineering perspective, adopting generative AI introduces entirely new classes of risk that do not exist or are highly mitigated in traditional AI architectures.
- Hallucinations and Non-Determinism: Because generative models operate probabilistically, they can confidently generate outputs that are factually incorrect or logically flawed—a phenomenon known as hallucination. In traditional AI, an out-of-bounds input usually yields a low-confidence score; a generative model will often attempt to synthesize an answer regardless.
- Context Window Constraints: Generative models have strict limits on the amount of input data they can process in a single inference step (the context window). Processing massive context sizes leads to quadratic increases in memory and compute costs due to the nature of the self-attention mechanism, though newer architectures are attempting to create linear attention models.
- Security Vulnerabilities: Generative interfaces are susceptible to novel attack vectors such as Prompt Injection, where malicious actors embed hidden instructions within input text to bypass model safety guardrails and hijack the system’s output.
- Copyright and Intellectual Property: Traditional AI models extract mathematical insights; generative models can potentially memorize and reproduce verbatim snippets of their training data, leading to complex legal challenges regarding copyright infringement and fair use of open-source code and artistic content.
Conclusion
The difference between AI and generative AI is the difference between a system that interprets the world and a system that can simulate it. Traditional AI remains the undisputed champion of structured analytics, precise classification, and deterministic decision-making. It operates highly efficiently and serves as the invisible backbone of modern digital infrastructure, from spam filters to high-frequency trading algorithms.
Generative AI, powered by foundation models and transformative architectures, unlocks a new frontier of machine capability. By shifting from discriminative analysis to probabilistic synthesis, it enables machines to generate code, draft prose, and create imagery, acting as a highly capable collaborative reasoning engine.
For the modern software engineer, mastering both paradigms is not optional. The future of software architecture lies in hybrid systems—utilizing the creative reasoning of generative AI to interface with human intent, backed by the deterministic reliability and precision of traditional AI to execute core logic safely and efficiently.

Frequently Asked Questions (FAQs)
Is ChatGPT considered traditional AI or generative AI?
ChatGPT is a prime example of Generative AI. It is built upon the Generative Pre-trained Transformer (GPT) architecture. Rather than classifying your input into a predefined category, it probabilistically predicts and synthesizes a sequence of tokens (words) to generate novel, conversational responses based on the prompt provided.
Can traditional AI and generative AI be used together in a single application?
Yes, and this is considered an industry best practice. A common architectural pattern is Retrieval-Augmented Generation (RAG). In a RAG pipeline, a traditional AI model (like a dense vector search or semantic classifier) accurately retrieves factual documents from a private database, and a generative AI model synthesizes those retrieved facts into a coherent, natural language response.
Which is harder to train: traditional AI or generative AI?
From a computational and infrastructural perspective, generative AI is exponentially harder to train. While traditional AI models can often be trained on local machines or small cloud instances within hours, training a foundation generative model from scratch requires massive distributed computing infrastructure, thousands of high-end GPUs, complex data parallelization strategies, and millions of dollars in compute costs.
Does Generative AI replace Traditional AI?
No. Generative AI is not a replacement; it is a complementary technology. For tasks requiring strict numerical prediction, structured data analysis, or real-time classification (like autonomous driving or credit scoring), traditional AI remains far more accurate, efficient, and cost-effective. Generative AI is applied where human-like synthesis, creativity, or unstructured data generation is required.