Data Preprocessing in Data Science

Overview
Data Preprocessing can be defined as a process of converting raw data into a format that is understandable and usable for further analysis. It is an important step in the Data Preparation stage. It ensures that the outcome of the analysis is accurate, complete, and consistent.
Understanding Data
The main objective of Data Understanding is to gather general insights about the input dataset that will help to perform further steps to preprocess data. Let’s review two of the most common ways to understand input datasets :
Data Types
Data Type can be defined as labeling the values a feature can hold. The data type will also determine what kinds of relational, mathematical, or logical operations can be performed on it. A few of the most common data types include Integer, Floating, Character, String, Boolean, Array, Date, Time, etc.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
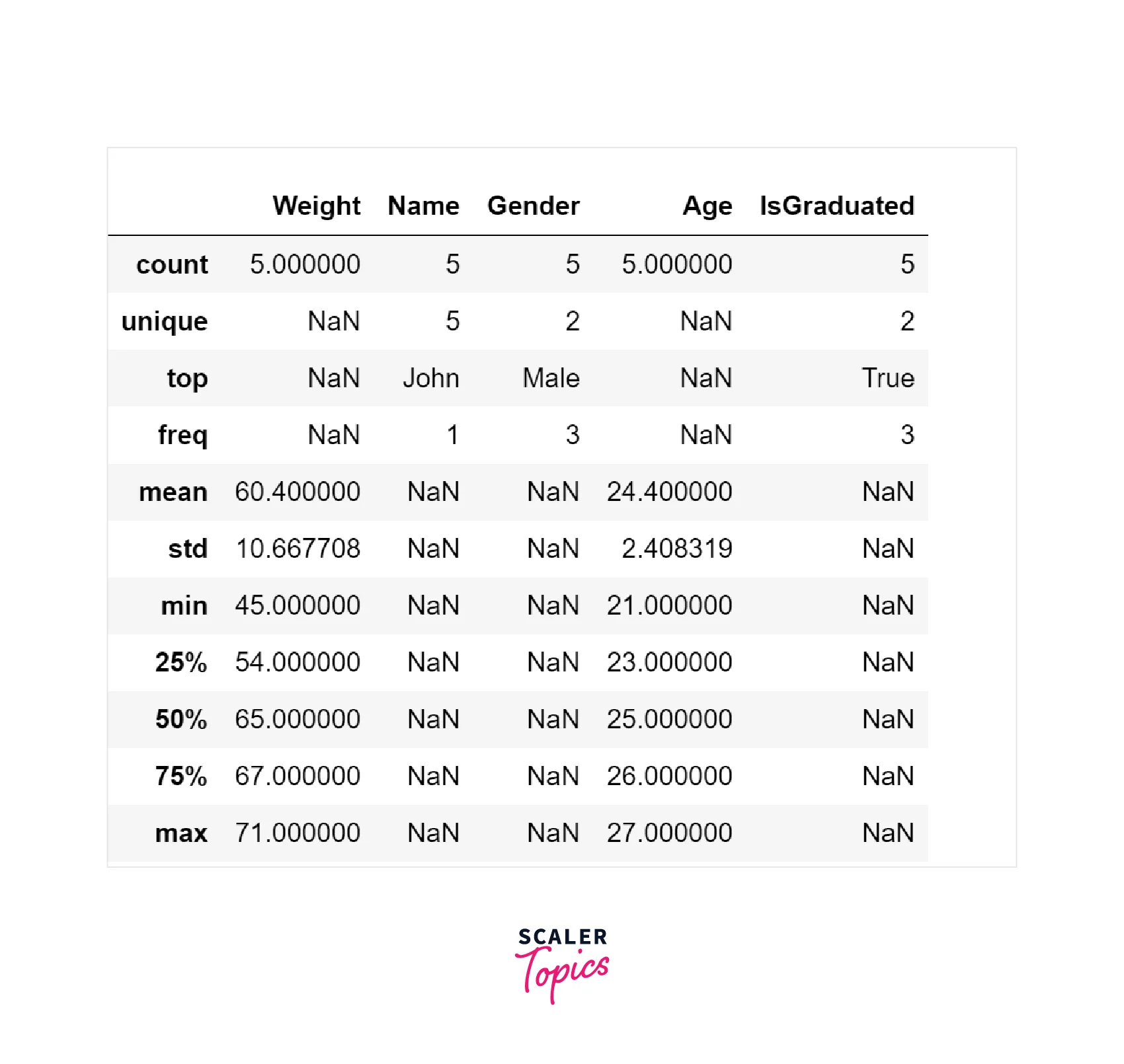
Data Summary
Data Summary can be defined as generating descriptive or summary statistics for the features in a given dataset. For example, for a numeric column, it will compute mean, max, min, std, etc. For a categorical variable, it will compute the count of unique labels, labels with the highest frequency, etc.
Let’s see below how we can apply the above two methods in Python language on a Pandas data frame :
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
What is Data Preprocessing
Real-world datasets are generally messy, raw, incomplete, inconsistent, and unusable. It can contain manual entry errors, missing values, inconsistent schema, etc. Data Preprocessing is the process of converting raw data into a format that is understandable and usable. It is a crucial step in any Data Science project to carry out an efficient and accurate analysis. It ensures that data quality is consistent before applying any Machine Learning or Data Mining techniques.
Ready to dive into the world of data science? Join our free Data Science course and unlock the secrets to harnessing the power of data.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Why is Data Preprocessing Important
Data Preprocessing is an important step in the Data Preparation stage of a Data Science development lifecycle that will ensure reliable, robust, and consistent results. The main objective of this step is to ensure and check the quality of data before applying any Machine Learning or Data Mining methods. Let’s review some of its benefits -
- Accuracy - Data Preprocessing will ensure that input data is accurate and reliable by ensuring there are no manual entry errors, no duplicates, etc.
- Completeness - It ensures that missing values are handled, and data is complete for further analysis.
- Consistent - Data Preprocessing ensures that input data is consistent, i.e., the same data kept in different places should match.
- Timeliness - Whether data is updated regularly and on a timely basis or not.
- Trustable - Whether data is coming from trustworthy sources or not.
- Interpretability - Raw data is generally unusable, and Data Preprocessing converts raw data into an interpretable format.
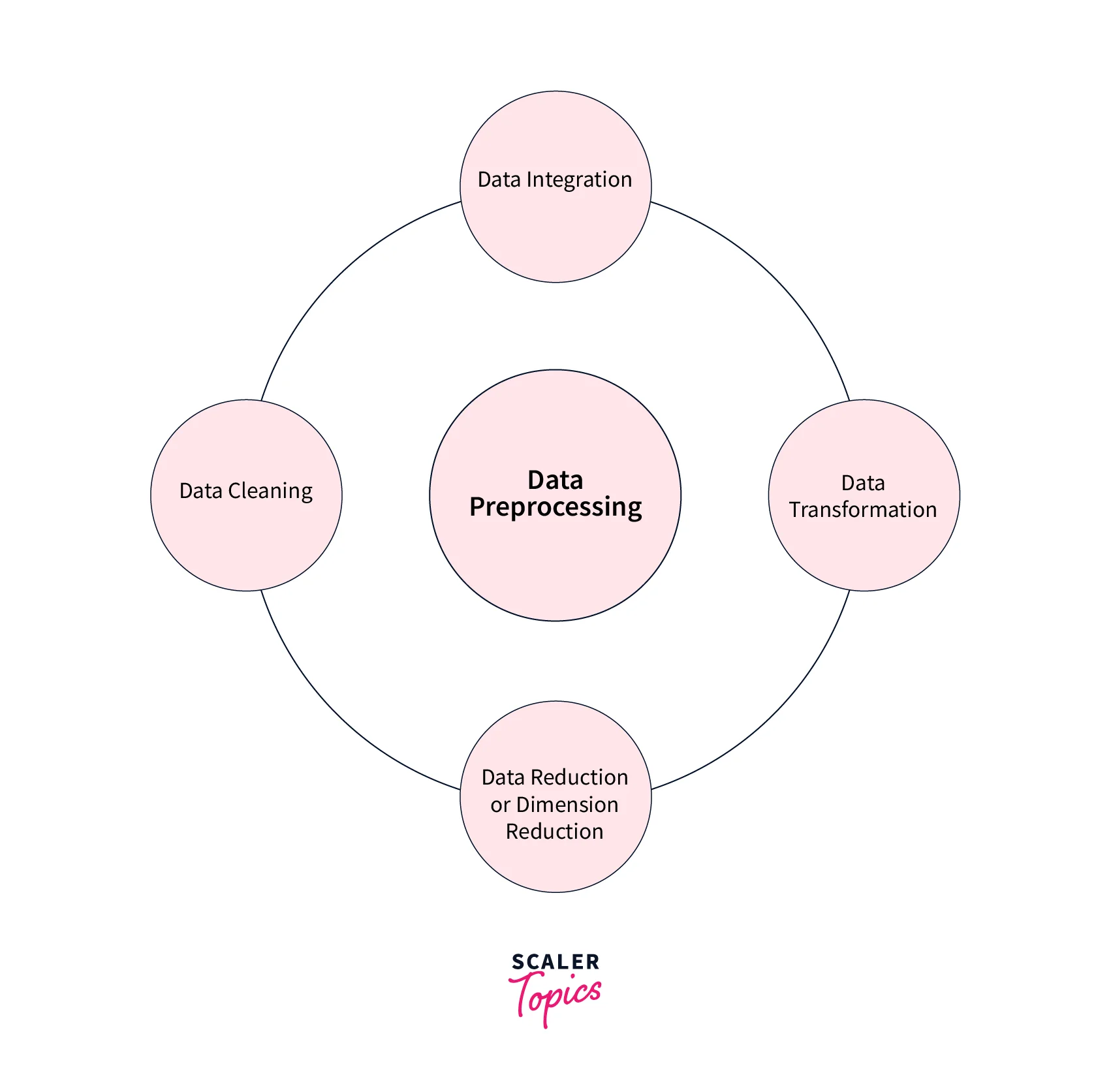
Key Steps in Data Preprocessing
Let’s explore a few of the key steps involved in the Data Preprocessing stage -
Turn Learning into Career Growth
Data Cleaning
Data Cleaning uses methods to handle incorrect, incomplete, inconsistent, or missing values. Some of the techniques for Data Cleaning include -
- Handling Missing Values
- Input data can contain missing or NULL values, which must be handled before applying any Machine Learning or Data Mining techniques.
- Missing values can be handled by many techniques, such as removing rows/columns containing NULL values and imputing NULL values using mean, mode, regression, etc.
- De-noising
- De-noising is a process of removing noise from the data. Noisy data is meaningless data that is not interpretable or understandable by machines or humans. It can occur due to data entry errors, faulty data collection, etc.
- De-noising can be performed by applying many techniques, such as binning the features, using regression to smoothen the features to reduce noise, clustering to detect the outliers, etc.
Data Integration
Data Integration can be defined as combining data from multiple sources. A few of the issues to be considered during Data Integration include the following -
- Entity Identification Problem - It can be defined as identifying objects/features from multiple databases that correspond to the same entity. For example, in database A _customer_id,_ and in database B _customer_number_ belong to the same entity.
- Schema Integration - It is used to merge two or more database schema/metadata into a single schema. It essentially takes two or more schema as input and determines a mapping between them. For example, entity type CUSTOMER in one schema may have CLIENT in another schema.
- Detecting and Resolving Data Value Concepts - The data can be stored in various ways in different databases, and it needs to be taken care of while integrating them into a single dataset. For example, dates can be stored in various formats such as DD/MM/YYYY, YYYY/MM/DD, or MM/DD/YYYY, etc.
Data Reduction
Data Reduction is used to reduce the volume or size of the input data. Its main objective is to reduce storage and analysis costs and improve storage efficiency. A few of the popular techniques to perform Data Reduction include -
- Dimensionality Reduction - It is the process of reducing the number of features in the input dataset. It can be performed in various ways, such as selecting features with the highest importance, Principal Component Analysis (PCA), etc.
- Numerosity Reduction - In this method, various techniques can be applied to reduce the volume of data by choosing alternative smaller representations of the data. For example, a variable can be approximated by a regression model, and instead of storing the entire variable, we can store the regression model to approximate it.
- Data Compression - In this method, data is compressed. Data Compression can be lossless or lossy depending on whether the information is lost or not during compression.
Data Transformation
Data Transformation is a process of converting data into a format that helps in building efficient ML models and deriving better insights. A few of the most common methods for Data Transformation include -
- Smoothing - Data Smoothing is used to remove noise in the dataset, and it helps identify important features and detect patterns. Therefore, it can help in predicting trends or future events.
- Aggregation - Data Aggregation is the process of transforming large volumes of data into an organized and summarized format that is more understandable and comprehensive. For example, a company may look at monthly sales data of a product instead of raw sales data to understand its performance better and forecast future sales.
- Discretization - Data Discretization is a process of converting numerical or continuous variables into a set of intervals/bins. This makes data easier to analyze. For example, the age features can be converted into various intervals such as (0-10, 11-20, ..) or (child, young, …).
- Normalization - Data Normalization is a process of converting a numeric variable into a specified range such as [-1,1], [0,1], etc. A few of the most common approaches to performing normalization are Min-Max Normalization, Data Standardization or Data Scaling, etc.
Applications of Data Preprocessing
Data Preprocessing is important in the early stages of a Machine Learning and AI application development lifecycle. A few of the most common usage or application include -
- Improved Accuracy of ML Models - Various techniques used to preprocess data, such as Data Cleaning, Transformation ensure that data is complete, accurate, and understandable, resulting in efficient and accurate ML models.
- Reduced Costs - Data Reduction techniques can help companies save storage and compute costs by reducing the volume of the data
- Visualization - Preprocessed data is easily consumable and understandable that can be further used to build dashboards to gain valuable insights.
Conclusion
- Data Preprocessing is a process of converting raw datasets into a format that is consumable, understandable, and usable for further analysis. It is an important step in any Data Analysis project that will ensure the input datasets's accuracy, consistency, and completeness.
- The key steps in this stage include - Data Cleaning, Data Integration, Data Reduction, and Data Transformation.
- It can help build accurate ML models, reduce analysis costs, and build dashboards on raw data.
Ready to master Data Science? Explore our comprehensive course now!