Informed Search
Overview
Informed Search algorithms play a significant role in artificial intelligence. These algorithms enable more effective and efficient search using heuristic functions to direct the search process towards a goal state. This article will introduce the topic and give a general overview of AI's informed search algorithms.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Introduction
Informed search algorithms are a type of search algorithm that uses heuristic functions to guide the search process. For example, a heuristic function calculates the cost of moving from a starting state to a goal state. By employing this assessment, informed search algorithms can select search paths more likely to lead to the desired state. As a result, the search process is improved, making it quicker and more accurate for AI systems to make decisions.
A* search, iterative deepening A*, and best first search in artificial intelligence are examples of informed search algorithms. These algorithms are frequently employed in AI applications and have successfully resolved challenging issues.
Heuristics function
A heuristic function calculates the cost of moving from a starting state to a goal state. This function directs the search process in intelligent algorithms like A* search and the best first search in artificial intelligence. The algorithm can prioritize search paths that are more likely to lead to the goal state by using the heuristic function, which gives an estimate of how close a particular state is to the goal state.
Informed search algorithms use two primary categories of heuristic functions: acceptable and inadmissible. A heuristic function that never overestimates the expense of getting to the desired state is acceptable. In other words, a valid heuristic function always offers a lower constraint on the expense of getting to the desired state. Conversely, an unallowable heuristic function can exaggerate the expense of getting to the objective state, producing less-than-ideal answers.






Admissibility of the Heuristic Function
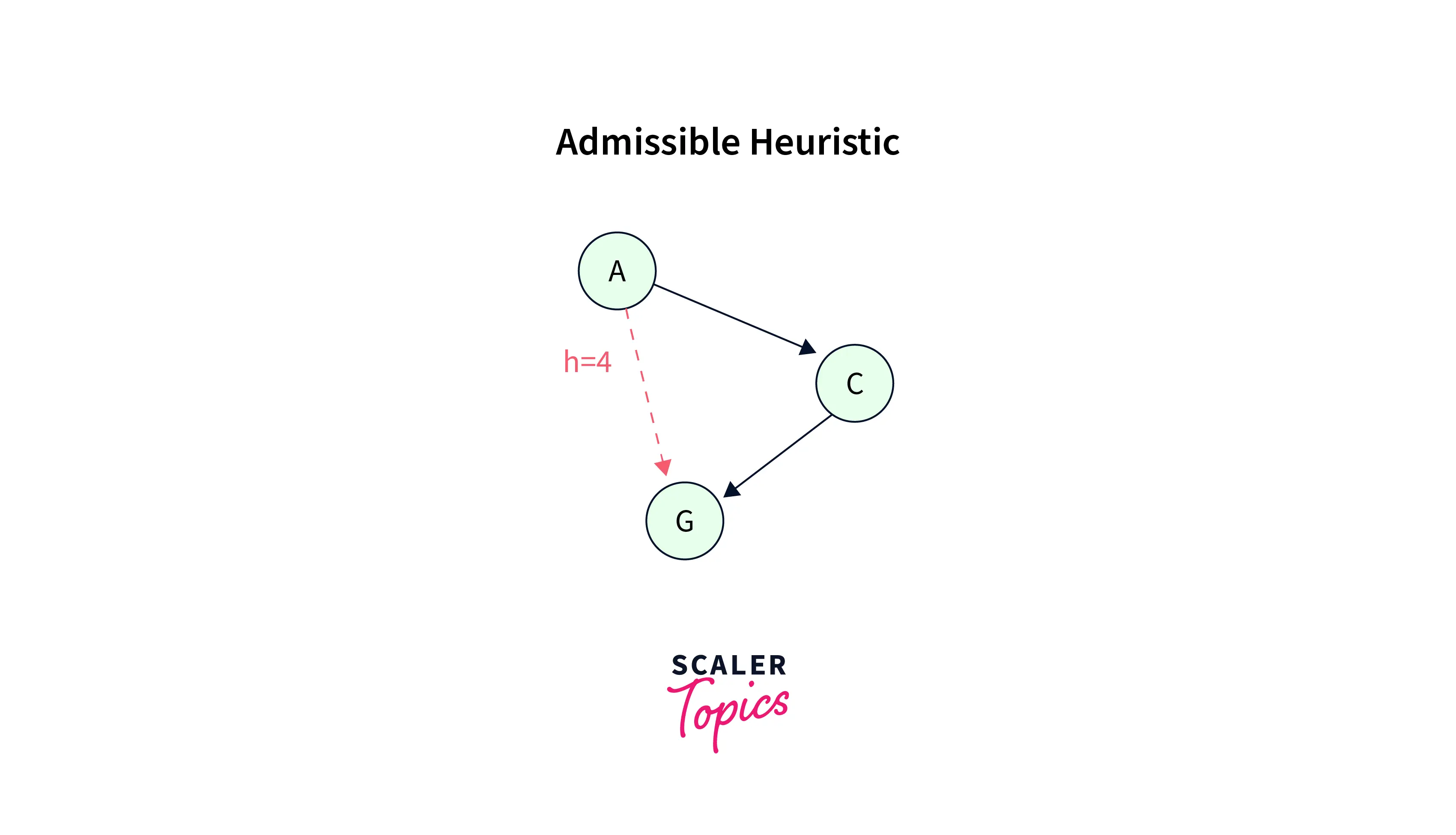 Admissibility is an essential quality of a heuristic function employed in intelligent search algorithms. The search algorithm will always locate the best solution if the heuristic function is valid. This is so that an admissible heuristic function can lower bind the cost of achieving the desired state. As the heuristic function provides an estimated cost, each path the algorithm discovers must cost more than or equal to that estimate.
Admissibility is an essential quality of a heuristic function employed in intelligent search algorithms. The search algorithm will always locate the best solution if the heuristic function is valid. This is so that an admissible heuristic function can lower bind the cost of achieving the desired state. As the heuristic function provides an estimated cost, each path the algorithm discovers must cost more than or equal to that estimate.
On the other hand, the search algorithm might only locate the best solution if the heuristic function is valid. This is because an unallowable heuristic function may overestimate the expense of getting to the goal state, which would force the search algorithm to consider less desirable alternatives. However, an invalid heuristic function is helpful in practice since it can improve search efficiency by pointing the search algorithm toward the desired state.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Pure Heuristic Search
An informed search algorithm employed in artificial intelligence which expands nodes based on heuristic values is called a pure heuristic search algorithm. These algorithms use heuristics, which are shortcuts or general rules of thumb that direct the search process in the direction of the desired state. In addition, pure heuristic search algorithms use domain-specific knowledge to increase search efficiency instead of uninformed search algorithms, which have no prior knowledge of the problem area.
The A* algorithm is one of the most widely used pure heuristic search methods. The cost of moving from the current state to the objective state is estimated by the A* algorithm using a heuristic function. We will understand this algorithm and its working in depth later.
The two main Algorithms
Turn Learning into Career Growth
A. Best First Search Algorithm(Greedy search)
The Best First Search algorithm in artificial intelligence, sometimes called Greedy Search, is an intelligent search algorithm. Because it uses heuristic functions to choose which path to explore first, it is known as an informed search. According to this technique, the next node to be explored is selected based on how close it is to the target. It starts by exploring the node with the shortest predicted distance.
Steps to perform a Best First Search in artificial intelligence:
- Start node added to the open list.
- While the open list is not empty: a. Eliminate the node from the open list with the shortest calculated distance. b. Provide the solution if the node is the goal node. c. Generate the children of the current node. d. Estimate the children's travel time to the objective after adding them to the open list.
- There is only a solution if the open list is empty.
Advantages:
- If a decent heuristic function is applied, it finds a solution rapidly.
- It can be applied to a variety of issues.
- Implementing it is simple.
Disadvantages:
- As it only considers the expected distance to the target and not the actual cost of getting there, it could only sometimes come up with the best solution.
- It can become trapped in a local minimum and stop looking for alternate routes.
- To perform properly, it needs a good heuristic function.
Example:
The algorithm selects the node with the lowest heuristic value as the next node to expand.
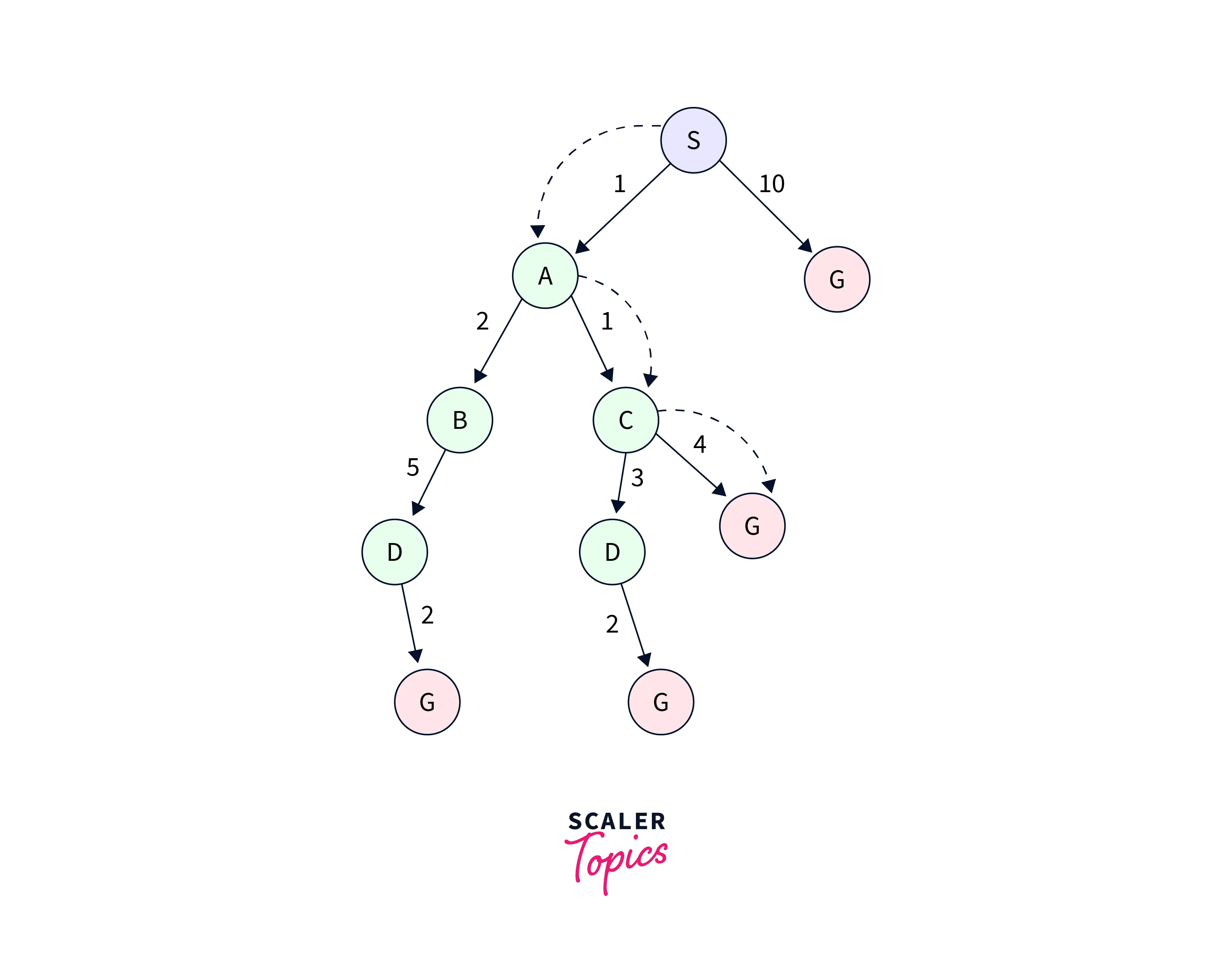
Let's consider the following graph:
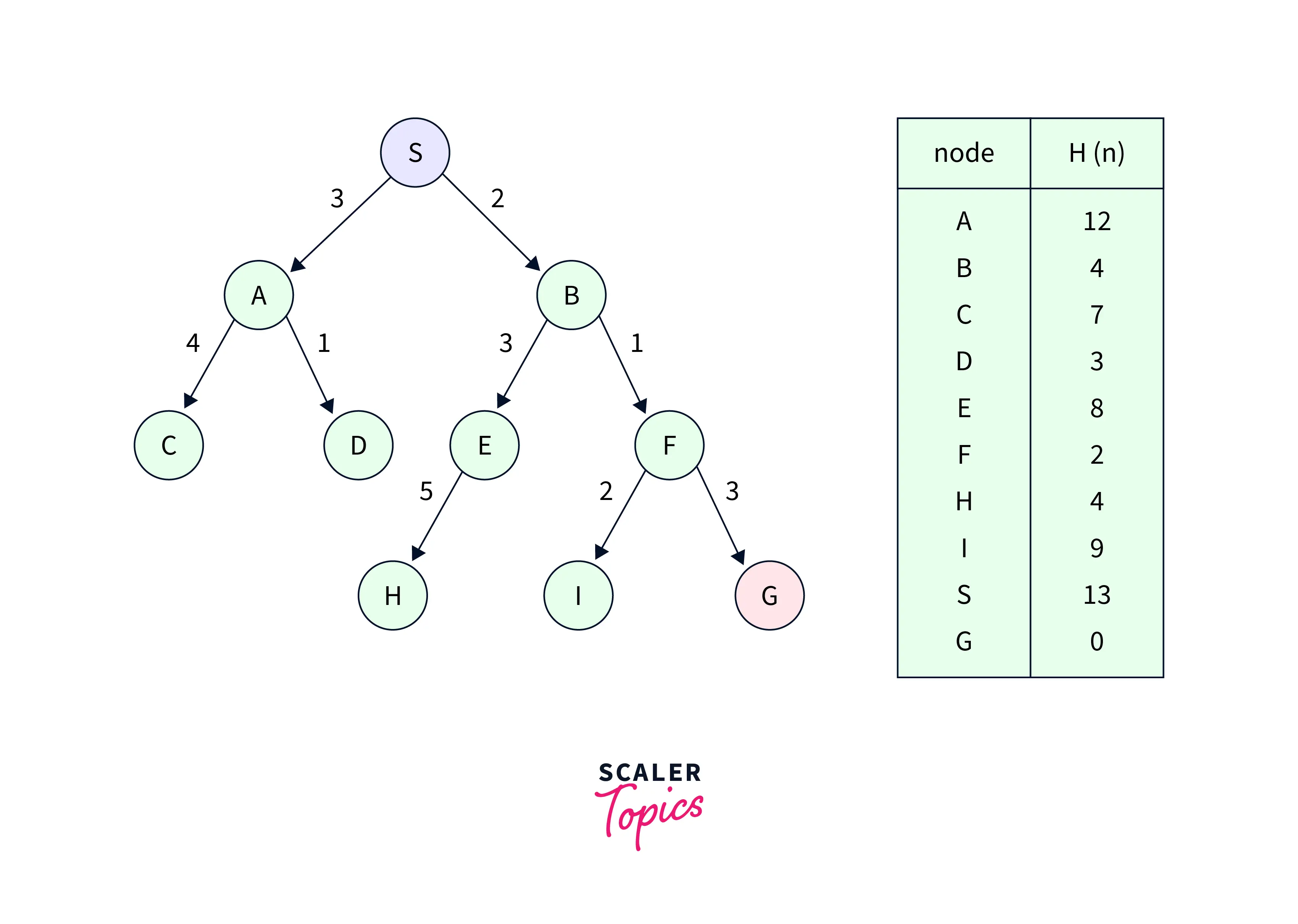 We are using two lists in this search example, the OPEN and CLOSED Lists. The iterations for traversing the aforementioned example are listed below.
Solution:
We are using two lists in this search example, the OPEN and CLOSED Lists. The iterations for traversing the aforementioned example are listed below.
Solution:
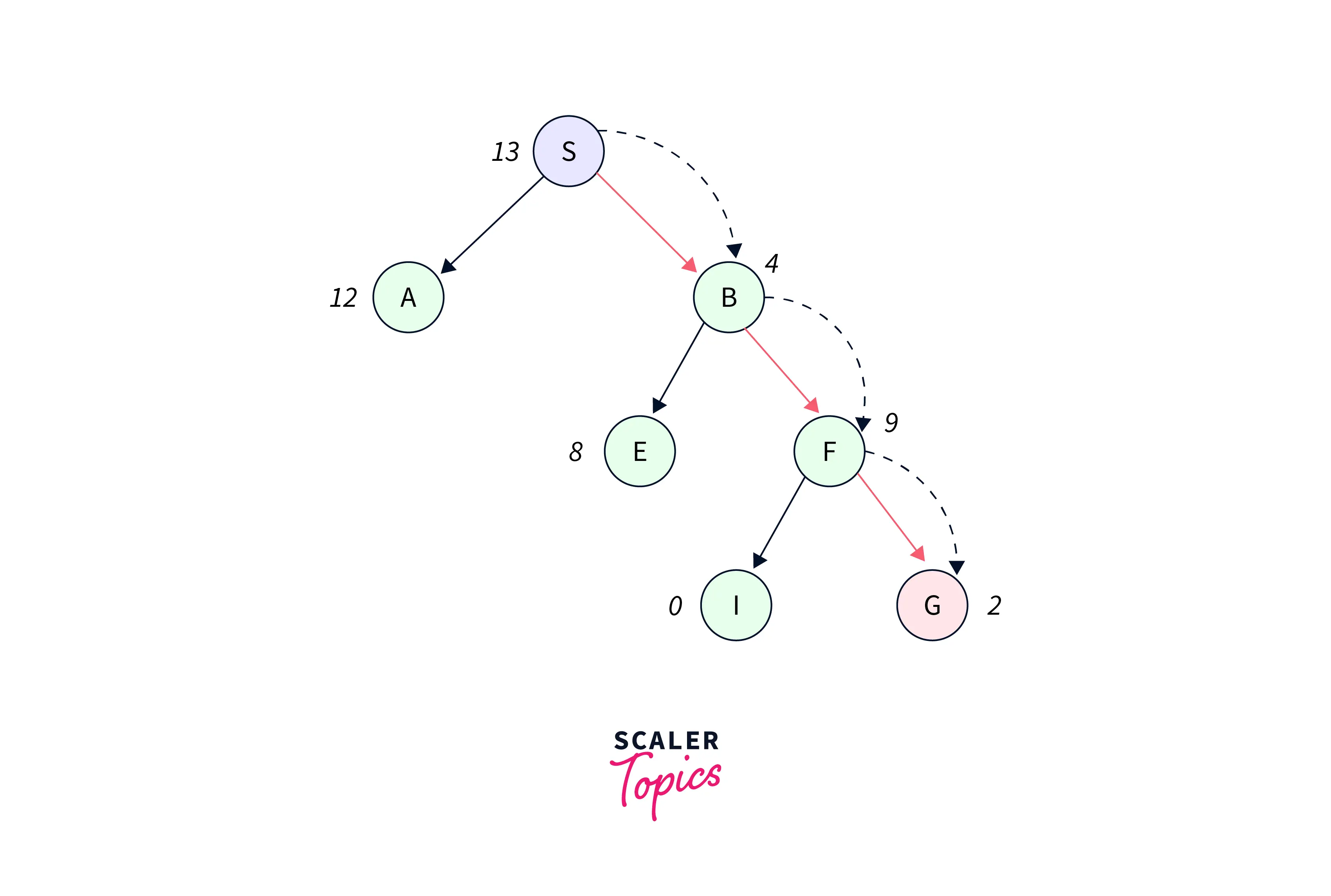 Expand the nodes of S and put them in the CLOSED list
Expand the nodes of S and put them in the CLOSED list
- Initialization: Open [A, B], Closed [S]
- Iteration 1: Open [A], Closed [S, B]
- Iteration 2: Open [E, F, A], Closed [S, B] -> Open [E, A], Closed [S, B, F]
- Iteration 3: Open [I, G, E, A], Closed [S, B, F] -> Open [I, E, A], Closed [S, B, F, G]
Hence the final solution path will be: S->B->F->G
Time complexity: The worst-case time complexity of the Greedy best-first search in artificial intelligence is .
Space Complexity: The worst-case space complexity of Greedy best-first search in artificial intelligence is , where m is the maximum depth of the search space.
B. A* Search Algorithm
To determine the best route from the starting node to the goal node, the A* Search Algorithm combines the cost function and the heuristic function. , where is the cost from the starting node to node n and is the anticipated cost from node n to the goal node, expands the one with the lowest overall cost.
Steps of A* Search Algorithm:
- Set the starting node's g-value to 0 and its h-value to the expected cost of getting there from the starting node.
- Expand the node with the lowest total f(n) cost.
- Stop the search and return the route from the starting node to the goal node if the expanded node is the desired node.
- If not, determine the g-value and h-value, and update the f-value for each neighbor of the expanded node. Finally, add the neighbor to the open list if it's not already there.
- Until the goal node is located or the open list is empty, repeat steps 2-4.
Advantages:
- If the heuristic function is acceptable, which means it never overestimates the real cost, the A* Search Algorithm promises to identify the best course of action.
- Because it only investigates nodes with a good chance of leading to the target, the A* Search Algorithm is effective in terms of time and space complexity.
Disadvantages:
- If infinitely many nodes have a lower total cost than the goal node, the A* Search Algorithm might not be complete.
- If the heuristic function is inadmissible or inconsistent, it overestimates or underestimates the actual cost. Therefore, there may be better options than the A* Search Algorithm.
Example:
Consider the following graph:
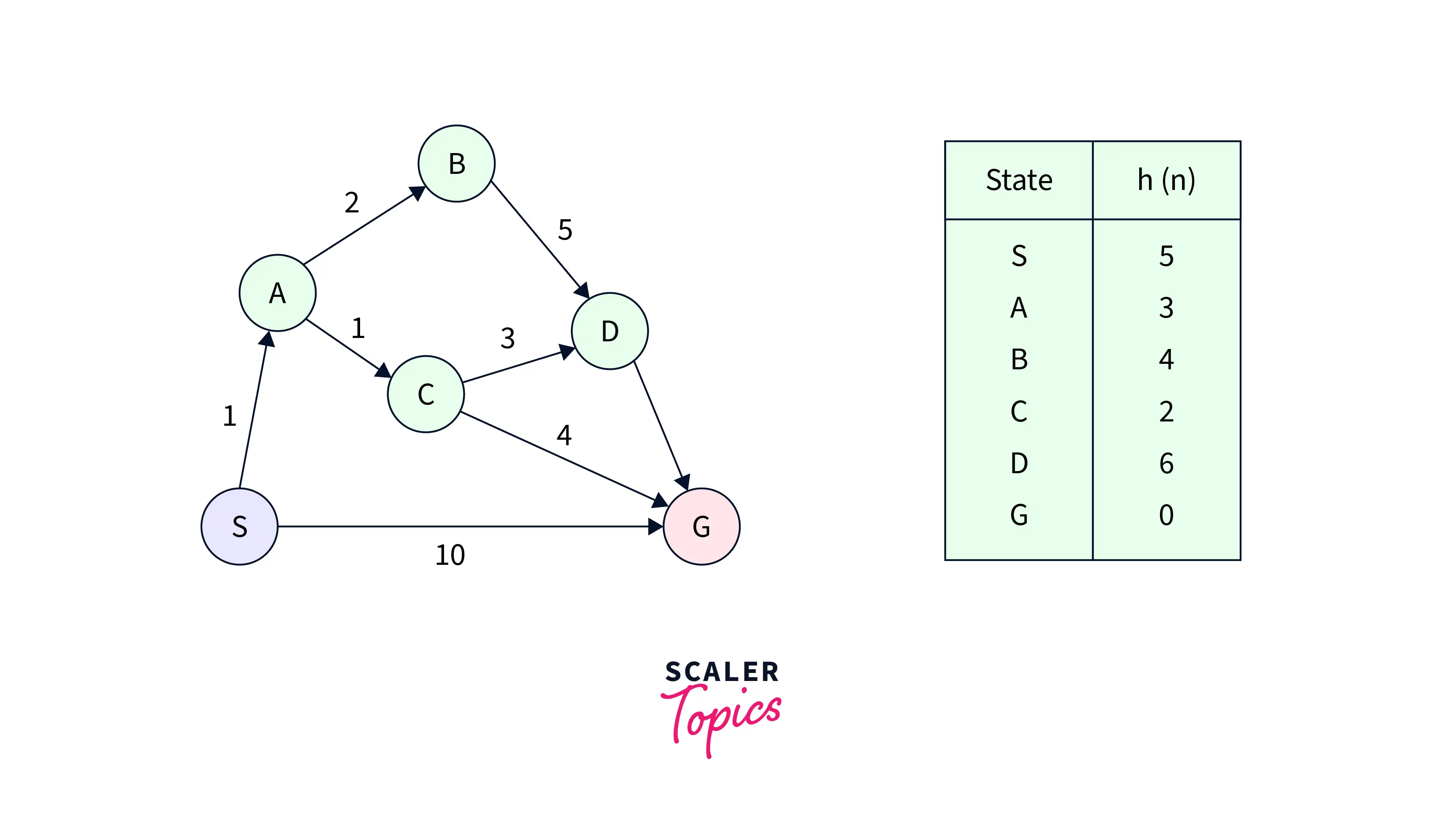 Solution:
In this example, we will traverse the given graph using the A* algorithm. The heuristic value of all states is given in the table so we will calculate the of each state using the formula , where is the cost to reach any node from the start state.
Solution:
In this example, we will traverse the given graph using the A* algorithm. The heuristic value of all states is given in the table so we will calculate the of each state using the formula , where is the cost to reach any node from the start state.
- Initialization: {(S, 5)}
- Iteration1: {(S--> A, 4), (S-->G, 10)}
- Iteration2: {(S--> A-->C, 4), (S--> A-->B, 7), (S-->G, 10)}
- Iteration3: {(S--> A-->C--->G, 6), (S--> A-->C--->D, 11), (S--> A-->B, 7), (S-->G, 10)}
Iteration 4 will give the final result, asS--->A--->C--->Gprovides the optimal path with cost 6.
Let's say we want to identify the best route from node A to node F. The straight-line distance can be used as our heuristic function. From node A to node F, the straight line distance is 5.
The procedure begins at node A, where the f-value is 0 + 5, and moves on to node C where the f-value is 2 + 3 and hence 5. The algorithm then advances to the destination node, node F, with an f-value of 4 + 1 = 5. A -> C -> F is the route from A to F, costing 4.
Time Complexity: The A* search algorithm has a time complexity that depends on the heuristic function, and the number of nodes extended increases exponentially with solution depth d. As a result, the branching factor, b, determines the temporal complexity, which is .
Space Complexity: The A* search algorithm has an space complexity.
Conclusion
- Compared to uninformed search algorithms, informed search algorithms better use heuristic functions to direct the search toward a solution.
- One of the most well-liked informed search algorithms is A*, combining greedy and uniform-cost search benefits.
- The selection of a heuristic function can substantially impact the search algorithm's effectiveness. Heuristic functions can be consistent or acceptable.
- While they may need more computing power and perform worse if the heuristic function is incorrectly chosen, educated search algorithms can be more effective than ignorant search algorithms.
- There are several uses for informed search algorithms, such as in gameplay, puzzle solving, and route planning.