Product Recommenders- Amazon

Overview
As the name suggests, Recommender Systems are used to recommend items/things/products to the end-user by considering multiple factors. For example, Netflix, YouTube, Amazon, etc. all use recommendation systems to suggest relevant videos or products that the end-user is likely to engage with. So, let’s learn how to build a recommender system to recommend relevant or similar products.
What are We Building?
In this project, we will use a dataset extracted from Amazon by AppliedAI. It consists of 180K fashion products for women. Further, we will build a recommender system utilizing Natural Language Processing (NLP) to recommend similar products to the customer.
Pre-requisites
- Python
- Natural Language Processing Techniques - Bag of Words, TF-IDF, Word2Vec
- Similarity Metrics - Cosine and Euclidean Similarity
- Data Visualization
How are We Going to Build This?
In this project, we will utilize NLP to build text similarity-based recommender models to suggest products to the end customer. We will develop recommender systems based on three different approaches, as mentioned below -
- Bag Of Words (BoW) model
- TF-IDF model
- Text Semantics model (Word2Vec)
Final Output
The final output will show the product searched by the customer or input query and will display recommended products based on the developed model.


Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Requirements
We will be using below libraries, tools, and modules in this project -
- Pandas
- Numpy
- Scikit-learn
- NLTK
- Matplotlib
- Seaborn
- Gensim
- Requests, re, os, PIL, io
Building the Recommendation System
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Import Libraries
Let’s start the project by importing all necessary libraries to build an NLP-based Recommender System.
Data Exploration
- In this project, we will use a dataset extracted by AppliedAI from Amazon Products API. It consists of 180K fashion products for women. This dataset can be downloaded from here
- Now, let’s perform a basic Exploratory Data Analysis (EDA) on this dataset.
Output:
Let’s explore how many missing/NULL values are in this dataset. As shown in the figure below, feature _color_ and _formatted_price_ contain a lot of NULL values.
Output:
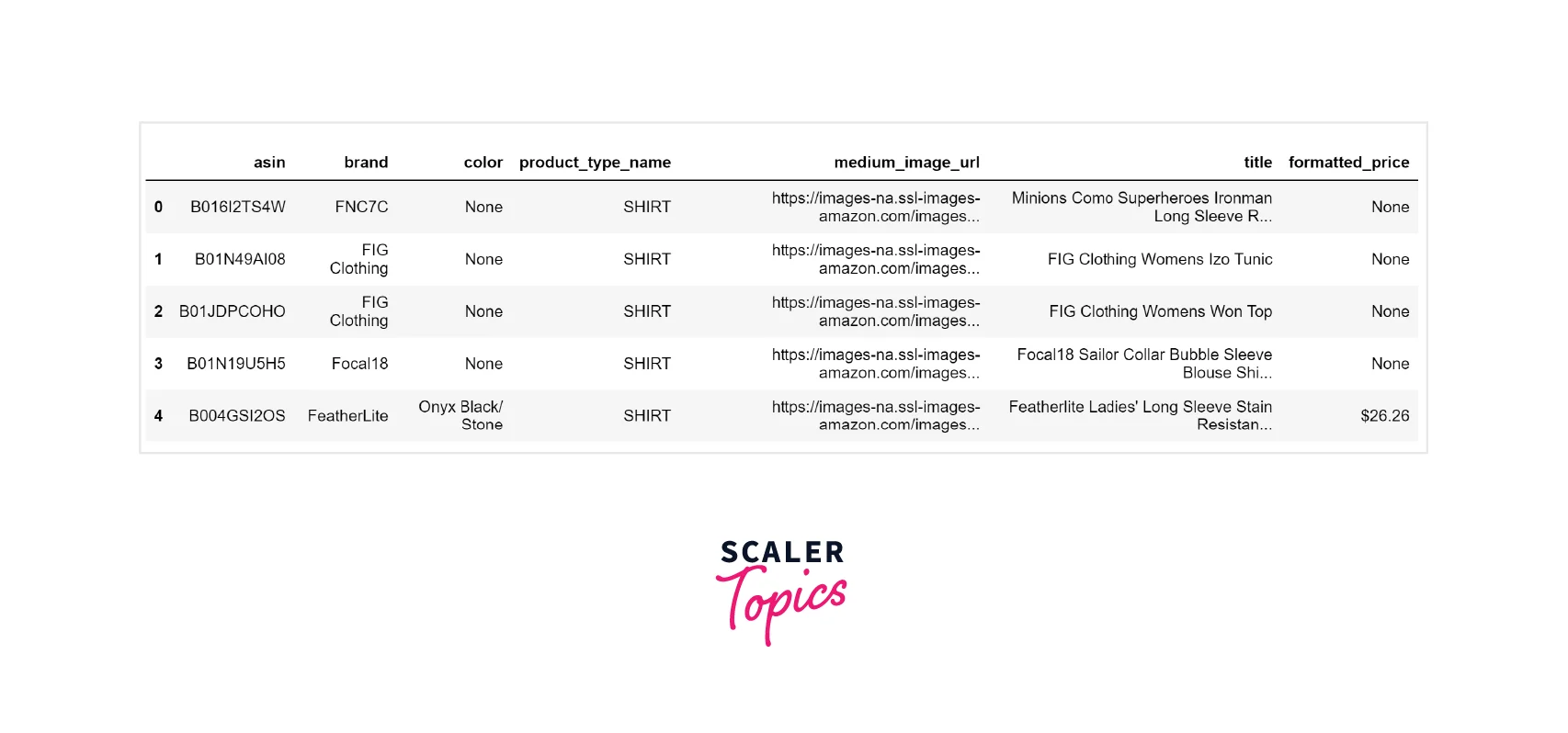
Now, let’s explore product categories by exploring _product_type_name_ feature. This feature contains 72 unique categories, as shown below. Also, 91% of records in this dataset belong to a single category, i.e., SHIRT.
Output:
Let's look at the value counts of different product names.
Output:
Let's see how color is distributed among the records in this dataset. Black color is the one with the highest distribution, i.e., 20% of the records are Black.
Output:
Now let’s get into the Product Title and explore how many unique titles there are. We will also check the distribution of the Product title’s length.
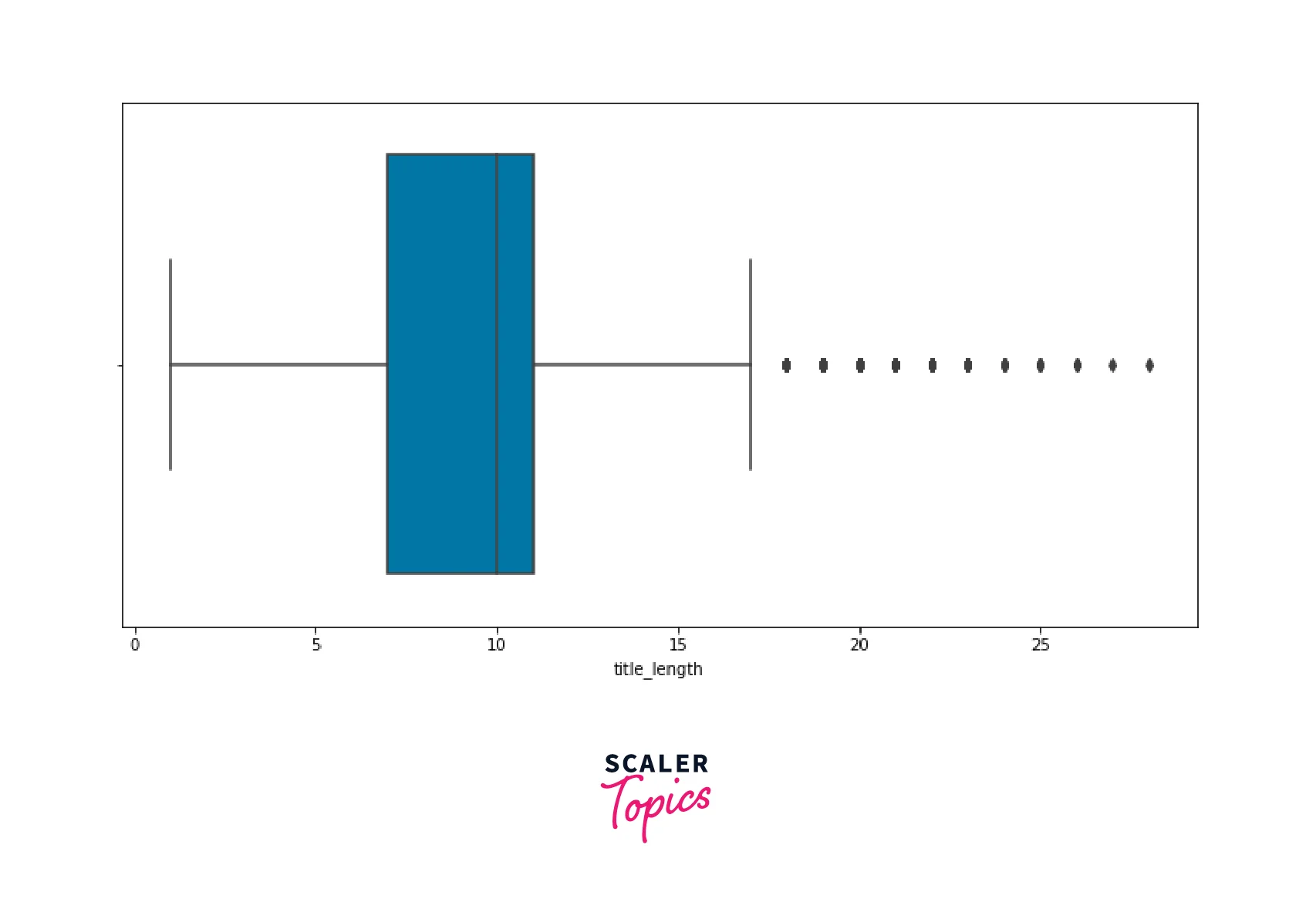

As shown in the above diagram, the word length in the feature _title_ can range from 1 to 28. So we need to remove records having the title length < 3 as they might not contain enough information about the product. Also, a few of the product titles are common, and while recommending similar products, we may be suggesting the same products to the customer because of the same title. So, we will also remove all the duplicate titles from the data.
Data Pre-processing
In the Data Pre-processing stage, we will remove all the special characters and stopwords from the feature _title_.
Turn Learning into Career Growth
Text-Based Product Similarity
Now we have finished data pre-processing, and the next step is to develop the recommendation system. In this project, we will utilize text-based product similarity to recommend the users. We will first convert product titles into vectors and utilize Euclidean distance to identify similar products. To vectorize product titles, we will use three approaches as mentioned below -
- Bag of words model
- TF-IDF model
- Text Semantics model (Word2Vec)
Before getting each model, let’s define some utility functions which we will use in each category of the model.
Bag of Words Model
The Bag of Words is a simplified representation of a document where only the count of words represents the document. In this model, the text is converted to a vector of length equal to unique words in the text, and each value in the vector will represent the count of respective words in the text.
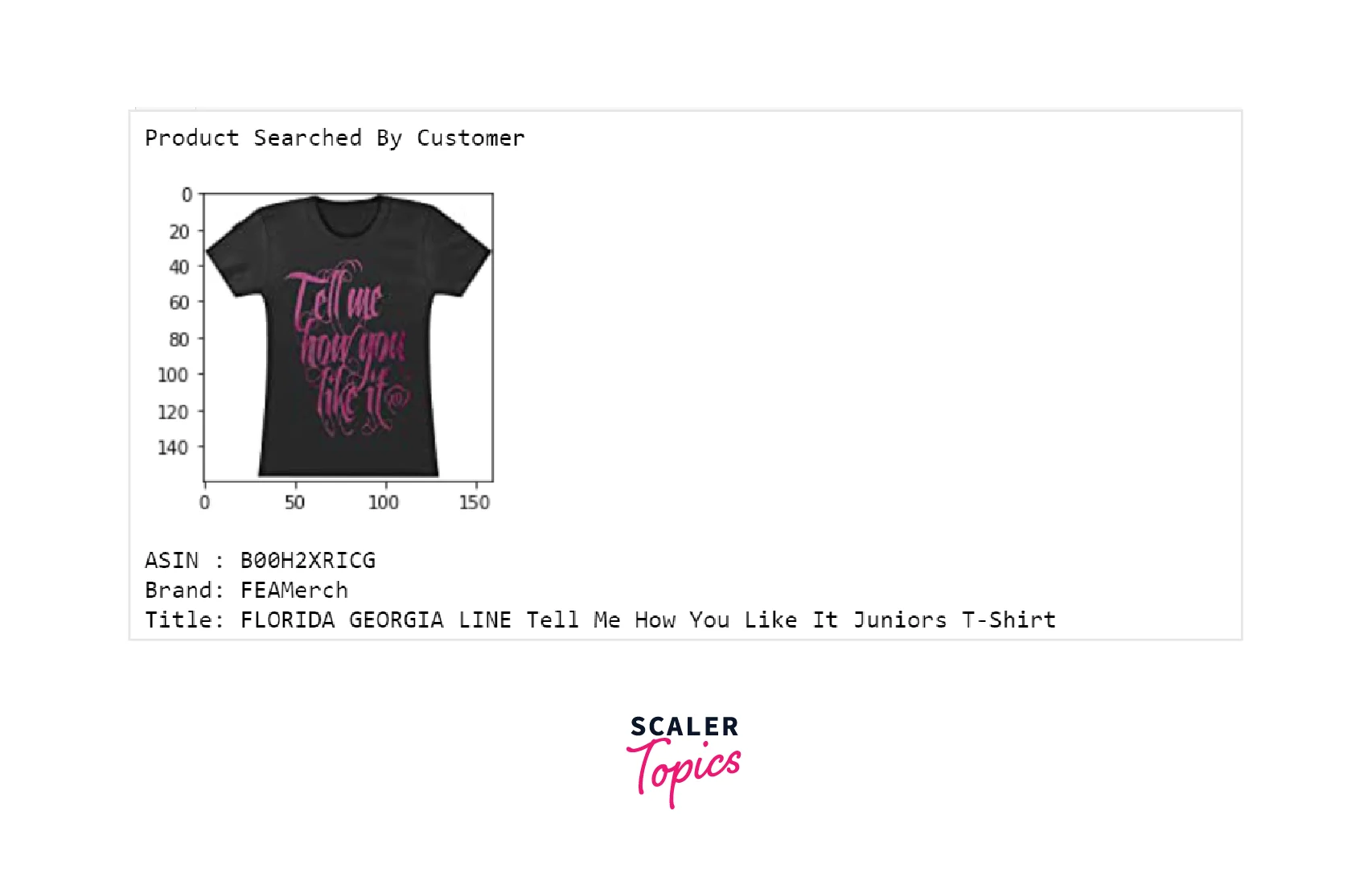

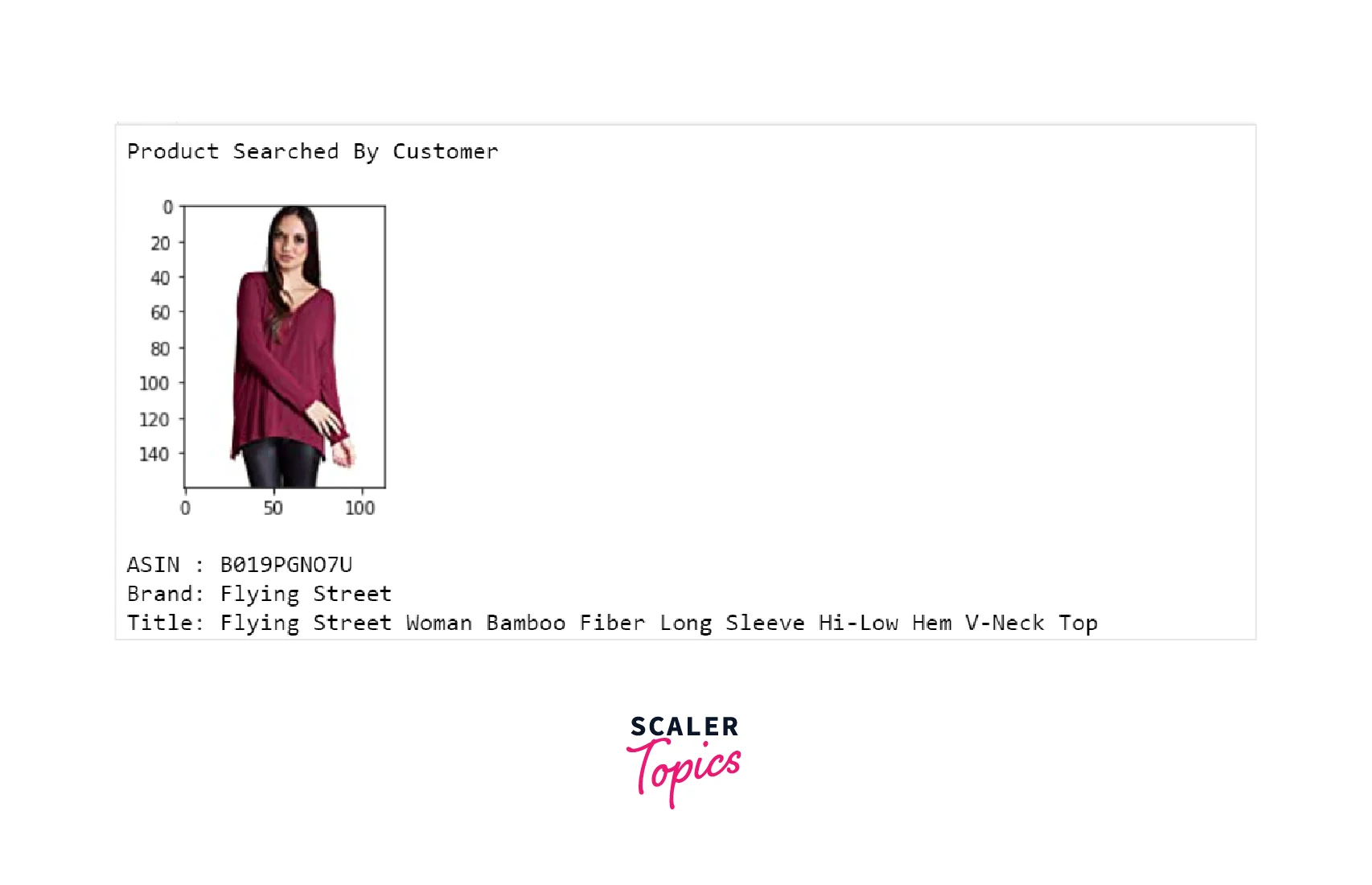
If you look at the images and their titles, you can see that these are similar products. Now, let’s try the TF-IDF approach in the next subsection.
TF-IDF Model
TF-IDF stands for Term Frequency - Inverse Document Frequency, which is used to determine the weights signifying the importance of a word in the document or text. This technique is highly prevalent in text mining and information retrieval.

Text Semantics Model (Word2Vec)
In this model, we will create embeddings for a product title using text semantics-based models, such as Word2Vec. Word2Vec can convert each word/token into a fixed length of vector/embedding. So, by generating embeddings for each word in the product title, we can create an average Word2Vec for each title. It is computed by adding all word embeddings present in the word and then taking an average of it. Let’s see how Average Word2Vec produces recommendation results -
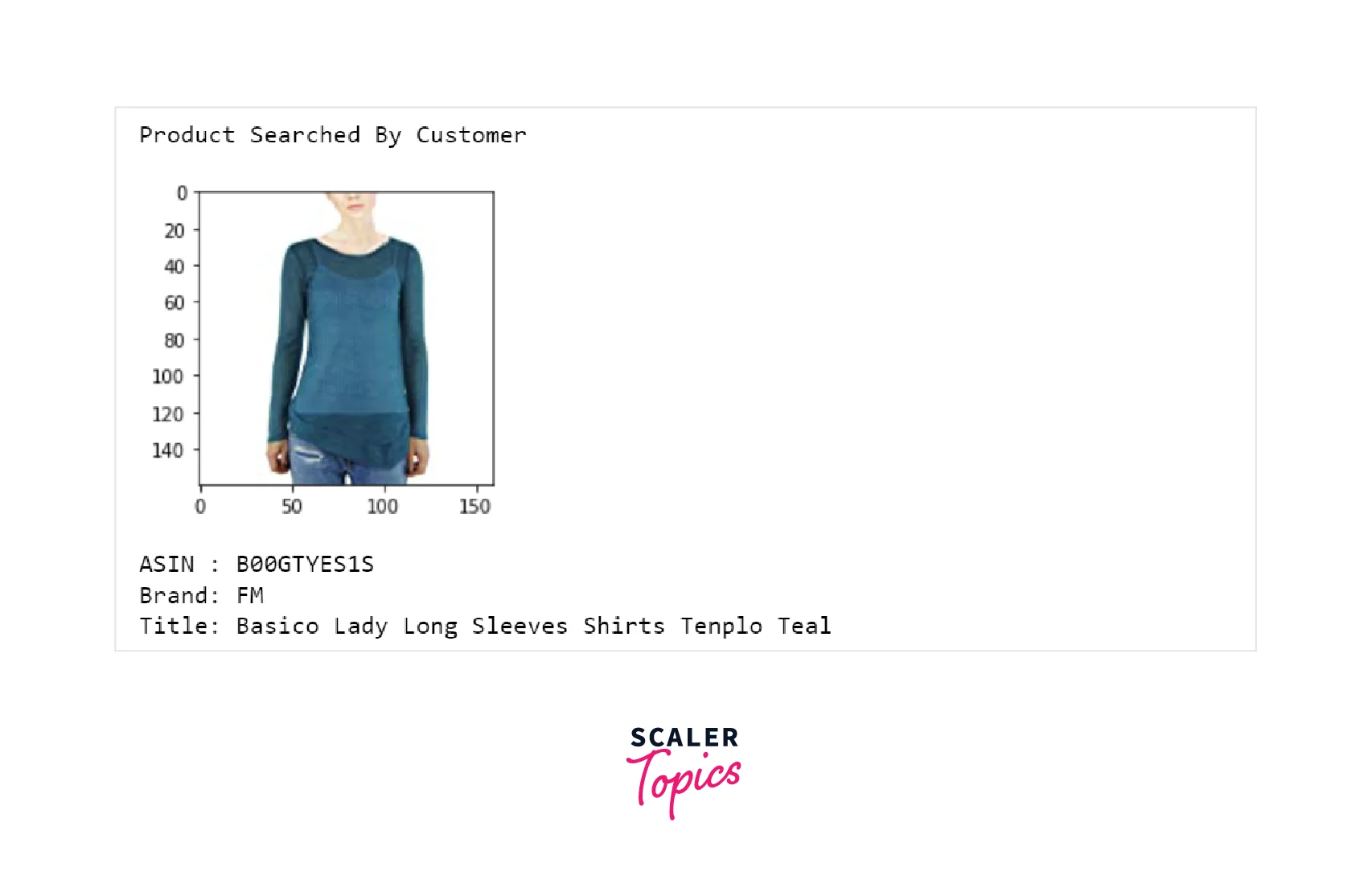

Final Remarks
So, as shown in above exercise, Word2Vec method works best as it transform words into a latent space where similar words would appear together, resulting in better similarity score and relevant recommendations. TF-IDF method also provides good recommendations, is easy to implement, and works well when you don't have a lot of data to train your own Word2Vec model.
What’s Next
- In previous sections, we have tried developing a recommender system based on euclidean distance as a similarity metric.
- Another similarity metric that can be used is cosine similarity. You can try out building a recommender system using the cosine similarity metric.
- Also, you can experiement with brand and color feature as well while recommending similar products to the customer
Conclusion
- We developed a recommender system to recommend fashion products based on text-based product similarity.
- We used Bag of Words, TF-IDF, and Word2Vec to create embeddings for the product titles and identify similar products for the recommendation.