Python for Data Science

Python, an open-source, high-level programming language, stands as a cornerstone in Data Science due to its simplicity, readability, and versatility since its 1991 inception. Its streamlined syntax empowers Data Scientists to concentrate on problem-solving rather than wrestling with syntax. This language's popularity burgeons within the Data Science realm, attributed to its user-friendly nature, abundant open-source libraries, and comprehensive documentation. These resources facilitate tasks ranging from Machine Learning and Deep Learning to Data Visualization and Pre-processing. Tailored for 2023's landscape, this tutorial elucidates Python fundamentals intertwined with pivotal Data Science facets like preprocessing, visualization, statistics, and machine learning, catering to novices and seasoned professionals alike.
Useful Features of Python Language
A few of the features that make Python a useful language include as following -
- Simplicity and Readability - Python uses clear, elegant, and concise syntax that makes it easy to learn, understand and read, even for people new to programming.
- Flexibility - Python can be used for a wide variety of tasks such as web development, software development, scientific computing, data analysis, etc.
- Large Open-Source Library - Python has a large open-source library that provides various useful functions and modules.
- Community Support - Python has a large and active community of programmers who continuously contribute to its libraries and other resources, making it easier to work with the language.
- Multi-Platform Support - Python can be used on many different operating systems such as Windows, Mac OS, Linux, etc.
- Interpreted - Python is an interpreted language, meaning an interpreter executes it rather than being compiled into machine code. This enables a faster development lifecycle.
- Object-Oriented - Python supports object-oriented programming.
Why Python for Data Science?
Let’s review a few reasons why Python should be preferred for Data Science over any other programming language.
- Prevalent and Popular in the Data Science Community - Python is the most popular programming language in the field of Data Science.
- Great Ecosystem of Libraries and Frameworks - Python comes with many open-source libraries and frameworks along with great online documentation for the efficient implementation of various Data Science tasks such as Machine Learning, Deep Learning, EDA, Data Pre-processing, Data Visualization, etc.
- Easy to Use - One of the main reasons Python is widely used and most popular in the Data Science community is its ease of use and simplified syntax, making it easy to learn and adapt for people with no engineering background. This makes it an excellent choice for Data Scientists, who frequently use complex algorithms and data structures.
- Flexible - Python can be used for many Data Science tasks such as Data Collection, Data Cleaning, Exploratory Data Analysis (EDA), Feature Engineering, ML Modeling, Data Visualization, etc.
- Large Community - Python has a large and active community of programmers who continuously contribute to its libraries and other resources, making it easier to work with the language.
- High performance - Python has been optimized for performance, and many of its libraries and frameworks are highly efficient. This makes it possible to work with large volumes of data and apply complex calculations quickly and efficiently.
Data Science Using Python vs. R
Both Python and R languages are quite popular in the Data Science community. R has been in use for a long time in Data Science, but in a few years, Python has taken over the R language, becoming the most popular and preferred language in the Data Science community.
Let’s explore the difference between Python and R in the below table -
| Factor | Python | R |
| Primary Users | Programmers and Developers | Researchers and Scholars |
| Objective | Development, Testing, and Production of the Data Science, ML, and Deep Learning Algorithms. | Statistical and Data Analysis |
| Popular Data Science Libraries | Pandas, Matplotlib, NumPy, Seaborn, Sklearn, etc. | Dpylr, ggplot2, caret, etc. |
| Learning Curve | Easy to Learn and Adapt | Steep Learning Curve |
| Performance | Efficient and quick to process large volumes of data | Can be slow compared with Python language |
Commonly Used Libraries for Data Science
One of the reasons for the popularity of Python in the Data Science community is that it provides numerous libraries to implement any kind of Data Science related tasks. A few of the most common libraries used by Data Scientists include -
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
NumPy
- NumPy is a library that provides various methods and functions to handle and process large Arrays, Matrices, and Linear Algebra.
- It stands for Numerical Python, and this library provides vectorization of various linear algebraic and mathematical functions required to work with matrices and arrays. Vectorization enables functions on all vector elements without needing to loop through and act on each element simultaneously, resulting in enhanced execution speed and performance.
Pandas
- Pandas is the most popular Python library among Data Scientists and Analysts. This library provides many functions to perform Data Cleaning, Data Manipulation, and Analysis on large volumes of data. Pandas is a perfect tool when it comes to Data Wrangling.
- It supports two data structures - Series and Dataframe.
- Series is a one-dimensional array capable of holding data of any type (integer, string, float, python objects, etc.). A Data frame in Pandas is a heterogeneous two-dimensional data structure, i.e., data is aligned in a tabular fashion in rows and columns like an excel spreadsheet or SQL table. Pandas DataFrame is capable of having columns with multiple data types.
Matplotlib
- Data Visualization is one of the essential steps in implementing any Data Science solution. Matplotlib is a handy library that provides methods and functions to visualize data in any format, such as graphs, pie charts, plots, etc. It can also be used to customize any aspect of your figures and make them interactive.
SciPy
- Statistical Analysis is an important step in any Data Science project, such as performing EDA on the data using statistical methods such as mean, standard deviation, z-score, p-value test, etc. SciPy library will provide various methods and functions for implementing statistical and mathematical concepts required in Data Science.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Scikit-Learn
- It is a Machine Learning Python library that provides a simple, optimized, and consistent implementation for a wide array of Machine Learning techniques.
Turn Learning into Career Growth
Data Science with Python: Demo
In this demo, we will use the IRIS dataset and perform the following tasks -
- Data Pre-processing
- Data Visualization
- ML Model Development
Data Pre-processing
The iris data consists of 150 samples of three species of Iris flowers. This dataset consists of sepal length, sepal width, petal length, and petal width. We will use Sklearn dataset libraries to load this dataset and convert it into a Pandas dataframe. Further, we will explore the data summary and distribution of target variables.
| index | sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target | species |
|---|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0.0 | setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0.0 | setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0.0 | setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0.0 | setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0.0 | setosa |
Output:
Output:
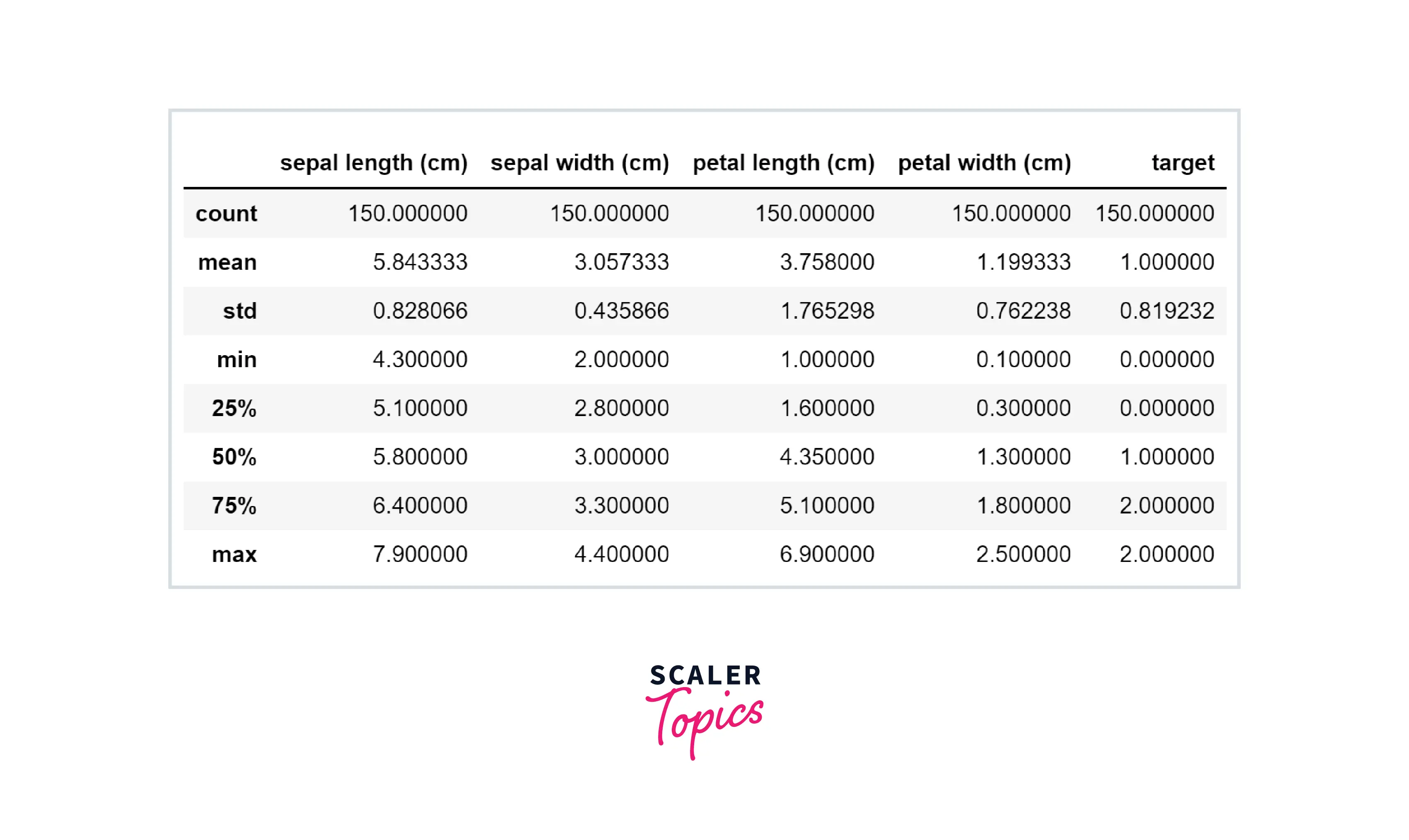
As we can see, all labels are equally distributed. We can also explore various statistical metrics, such as mean, std, min, max, etc., for each variable.
Data Visualization
In this step, we will generate a scatter plot between petal length and width for each target label.
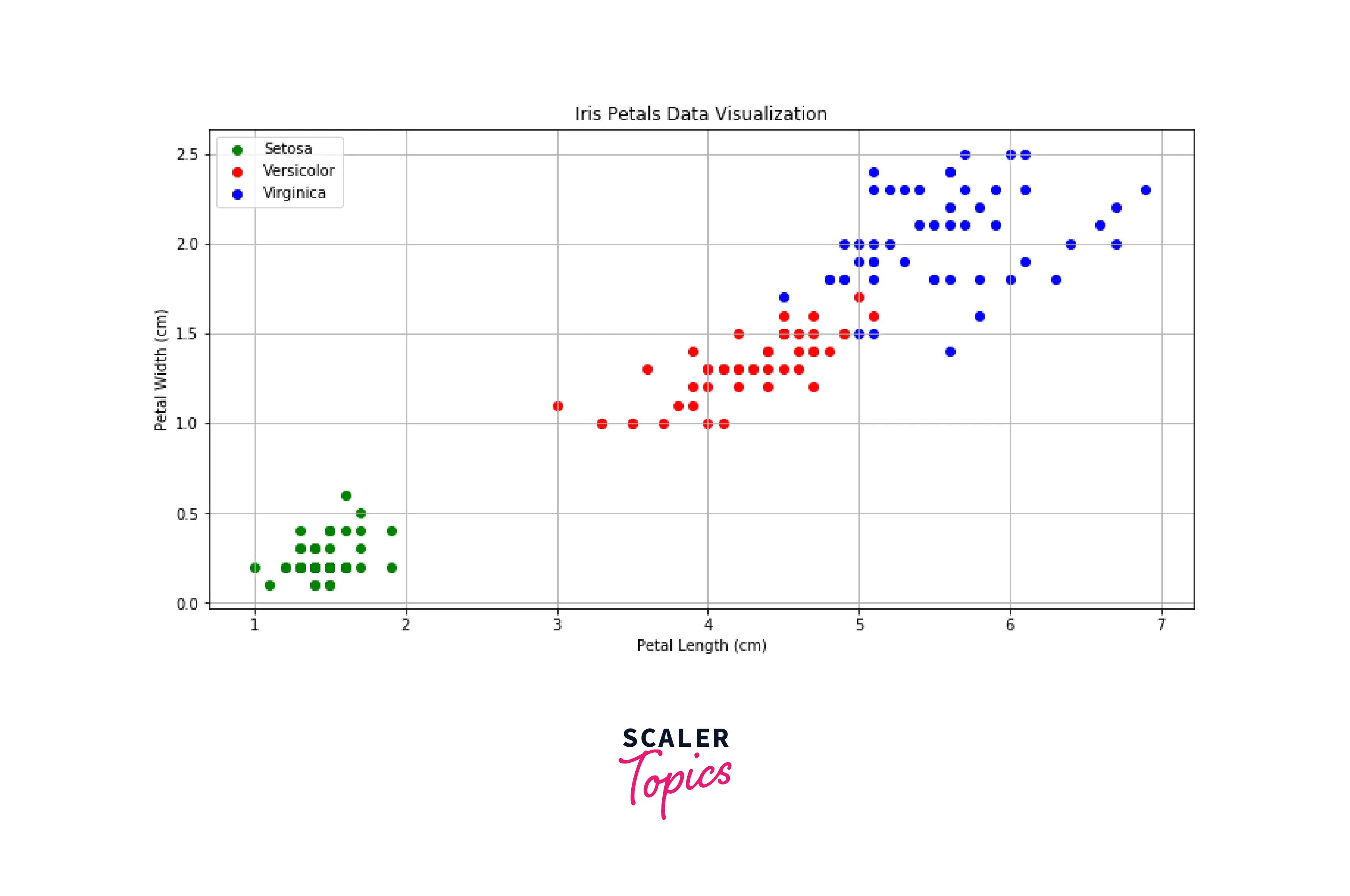
As we can see, all classes/labels are well separated and form distinct clusters.
ML Model Development (Classification)
In this step, we will develop a simple logistic regression model and explore its accuracy.
Output:
As you can see, the model can predict each value with 100% accuracy or 100% precision, recall, or F1 score.
How to Learn Python for Data Science
Learning Python is essential to start or build your career in Data Science as it is the most popular and preferred language among Data Scientists. You can learn Python to implement various Data Science tasks using the guide below.
- Learn Python Fundamentals - The first step to learning anything is understanding its fundamentals. You can consider various Data Science online courses, boot camps, or self-learning methods to learn and adapt Python basics.
- Practice with Hands-on Learning - Next step is to get your hands dirty and get hands-on experience using various problems. It will help you sharpen your fundamentals of the Python language.
- Learn Python Data Science Related Libraries - You should learn and master all popular and widely used Data Science libraries such as Pandas, NumPy, SciPy, Matplotlib, Seaborn, Sklearn, etc.
- Build a Data Science Portfolio - Aspiring Data Scientists must focus on building their Data Science portfolio as they learn Python language. They should have various categories of projects, such as Data Cleaning projects, Data Visualization projects, ML Model projects, etc.
- Apply Advanced Data Science Techniques - Data Science requires constant learning. Once you have grasped the fundamentals of Python for Data Science, you should move on to learn advanced Data Science techniques.
If you want to get started in Data Science with Python, you can check out this free course by Scaler topics.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Python Fundamentals
To learn Python for Data Science, it is necessary to understand the fundamentals of Python before moving on to more advanced concepts and libraries. Let’s explore the basic fundamental concepts you need to learn and master in Python language are -
- Data Types - Python supports several built-in data types. These data types can be simple as Integers, Float, String, Character,, etc., and these data structures can be compound in nature, such as Lists, Tuples, Sets, Dictionaries, etc.
- Variables - In Python, a variable refers to a location in memory where a value can be accessed and retrieved. A variable can be defined in any of the data types mentioned above.
- Operators - Python supports several built-in operators, such as arithmetic, comparison, assignment, and logical operators.
- Control Flow Statements - to control the flow of execution, Python supports and provides various control flow statements, such as if-else, for, and while loops.
- Functions - A function is a block or few lines of code used to perform some operations on the data and return the desired output.
- List Comprehension - It enables creating a new list based on the values of an existing list without writing a loop statement.
Conclusion
- Python is an open-source, interpreted, high-level, and general-purpose programming language known for its elegant syntax, simplicity, and readability. It is the most popular language among Data Scientists and Analysts.
- One of the main reasons Python is widely used and most popular in the Data Science community is its ease of use and simplified syntax, making it easy to learn and adapt for people with no engineering background. Also, it can be used to perform a wide range of Data Science tasks such as Data Collection, Wrangling, EDA, Visualization, ML Model Development, etc.
- The most common libraries used in Python include - Pandas, Matplotlib, NumPy, SciPy, Sklearn, etc.