Siamese Networks
Overview
Obtaining enough data for deep learning tasks can be a significant challenge, especially in domains like facial recognition, signature verification, and text similarity, where large datasets are difficult. In such cases, a traditional CNN may not be effective. Siamese Networks, however, can excel at one-shot learning tasks by minimizing a similarity metric between images. This article explains the inner workings of Siamese Networks and provides an implementation for Signature Verification.
Introduction
Siamese networks are a one-shot classification paradigm where only a single example is enough for the network to classify images accurately. This network uses the concept of Contrastive Loss, which finds a pairwise similarity score between the images in the Dataset. Instead of learning the content of the images, the Siamese network learns the differences and similarities between them. This unique learning paradigm makes these networks much more robust to the lack of data and improves performance without needing domain-specific information.
Signature verification is a task in which these networks excel. This task aims to identify forged signatures given a single signature sample for thousands of people. This task is challenging due to the vast differences between individual signatures and the need for more training data.
In this article, we will explore the task of Signature Verification using these Siamese Networks and create a working model using PyTorch.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
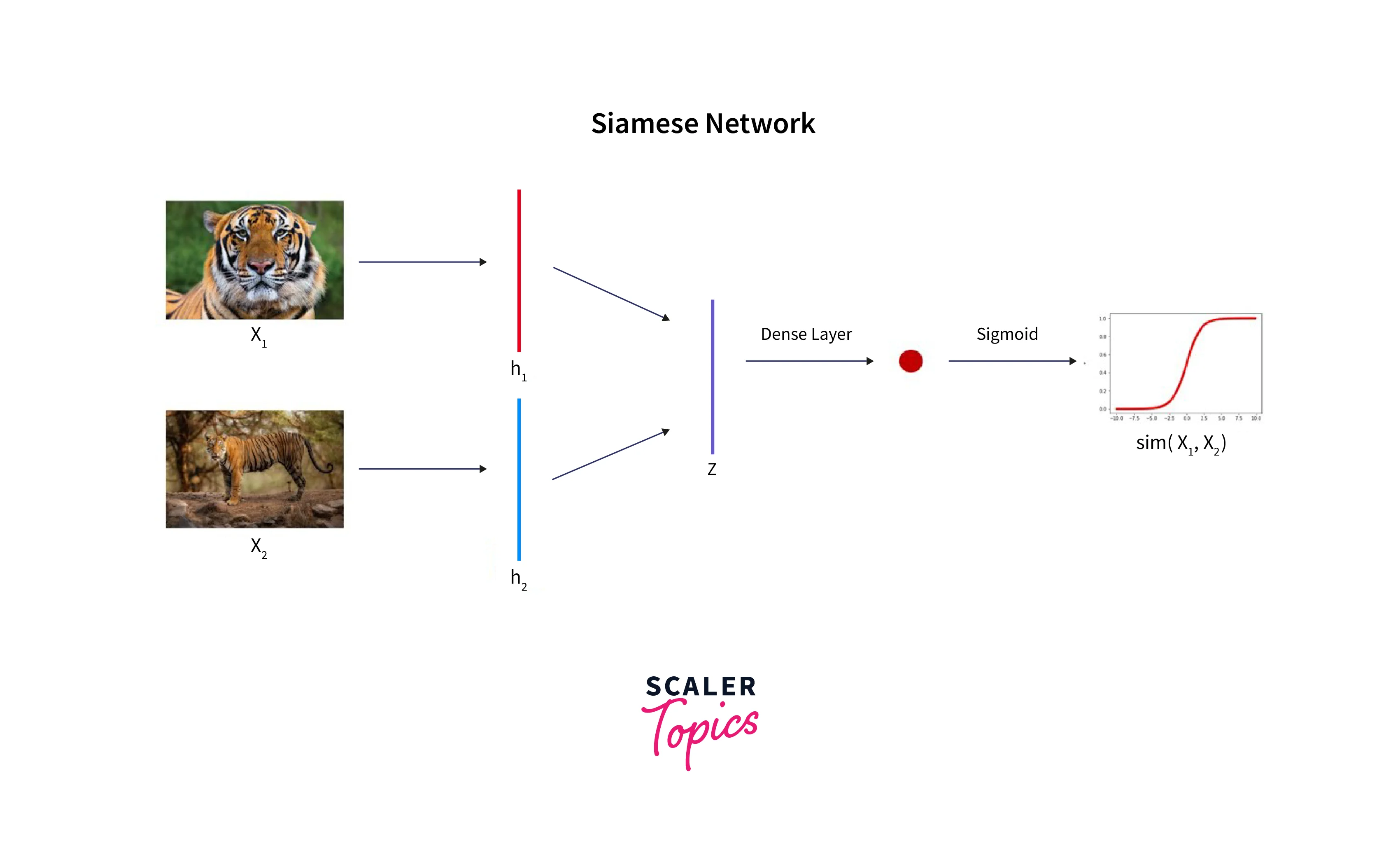
What are Siamese Networks?
Siamese Networks are a family of networks that uses two identical subnetworks for one-shot classification. The sub-networks share the same configuration, parameters, and weights but have different inputs. A Siamese Network learns a similarity function, unlike a regular CNN that learns to predict multiple classes using vast amounts of data. We can use the learned function to differentiate between classes without needing a lot of data. These networks are specialized in one-shot classification, meaning they only need a single example to classify images accurately in many cases.
As a real-life use case, Siamese Networks are applied to face recognition and signature verification tasks. Consider the face recognition task done for a company that wants to take an automated face-based attendance. The company would only have a single picture of its employees. A regular CNN would have been incapable of accurately classifying thousands of employees based on a single image of each. A Siamese network, on the other hand, excels at this task.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Exploring Few-Shot Learning
Few-shot learning is a type of machine learning where models are trained to make predictions based on a few examples. This paradigm contrasts with traditional machine learning methods that require a large amount of labeled data to train. Making predictions with a few examples is especially useful when obtaining large amounts of labeled data is difficult or expensive.
Few-shot models are designed to exploit the differences between a small number of samples and can make predictions ranging from a few samples to a single sample. This ability is achieved by using a variety of architectures, such as Siamese Networks, Meta-learning, and others. These architectures allow the model to learn good data representations that we can apply to new, unseen samples.
Two examples of use cases for few-shot learning are:
- Object Detection in Surveillance: Few-shot learning can detect objects in surveillance footage with a few examples of the objects of interest. The model can be trained on a small set of labeled examples and then used to detect the objects in new footage, even if they have never been seen.

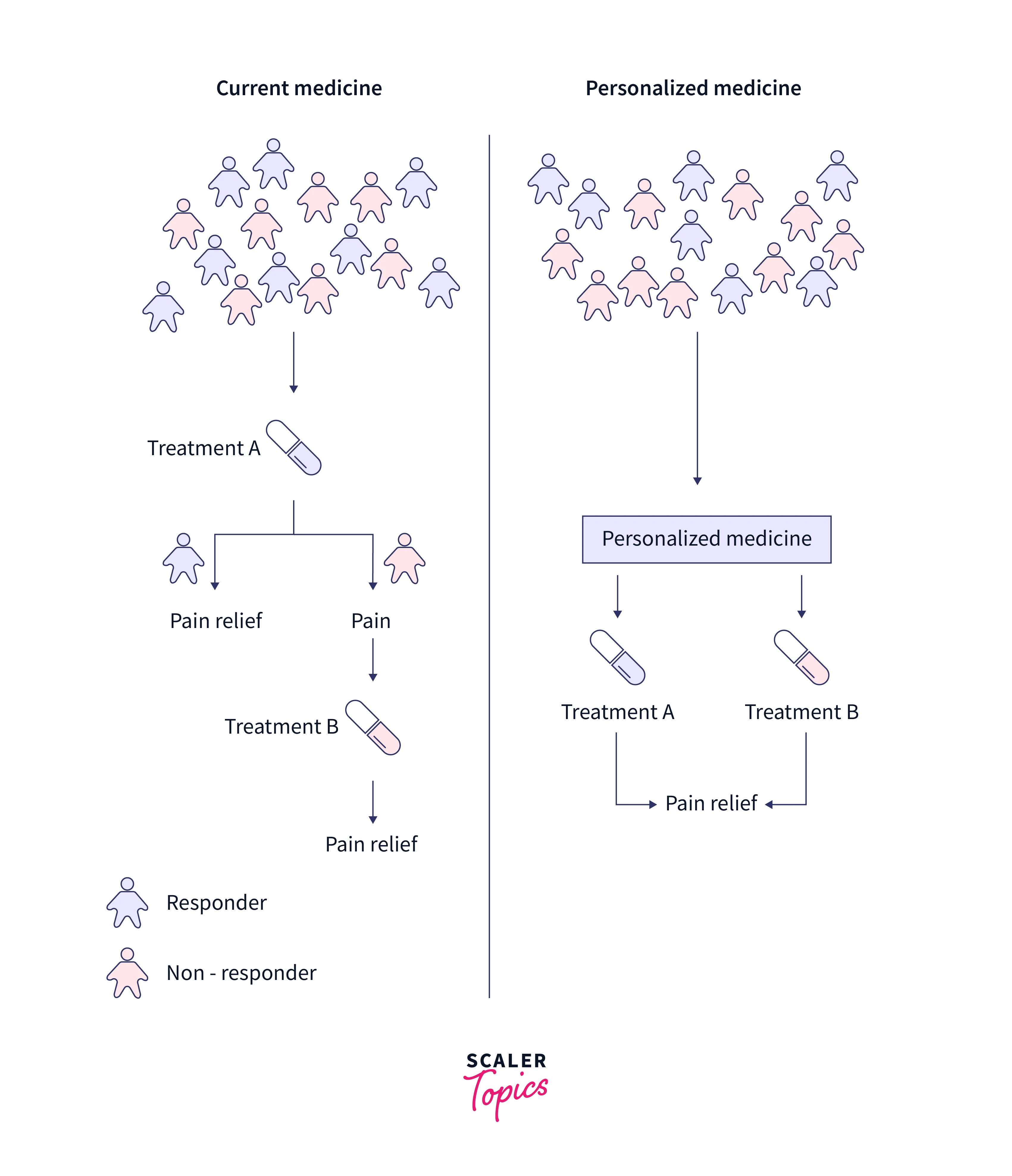
- Personalized Medicine: In personalized Medicine, doctors may only have a small number of examples of a patient's medical history, such as a few CT scans or blood tests. A few-shot learning model can be trained on these examples to predict the patient's future health, such as the likelihood of developing a certain disease or responding to a particular treatment.
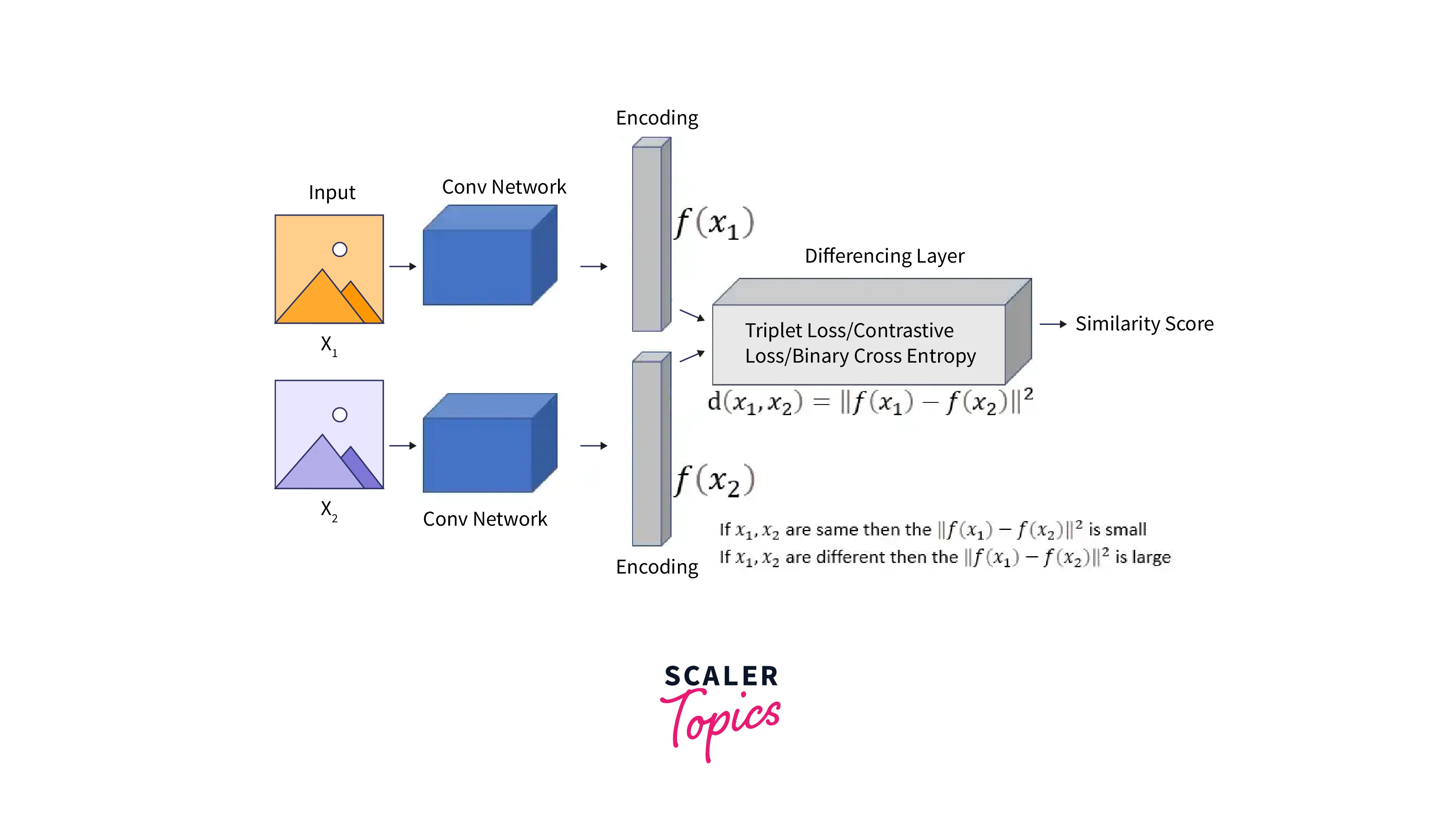
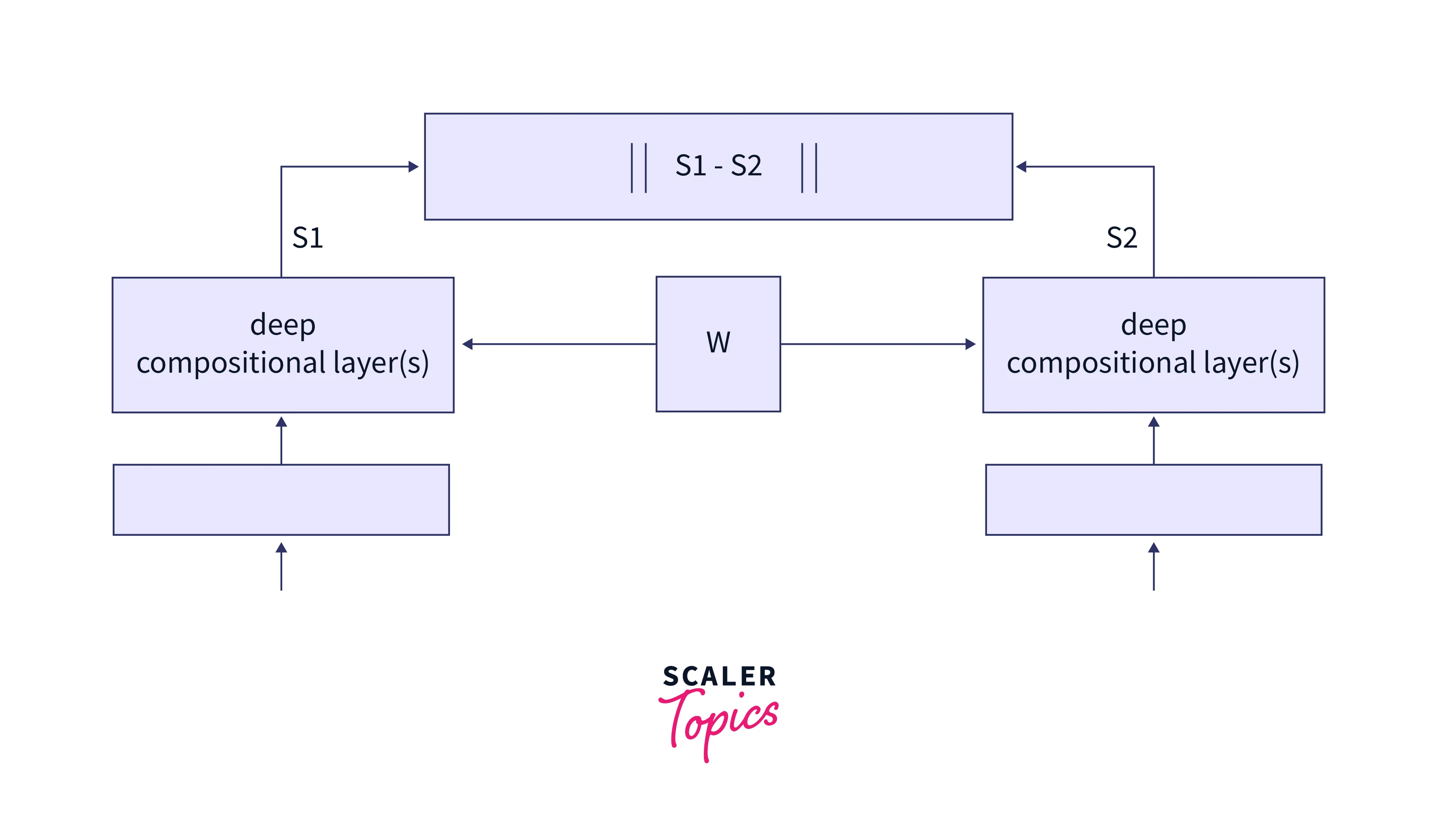
Architecture of Siamese Networks
The Siamese network architecture consists of two identical subnetworks, each taking one of the inputs. These inputs are first passed through a convolutional neural network (CNN), which extracts features from the input images. The outputs of these subnetworks are then encoded, typically through a fully connected layer, to produce a compact representation of the input.
The CNN has two branches and a shared feature extraction part consisting of convolutional, batch normalization, and ReLU activation layers followed by max pooling and dropout layers. The final part is the FC layer that maps the extracted features to the final classification outputs. A function defines a linear layer followed by a series of ReLU activations and a set of consecutive operations (convolution, batch normalization, ReLU activation, max pooling, and dropout). The forward function then passes the inputs through the two branches of the network.
The Differencing layer is used to find similar inputs and magnify the differences between dissimilar pairs by using the Euclidean Distance function where,
- are the two inputs.
- is the output of the encoding.
- is the distance function.
One of the key features of the Siamese network is that any changes made to one side of the network are reflected on the other. This feature allows the network to learn good data representations that we can apply to new, unseen samples. The network then returns an encoding, often represented as a similarity score, that we can use to differentiate between classes.
The architecture of this network is shown in the figure below. Note that the network is a one-shot classifier and does not require a lot of examples per class.
Loss Functions Used in Siamese Networks
A loss function is a mathematical function used to measure the difference or dissimilarity between the predicted and actual output for a given input in a machine-learning model. The goal of training a model is to minimize the loss function, which we can achieve by adjusting the model's parameters.
There are many loss functions, each appropriate for different types of problems. For example, mean squared error is commonly used for regression problems, while cross-entropy loss is commonly used for classification problems.
Unlike many other networks, the Siamese Network uses multiple loss functions. These functions are explained below.
Binary Cross Entropy Loss
Binary cross-entropy loss is a loss function commonly used for binary classification problems, where the goal is to predict one of two possible outcomes. In a Siamese network, the goal is to classify an image as "similar" or "dissimilar" to another.
The function calculates the difference between the predicted probability of the positive class and the actual outcome. In the case of the Siamese network, the predicted probability is the probability that the two images are similar, and the actual outcome is a binary value of 1 if the images are similar and 0 if they are dissimilar.
It is defined as the negative log-likelihood of the true class, which is calculated as:
where,
- y: true label.
- p: predicted probability.
The goal of training a model using binary cross-entropy loss is to minimize this function, which we can achieve by adjusting the model's parameters. By minimizing the binary cross-entropy loss, the model will learn to predict the correct class accurately.
Contrastive Loss
The Contrastive Loss function finds the difference between image pairs by using distance as a similarity measure. This function is useful when there are few training examples per class. A caveat of using Contrastive loss is that it requires pairs of negative and positive training samples. We can visualize this loss in the figure below.
The Contrastive Loss equation is where,
- m: classification margin.
- D: Euclidean distance.
- Y: input to the function.
When Y is 0, the inputs share the same class. When the value of Y is 1, they are from different classes. The margin m defines the distance function's margin to identify pairs contributing to the loss. The value of m is always greater than 0.
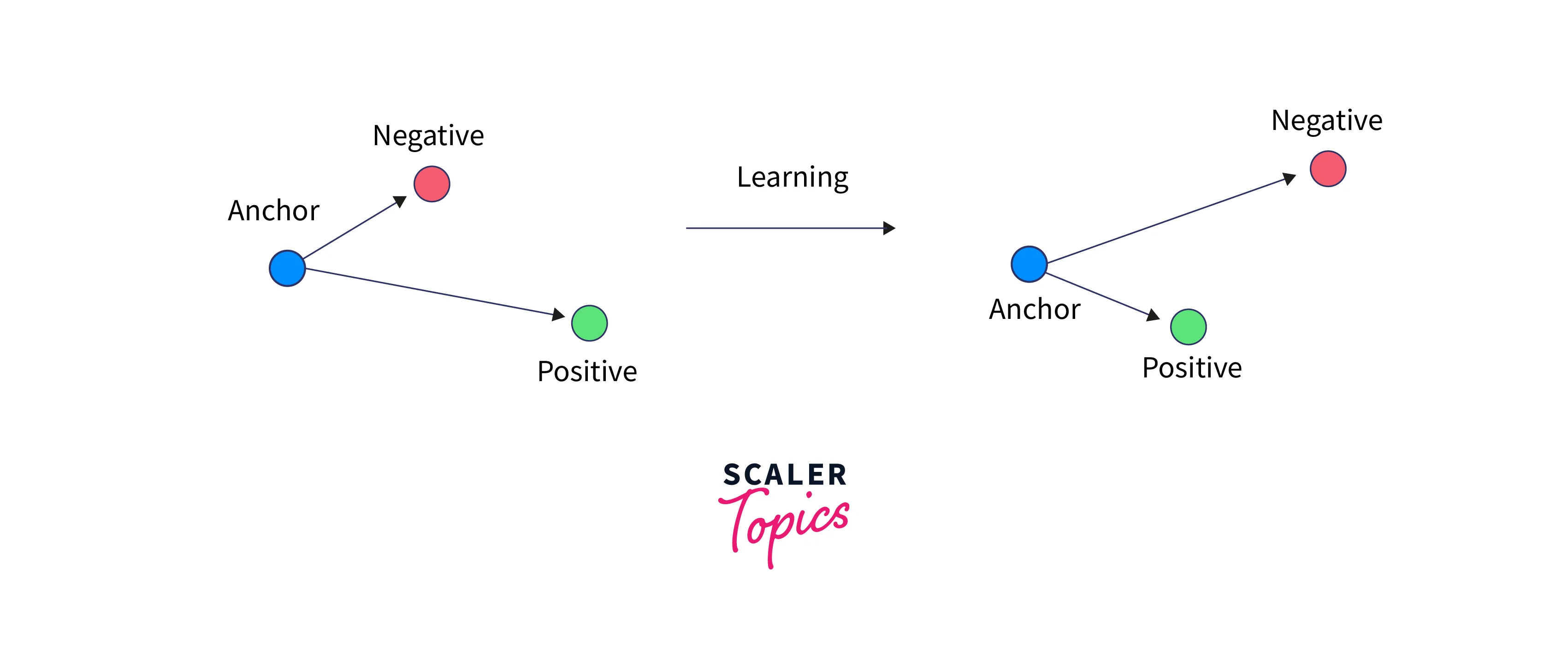
Triplet Loss
The triplet loss uses triples of data. These triples can be seen in the image below.
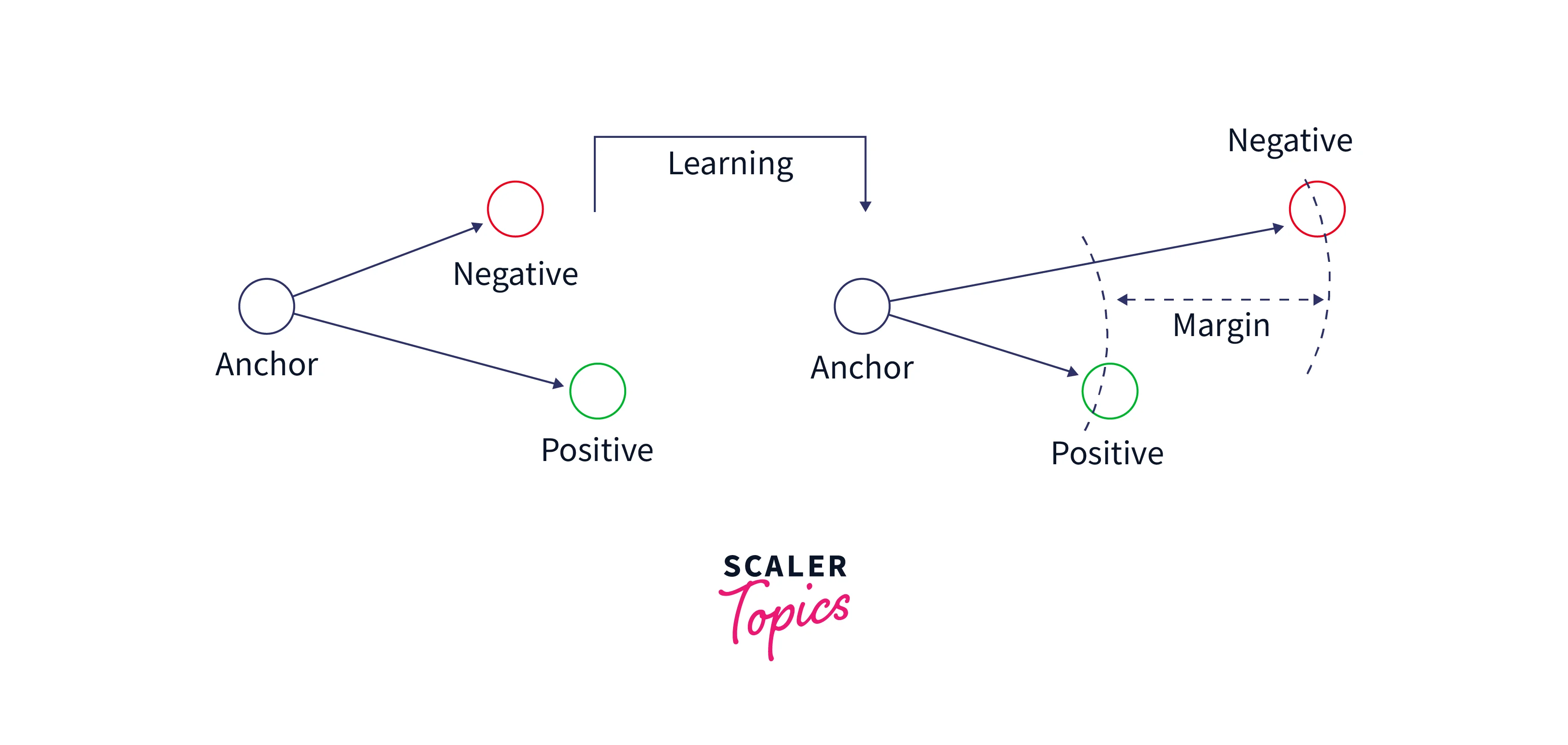
The objective of the triplet loss function is to maximize the distance between the anchor and the negative samples while minimizing the distance between the anchor and the positive samples. This task is shown in the below image.
The Triplet loss is defined as: where,
- d: Euclidean distance.
- a: anchor input.
- p: positive input.
- n: negative input.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Building a Signature Verification Model With Siamese Networks
Signature verification is identifying forged signatures given a dataset of real ones. For this task, a model has to learn the difference between hundreds of signatures. Given a fake or a real signature, the model has to differentiate between them. This verification task is extremely hard for a regular CNN due to the complexity of changes and lack of training samples. In most cases, only a single signature is available per person, and the model needs to learn how to verify signatures for thousands of people. The following sections explore building a model to tackle this task using PyTorch.
Dataset
The Dataset we will be using is a signature verification dataset known as ICDAR 2011. This Dataset contains Dutch signatures that are either forged or original. An example of the data is shown below.

We can download the Dataset from this drive link.
Description of Problem Statement
This article considers recognizing fake signatures as part of a signature verification problem. We aim to take a dataset of signatures and use a Siamese network to predict which test signatures belong to real people and which are forged. We need to create a pipeline that reads the Dataset, creates image pairs, and passes them to the Siamese network. After training the network on the Dataset, we need to create functions for inference.
Imports
To create the Siamese Network, we need to import a few libraries. We import the Pillow library(PIL) for image processing. We will import the plotting package matplotlib, the numerical library numpy, and the progress bar library tqdm for other utilities. We will use Pytorch and torchvisionto train and build the network.
Utility Functions
To visualize the network's outputs, we create a function that takes the images and the labels as inputs and plots them in an easy-to-visualize grid.
Data Preprocessing
The Siamese network's data structure is very different from the usual image classification networks. Instead of providing an image and a label, the Dataset Generator for the Siamese network must provide pairs of images. These pairs are converted to Black and white, then resized and converted to Tensors. There are two types of pairs - the positive pair, where both the inputs images are identical, and the negative pair, where the images are not identical. We also create a function that returns the size of the Dataset when called.
Turn Learning into Career Growth
Brief Description of the Features
The features that the network gets are pairs of images. There are positive or negative data pairs. Both the pairs are image data and are Tensor representations of the underlying images. The labels provided to the Siamese network are categorical.
Standardization of the Features
To standardize the features, we first convert them to Black and White. We also resized all the images to be (105x105) square as the Siamese Network requires this size. Finally, we convert all the images to Tensors to improve performance and be able to use the GPU.
Splitting the Dataset
We split the Dataset into training and testing parts to ensure that the model can be used for prediction and not just training. For simplicity, we only use the first 1000 data points. Setting the load_subset function to None would use the entire Dataset but take much longer. We do not perform Data Augmentation here, but that is an option to make the network perform better in the long run.
Neural Network Architecture
We can create the architecture that we described above in a few steps. First, we create a function that creates blocks of Convolutions, Batch Normalisation, and ReLU with different input and output channels. We give this function the option of having a Dropout layer at the end or skipping that layer. We also create another function that generates blocks of FC layers followed by ReLU layers. We can use these functions to create the Sequential model that defines the Siamese Network. After creating the CNN part of the architecture using the functions we defined earlier, we must create the FC part of the network. Note that different padding and kernel sizes are used across the network. The FC part of the network is blocks of Linear layers followed by ReLU activations. Once we have defined the architecture, we can run a forward pass for the data we pass to the network. Note that the view function is used to resize the output of the previous block by flattening dimensions. After creating this function, we can train the Siamese network on the data.
Loss Function
The loss function that the Siamese Network uses is contrastive loss. We can define this loss using the equations mentioned earlier in the article. To improve code performance, instead of defining the loss as a simple function, we inherit from nn.Module and create a class that returns the outputs of the function. This wrapper will allow PyTorch to optimize the code for better runtime performance.
Training the Siamese Network
Now that we have loaded and cleaned up the data, we can train the Siamese network. To do so, we first create the training and testing data loaders. Note that the evaluation DataLoader has a batch size of 1 as we want to perform one-by-one evaluations. We then send the model to the GPU and define the Contrastive Loss and the Adam optimizer.
We then write a function that takes the train DataLoader as an argument. We keep a running array of the loss and the counter to plot it later. After that, we iterate over the points in the DataLoader. For every point, we send the pairs to the GPU, run the pairs through the network, and calculate the Contrastive Loss. We can then perform the backward pass and return the net loss for a batch of data.
We can train the model for several epochs using our created function. This article only trains the model for a few epochs as a demo. If the evaluation loss is the best we have seen across the entire training period, we save the model for inference at that epoch.
Testing the Model
After training the model, we can evaluate it and run inference for a single data point. Like the training function, we create an evaluation function that inputs the test data loader. We iterate the data loader one at a time and obtain the pairs of images we wish to test. We pass these image pairs to the GPU and run the model over them. After obtaining the output from the model, we find the Contrastive loss and save it to a list.
We can run the code for a single evaluation over all the test data points. To visualize the performance, we will plot the image and print the pairwise distances between the data points the model identifies. We can then plot these results as a grid.

Pros and Cons of Siamese Networks
Like all Deep Learning applications, Siamese Networks have multiple pros and cons. Some of them are listed below.
Cons
- The biggest disadvantage of using a Siamese network is that it returns only a similarity score. Since the network's output is a distance metric, it does not sum up to 1. This property makes it harder to use in some cases.
Pros
- Siamese networks are robust to varying numbers of examples in classes. This robustness is because the network requires very little information about the classes.
- Domain-specific information does not need to be provided to the network to classify images.
- Siamese networks can perform predictions even with a single image per class.
Applications of Siamese Networks
Siamese Networks have quite a few applications. Some of them are as follows.
Facial recognition Due to the paired nature of the Siamese networks, one-short facial recognition is a good use case to use this network. The contrastive loss is used to push different faces away from each other and pull similar faces closer. In doing so, the Siamese network learns to identify faces without requiring too many examples.

Fingerprints Similar to facial recognition, we can also use Siamese Networks for fingerprint recognition. Once the fingerprints in the database have been cleaned and pre-processed, we can feed them pairwise to the network. The Siamese network then learns to find their differences and identify the valid and invalid fingerprints.
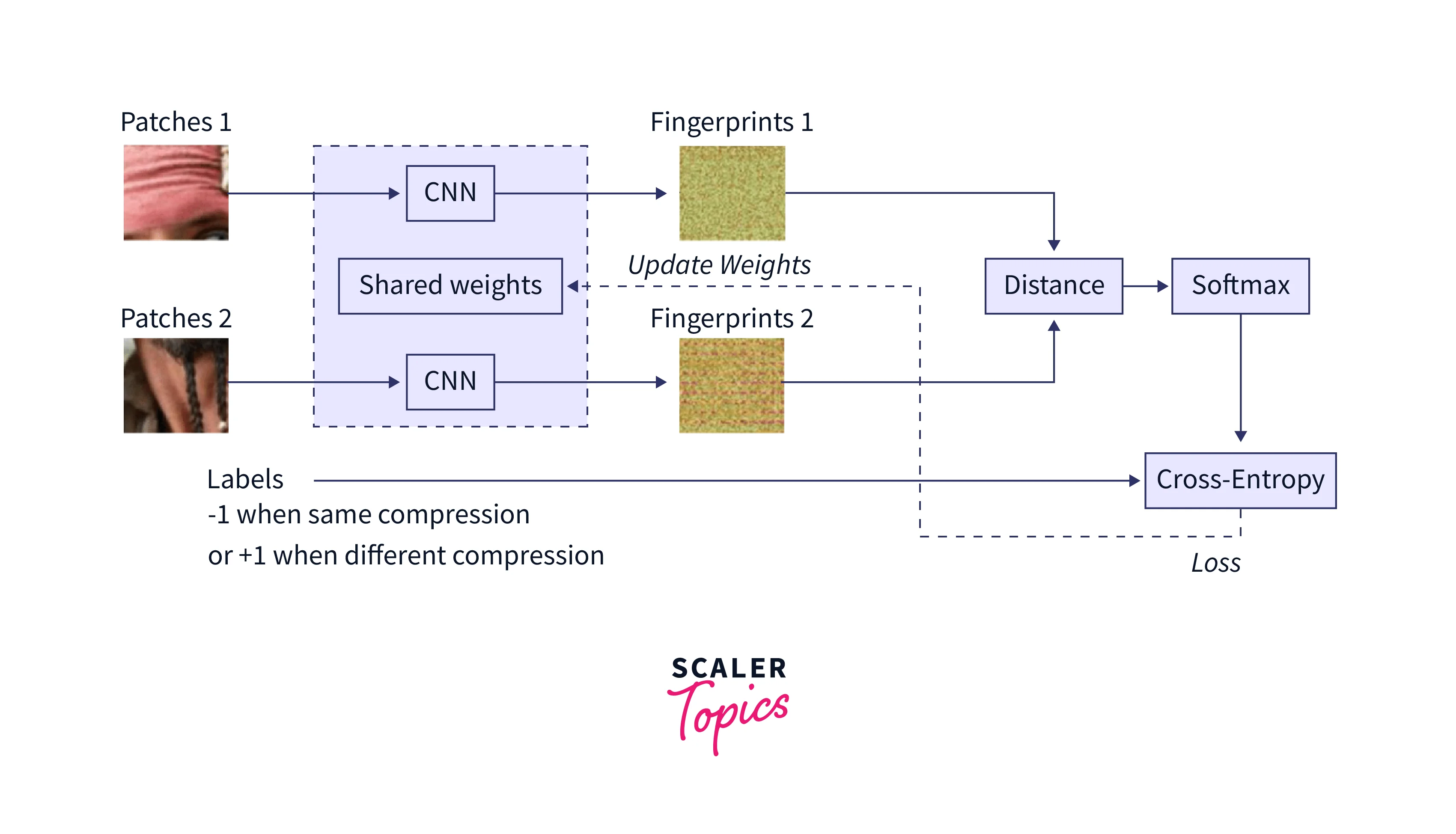
Signature Verification This article focused on implementing Signature Verification using Siamese networks. As we saw in this article, we can create a pairwise dataset using signatures and the network to identify which signatures are forged and which are real.

Text Similarity Another useful application of Siamese Networks is Text similarity. Given multiple pieces of text, the network can be fed a pairwise dataset and tasked with identifying similar ones. Examples of such tasks include - finding similar questions from a question bank and using Siamese networks to find similar documents from a text database.
Conclusion
- Siamese networks are a powerful tool for classifying datasets with few examples per class.
- We learned the concepts behind Siamese networks and understood the architecture, loss functions used, and how to train such a network.
- We explored the Signature verification task using the ICDAR 2011 dataset and implemented a model to identify forged signatures.
- We also understood the entire training and testing pipeline for Siamese networks, including its paired data representation.