Code Generator in Compiler Design
A code generator in compiler design is a tool that creates the final set of instructions (known as target code) based on three-address statements. It helps in converting a middle-stage representation of the original program into the actual program the computer can run. To put it simply, it transforms a structured representation of the code, often shown as an abstract syntax tree, into machine-dependent executable code by first constructing the abstract syntax tree and then generating the corresponding machine code. This article aims to help you understand these steps in detail.
Register and Address Descriptors
Register Descriptor:
A register descriptor is a data structure that stores details about the registers employed in the program, such as their registration number, name, and type. It keeps track of the current contents of each register.
The compiler relies on this register file when creating machine code for your program to ascertain the values accessible for use in your program. Initially, these descriptors indicate that all registers were blank and provide comprehensive information about each register's status by serving as a container and examining each register to establish whether it holds valid data or not. If a register is empty, it becomes available for other purposes.
Let's see an example:
In this example, the register descriptor would track the information related to registers used for storing a, b, and the result of the addition operation. For instance, it might indicate that register R0 is currently holding the value of a, register R1 is holding the value of b, and so on.
Address Descriptors:
An address descriptor serves as a storage unit for holding the location where the current value of a name can be located during runtime, facilitating access during program execution.
It is a representation of the memory locations used by a program, and it is created by the getReg function. This function returns a structure with information on how to access memory. Users need to invoke getReg method with two arguments when they intend to fetch data from any specified location within the program's source code. The first argument specifies the register containing the desired value, and the second argument specifies where the value should be restored to its original storage location in memory or disk within this register.
This occurs prior to returning the data to the main memory once more, through calls of LoadFromBuffer() or StoreToBuffer() indirectly following successful access to its contents. However, only one instance of an address descriptor exists at any given time unless another thread is executing.
Let's extend the previous example with an additional variable:
Here, the address descriptor for data[index] would specify the memory location where the value is stored. It could involve information about the base address of the array data and the offset calculated using the value of index.
The getReg function, used to create an address descriptor, would determine how to access memory locations. Calling function getReg(data, index) might return a structure indicating that the value is in memory at the address calculated using the base address of data and the offset based on the value of index.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Code Generation Algorithm
The algorithm processes a series of three-address statements, specifically those of the form a := b op c. Here's a breakdown of the steps involved:
- Utilize the getreg function to identify the location (L) where the result of the computation b op c should be stored.
- Check the address description for y to find y'. If the value of y is currently in both memory and register, prefer the register y'. If y is not already in L, generate the instruction MOV y', L to copy y into L.
- Generate the instruction OP z', L, where z' indicates the current location of z.If z is present in both memory and register, prefer a register to a memory location. Update the address descriptor of x to indicate that x is in location L.
- If x is already in L, update its descriptor and remove x from all other descriptors.
- If the current values of y or z have no further uses, are not live on exit from the block, or are not in a register, alter the register descriptor to indicate that after the execution of x := y op z, those registers will no longer contain y or z.
The algorithm operates on a queue of three-address statements, where each statement has the form x: y op z. The algorithm initiates by invoking the getreg function to identify the storage location (L) for the result of y op z. It manages the address descriptor of b, determining b' based on whether the value of b is in both memory and registers. If b is not in L, it generates the instruction MOV b' to copy b into L.
Next, it generates the new instruction OP c', updating the address descriptor of a to indicate that a is now stored in L. If a is already in L, it updates its descriptor and removes a from all other descriptors.
Finally, the algorithm adjusts the register descriptor if b or c have no further uses, are not live on exit, or are not stored in registers, indicating that the registers will no longer contain these values.
Instruction Generation for Operations on Registers
During the instruction generation for operations on registers, your code statements are transformed into machine instructions.
This process relies on details from ELF file format files (created by GCC) and other sources like Bazel's build system, which understands how to generate specific machine code for particular computer processors.
You can think of this step as "register allocation." where we decide which registers will be used for each operation and determine the total number needed. The compiler considers information from previous steps and follows rules about the required registers for specific operations. For instance, a 32-bit addition may need two registers: one to hold the value being added and another for the result of the operation by producing optimized code based on the type of operation being performed (such as addition) and the registers involved (like i32).
Example:
Let's say you have the following code statement in your program:
During instruction generation, the compiler allocates registers for this addition operation. It decides which registers will store the values of 'a' and 'b' and another register for the result. The specific registers chosen and the instructions generated will depend on the rules and optimization strategies employed by the compiler for this particular type of operation on your CPU architecture.
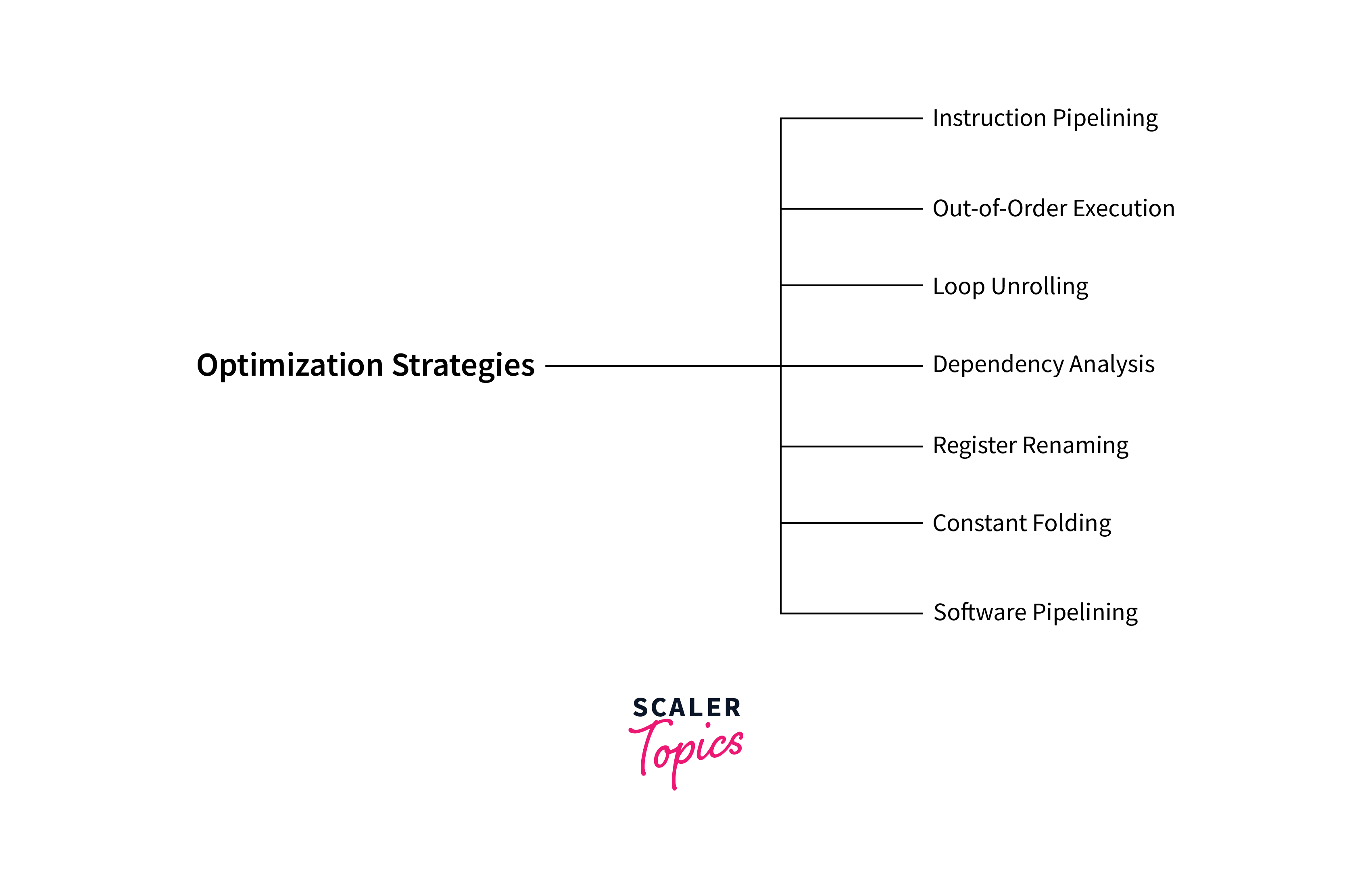
We will now see the optimization strategies used by compiler to enhance the performance of the generated code with the aim to make the best use of the available hardware resources and exploit parallelism, ultimately leading to faster and more efficient execution of the program.
-
Instruction Pipelining:
Instruction Pipelining allows multiple instructions to be in various stages of execution simultaneously resulting in reduced execution time and a more efficient processor. -
Out-of-Order Execution:
Here, the processor executes instructions as soon as their operands are available, rather than strictly following the program order. This can lead to better utilization of resources. -
Loop Unrolling:
Identify loops in the code and unroll them, duplicating the loop body to reduce loop overhead. This will help in creating additional opportunities for instruction-level parallelism. -
Dependency Analysis:
Dependencies between instructions are identified for scheduling instructions to maximize parallelism while avoiding data hazards. -
Register Renaming:
Implement register renaming to reduce register pressure by assigning multiple virtual registers to a single physical register (to manage limited hardware resources). -
Software Pipelining:
Apply software pipelining to overlap the execution of multiple iterations of a loop. This helps in enhancing instruction-level parallelism and can lead to improved performance. -
Constant Folding:
Perform constant folding to eliminate unnecessary instructions and replace constants in the code with their computed values to reduce the number of instructions executed.
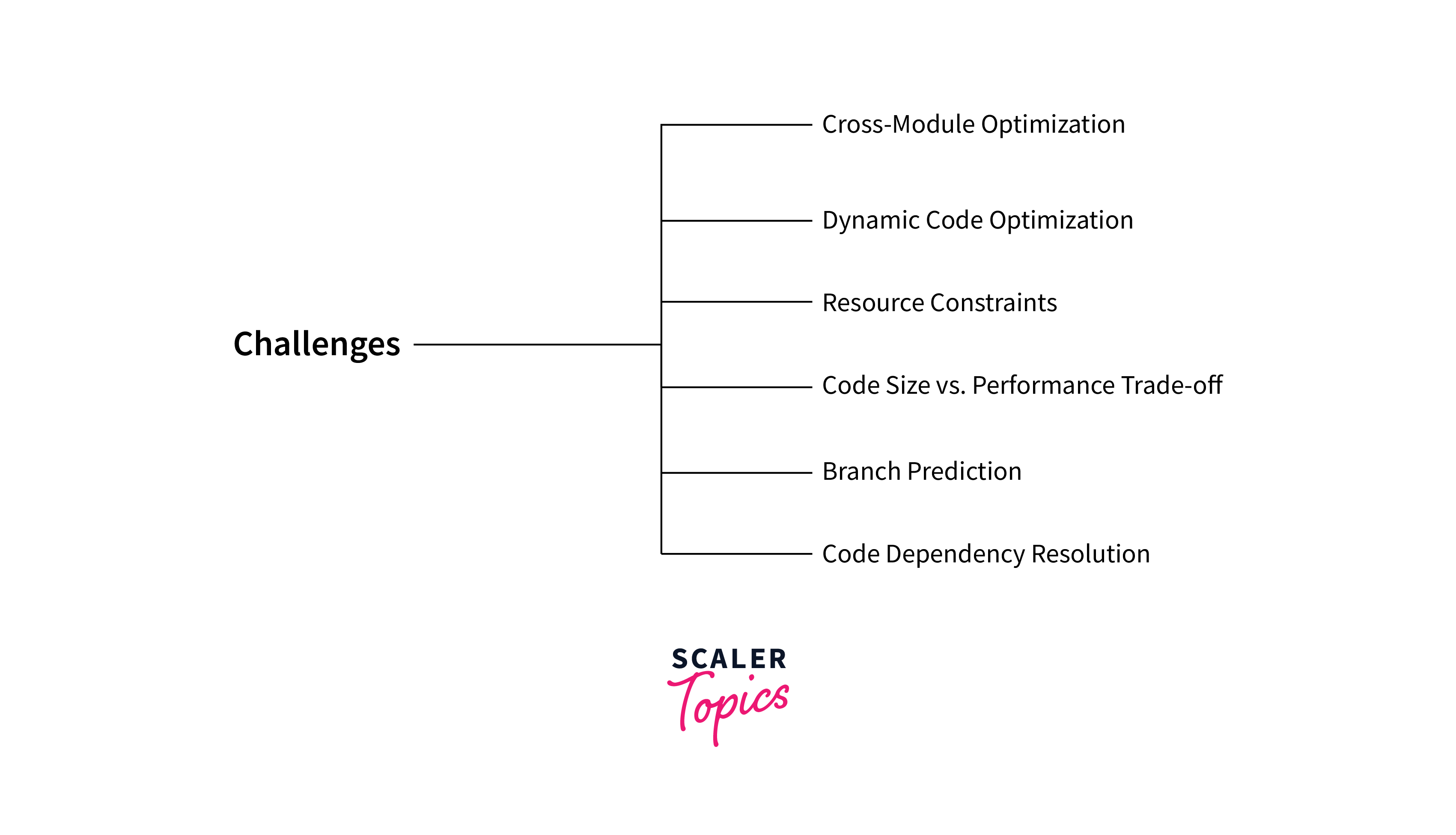
Also, we will see what are the challenges that compiler faces while trying to generate the optimized code. Let's see few of them:
-
Resource Constraints:
Balancing the allocation of limited resources to different instructions without causing bottlenecks is a challenging aspect of instruction scheduling -
Code Size vs. Performance Trade-off:
While optimizing for performance, it's essential to consider the potential increase in code size, as larger code sizes may lead to longer memory access times. Thus, right balance between code size and performance is must. -
Branch Prediction:
Improper handling of branches can result in pipeline stalls and decreased performance. -
Code Dependency Resolution:
Identifying and mitigating dependencies is crucial for maintaining a smooth instruction flow and preventing stalls in the pipeline. -
Cross-Module Optimization:
Coordinating instruction scheduling across different parts of the program can be challenging but is essential for achieving global optimization benefits. -
Dynamic Code Optimization:
Here, compiler adapts its optimization strategies based on runtime behavior. This involves making decisions during program execution, introducing additional complexity.
Turn Learning into Career Growth
Generating Code
The provided assignment statement
can be represented as a sequence of three-address codes in a queue:
The corresponding code sequence for the given problem is expressed as:
Output:
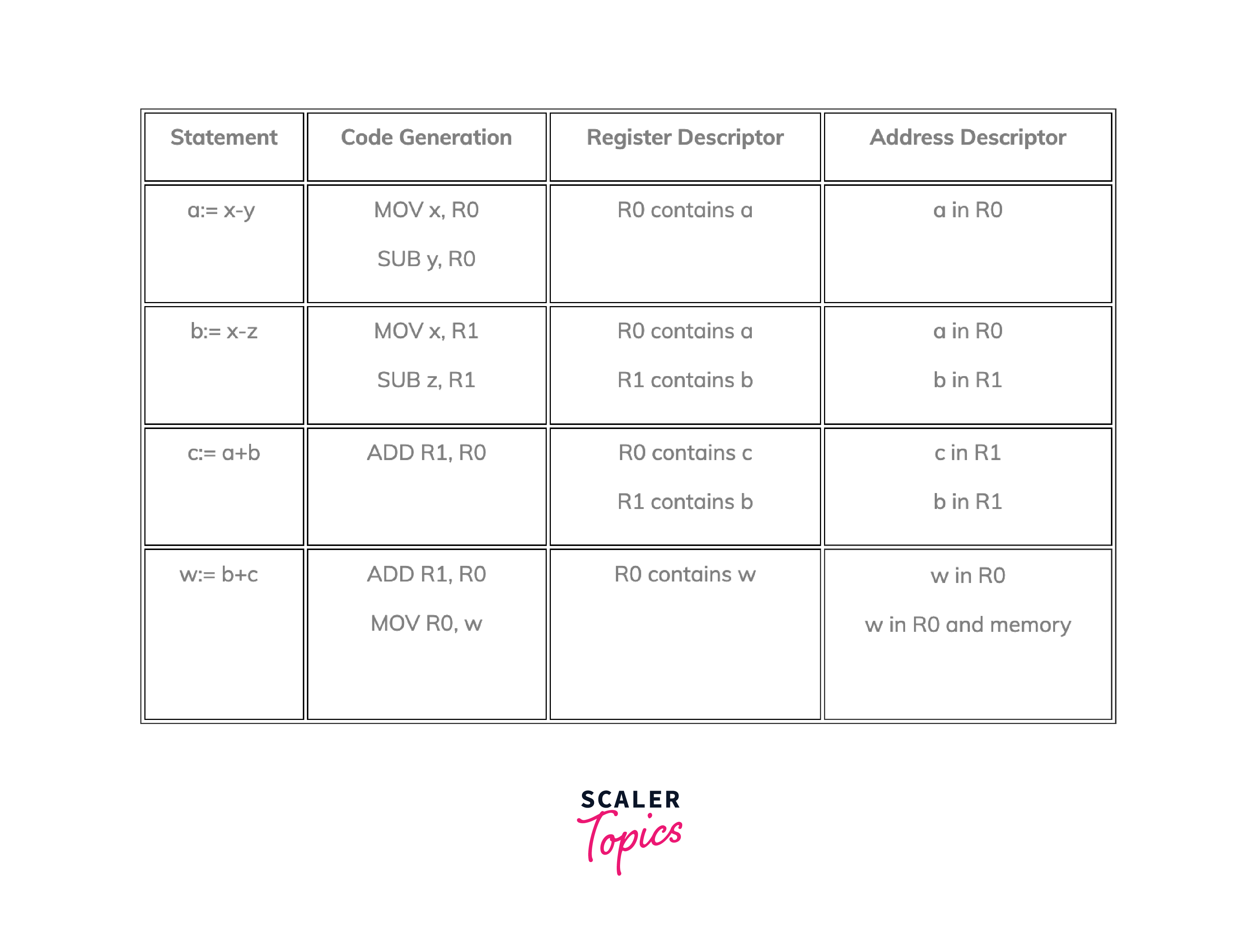
Code Generation:
- For a := x - y, it generates the assembly-like code MOV x, R0 (moves the value of x to register R0) and SUB y, R0 (subtracts the value of y from the content of R0).
- For b := x - z, it generates MOV x, R1 and SUB z, R1.
- For c := a + b, it generates ADD R1, R0 (adds the content of R1 to the content of R0).
- For w := b + c, it generates ADD R1, R0 and MOV R0, w.
Register Descriptor:
- After a := x - y, R0 contains the value of a.
- After b := x - z, R1 contains the value of b.
- After c := a + b, R0 contains the value of c.
- After w := b + c, R0 contains the value of w.
Address Descriptor:
- For each assignment, it indicates that the values are directly stored in registers (R0, R1).
Instruction Scheduling
Instruction scheduling is like organizing a to-do list for a computer. We rearrange the tasks (instructions) so that the computer can do them in the best way on its specific type. We look at how the computer works and figure out the most efficient order for tasks. We also think about things like having enough space to keep information and if there's any delay in the process. It's like planning the steps for a computer to work smoothly.
Conclusion
- Code generator in compiler design translate source code into machine instructions for execution.
- Register descriptors store information about registers, including registration number and type.
- Address descriptors represent memory locations used by a program.
- The code generation algorithm involves setting up descriptors and generating machine instructions.
- Instruction scheduling organizes tasks for efficient execution on a specific CPU architecture.