RAG vs Agentic AI: Key Differences Explained
Retrieval-Augmented Generation (RAG) is a static AI framework that fetches external data from a vector database to enrich prompt responses. In contrast, Agentic AI employs autonomous retrieval augmented generation agents capable of dynamic reasoning, multi-step planning, tool utilization, and iterative decision-making to resolve complex, ambiguous queries autonomously.
Introduction to the Evolution of AI Systems
The rapid maturation of Large Language Models (LLMs) has fundamentally altered how software engineers approach natural language processing, data retrieval, and automated reasoning. In the earliest iterations of LLM integration, models relied entirely on their parametric memory—the static weights trained during their foundational pre-training phase. This approach quickly revealed severe limitations, primarily regarding knowledge cutoffs, hallucination of facts, and the inability to access proprietary enterprise data.
To resolve these limitations, Retrieval-Augmented Generation (RAG) was introduced as a systemic architecture that decoupled the knowledge base from the reasoning engine. RAG allowed systems to query external databases, retrieve relevant context, and append it to the user’s prompt before generating an answer. However, as enterprise demands grew, the limitations of standard linear RAG became apparent. Queries requiring multi-step reasoning, aggregations across disparate data sources, or self-correction during the retrieval phase exposed the rigid nature of traditional RAG pipelines.
This friction catalyzed the transition toward Agentic AI. By embedding LLMs within iterative control loops and outfitting them with software tools, developers created systems that do not merely retrieve and generate, but plan, execute, observe, and adapt. Understanding the architectural and operational delta between standard RAG and Agentic AI is critical for engineering teams tasked with building robust, scalable, and accurate AI applications.



What is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an architectural pattern that bridges the gap between a Large Language Model’s fixed internal knowledge and real-time, domain-specific external data. At its core, RAG functions as a semantic search engine fused with a generative text model. When a user issues a query, the system intercepts the request, maps it to a latent vector space, retrieves mathematically similar document chunks from a database, and feeds both the original query and the retrieved context into the LLM for synthesis.
This process is strictly linear and deterministic in its control flow. The model executes a single retrieval pass, generates an output based solely on that immediate context, and terminates. It does not possess the capacity to evaluate whether the retrieved documents actually contain the answer before generating a response, nor can it execute a secondary search if the initial context is insufficient.
Core Components of Traditional RAG
A standard RAG pipeline is built upon three foundational pillars:
- Data Ingestion and Indexing: Raw enterprise data (PDFs, code repositories, internal wikis) is parsed, split into manageable chunks, and converted into dense vector embeddings using specialized embedding models. These embeddings are stored in a Vector Database (such as Pinecone, Milvus, or pgvector).
- The Retrieval Mechanism: When a runtime query is received, it is embedded using the same model. The system then performs a k-Nearest Neighbors (k-NN) or Approximate Nearest Neighbors (ANN) search to find the most contextually relevant chunks. This relies on mathematical distance metrics, primarily Cosine Similarity. The equation for this is represented as: Cosine Similarity (A, B) = (A · B) / (||A|| * ||B||).
- The Generative Synthesis: The retrieved chunks are injected into a predefined prompt template alongside the user’s original query. The LLM processes this augmented prompt to generate a final, grounded response.
Limitations of Standard RAG
While traditional RAG dramatically reduces hallucinations and grounds LLM outputs in factual data, its rigid architecture presents specific challenges for complex engineering use cases:

- Single-Pass Dependency: If the initial retrieval yields poor or irrelevant results (due to poor phrasing or semantic mismatch), the LLM will generate a suboptimal or entirely incorrect answer. It cannot “try again.”
- Inability to Synthesize Across Silos: Standard RAG struggles with queries that require relational aggregation. For example, a query like “Compare the Q3 financial results of Company A and Company B” might fail if the chunks containing Company A’s data and Company B’s data do not surface together in the top-k retrieval results.
- Lack of Tool Usage: A standard RAG system cannot execute code, query SQL databases, check live APIs, or perform mathematical calculations. It is strictly limited to semantic text retrieval.
What is Agentic AI (and Agentic RAG)?
Agentic AI refers to a paradigm where artificial intelligence systems operate as autonomous entities capable of goal-directed behavior, logical reasoning, and environmental interaction. Instead of acting as a passive text generator, the LLM in an Agentic AI system functions as the central processing unit (CPU) or orchestrator. It receives a high-level goal, formulates a step-by-step execution plan, selects appropriate tools to gather information or enact changes, and continuously evaluates its own progress until the goal is achieved.
When this agentic framework is specifically applied to data retrieval architectures, it is referred to as Agentic RAG. This advanced architecture replaces the static, single-pass retrieval pipeline with dynamic retrieval augmented generation agents. These agents can determine if they need to retrieve data, where to search, how to refine their search queries based on initial findings, and when they have accumulated enough context to fulfill the user’s request.
The Concept of Retrieval Augmented Generation Agents
Retrieval augmented generation agents are specialized autonomous routines that treat vector databases, traditional relational databases, and external web APIs as callable tools rather than mandatory pipeline steps. If a user asks a complex question, the agent might first query a vector database. Upon observing the returned context, the agent might deduce that it only has half the answer. It will then autonomously formulate a second, highly specific query to an entirely different database to retrieve the missing information, cross-reference the data, and finally generate the output.
Core Components of Agentic AI Architectures
To achieve autonomous behavior, Agentic AI architectures require several components that do not exist in standard RAG:
- The Orchestrator (Reasoning Engine): A highly capable LLM (such as GPT-4 or Claude 3.5 Sonnet) that drives the decision-making loop.
- Memory Systems:
- Short-term memory: Maintains the context of the current thought-action-observation loop.
- Long-term memory: Stores historical interactions and state data across extended sessions.
- Tool Calling / Function Calling: The ability of the LLM to output structured data (typically JSON schemas) that trigger external Python functions, API requests, or database queries.
- Planning Mechanisms: Frameworks like ReAct (Reasoning and Acting) or Plan-and-Solve that force the model to explicitly state its assumptions, intended actions, and evaluations of outcomes.
RAG vs Agentic AI: Core Architectural Differences
Understanding the transition from standard RAG to Agentic RAG requires examining the shift from a linear, deterministic pipeline to a cyclical, non-deterministic control flow. Traditional RAG guarantees a predictable sequence of events: embed query, retrieve context, generate prompt, infer response. The latency is highly predictable, and the computational cost is static per query.
Agentic AI introduces dynamic branching. Because retrieval augmented generation agents evaluate their own outputs, a single user prompt might trigger one database query, or it might trigger ten, depending on the complexity of the task and the quality of the data retrieved in the initial passes. This fundamental difference affects system design, cost optimization, error handling, and latency budgeting.
Below is a technical comparison detailing the core architectural differences between the two paradigms.
| Feature | Standard RAG | Agentic AI (Agentic RAG) |
|---|---|---|
| Control Flow | Linear and deterministic. Follows a strict, pre-programmed sequence. | Cyclic and dynamic. The LLM dictates the execution path based on intermediate results. |
| Retrieval Paradigm | Single-pass retrieval. Top-k documents are fetched blindly based on query embedding. | Multi-hop and iterative retrieval. The agent evaluates retrieved data and reformulates queries if needed. |
| Tool Integration | None. Relies strictly on vector search or predefined database queries. | Extensive. Can utilize SQL integrations, API endpoints, web scrapers, and code interpreters. |
| Reasoning & Planning | Zero-shot synthesis. The LLM only reasons over the final augmented prompt. | Multi-step reasoning (e.g., ReAct). The agent formulates plans, reflects on outcomes, and self-corrects. |
| Error Handling | Fails silently or hallucinates if retrieval yields poor context. | Self-correcting. If a search tool returns no data, the agent can rephrase the query and try again. |
| Latency & Cost | Low and predictable. One embedding call, one LLM inference. | Variable and potentially high. Requires multiple LLM inference calls per user query. |
How Agentic RAG Works: A Deep Dive into the Workflow
Transitioning from theoretical definitions to practical engineering requires a deep dive into the operational workflow of an Agentic RAG system. Unlike a standard pipeline, the agentic workflow is governed by an orchestration loop that continuously evaluates the state of the system against the user’s initial objective.
When a prompt enters an Agentic RAG architecture, it does not immediately go to an embedding model. Instead, it hits the LLM orchestrator first. The orchestrator acts as a dynamic router, evaluating the linguistic properties and semantic intent of the query to determine the best course of action.
Dynamic Routing and Query Reformulation
One of the most powerful features of retrieval augmented generation agents is dynamic routing. In an enterprise system, data is rarely stored in a single unified vector database. Customer data might reside in an SQL database, technical documentation in a vector store, and live stock prices behind a REST API.
When the agent receives a query like “Did the client who filed ticket #4592 experience similar issues in the past according to our internal wiki?”, it performs the following steps:
- Decomposition: It breaks the query down into smaller tasks.
- Tool Selection (Routing): It recognizes that “ticket #4592” requires an SQL or API lookup, while “internal wiki” requires a vector database search.
- Query Reformulation: User queries are often poorly phrased for vector search. The agent reformulates the query, stripping out conversational filler to generate a dense keyword or semantic query highly optimized for the vector index.
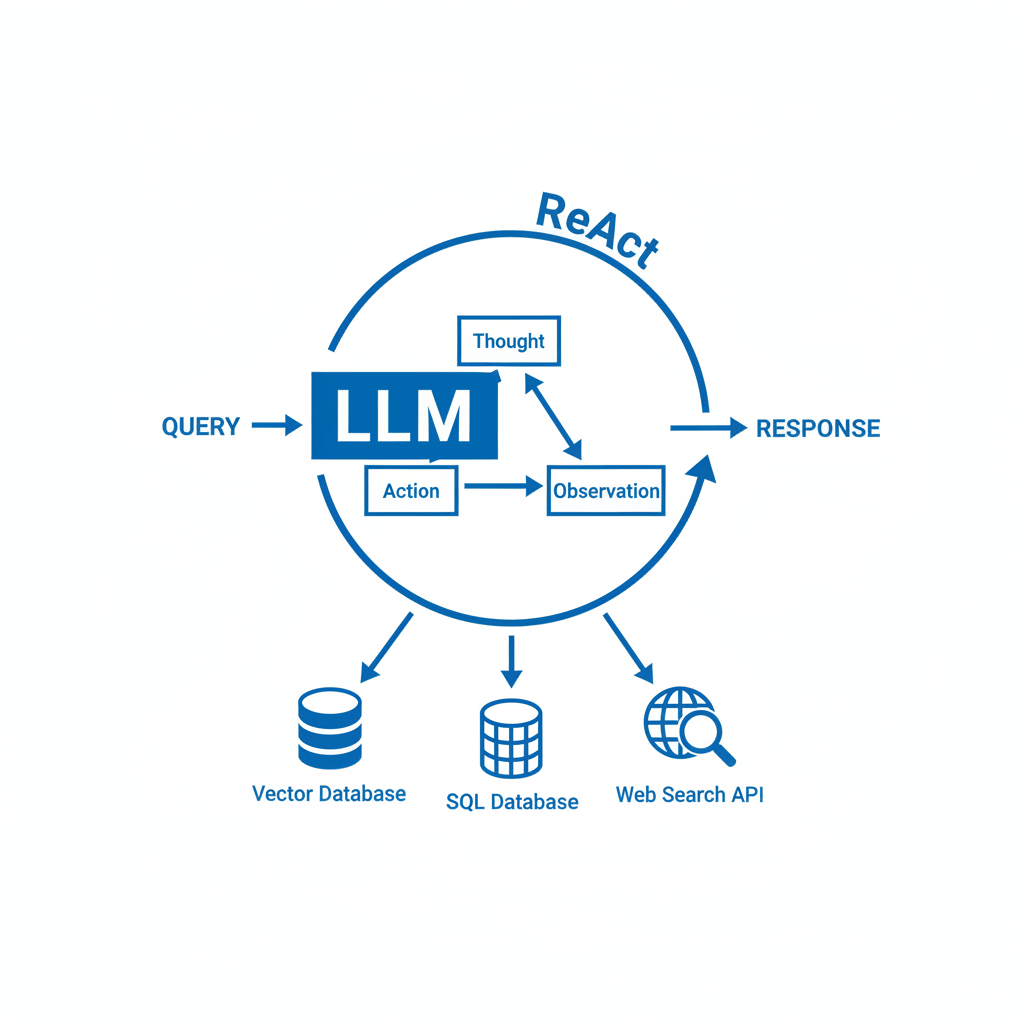
The ReAct (Reasoning and Acting) Framework
The operational heart of most Agentic RAG systems is the ReAct framework. ReAct forces the LLM to generate alternating “Thoughts” and “Actions.” This trace allows the model to maintain state and logic throughout complex tasks.
A typical ReAct cycle in an Agentic RAG system looks like this:
- Thought: I need to find the specific error logs for ticket #4592 before I can search the wiki for similar issues.
- Action: Execute
SQL_Query_Toolwith argumentSELECT error_log FROM tickets WHERE id = 4592. - Observation: The tool returns: “Null pointer exception at module auth.py line 42”.
- Thought: Now I know the exact error. I will search the vector database for documentation on “Null pointer exception auth.py line 42”.
- Action: Execute
Vector_Search_Toolwith argumentauth.py null pointer exception. - Observation: The tool returns context indicating that this is a known issue caused by an outdated OAuth token.
- Thought: I have all the necessary information to answer the user’s question.
- Action: Generate final response.
This iterative loop prevents the catastrophic failures common in standard RAG by allowing the model to verify intermediate data before proceeding to the final generation step.
Code Implementation: From Simple RAG to Agentic RAG
To fully grasp the architectural divergence, examining the code-level implementation is vital. The following examples demonstrate the shift from a static pipeline pattern to an agentic tool-calling pattern using pseudo-Python and common frameworks like LangChain.
Standard RAG Implementation
In a standard RAG setup, the code forces a strict, unavoidable path: user input -> embed -> retrieve -> prompt -> LLM -> output.
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_community.vectorstores import FAISS
from langchain_core.prompts import PromptTemplate
# 1. Initialize static components
embeddings = OpenAIEmbeddings()
vector_store = FAISS.load_local("enterprise_index", embeddings)
retriever = vector_store.as_retriever(search_kwargs={"k": 3})
llm = ChatOpenAI(temperature=0)
# 2. Define the static prompt
prompt_template = PromptTemplate.from_template(
"Answer the user's question based ONLY on the following context:\n{context}\n\nQuestion: {question}"
)
def standard_rag_query(user_query: str) -> str:
# 3. Strict Linear Execution
# Step A: Retrieve
docs = retriever.invoke(user_query)
context_string = "\n".join([doc.page_content for doc in docs])
# Step B: Format
formatted_prompt = prompt_template.format(context=context_string, question=user_query)
# Step C: Generate
response = llm.invoke(formatted_prompt)
return response.content
# Execution
print(standard_rag_query("What is our refund policy?"))
Agentic RAG Implementation with Routing and Tools
In an Agentic RAG system, the vector store is wrapped as a callable tool alongside other tools. The LLM is configured as an Agent Executor that autonomously decides which tools to invoke based on the user’s prompt.
from langchain_openai import ChatOpenAI
from langchain.agents import initialize_agent, AgentType, Tool
from langchain_community.utilities import SQLDatabase
# Assume retriever is already initialized as in the previous example
# 1. Wrap the static retriever into an actionable Tool
def query_vector_wiki(query: str) -> str:
docs = retriever.invoke(query)
return "\n".join([doc.page_content for doc in docs])
wiki_tool = Tool(
name="Internal Wiki Database",
func=query_vector_wiki,
description="Useful for answering questions about company policies, technical documentation, and standard operating procedures."
)
# 2. Define additional tools for the Agent
sql_db = SQLDatabase.from_uri("sqlite:///enterprise_data.db")
def query_sql(query: str) -> str:
# Wrapper logic for safely querying SQL
return sql_db.run(query)
sql_tool = Tool(
name="Customer SQL Database",
func=query_sql,
description="Useful for fetching specific user data, ticket statuses, and billing information using SQL."
)
# 3. Initialize the Agentic Orchestrator
llm = ChatOpenAI(temperature=0, model="gpt-4")
tools = [wiki_tool, sql_tool]
agent_executor = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
max_iterations=5 # Safety mechanism to prevent infinite loops
)
def agentic_rag_query(user_query: str) -> str:
# The agent autonomously decides the execution path
return agent_executor.run(user_query)
# Execution: The agent will first use the SQL tool, observe the result,
# then use the Wiki tool, and finally synthesize an answer.
print(agentic_rag_query("Check the status of ticket #4592 and explain the underlying policy error."))
Applications and Enterprise Use Cases
Choosing between standard RAG and Agentic AI is not merely a matter of selecting the “most advanced” technology. The decision must be rooted in specific business requirements, computational budgets, and the tolerance for latency.
Ideal Scenarios for Traditional RAG
Standard RAG remains highly effective and preferred for straightforward, information-dense retrieval tasks where speed and cost-efficiency are paramount.
- Customer Support Chatbots: Handling common FAQs where answers exist explicitly within a single, curated knowledge base.
- Internal Document Search: Allowing employees to quickly semantically search through hundreds of HR PDFs or onboarding manuals.
- Summarization Tasks: Retrieving a specific financial report and summarizing its contents in a single pass.
In these scenarios, the overhead of an agentic loop introduces unnecessary latency and token costs without significantly improving the quality of the output.
Where Agentic AI and Agentic RAG Shine
Retrieval augmented generation agents are essential when queries are highly complex, span across diverse data modalities, or require an explicit sequence of operational steps to resolve.
- Complex Technical Troubleshooting: A developer asks an agent to debug a stack trace. The agent searches the code repository tool, queries the JIRA API for open tickets, checks the vector database for past post-mortems, and synthesizes a comprehensive fix.
- Financial Analysis and Auditing: An agent is tasked with comparing unstructured narrative data from annual reports (vector search) with raw numerical data stored in relational databases (SQL execution), performing mathematical comparisons, and writing an investment thesis.
- Dynamic Data Pipelines: Systems where the underlying data is constantly changing, and the agent must verify the freshness of its retrieval by cross-referencing timestamps via external APIs before delivering an answer.
Challenges and Ethical Considerations
While Agentic RAG represents a massive leap in AI capability, it introduces a unique set of engineering challenges, performance bottlenecks, and ethical considerations that must be actively mitigated during system design.
Latency and Computational Cost
Because an agentic system relies on continuous iteration, a single user prompt can trigger multiple LLM inferences and external API calls. In a standard RAG system, a query might consume 1,000 tokens and resolve in 1.5 seconds. The same query processed by an agent using the ReAct framework might consume 6,000 tokens across five reasoning steps and take 12 seconds to resolve. Engineering teams must heavily optimize prompts, utilize faster, smaller models for routing decisions, and implement aggressive caching mechanisms to make agentic architectures viable in production.
Hallucinations and Infinite Loops
Agents are susceptible to getting trapped in infinite reasoning loops. If an agent formulates a query that consistently returns no data from a tool, a poorly configured LLM might continually rephrase the same query in a slightly different way, executing the tool indefinitely until it hits a hard rate limit. To prevent this, developers must implement strict max_iterations limits and provide explicit system prompts that instruct the agent to gracefully degrade or ask the user for clarification when a tool fails to yield useful data.
Security and Access Control
Standard RAG architectures are relatively secure because their primary interaction with data is read-only vector retrieval. Agentic AI systems, however, are inherently designed to take action. If an agent is granted write access to an SQL database or the ability to trigger internal enterprise APIs, it opens the door to severe security vulnerabilities, including Prompt Injection attacks.
Malicious users can craft inputs designed to trick the agent’s orchestrator into executing destructive tools (e.g., dropping database tables or leaking sensitive HR data). Securing retrieval augmented generation agents requires implementing strict Role-Based Access Control (RBAC) at the tool execution layer, ensuring that the agent assumes the minimal necessary permissions of the user querying it. Furthermore, “Human-in-the-Loop” (HITL) approval gates must be integrated before any agent is allowed to execute a state-changing action.
Frequently Asked Questions (FAQ)
What is the primary difference between RAG and Agentic RAG?
The primary difference lies in the control flow. Standard RAG uses a linear, single-pass pipeline to retrieve data and generate text. Agentic RAG uses an LLM as an autonomous reasoning engine that iteratively selects tools, evaluates retrieved data, and self-corrects until it gathers enough information to answer the query.
Can Agentic AI work without a vector database?
Yes. While standard RAG relies heavily on vector databases for semantic search, Agentic AI is tool-agnostic. An agent can be constructed entirely using SQL databases, external REST APIs, and mathematical calculators without ever touching a vector database. When vector databases are included as tools, the system is specifically referred to as Agentic RAG.

How do you evaluate the performance of retrieval augmented generation agents?
Evaluating agents is vastly more complex than standard RAG. Instead of merely measuring retrieval accuracy (Precision/Recall) and generation quality, you must evaluate the agent’s trajectory. Frameworks like AgentBench or custom tracing tools (like LangSmith) are used to evaluate whether the agent selected the right tools, executed them in the most efficient order, and successfully recovered from tool errors during its reasoning loop.
What is the latency impact of moving from RAG to Agentic RAG?
The latency impact is significant. Because standard RAG requires only one LLM call, it typically resolves in 1-3 seconds. Agentic RAG requires an LLM call for every “thought” and “action” in its loop. Depending on the complexity of the task, Agentic RAG can take anywhere from 5 seconds to over a minute.
How do you prevent an agent from taking dangerous actions?
Agents should be strictly sandboxed. Never grant an autonomous agent direct write or delete permissions to production databases without oversight. Utilize “Human-in-the-Loop” architectures where the agent formulates a plan and pauses execution to request manual approval from a human engineer before calling high-risk tools.