Attention Mechanism in Deep Learning
The attention mechanism in deep learning, a pivotal advancement in the field, was initially developed to enhance the encoder-decoder model's efficiency in machine translation. This mechanism operates by selectively focusing on the most pertinent elements of the input sequence, similar to how we might concentrate on a single conversation amidst the noise of a crowded room.
Fundamentally, the attention mechanism is akin to our brain's neurological system, which emphasizes relevant sounds while filtering out background distractions. In the realm of deep learning, it allows neural networks to attribute varying levels of importance to different input segments, significantly boosting their capability to capture essential information. This process is crucial in tasks such as natural language processing (NLP), where attention aids in aligning relevant parts of a source sentence during translation or question-answering activities.
Beyond NLP, attention mechanisms have demonstrated substantial benefits in computer vision, like Google Streetview's precise identification of house numbers. This guide aims to deepen your understanding of the attention mechanism, exploring its types, applications, advantages, and hands-on implementation in TensorFlow, enhancing your deep learning models' performance by focusing on the most relevant information.
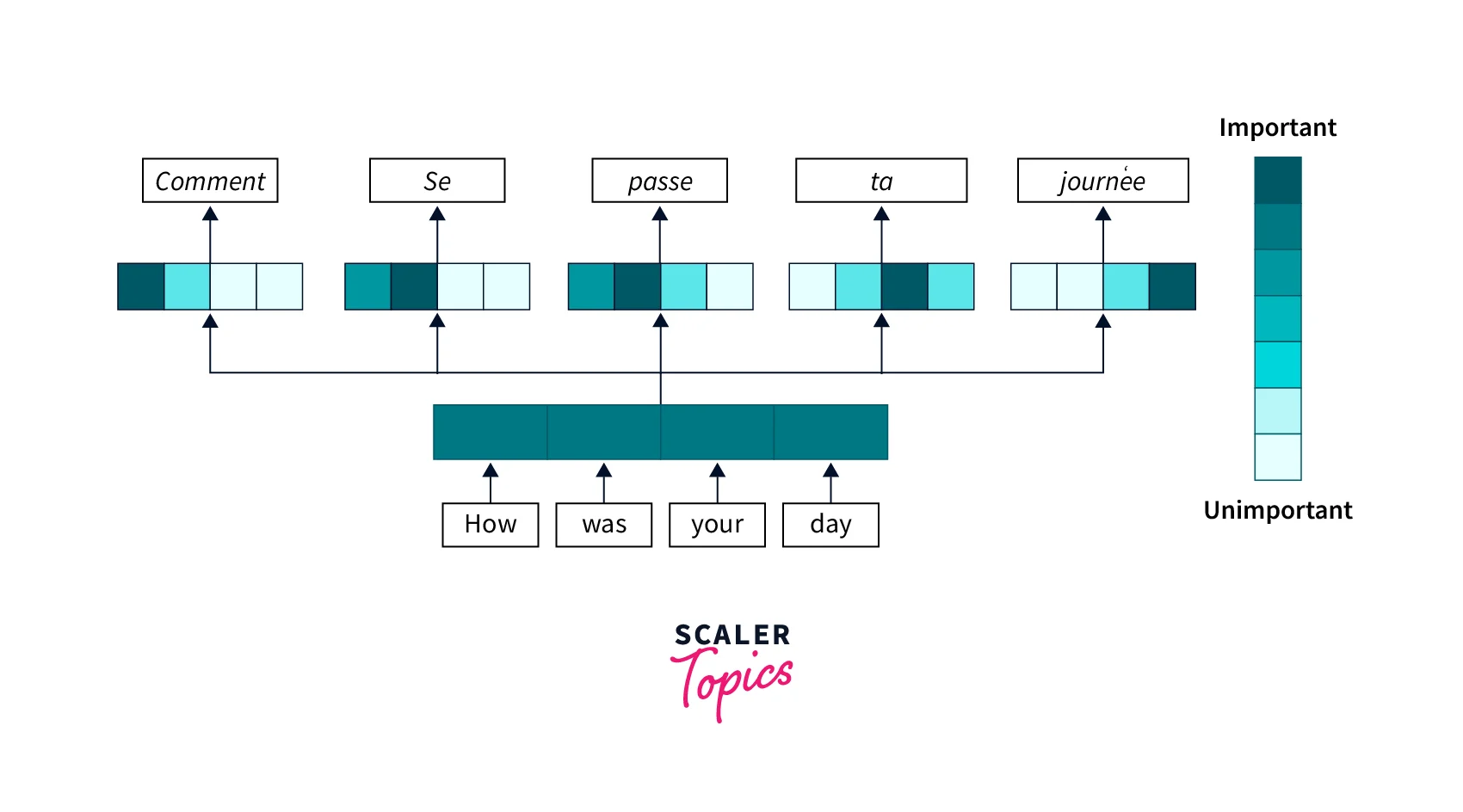
What is the Attention Mechanism
Attention mechanisms in deep learning are used to help the model focus on the most relevant parts of the input when making a prediction. In many problems, the input data may be very large and complex, and it can be difficult for the model to process all of it. Attention mechanisms allow the model to selectively focus on the parts of the input that are most important for making a prediction, and to ignore the less relevant parts. This can help the model to make more accurate predictions and to run more efficiently.
Need of Attention Mechanism
In many deep learning models, data is processed by passing it through multiple layers of neural networks. These networks are composed of many interconnected nodes organized into layers. Each node processes the data and passes it on to the next layer. This allows the model to extract increasingly complex features from the data as it passes through the network.
However, as the data passes through these layers, it can become increasingly difficult for the model to identify the most relevant information.
Attention mechanisms were introduced as a way to address this limitation in these models. In attention-based models, the model can selectively focus on certain parts of the input when making a prediction.
Consider machine translation as an example, where a traditional seq2seq model would be used. Seq2seq models are typically composed of two main components: an encoder and a decoder.
- The encoder processes the input sequence and represents it as a fixed-length vector (context vector), which is then passed to the decoder.
- The decoder uses this fixed-length context vector to generate the output sequence.
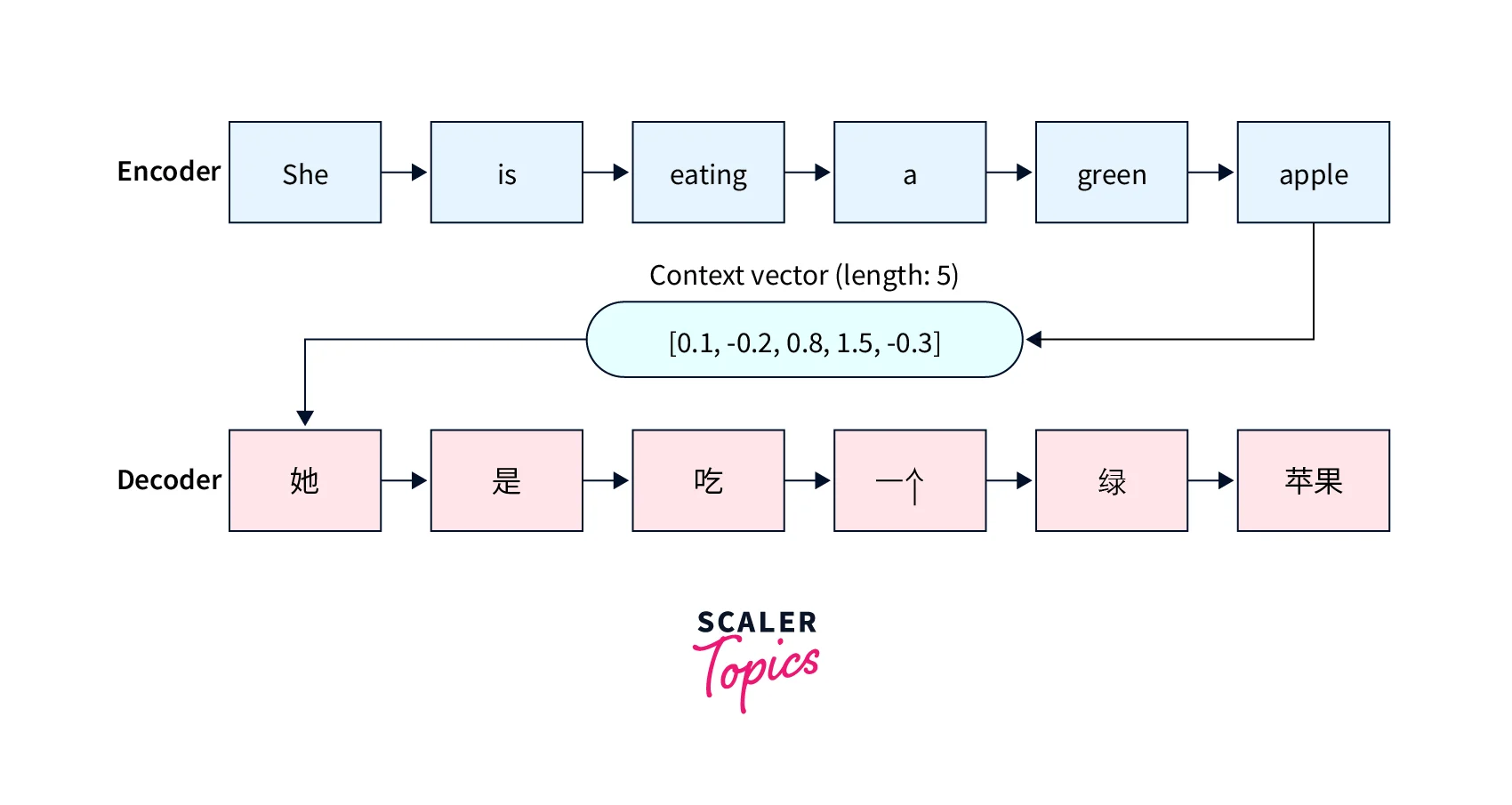
The encoder and decoder networks are recurrent neural networks like GRUs and LSTMs.
Note: One glaring disadvantage of this approach is the model's inability to remember long sequences because of the fixed-length context vector.
High-level Overview of the Attention Mechanism
The Attention mechanism solves the problem discussed above. The attention mechanism allows the model to "pay attention" to certain parts of the data and to give them more weight when making predictions.
In a nutshell, the attention mechanism helps preserve the context of every word in a sentence by assigning an attention weight relative to all other words. This way, even if the sentence is large, the model can preserve the contextual importance of each word.
For example, in natural language processing tasks such as language translation, the attention mechanism can help the model to understand the meaning of words in context. Instead of just processing each word individually, the attention mechanism allows the model to consider the words about the other words in the sentence, which can help it understand its overall meaning.
We can implement the attention mechanism in many different ways, but one common approach is to use a neural network to learn which parts of the data are the most relevant. This network is trained to pay attention to the data's most important parts and give them more weight when making predictions.
Overall, the attention mechanism is a powerful tool for improving the performance of sequence models. By allowing the model to focus on the most relevant information, the attention mechanism can help to improve the accuracy of predictions and to make the model more efficient by only processing the most important data. As deep learning advances, we might see even more sophisticated applications of the attention mechanism.
How Does the Attention Mechanism Work?
To be able to understand the attention mechanism in detail, it is required that you understand Sequence to Sequence models like LSTMs and GRUs.
The first paper which brought the idea of attention mechanism to the world was Bahdanau et al., 2015. It proposes the encoder-decoder model with an additive attention mechanism.
Let's consider a machine translation example where x denotes the source sentence with a length of n and y denotes the target sequence length with a length of m.
For a bi-directional sequence model which could be used for the task, there will have two hidden states, the forward and the backward hidden states. In Bahdanau et al., 2015, a simple concatenation of these two hidden states represents the encoder state. That way, both preceding and following words can be used to compute the attention of any word in the input.
Note: In a normal encoder-decoder model, only the last hidden state of the encoder will represent the encoder state.
The decoder network's hidden state is,
Where t denotes the length of the sequence and the ct, is the context vector (of each output yt), which is nothing but a sum of hidden states of the input sequence hi, weighted by alignment scores.
Now how is this alignment score that acts as the weight calculated? The alignment score is parameterized by a single feed-forward neural network which is trained along with other parts of the model.
The alignment model gives out a score for each pair of input and output at position , based on the relevance. The set of are the weights of how much each source hidden state should attend to each output state.
The feed-forward neural network learns this relevance/alignment score, and its hidden state is softmax to obtain the probabilities.
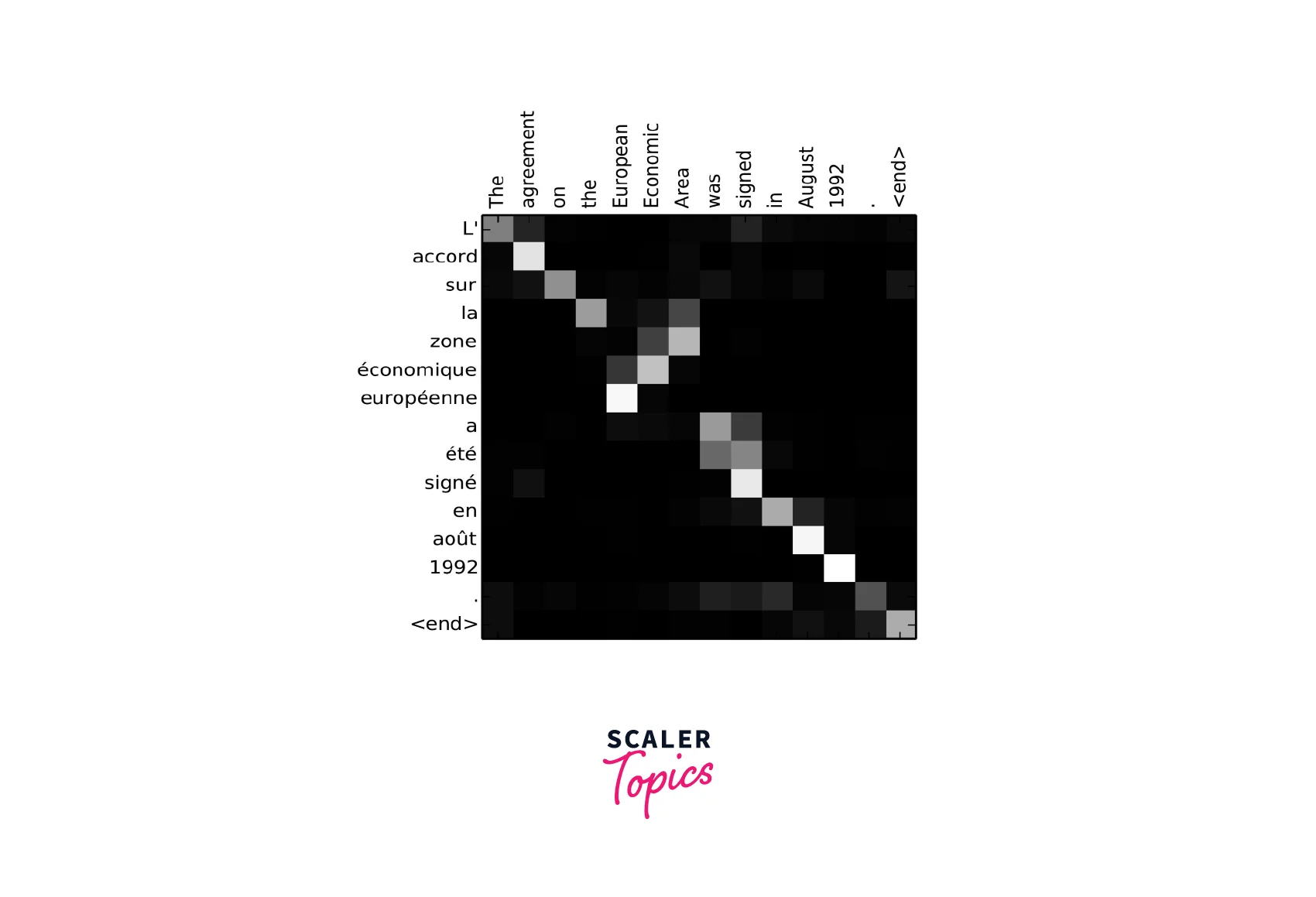
The image above shows an alignment matrix learned using the attention mechanism.
There are three main components of the equation,
- Query vector - - which is matched against a set of keys to obtain a score
- Key vector - - the set of weights that denote the importance of each query element
- Value vector -
dontloo's answer in stackexchange
The key/value/query concept is analogous to retrieval systems. , For example,, when you search for videos on Youtube, the search engine will map your query (text in the search bar) against a set of keys (video title, description, etc.) associated with candidate videos in their database, then present you the best-matched videos (values).
The attention operation can also be thought of as a retrieval process.
In Bahdanau et al., 2015's attention mechanism, the Value and Key vectors are essentially the same, the encoded hidden states, while the Query vector is the previous encoder output .
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Types of Attention
Several different types of attention mechanisms can be used in deep learning models. Some of the most common types include:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Self-Attention
Imagine the sentence below being used as input for a machine translation model:
The driver could not drive the car fast enough because it had a problem.
In the above sentence, does the it refer to the driver or the car? Who had the problem?
For humans, it is a straightforward answer, but for machines, it might not be very clear if they cannot learn the context.
When doing machine translation, for example, it is important to have attention scores for the source and target sequences, and to have it between the source sequence themselves, thus self-attention.
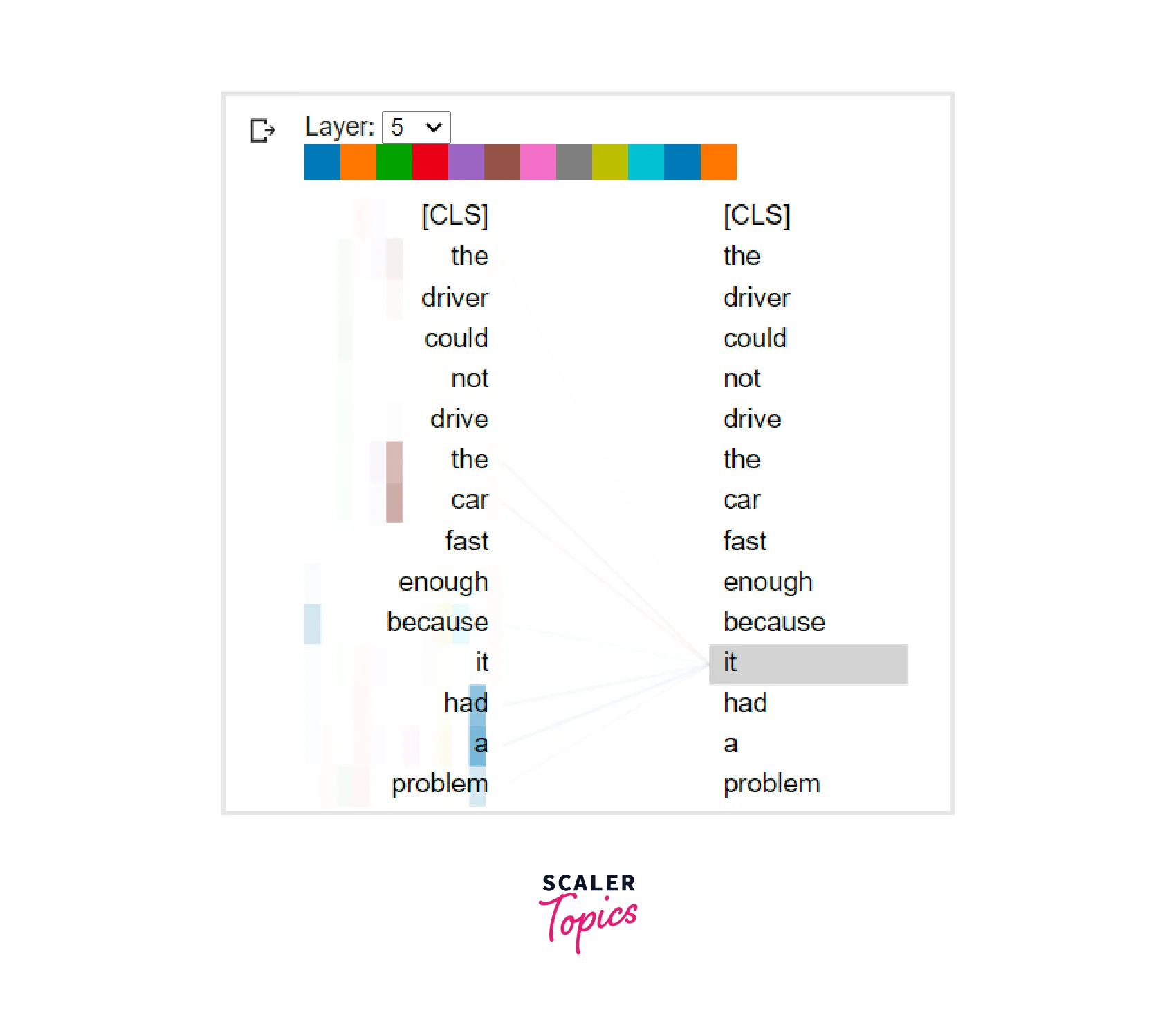
The above illustration shows the attention weights of a learned model, and we can see that when encoding the word "it", the model was rightfully paying more attention to the word "car" than any other word.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Dot-product Attention
- Dot-product Attention computes the attention weights as the dot product of the query and key vectors.
Scaled dot-product Attention
- Scaled dot-product Attention, a variant of dot-product attention that scales the dot product by the square root of the key dimension.
Multi-head Attention
- Multi-head Attention splits the query, key, and value vectors into multiple heads and applies dot-product attention to each head independently.
Turn Learning into Career Growth
Self-attention
- Self-attention is a type of attention mechanism discussed in the previous sections. Here the input sequence is used as both the query and the key.
Structured Attention
- Structured Attention allows the attention weights to be learned using a structured prediction model, such as a conditional random field.
These different attention mechanisms can be used in various combinations and configurations to achieve different performance and efficiency trade-offs.
Difference Between Global vs Local Attention
- Computing attention over the entire input sequence as in Global Attention is sometimes unnecessary because despite its simplicity it can be computationally expensive. Thus Local Attention resulted as a solution for this as Local Attention considers only a subset of the input units/tokens.
- Comparatively Local Attention is seen as hard attention since we need to take hard decisions at the first, to exclude some input points.
- In global attention, we require as many weights as the source sentence length whereas in Local attention it is less because attention is paced over only a few source states.
How to Implement Attention Mechanism With Python?
Let's dive into the implementation of the General Attention Mechanism with Python using Numpy and SciPy libraries.
Initially calculate the attention for the first four-word in a sequence of four, you can then generalize the code to calculate the attention output for all four words in matrix form.
Firstly defining word embeddings which can be generated byan encoder.
Secondly generating weight matrices by eventually multiplying to the word embedding to generate the queries, keys and values.
The number of rows of each matrix and dimensionality of the word embeddings are equal.
Advantages and Disadvantages of Attention Mechanism
The Attention mechanism is a powerful tool for improving the performance of deep learning models, and it has several key advantages. Some of the main advantages of the attention mechanism include the following:
- Improved accuracy: By allowing the model to pay attention to the most relevant information, the attention mechanism can help to improve the accuracy of predictions.
- Improved efficiency: The attention mechanism can make the model more efficient by only processing the most important data, reducing the computational resources required and making the model more scalable.
- Improved interpretability: The attention weights learned by the model can provide insight into which parts of the data are the most important, which can help improve the model's interpretability.
However, the attention mechanism also has a few disadvantages that should be considered. Some of the main disadvantages include the following:
- Difficulty of training: The attention mechanism can be challenging to train, especially for large and complex tasks. This is because the attention weights must be learned from the data, which can require a large amount of data and computational resources.
- Overfitting: The attention mechanism might be prone to overfitting, which means that the model may perform considerably well on the training data but not generalize well to new data. Regularization techniques can mitigate this, but it can still be challenging when working with large and complex tasks.
- Exposure bias: The attention mechanism can suffer from the problem of exposure bias, which occurs when the model is trained to generate the output sequence one step at a time, but at test time, it is required to generate the entire sequence at once. This can lead to poor performance on the test data, as the model may not be able to generate the entire output sequence accurately.
While the attention mechanism has many advantages, we must also understand its disadvantages.
Applications of Attention Mechanism
Some of the main applications of the attention mechanism include:
- NLP tasks like machine translation, text summarization, and question answering. In these tasks, the attention mechanism can help the model understand the meaning of words in context and to focus on the most relevant information.
- Computer vision tasks like image classification and object detection. In these tasks, the attention mechanism can help the model to identify the most important parts of an image and to focus on specific objects in the scene.
- Speech recognition tasks, such as transcribing audio recordings or recognizing spoken commands. In these tasks, the attention mechanism can help the model focus on the audio signal's relevant parts and identify the words being spoken.
- Music generation tasks, such as generating melodies or chord progressions. In these tasks, the attention mechanism can help the model to focus on the relevant musical elements and create coherent and expressive compositions.
Overall, the attention mechanism has many potential applications in a wide range of deep learning tasks, and it is an important tool for improving the performance of these models.
Simple Implementation of Attention Mechanism in Tensorflow 2
Elevate your understanding of deep learning with our Deep Learning free course. Enroll today and pave the way for a rewarding career in artificial intelligence.
Conclusion
In conclusion, attention mechanisms are a powerful tool in deep learning. They have already been applied successfully in a variety of domains and have many practical applications. It is worth considering incorporating attention mechanisms into your work and projects as they can be highly effective.
Here are some key takeaways about attention mechanism from this article:
- Attention mechanisms are a type of neural network layer that can be added to deep learning models.
- They allow the model to focus on specific parts of input by assigning different weights to different parts of the input.
- This weighting is typically based on the relevance of each part of the input to the task at hand.
- Attention mechanisms are effective in a variety of tasks, including machine translation, image captioning, and speech recognition.
- They can be implemented using various techniques, such as dot-product attention, multi-headed attention, and transformer architectures.
- Attention mechanisms can be useful for handling long input sequences, as they allow the model to selectively focus on the most relevant parts of the input.
- They can also be used to improve the interpretability of a model by providing a visual representation of which parts of the input the model is paying attention to.