Handling Missing Values- Categorical & Numerical

Overview
Data Cleaning is an important step in the Machine Learning modeling process. Data Cleaning can be defined as a process of correcting or removing inaccurate, corrupted, duplicate, or incomplete data. One of the most common issues Data Scientists and Data Analysts face during this step is how to deal with missing values. Let’s get into why handling missing values is important and review some of the methods to deal with missing values.
Introduction
Real-world datasets are messy and contain missing values. Sometimes missing values are also referred to as NULL or NaN values. It is essential to handle missing values in a dataset before performing EDA and developing ML models on it. Let’s see why it is important to handle missing values and how it can impact your analysis and modeling.
How Does Missing Data Affect Your Algorithms
If missing values are not properly dealt with and imputed, a Data Scientist or Researcher may come up with inaccurate insights or assumptions about the data during the EDA stage, which subsequently can have a significant impact on the ML modeling phase. Missing values can also reduce the true representativeness of the dataset and result in the reduced statistical significance of the analysis performed.
Also, if you just keep the missing values as it is, many ML model algorithms will throw an error during the training phase as they can’t handle missing values inherently.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
What Can Cause Missing Data?
In today’s world, organizations are collecting data from a variety of sources such as surveys, sensors, systems, etc. The causes for missing values in a dataset depend on how it has been collected. In the case of surveys, many people don’t prefer to fill out the entire form due to numerous reasons such as privacy, no knowledge regarding questions, etc., and it can lead to missing values in the data. There could be a technical glitch or loss of communication with the sensors or systems, which can further result in missing or inconsistent values in the final data.
In some cases, data could be missing for legitimate reasons as well. E.g., delivery time for a food order will be missing or empty if the order is en route and not yet delivered.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
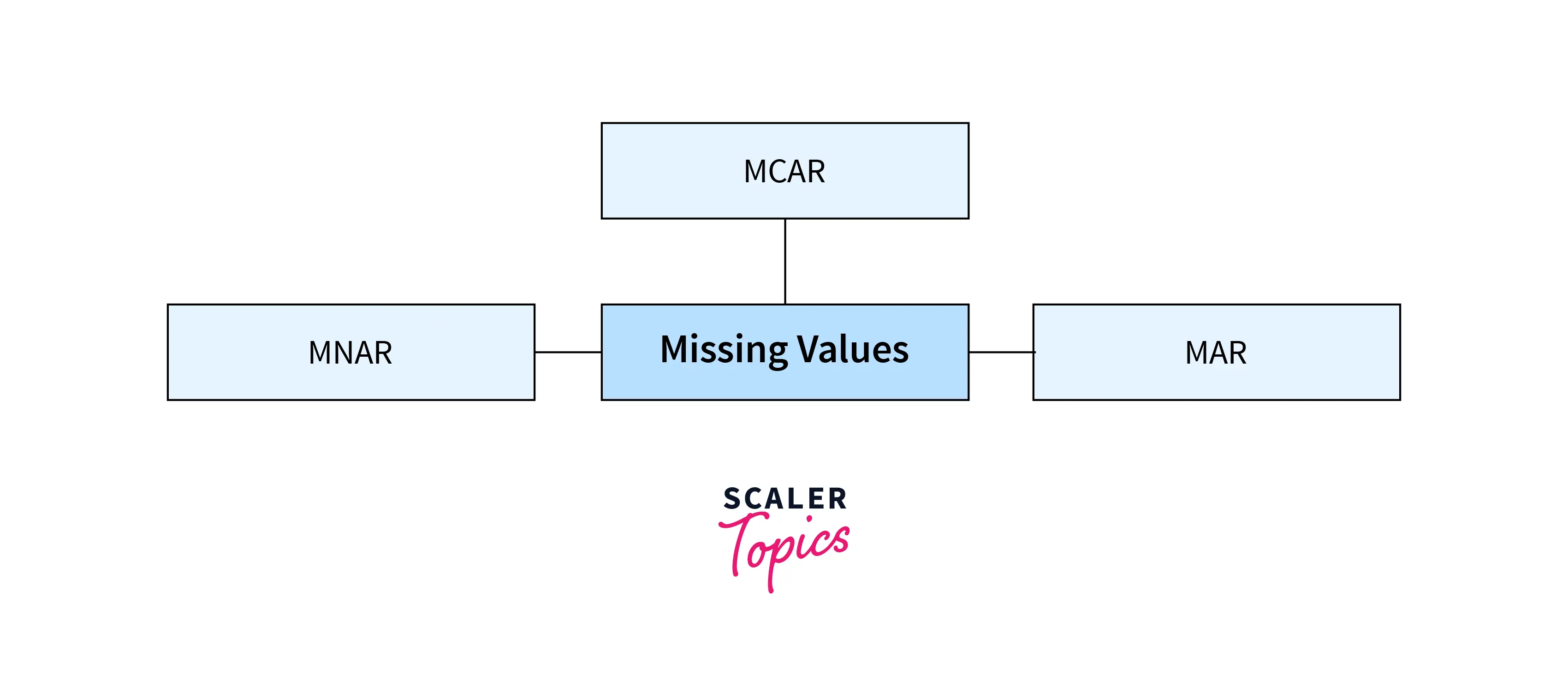
Type of Missing Values
Missing values can be categorized into three categories as mentioned below -
- Missing Completely at Random (MCAR) - In this case, missing values are randomly distributed across the variable, and it is assumed that other variables can’t predict the missing value.
- Missing at Random (MAR) - In MAR, missing data is randomly distributed, but it can be predicted by other variables/data points. For example, sensors could not log data for a minute due to a technical glitch, but it can be interpolated by previous and subsequent readings.
- Missing Not at Random (MNAR) - In this case, missing values are not random and missing systematically. For example, people avoid certain information while filling out surveys.
How to Handle Missing Data?
There are many ways you can remove or impute missing values in a dataset. How you handle missing values also depends on the type of variable, i.e., numerical or categorical, as some methods work only on one kind of variable.
Let’s also apply these methods to a customer segmentation dataset. You can download this data from here - (https://www.kaggle.com/datasets/vetrirah/customer?resource=download). Let’s first perform a basic EDA on this dataset to check how many values are missing and in which variables. It has a total of 8068 records and 11 variables in it.
Output:
As you can see, there are 6 variables that contain missing or NULL values. These variables are a mix of categorical and numerical values. Now let’s review some of the most common methods to deal with these missing values.
Removal
- This is the easiest way to handle missing values. You can either remove rows or columns containing missing values. However, this can result in the loss of important data points and can lead to less accuracy during the ML modeling phase. This approach works well when there are only a very few rows that contain missing values or columns that contain missing data that are not important or relevant to the accuracy of the ML models.
- You can use pandas_ library’s _dropna function to remove rows/columns containing missing values
Output:
Output:
Turn Learning into Career Growth
Imputation
Imputation of missing values is considered the best option, as removing them will lead to less number of records which can impact the accuracy of the ML models. Let’s review some of the most common imputation methods for missing values -
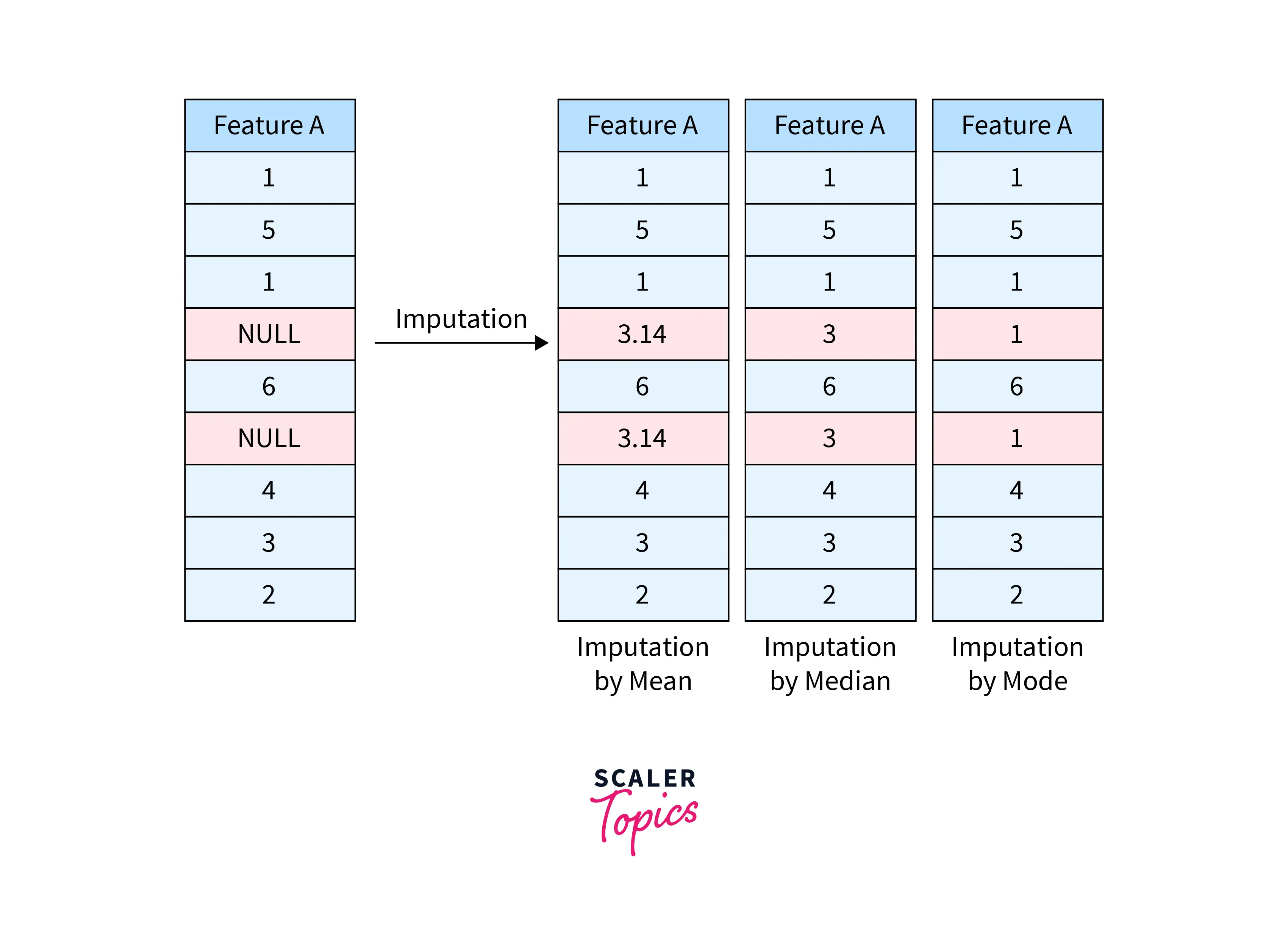
Imputation by Mean
- In this approach, you can replace missing values of a column by computing its mean/average. However, this approach only works for numerical variables. This method is simple, fast, and works well for small datasets.
- There are some limitations as well with this approach, such as outliers in a column can result in skewed mean that can impact the accuracy of the ML model. Also, this approach does not consider feature correlation while imputing the missing values.
- You can use the fillna function to impute the missing values by column mean.
Imputation by Median
- To handle the outlier issue in imputation by mean, you can replace the NULL values with the column’s median. This approach also works only with numerical variables and ignores feature correlations.
Imputation by Mode (Most Frequent Values)
- In this method, you can impute the missing or NULL values by the most frequent or common value in the column. The advantage of this method is that it can work with both numerical and categorical features. However, it ignores feature correlations, just like previous approaches.
- You can use Scikit-learn’s SimpleImputer class for this imputation method. This class also works for imputation by mean and median approaches as well.
Imputation by KNN (Nearest Neighbor Approach)
- In the K-Nearest-Neighbor imputation approach, a sample containing missing values is replaced by identifying other samples which are closest to it. The idea in the KNN method is to first identify the closest k samples/neighbors and then use these k samples to estimate the values of missing points.
- You can use Scikit-learn’s KNNImputer class to handle NULL values with this approach.
Imputation by MICE (Multiple Imputation by Chained Equations)
- MICE is an iterative process in which each feature’s missing values are predicted by the rest of the features, and this process is followed for all features.
- Suppose you have three features - age, height, and weight. We can first initialize MICE by imputing missing values in each feature using the SimpleImputer class. After that, missing values in the age feature can be predicted by other features height and weight by running a regression model on them. Then this process is followed for the rest of the features as well. The main advantage of this method is that it considers feature correlations while imputing the missing values.
- You can use Scikit-learn’s IterativeImputer class to perform MICE to replace missing values.
Flagging
In some cases, NULL or missing values represent information and need not be imputed. For example, the discharge date for a patient might be missing as they have not been discharged yet, or delivery time will be missing for the orders if they are en route. This information can be used to create a flag column to signify whether the patient has been discharged or the order has been delivered.
Last Observation Carried Forward (LOCF)
In the case of longitudinal data, where data is collected through a series of repeated observations for the same subject, LOCF can be used to handle missing values. In LOCF, missing values are imputed with the last observed values for the subject.
Interpolation - Linear
Linear interpolation is an imputation technique that assumes a linear relationship between data points and utilizes adjacent non-missing values to compute values for a missing data point.
Algorithms That Support Missing Values
Most of the ML model algorithms require the imputation of missing values before fitting them, but there are some ML algorithms that can support NULL or missing values by default. A few of the most common algorithms that support NULL values are XGBoost, Naive Bayes, KNN, LightGBM, Random Forest, etc.
Conclusion
- It is important to handle missing values as they can lead to inaccurate conclusions about the data, which can significantly impact the accuracy of the analysis.
- There are several methods available to handle missing values, such as removal, imputation, flagging, etc. You can use libraries available in Python language to handle missing values in your dataset.