AI Infrastructure: What It Is and Why It Matters for Modern AI Systems
AI infrastructure is the complete end-to-end stack of hardware and software technologies required to develop, train, deploy, and manage artificial intelligence and machine learning models. This foundational layer encompasses everything from specialized processors and high-speed networking to data pipelines, orchestration software, and MLOps platforms.
The Core Pillars of AI Infrastructure
The sophistication of modern AI, particularly large language models (LLMs) and generative systems, is not merely a product of algorithmic innovation. It is built upon a foundation of highly specialized and massively scalable infrastructure. Understanding this infrastructure requires dissecting its constituent layers, each of which addresses a specific set of computational, data management, and operational challenges. These layers work in concert to transform raw data and theoretical models into functional, high-performance AI applications.
The Hardware Layer: Specialized Computing
The hardware layer forms the physical bedrock of any AI system. The immense computational demands of training deep neural networks, which involve billions or even trillions of parameter calculations, have driven the development of hardware far beyond the capabilities of traditional CPUs. This specialized hardware is designed to excel at the parallel matrix and vector operations that are fundamental to deep learning.
- Graphics Processing Units (GPUs): Originally designed for rendering graphics, GPUs have become the de facto standard for AI training due to their massively parallel architecture. Companies like NVIDIA dominate this space with products like the A100 and H100 Tensor Core GPUs, which are architected specifically to accelerate the tensor operations common in deep learning. The CUDA (Compute Unified Device Architecture) platform provides a software layer that allows developers to directly access the GPU's computational power.
- Tensor Processing Units (TPUs): Developed by Google, TPUs are Application-Specific Integrated Circuits (ASICs) designed from the ground up to accelerate machine learning workloads developed with TensorFlow and JAX. Unlike GPUs, which retain some graphics-processing capabilities, TPUs are purpose-built for high-volume, low-precision matrix multiplication, making them exceptionally efficient for large-scale training and inference.
- High-Performance Networking: When training models that are too large for a single machine, the communication speed between nodes becomes a critical bottleneck. High-performance networking technologies are essential. InfiniBand, with its high bandwidth and low latency, is a common choice in dedicated AI clusters. It supports Remote Direct Memory Access (RDMA), which allows one machine's network adapter to access the main memory of another machine directly, bypassing the CPU and significantly reducing communication overhead. This is crucial for efficient distributed training.
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol Now
- High-Throughput Storage Systems: AI models consume and produce vast quantities of data. Training datasets can be terabytes or even petabytes in size. The storage system must be able to feed this data to the accelerators without delay. This necessitates high-throughput, low-latency storage solutions like NVMe (Non-Volatile Memory Express) SSDs and parallel file systems (e.g., Lustre, BeeGFS) that can serve data to thousands of compute nodes simultaneously.
The Software Layer: Orchestration and Management
The most powerful hardware is ineffective without a sophisticated software layer to manage resources, orchestrate complex workflows, and streamline the entire machine learning lifecycle. This layer abstracts away the underlying hardware complexity, allowing data scientists and engineers to focus on model development.
-
Containerization and Orchestration: Containers (primarily Docker) package an application and its dependencies into an isolated, portable unit. This ensures consistency across development, testing, and production environments. Kubernetes has emerged as the industry standard for container orchestration, automating the deployment, scaling, and management of these containerized applications. For AI workloads, custom Kubernetes operators like Kubeflow extend its capabilities to manage complex ML pipelines.
A simple Kubernetes Pod specification to request a GPU resource might look like this:
-
Distributed Computing Frameworks: Frameworks like Ray and Dask are designed to scale Python applications and ML workloads across multiple machines. They provide simple APIs to parallelize code, making it easier to implement distributed data processing and model training strategies without delving into the complexities of low-level network programming.
-
MLOps Platforms: MLOps (Machine Learning Operations) platforms provide the tooling to manage the end-to-end ML lifecycle. This includes tools for:
- Experiment Tracking: Logging parameters, metrics, and artifacts for every training run (e.g., Weights & Biases, MLflow).
- Model Registry: Versioning and managing trained models.
- CI/CD Automation: Automating the process of training, testing, and deploying models.
The Data Layer: The Fuel for AI Models
Data is the essential raw material for any AI model. The data layer of AI infrastructure is responsible for the reliable and efficient ingestion, storage, processing, and versioning of the massive datasets required for training and inference.
- Data Ingestion and Pipelines: Scalable systems like Apache Kafka are used for real-time data streaming, while frameworks like Apache Spark are used for large-scale batch data processing and transformation (ETL).
- Data Storage and Warehousing: Modern data architectures often use a data lake (e.g., on Amazon S3 or Google Cloud Storage) to store vast amounts of raw, unstructured data. A feature store is a more specialized component that manages and serves curated, versioned features ready for model training, ensuring consistency between training and serving environments.
- Data Versioning: Just as Git versions source code, tools like DVC (Data Version Control) version datasets and models. This is crucial for reproducibility, allowing teams to roll back to specific data versions and understand exactly which data was used to train a particular model version.
AI Infrastructure vs. AI Platforms: A Critical Distinction
The terms "AI Infrastructure" and "AI Platform" are often used interchangeably, but they represent different levels of abstraction. Understanding their distinction is key to making informed architectural decisions. AI infrastructure refers to the foundational compute, storage, networking, and core software components. AI platforms are higher-level, often managed services built on top of this infrastructure, designed to simplify and accelerate the development and deployment of AI applications.
Think of it this way: AI infrastructure provides the raw materials (processors, servers, orchestration engines), while an AI platform provides the integrated workshop and pre-built tools (managed training services, auto-scaling inference endpoints, pre-trained APIs).
| Aspect | AI Infrastructure | AI Platform |
|---|---|---|
| Abstraction Level | Low-level. Deals with virtual machines, containers, GPUs, storage volumes, and network configuration. | High-level. Deals with APIs, managed services, and automated workflows (e.g., "click-to-train"). |
| Target User | Infrastructure Engineers, MLOps Engineers, DevOps Specialists. | Data Scientists, Machine Learning Engineers, Application Developers. |
| Scope | The "how" – provisioning and managing the underlying resources required to run AI workloads. | The "what" – providing the tools and services to build, train, and deploy models. |
| Customization | High. Full control over hardware selection, network topology, and software stack. | Limited. Operates within the constraints and abstractions provided by the platform vendor. |
| Examples | A Kubernetes cluster on bare-metal servers with InfiniBand, a self-managed Lustre file system. | Google Vertex AI, Amazon SageMaker, Azure Machine Learning, OpenAI API. |
Architectural Paradigms: Deployment and Scalability
Designing and deploying AI infrastructure involves making critical architectural choices that impact cost, performance, and scalability. The two primary decisions revolve around where the infrastructure will reside (on-premises vs. cloud) and how it will scale to handle increasingly demanding workloads.






On-Premises vs. Cloud vs. Hybrid
- On-Premises: This involves building and managing a dedicated AI data center.
- Pros: Maximum control over hardware and software, potentially lower TCO (Total Cost of Ownership) at very large, constant scale, and enhanced security and data privacy.
- Cons: High upfront capital expenditure (CapEx), long procurement cycles for specialized hardware, and the need for a dedicated team to manage and maintain the infrastructure.
- Cloud (IaaS/PaaS): This involves renting infrastructure from a major cloud provider like AWS, Google Cloud, or Microsoft Azure.
- Pros: Elastic scalability (pay-for-what-you-use), access to the latest hardware without procurement delays, and a shift from CapEx to operational expenditure (OpEx).
- Cons: Can become prohibitively expensive at scale, data egress costs can be significant, and potential for vendor lock-in.
- Hybrid: This approach combines on-premises infrastructure for steady-state, sensitive workloads with cloud resources for bursting capacity or experimenting with new hardware. This often provides an optimal balance of control, cost, and flexibility. Stop learning AI in fragments—master a structured AI Engineering Course with hands-on GenAI systems with IIT Roorkee CEC Certification
Become the Ai engineer who can design, build, and iterate real AI products, not just demos with an IIT Roorkee CEC Certification
AI Engineering Course Advanced Certification by IIT-Roorkee CEC
A hands on AI engineering program covering Machine Learning, Generative AI, and LLMs - designed for working professionals & delivered by IIT Roorkee in collaboration with Scaler.
Enrol NowScaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Scaling Strategies for AI Workloads
As models grow, a single machine is no longer sufficient. Scaling AI workloads requires distributing the computation across a cluster of machines.
- Vertical Scaling (Scaling Up): This involves increasing the resources of a single node—for example, by upgrading to a machine with more powerful GPUs or more RAM. This is the simplest approach but has physical limits and diminishing returns.
- Horizontal Scaling (Scaling Out): This involves adding more nodes to a cluster and distributing the work among them. This is the only viable strategy for training state-of-the-art models and is achieved through various parallelism techniques.
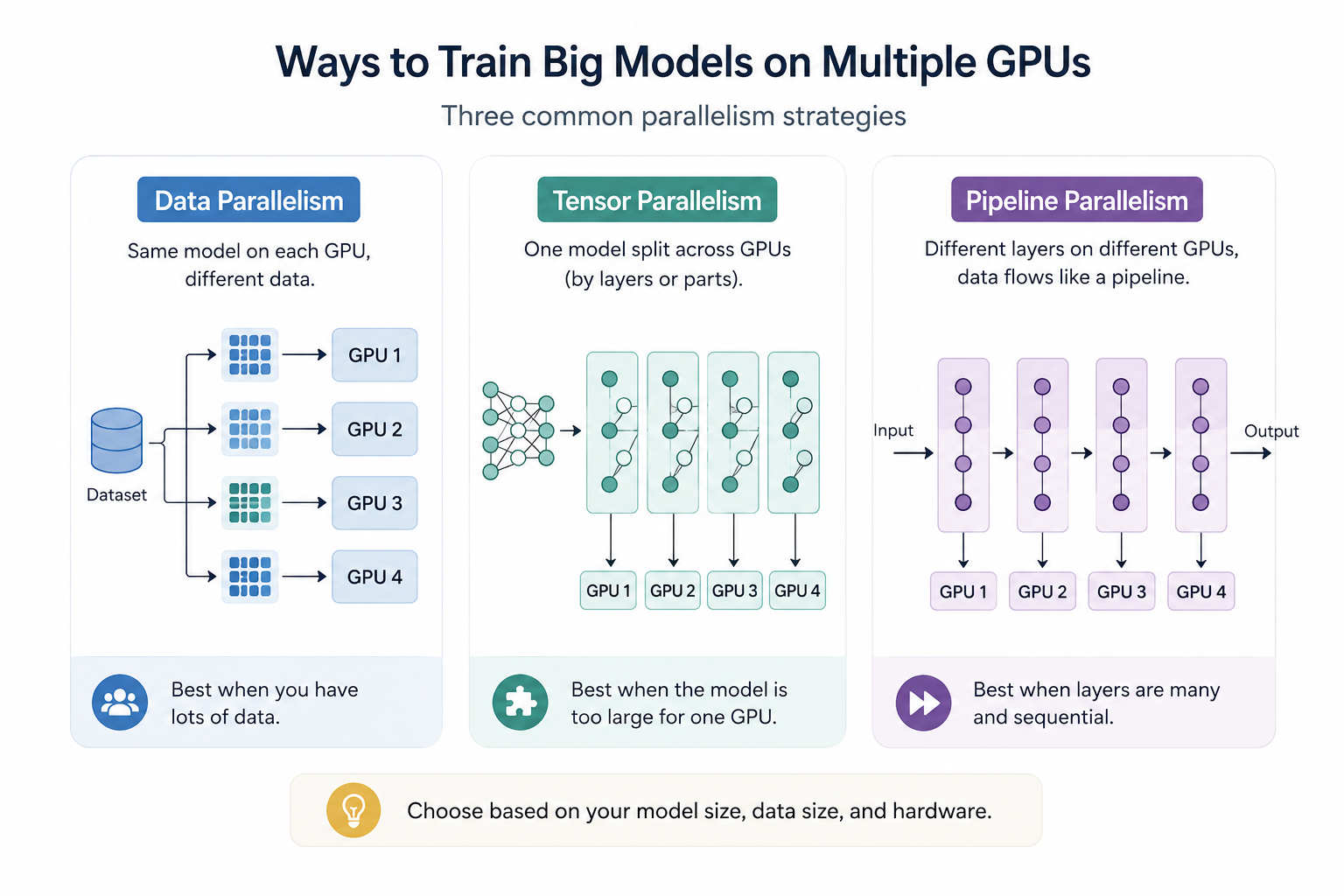
- Data Parallelism: This is the most common technique. The model is replicated on each worker node, and the training data is split (sharded) among them. Each node processes its shard of data, computes its local gradients, and then all gradients are aggregated and averaged to update the model weights.
- Model Parallelism: When a model is too large to fit in the memory of a single GPU, the model itself must be split.
- Tensor Parallelism: This involves splitting individual layers or even specific operations (like a large matrix multiplication) across multiple GPUs. This requires very high-speed interconnects between the GPUs (e.g., NVIDIA's NVLink).
- Pipeline Parallelism: This involves partitioning the model's layers sequentially across different GPUs. One GPU handles layers 1-8, the next handles layers 9-16, and so on. A mini-batch of data flows through this "pipeline," which can improve hardware utilization but introduces complexities like pipeline "bubbles" (idle time).
Key Challenges in Building and Managing AI Infrastructure
While powerful, building and operating high-performance AI infrastructure is a non-trivial engineering challenge fraught with technical and financial hurdles.
Cost Management
The cost of specialized AI hardware is substantial. A single high-end server with 8x NVIDIA H100 GPUs can cost hundreds of thousands of dollars. In the cloud, these instances can cost tens of dollars per hour. Managing these costs requires sophisticated scheduling, using preemptible/spot instances, and implementing "right-sizing" to ensure workloads are using resources efficiently.
Turn Learning into Career Growth
Scalability and Performance Bottlenecks
In a distributed system, the overall performance is limited by the slowest component. A bottleneck could be the network interconnect, the storage I/O speed, or even the CPU preparing data for the GPUs. Identifying and mitigating these bottlenecks requires deep system-level profiling and expertise in high-performance computing (HPC).
Reliability and Fault Tolerance
Training a large model can take weeks or even months. During such a long run on a cluster of hundreds or thousands of nodes, a hardware failure is not a possibility but a certainty. The infrastructure must have robust mechanisms for checkpointing the model's state periodically and seamlessly recovering the training job from the last checkpoint on a new node.
Security and Compliance
AI infrastructure often processes sensitive proprietary or personal data. Securing the data at rest and in transit, controlling access to compute resources, and ensuring compliance with regulations like GDPR or HIPAA are critical operational requirements.
Technical Complexity and Talent Shortage
The skillset required to design, build, and maintain high-performance ai computing infrastructure is a rare blend of systems engineering, network architecture, DevOps, and machine learning knowledge. There is a significant shortage of MLOps and AI infrastructure engineers, making it difficult for many organizations to build and support these complex systems in-house.
The Future of AI Computing Infrastructure
The field of AI infrastructure is evolving rapidly to meet the ever-growing demands of AI research and deployment. Several key trends are shaping its future.
- Software-Defined Infrastructure: The use of Infrastructure as Code (IaC) tools like Terraform and Ansible is becoming standard. This allows for the automated, repeatable, and version-controlled provisioning of entire AI environments, from the virtual network to the Kubernetes cluster and MLOps tooling.
- Rise of Sovereign AI: In response to geopolitical factors and the strategic importance of AI, nations and large corporations are increasingly investing in building their own "sovereign" AI clouds. These are dedicated, large-scale clusters designed to ensure data sovereignty and provide a competitive advantage in AI development.
- Specialization in Hardware: While GPUs remain dominant, the hardware landscape is diversifying. There is a growing ecosystem of ASICs and other accelerators designed for specific tasks. For example, some chips are optimized purely for inference, offering lower power consumption and cost per prediction than a general-purpose training GPU.
- Sustainable and Green AI: The massive energy consumption of AI data centers is a growing concern. The future of AI infrastructure will involve a greater focus on energy efficiency, including the development of more power-efficient hardware, the use of liquid cooling, and the colocation of data centers with renewable energy sources.
Conclusion
AI infrastructure is far more than a simple collection of servers; it is a complex, deeply integrated system of specialized hardware and sophisticated software that serves as the engine for modern artificial intelligence. From the silicon in the processors to the orchestration logic in Kubernetes, every component plays a critical role in enabling the development of models that are redefining industries. As AI systems continue to grow in scale and complexity, the design, management, and optimization of the underlying infrastructure will remain one of the most significant challenges and a key differentiator for organizations at the forefront of the AI revolution.
Frequently Asked Questions (FAQ)
What is the difference between MLOps and AI infrastructure? AI infrastructure refers to the foundational hardware and software stack (compute, storage, networking, orchestration). MLOps is the set of practices and tools that run on top of this infrastructure to automate and manage the lifecycle of machine learning models (e.g., experiment tracking, model deployment, monitoring). Infrastructure is the "where," and MLOps is the "how."
Can I build AI infrastructure with CPUs instead of GPUs? While you can technically run small-scale ML models on CPUs, it is highly impractical for deep learning. The parallel architecture of GPUs allows them to perform the matrix multiplication central to neural networks orders of magnitude faster than CPUs. For any serious AI development, GPUs or other specialized accelerators are a necessity.
How does Kubernetes help in managing AI infrastructure? Kubernetes provides a unified, scalable, and resilient platform for managing containerized AI workloads. It automates resource scheduling (e.g., assigning a job to a server with an available GPU), handles fault tolerance by restarting failed containers, and simplifies the deployment of complex, multi-service ML applications.
What is InfiniBand and why is it important for AI? InfiniBand is a high-performance computer network communications standard used in supercomputers and AI clusters. Its key advantages are extremely high bandwidth and very low latency. This is critical for distributed training, where large volumes of data (model gradients) must be exchanged between nodes with minimal delay. Slower networking like standard Ethernet would become a major bottleneck and severely slow down the training process.