Outlier Analysis in Data Mining
Overview
Outlier analysis in data mining involves identifying and analyzing data points significantly different or deviating from the rest of the dataset. Outliers can be caused by various factors, such as data entry errors, unexpected events, etc., and their detection can lead to valuable insights and improve the accuracy of models. A wide range of techniques can be used for outlier analysis in data mining, such as statistical methods, clustering algorithms, and machine learning models.
What is Outlier Analysis in Data Mining
Outlier analysis in data mining is the process of identifying and examining data points that significantly differ from the rest of the dataset. An outlier can be defined as a data point that deviates significantly from the normal pattern or behavior of the data. Various factors, such as measurement errors, unexpected events, data processing errors, etc., can cause these outliers. For example, outliers are represented as red dots in the figure below, and you can see that they deviate significantly from the rest of the data points. Outliers are also often referred to as anomalies, aberrations, or irregularities.
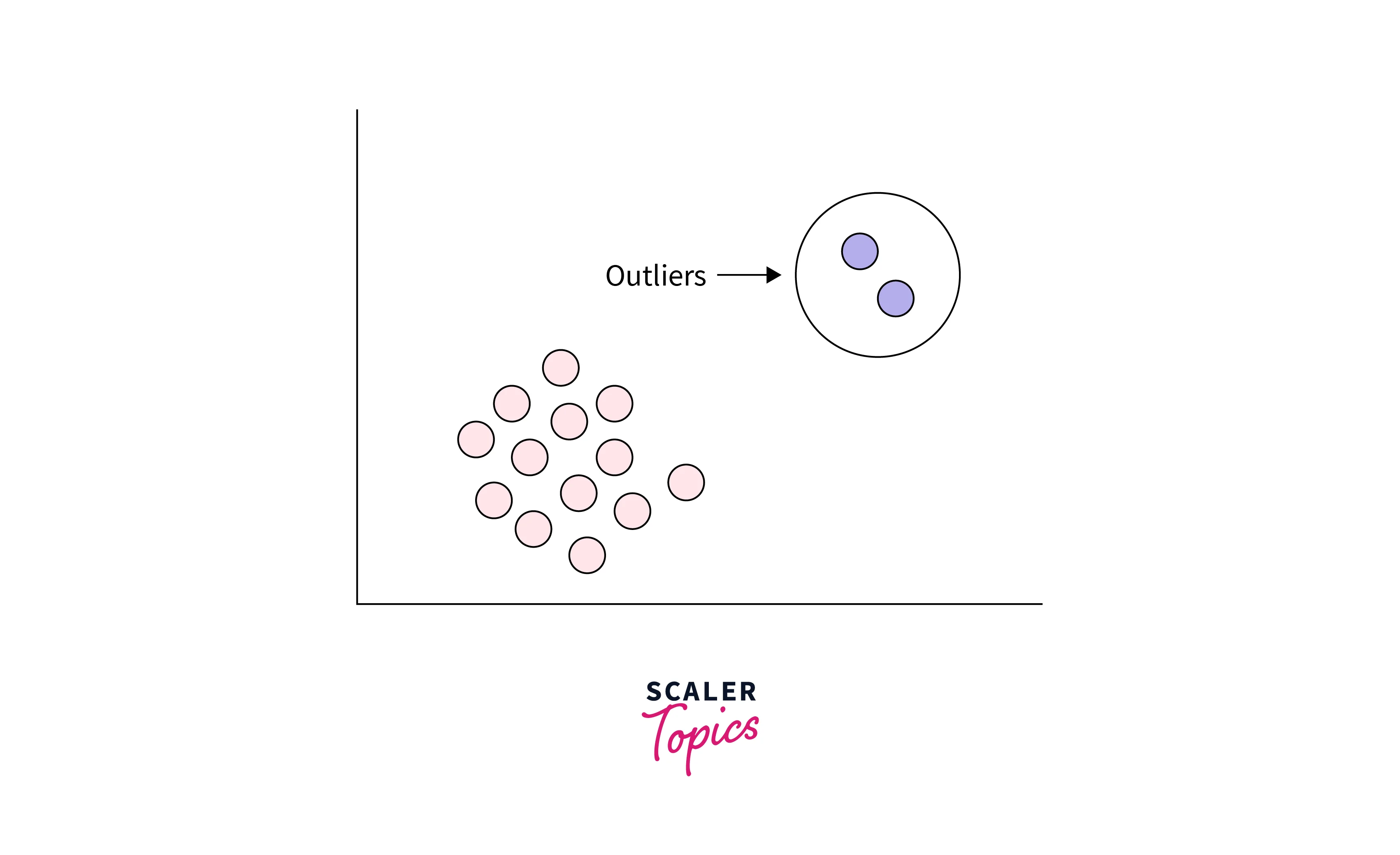
The next question that comes to our mind is whether outliers are the same as noise in the data. Outliers and noise are fundamentally different concepts, so let’s understand how outliers differ from noise.
Outliers vs. Noise
In data mining, noise refers to random variations or errors in the data that have no significant meaning or pattern. Noise can arise from various sources, such as measurement errors or data collection methods, and it can negatively affect the accuracy and reliability of data analysis. On the other hand, outliers can provide valuable insights and may need to be studied further, but they can also skew statistical analyses or predictive models if not handled properly.
Overall, the main difference between outliers and noise is that outliers are significant and potentially informative, while noise is insignificant and can be detrimental to data analysis.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Benefits of Outlier Analysis in Data Mining
Outlier analysis in data mining can provide several benefits, as mentioned below -
- Improved accuracy of data analysis - Outliers can skew the results of statistical analyses or predictive models, leading to inaccurate or misleading conclusions. Detecting and removing outliers can improve the accuracy and reliability of data analysis.
- Identification of data quality issues - Outliers can be caused by data collection, processing, or measurement errors, which can indicate data quality issues. Outlier analysis in data mining can help identify and correct these issues to improve data quality.
- Detection of unusual events or patterns - Outliers can represent unusual events or patterns in the data that may be of interest to the businesses. Studying these outliers can provide valuable insights and lead to discoveries.
- Better decision-making - Outlier analysis in data mining can help decision-makers identify and understand the factors affecting their data, leading to better-informed decisions.
- Improved model performance - Outliers can negatively affect the performance of predictive models. Removing outliers or developing models that can handle them appropriately can improve model performance.
Types of Outliers in Data Mining
Let’s understand various types of outliers in the data mining process -
Global (Point) Outliers
These are data points that are significantly different from the rest of the dataset in a global sense. Global outliers are typically detected using statistical methods focusing on the entire dataset's extreme values. For example, if we have a dataset of heights for a group of people, and one person is 7 feet tall while the rest of the heights range between 5 and 6 feet, the height of 7 feet would be a global outlier. An example of a global outlier is also shown below -
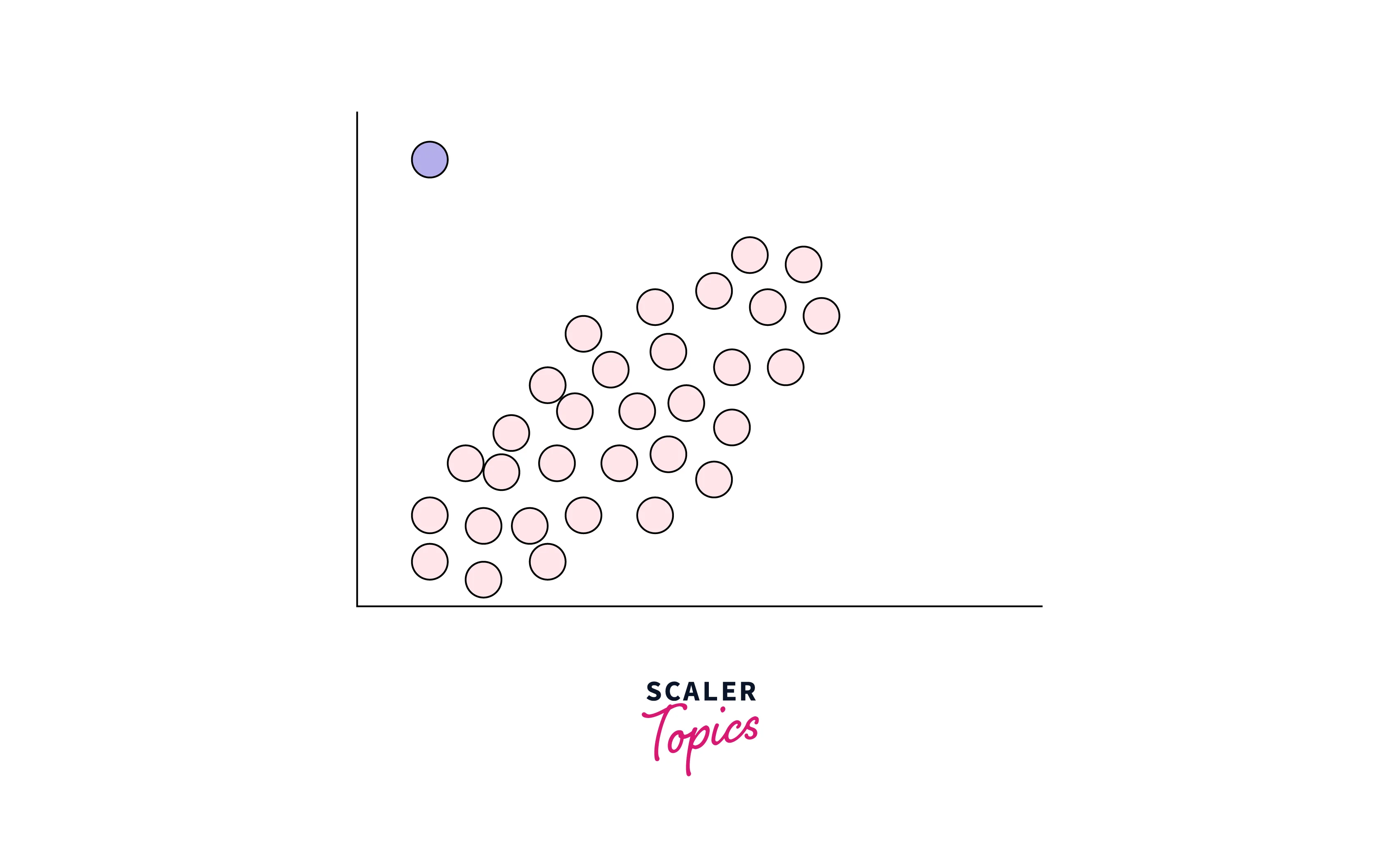
Turn Learning into Career Growth
Collective Outliers
These are groups of data points that are significantly different from the rest of the dataset when considered together. Collective outliers are typically detected using clustering algorithms or other methods that group similar data points. For example, suppose we have a dataset of customer transactions, and a group of customers consistently makes purchases that are significantly larger than the rest of the customers. In that case, this group of customers could be considered a collective outlier. Similarly, in an intrusion detection system, the transmission of a DOS packet from one PC to another PC can be considered normal behavior, but if DOS packets are transmitted to many PCs at the same time, it would be considered as collective outliers.
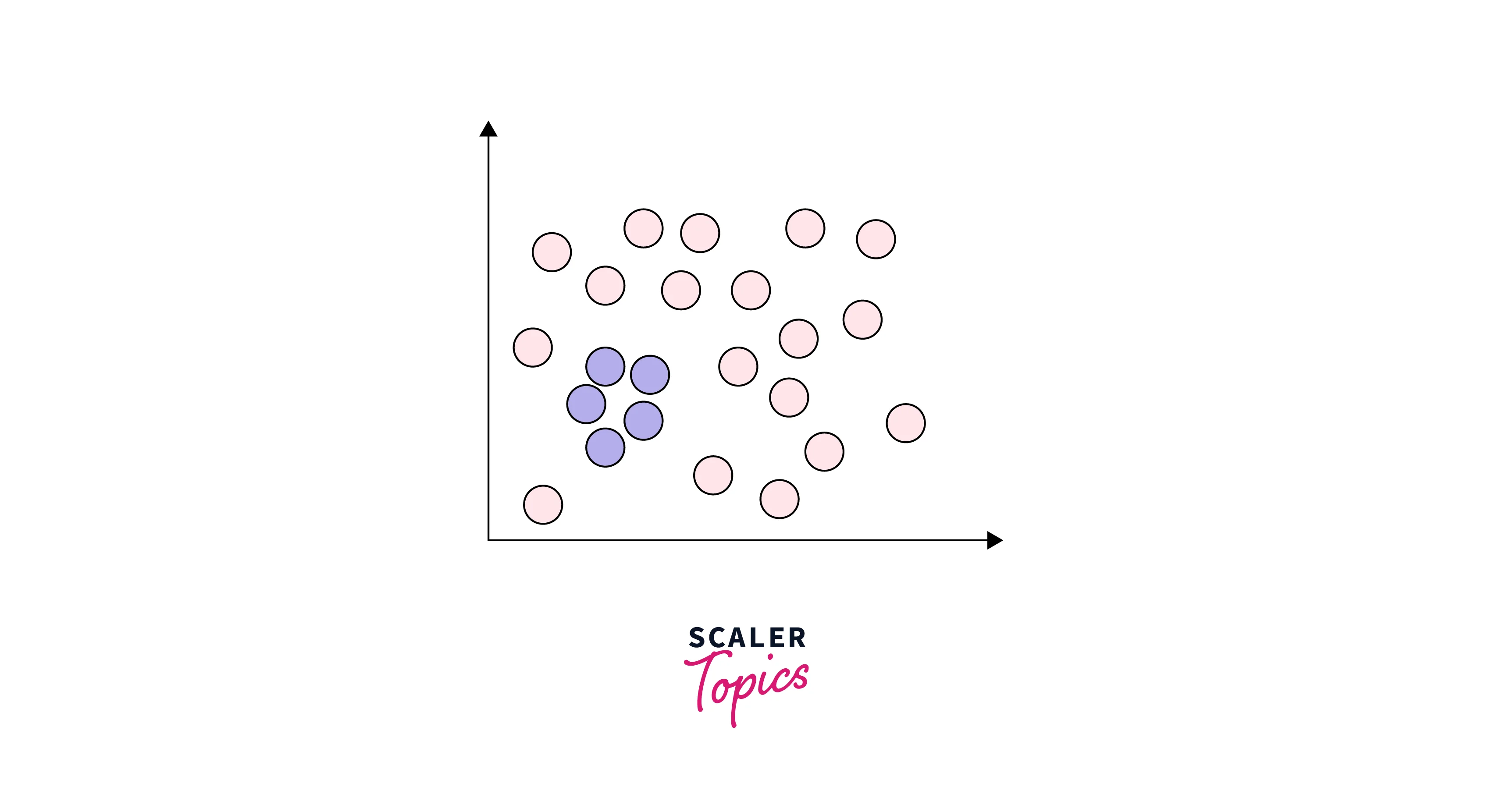
Contextual (Conditional) Outliers
These data points significantly differ from the rest of the dataset in a specific context. Contextual outliers are typically detected using domain knowledge or contextual information relevant to the dataset. For example, if a city is recording 40-degree Celsius temperature, it may be considered normal in the summer and a contextual outlier in the winter. An example of a contextual outlier is shown below -
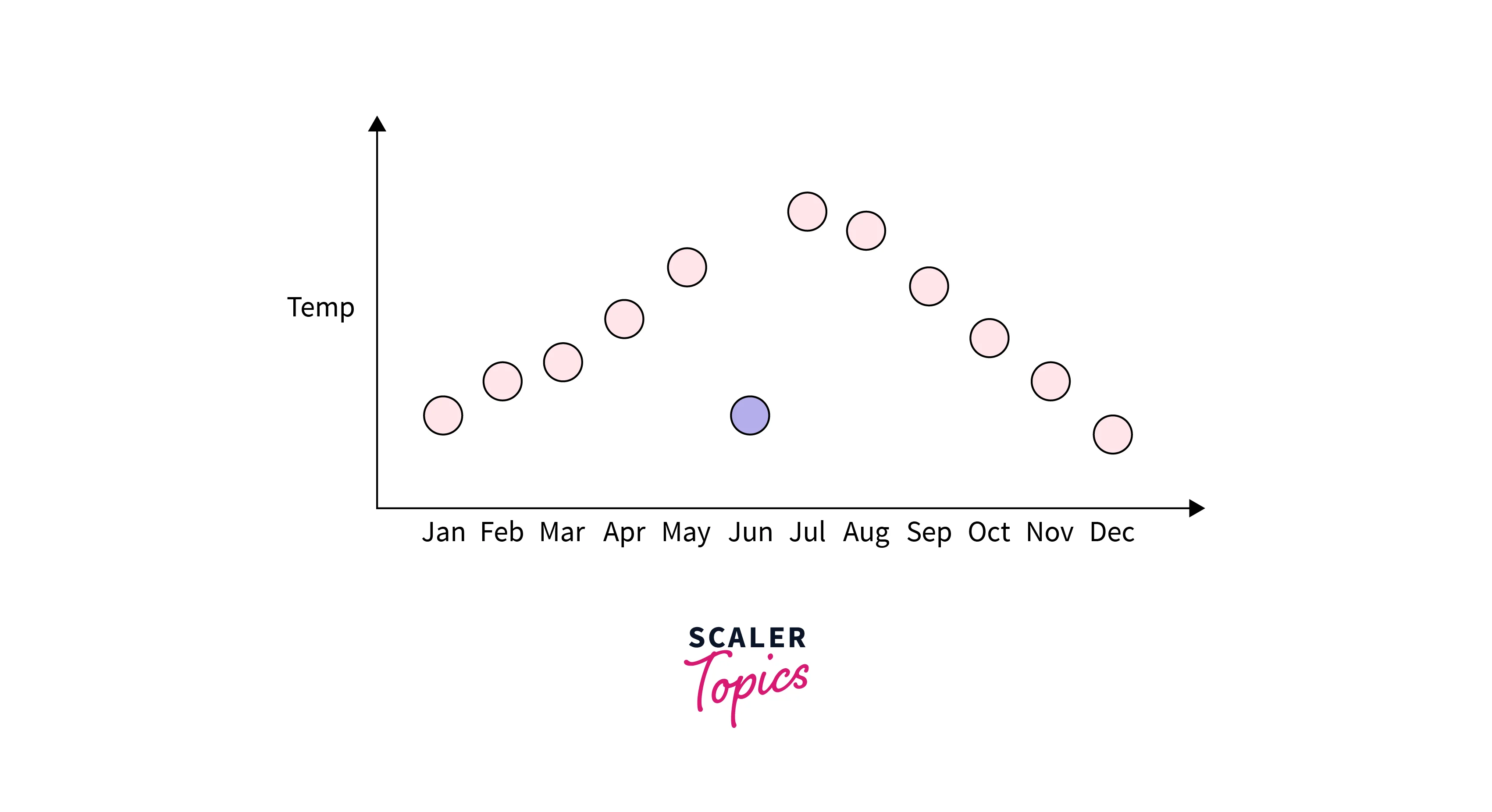
Eager to Explore Further in the Data Science Domain? Checkout Scaler's Data Science Courses and Master Data Science from Industry experts.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
How and When to Do Outlier Analysis in Data Mining?
Outlier analysis is an important step in data mining as it helps identify and deal with anomalies in the data. Here are some steps involved in the outlier analysis -
- Identify the data type - Before performing outlier analysis, it is important to identify the data type being analyzed, as this can impact the choice of outlier detection methods. For example, if the data is continuous, statistical methods such as z-scores can be used, while for categorical data, methods such as the chi-squared test can be used.
- Understand the context - It is important to understand the context in which the data was collected, as this can impact what constitutes an outlier. For example, a temperature reading of 40°C might be normal for one location but an outlier for another.
- Choose appropriate methods - Once the data type and context have been identified, appropriate outlier detection methods can be chosen. This could include statistical methods, machine learning algorithms such as clustering, or a combination of both.
- Evaluate and interpret results - After performing the outlier analysis, evaluating and interpreting the results is important. This involves understanding the outliers detected, determining whether they are genuine anomalies or errors in the data, and deciding on the appropriate actions. This could include removing outliers from the dataset, investigating further to understand the cause of the outliers, or simply noting the presence of outliers without taking further action.
In terms of when to do outlier analysis, it is typically performed as part of the data preprocessing phase before any modeling or analysis is carried out. Outlier analysis can be especially important when working with large datasets or complex data containing many different types of outliers. It is also important to re-evaluate outlier analysis periodically, as new data may reveal previously undetected outliers.
Applications of Outlier Analysis
Outlier analysis has many applications in various fields, as mentioned below -
- Finance - In finance, outlier analysis is used to identify abnormal fluctuations in stock prices or financial transactions, which can indicate fraud or insider trading.
- Healthcare - Outlier analysis is used in healthcare to identify patients with rare or unusual medical conditions or to detect abnormal patterns in medical data that can help diagnose diseases.
- Manufacturing - In manufacturing, outlier analysis is used to identify defective products or equipment producing out-of-specification results, which can affect the quality of the final product.
- Marketing - Outlier analysis is used to identify customers with high or low purchasing habits, which can help businesses create targeted marketing campaigns and promotions.
- Environmental science - Outlier analysis is used in environmental science to identify extreme weather events or natural disasters, which can help predict and mitigate the impact of these events on human populations and ecosystems.
- Cybersecurity - Outlier analysis is used in cybersecurity to detect abnormal network behavior or suspicious activity, indicating cyberattacks or data breaches.
FAQs
Q: What is an outlier in data mining?
A: In statistics, an outlier is an observation or data point that significantly differs from other observations in the dataset. Measurement errors, data entry errors, or legitimate deviations in the data can cause outliers.
Q: Why is outlier analysis important?
A: Outlier analysis is important because it can help identify anomalous data points that can affect the overall analysis and interpretation of the data. By detecting and handling outliers appropriately, data scientists can improve the accuracy and reliability of their results.
Don't just analyze data; master it. Join our Data Science free course and elevate your skills to tackle complex real-world challenges.
Conclusion
- In data mining, outlier analysis is an important technique used in various fields to identify and analyze unusual or anomalous data points.
- By detecting and handling outliers appropriately, statisticians and data scientists can improve the accuracy and reliability of their results.
- Outliers can be identified using various methods and can be removed, transformed, or treated in other ways to minimize their impact on the analysis.