What is Feature Engineering in Machine Learning?

Overview
Feature engineering can be defined as the process of selecting, manipulating, and transforming raw data into features that can improve the efficiency of developed ML models. It is a crucial step in the Machine Learning development lifecycle, as the quality of the features used to train an ML model can significantly affect its performance.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
What is Feature Engineering in Machine Learning
Feature engineering is the process of leveraging domain knowledge to engineer and create new features that are not part of the input dataset. These features can greatly enhance the performance of developed ML models. Feature engineering can involve the creation of new features from existing data, combining existing features, or selecting the most relevant features. In other words, feature engineering is the process of selecting, manipulating, and transforming raw data into features that better represent the underlying problem and thus improve the accuracy of the machine learning model.
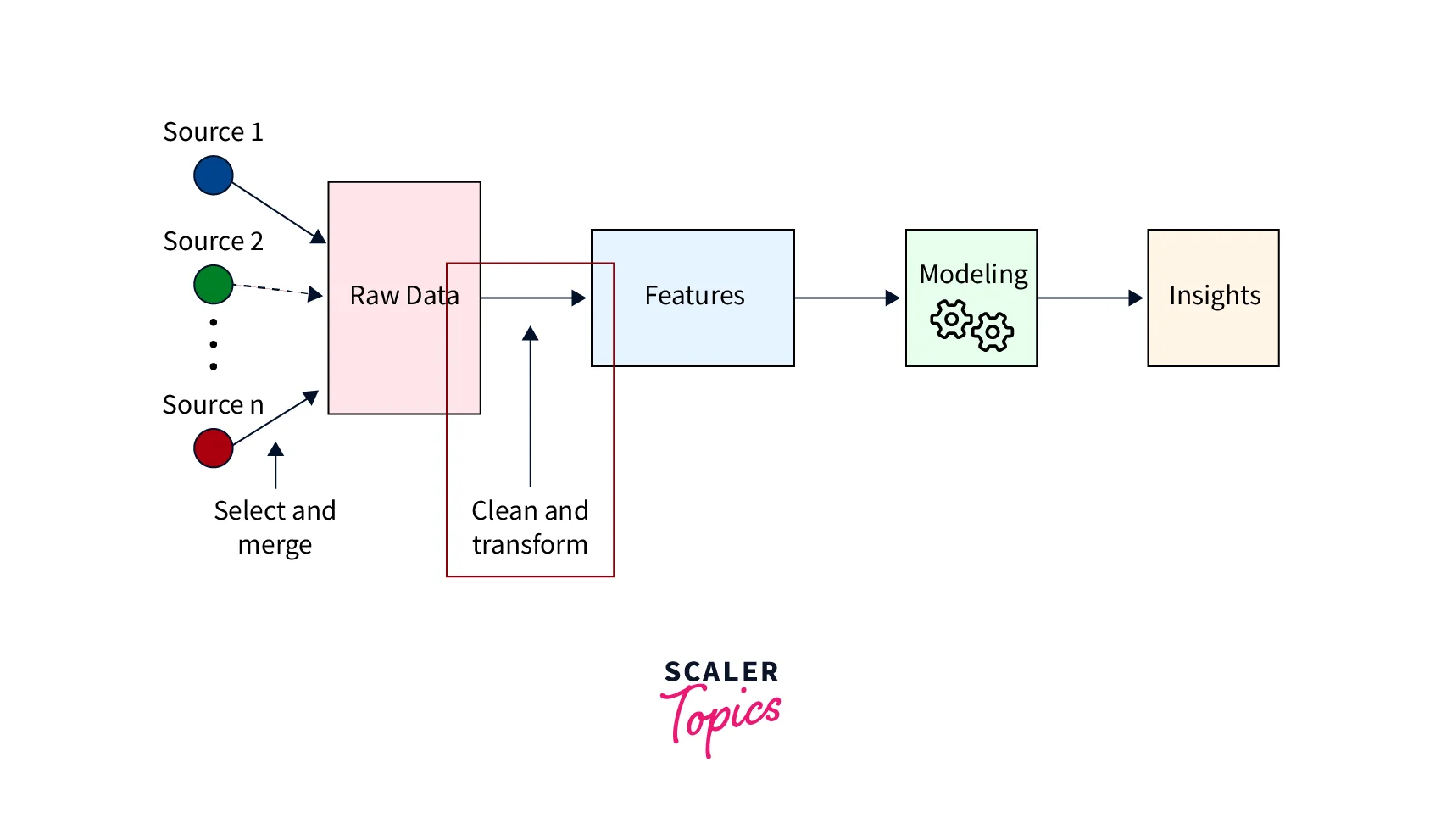
Feature engineering is part of the data pre-processing stage in a machine learning development lifecycle, as mentioned in the above figure. It typically consists of four processes.
Feature Creation
- Feature creation is one of the most common techniques in feature engineering. It is also known as feature construction or feature synthesis. It involves the creation of new features from existing data that is performed by combining or transforming the existing features. For example, if you have a dataset with the birth date of individuals, you can create a new feature age by subtracting it from the current date.
- This technique is advantageous when the existing features do not provide enough information to train and develop a robust machine-learning model or when the existing features are not in a usable format for an ML model development. It is a powerful way to improve the performance of machine learning models, but it can also be time-consuming and require a deep understanding of the data and the problem at hand.
Transformations
- Transformations are a set of mathematical operations that can be applied to existing features to create new ones.
- Some of the most common transformation techniques include data aggregation, scaling, normalization, binning, etc.
Feature Extraction
- Feature extraction is a feature engineering technique that creates new variables by extracting them from the raw data. The main objective of this process is to reduce the volume and dimensionality of the input data.
- A few of the most common techniques used for this method include - Principal Component Analysis (PCA), Cluster Analysis, etc.
Feature Selection
- The feature selection technique involves the selection of a subset of the most relevant features from the data and dropping the remaining features. It is performed using criteria such as the importance of the features, the correlation between the features and target variables, etc.
- It can greatly reduce the complexity of the ML model by removing redundant and irrelevant features from the training process.
Need for Feature Engineering in Machine Learning
Feature engineering is a crucial step in the machine learning development lifecycle, as the quality of the features used in the development of an ML model can greatly impact its performance. Let’s explore some of the reasons why feature engineering is required in machine learning.
- Better data representation - Feature engineering can help transform raw data into features that better represent the underlying problem, which can result in improving the efficiency and accuracy of the developed ML model.
- Improvement in model performance - Feature engineering can improve the machine learning model's performance in various ways, such as selecting the most relevant features, creating new important features, reducing the volume of input data, dropping irrelevant and redundant features, etc.
- Increased interpretability of the model - By creating new features that are more easily interpretable, feature engineering can make it easier to interpret and explain how the ML model is making its predictions, which can be greatly useful for debugging and improving the model.
- Reduced overfitting - By removing irrelevant or redundant features, feature engineering can help prevent overfitting.
- Reduce the complexity of the model - By dropping irrelevant features and keeping only important features, we can reduce the volume of the input data and can select simpler ML models to train.
Steps in Feature Engineering
Let’s explore the steps involved in the feature engineering process -
- Data Preparation - This data pre-processing step consists of collecting, manipulating, and combining raw data from various sources into a standardized format.
- Data Cleaning - This step requires handling missing values, removing erroneous and inconsistent values, etc.
- Exploratory Data Analysis (EDA) - EDA involves analyzing and investigating datasets through various data statistical and visualization methods. It can help data scientists to understand data better, its characteristics, how to manipulate it, choose the right features for the models, etc.
- Benchmark/Evaluation - This step involves evaluating the performance of the ML model using the engineered features and comparing it to the performance of the ML model without feature engineering.
Feature Engineering Techniques for Machine Learning
Let’s review some of the most popular techniques used in Feature Engineering -
Imputation
- In feature engineering, Imputation is a technique used to handle missing, irregular, erroneous, or NULL values in a given dataset.
- The most popular imputation techniques for numerical features include imputation by mean, median, and mode, imputation by nearest neighbors, interpolation, etc. The most common imputation technique for categorical features is the mode, or maximum occurred label or category.
Handling Outliers
- Outliers are the values or data points that are significantly different from the rest of the observations or data points in the dataset. These are also called abnormal, aberration, anomalous points, etc.
- In Data Science, handling outliers is a crucial step, as outliers can significantly impact the accuracy of the analysis and lead to incorrect conclusions and poor decision-making. In feature engineering, z-score, standard deviation, and log transformation are the most popular techniques to identify outliers and treat them.
Log Transformation
- Log transformation is one of the most popular techniques used by Data Scientists. It is used to transform skewed distributions into normal or less skewed distributions.
- Log transformation can also make outliers less extreme, improving the model's accuracy and fit.
Scaling
- In real-world datasets, features have different units and a range of values. For some ML models, such as KNN, etc., it is necessary to have all features on a common scale or the same range of values. Scaling is the technique used to transform variables to a common scale.
- Several techniques can be used for scaling data -
- Standardization - This is the most common scaling technique. It involves subtracting the mean of the data from each value and dividing it by the standard deviation. The resulting data would have zero mean and unit standard deviation in this case.
- Min-max scaling - This technique transforms all values in a feature to a common range (0, 1). It is performed by subtracting the minimum value from each data point and dividing by the range of the data.
Binning
- It is a process of converting numerical or continuous variables into multiple bins or sets of intervals. This makes data easy to analyze and understand.
- For example, the age features can be converted into intervals such as (0-10, 11-20, ..) or (child, young, …).
One Hot Encoding
- One Hot Encoding can be defined as a process of transforming categorical variables into numerical features that can be used as input to Machine Learning and Deep Learning algorithms.
- It is a binary vector representation of a categorical variable where the length of the vector is equal to the number of distinct categories in the variable. In this vector, all values would be 0 except the ith value, which will be 1, representing the ith category of the variable.
Best Feature Engineering Tools
Many available tools can help you automate feature engineering tasks and generate a large number of features within a short span of time. Let’s explore some of the most popular tools for feature engineering -
FeatureTools
- FeatureTools is an open-source software library to automate the feature engineering process. It can create a large number of features quickly and easily from temporal and relational data.
- FeatureTools utilizes a deep feature synthesis (DFS) technique to generate large amounts of features from a dataset automatically. This approach uses a set of pre-defined feature primitives that can be combined to create more complex features.
- It is good at handling relational databases and has good documentation and active community support.
- It also provides API and a library to access this tool using Python language and supports pandas dataframes as well.
- Its AutoML library helps you in building, optimizing, and evaluating machine learning pipelines.
AutoFeat
- AutoFeat is a python library that can help automate the generation of features by performing linear prediction models.
- This tool can also easily handle categorical variables with one hot encoding.
TsFresh
- TsFresh is a python package that is used to create features for time series data. It is one of the best open-source python libraries available to generate a huge number of features for time series classification and regression problems.
- Some of the features created by this library include - the number of peaks, average value, maximum value, time reversal symmetry statistic, etc.
OneBM
- OneBM tool directly interacts with tables and databases with raw data to create features automatically.
- This tool is useful for creating features on both relational and non-relational databases.
- It has no open-source library available either in Python or R language.
ExploreKit
- ExploreKit works on the basic intuition that highly informative features often result from manipulations of common or elementary features. This tool identifies common operators to transform each feature or combine several of the features together to create features automatically.
- It also uses meta-learning to rank the candidate features for the best possible feature selection.
- Its limitation is that it has no open-source library available either in Python or R language.
Conclusion
- In this article, we learned about what is feature engineering in machine learning. Feature engineering is the process of creating new features from raw data to improve the efficiency of developed ML models. It is a crucial step in the Machine Learning development lifecycle, as the quality of the features significantly affects the performance of the ML models.
- The most common techniques used for feature engineering include - imputation, handling outliers, scaling, one-hot encoding, etc.
- There are also many tools available that can help automate the feature engineering process and generate a huge number of features within a short period of time.