Autoencoders

Overview
An autoencoder is a neural network designed to learn a compressed representation of data by training an encoder network to map the input data to a lower-dimensional latent space and a decoder network to reconstruct the original data from the latent space. Autoencoders can be used for tasks such as dimensionality reduction, feature extraction, anomaly detection, data denoising, image generation, and semi-supervised learning. They are trained using supervised learning and can be applied to various data types, including images, text, and time series.
What is an Autoencoder?
An autoencoder is a neural network used to learn a representation (encoding) for a dataset, typically for dimensionality reduction. The network is trained to reconstruct the original data from the reduced encoding. It learns to compress the data onto a lower-dimensional latent space and then uncompress it back to the original space.
Autoencoders are used in various applications, such as image denoising and anomaly detection. There are various types of autoencoders, including convolutional autoencoders, denoising autoencoders, and variational autoencoders (VAEs). VAEs are a generative model, meaning they can generate new data samples similar to the training data.
The structure of an autoencoder typically consists of two parts: an encoder and a decoder. The encoder and decoder are usually implemented as neural networks. During training, the autoencoder minimizes the reconstruction loss, which is the difference between the input and reconstructed data.
Architecture of Autoencoders
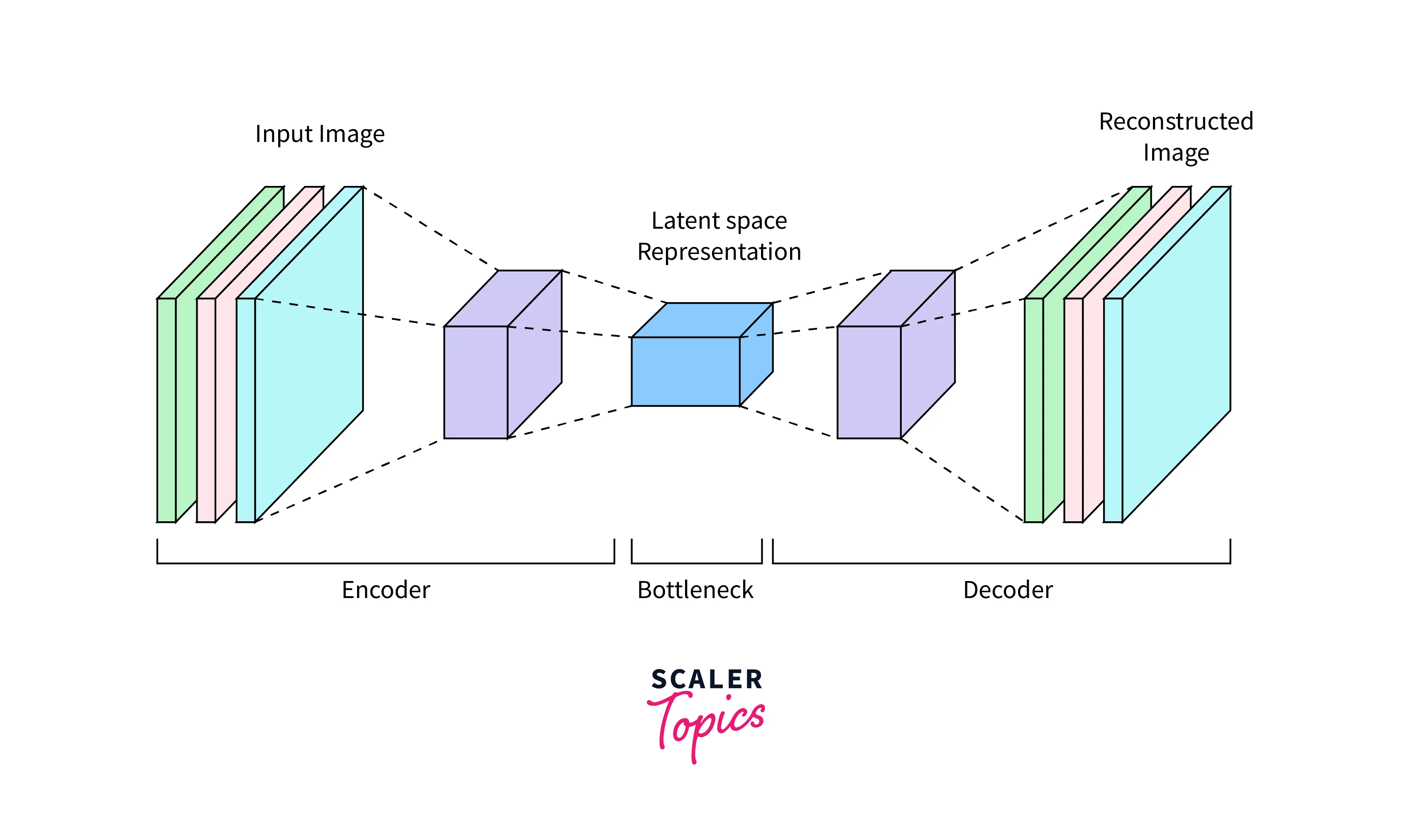
The architecture of an autoencoder typically consists of two parts: an encoder and a decoder. The encoder maps the input data to a lower-dimensional latent space, and the decoder maps the latent representation back to the original data space.
The encoder and decoder can be implemented as feedforward neural networks. The input to the encoder is the data you want to compress, and the output is the latent representation. The input to the decoder is the latent representation, and the output is the reconstructed data.
Here is a simple example of an autoencoder architecture:
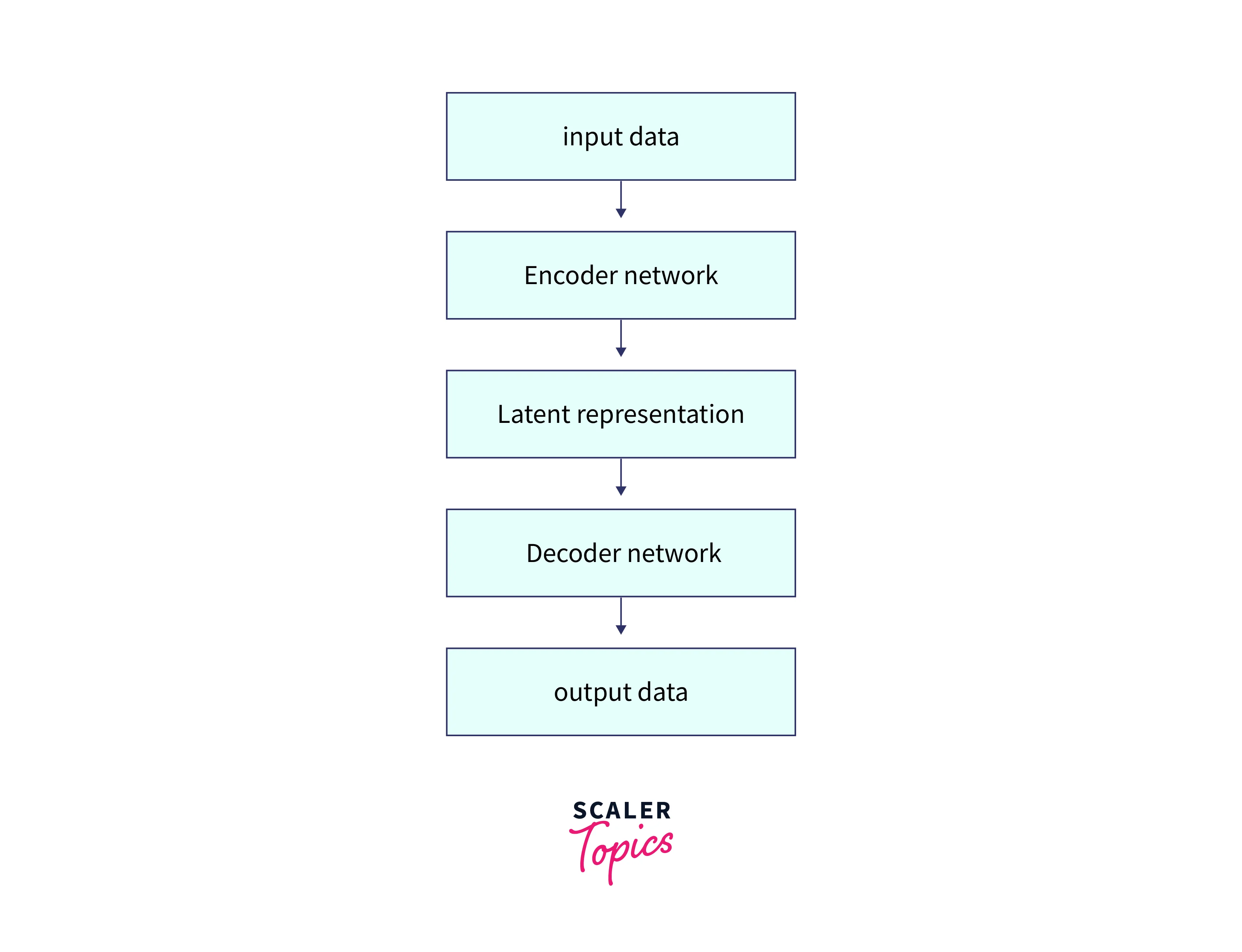
The encoder and decoder networks can have any number of layers and units, depending on the complexity of the data and the desired level of compression. During training, the autoencoder minimizes the reconstruction loss. The goal is to learn a representation that captures the most important features of the data while discarding the noise or less important details.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Types of Autoencoders
There are several types of autoencoders, each with its unique properties and characteristics:
-
Standard autoencoder: This is the basic form of autoencoder, where the encoder and decoder are composed of a linear stack of fully connected (dense) layers.
-
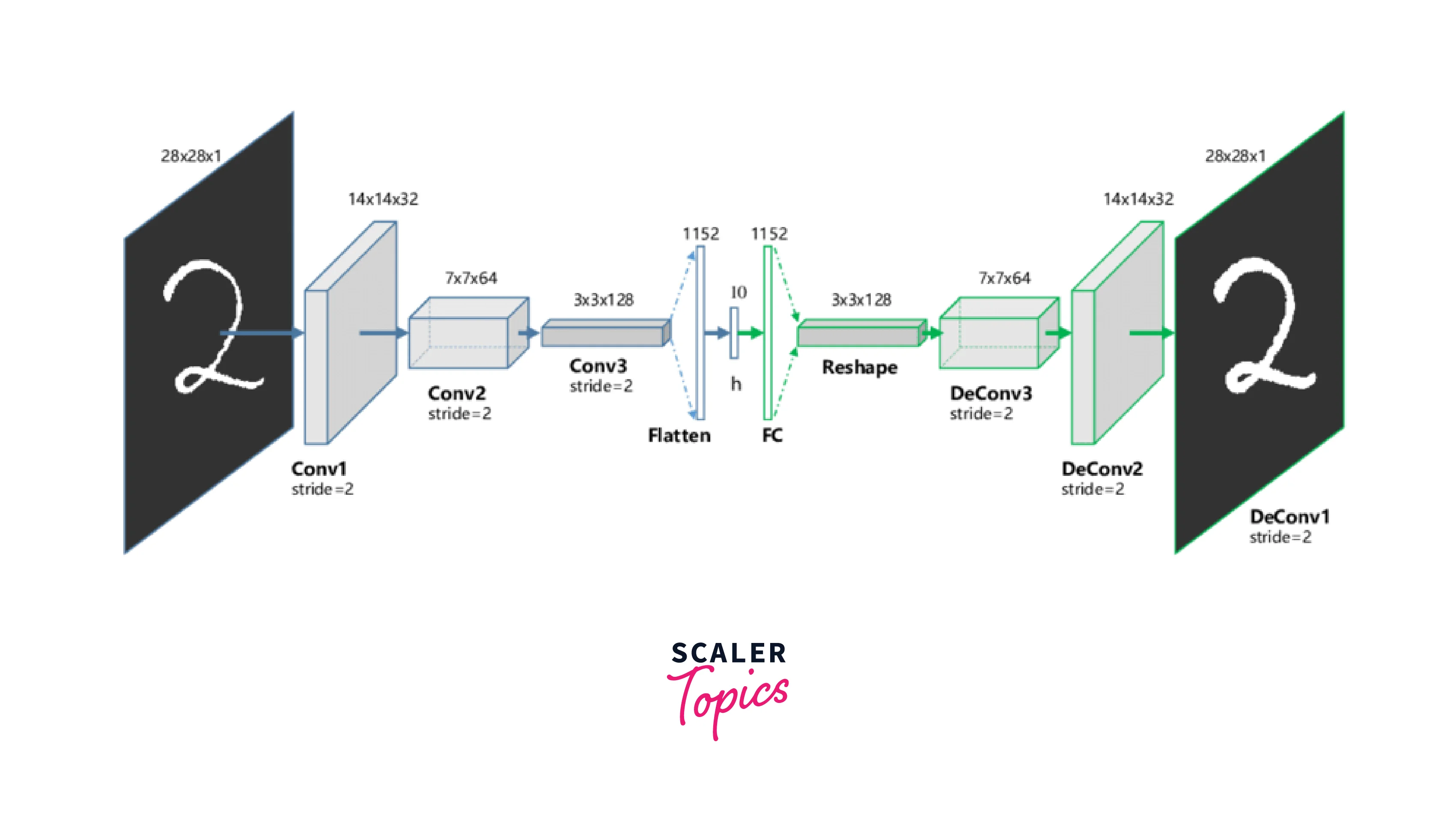
Convolutional autoencoder: This type of autoencoder is similar to a standard autoencoder, but the encoder and decoder use convolutional layers instead of dense layers. This is useful for processing data that has a grid-like structure, such as images.
-
Deep autoencoder: This refers to an autoencoder with many layers in the encoder and decoder networks. Deep autoencoders can learn more complex and abstract data representations but are more computationally expensive to train.
-
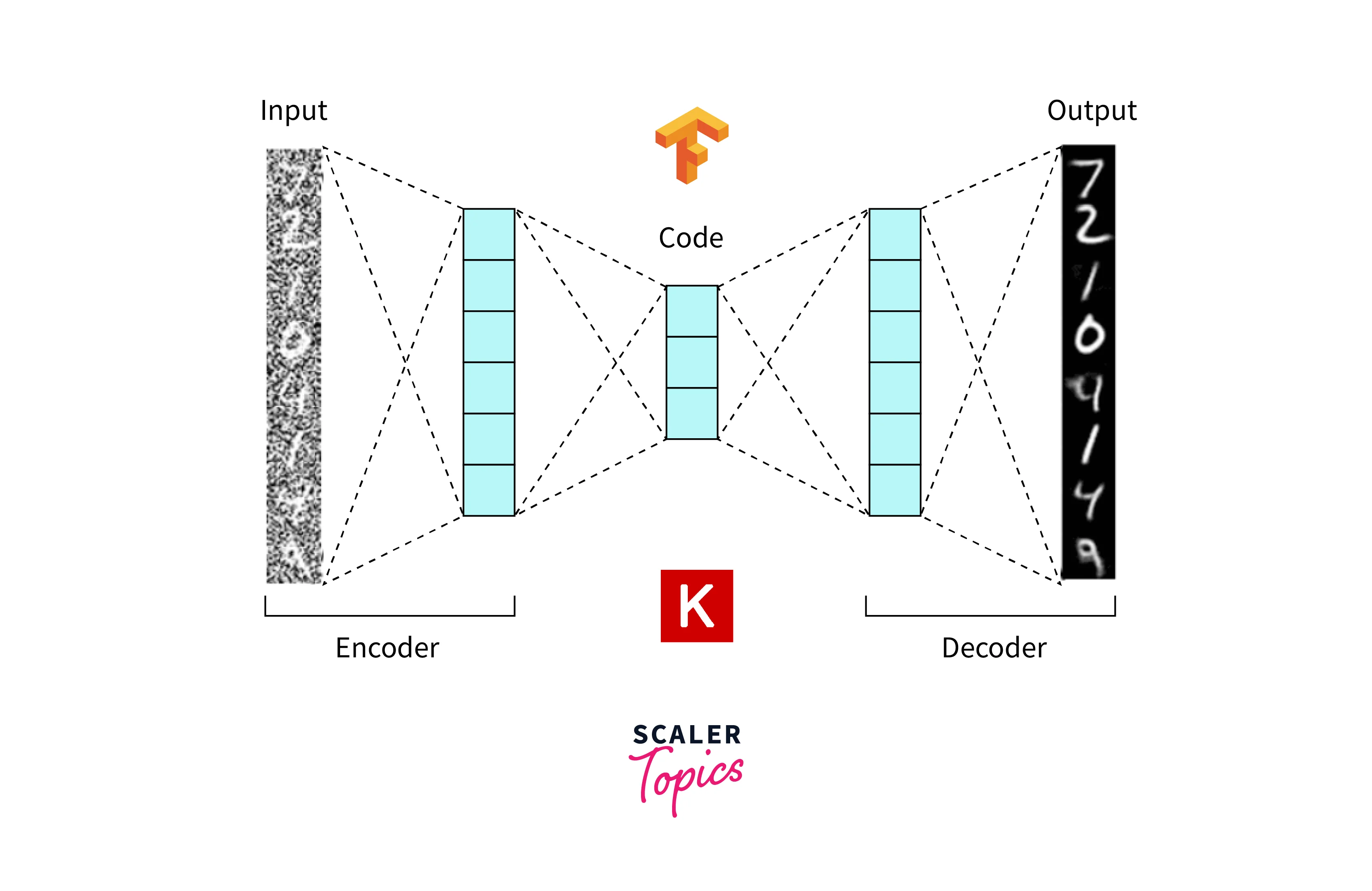
Denoising autoencoder: This autoencoder is trained to reconstruct the original data from a corrupted version. The encoder and decoder are still composed of dense or convolutional layers, but the goal is to learn a robust representation of noise.
- Sparse autoencoder: This autoencoder is trained to learn a representation with a small number of active units (i.e., units with non-zero activations). The goal is to encourage the autoencoder to learn a more efficient and compact data representation.
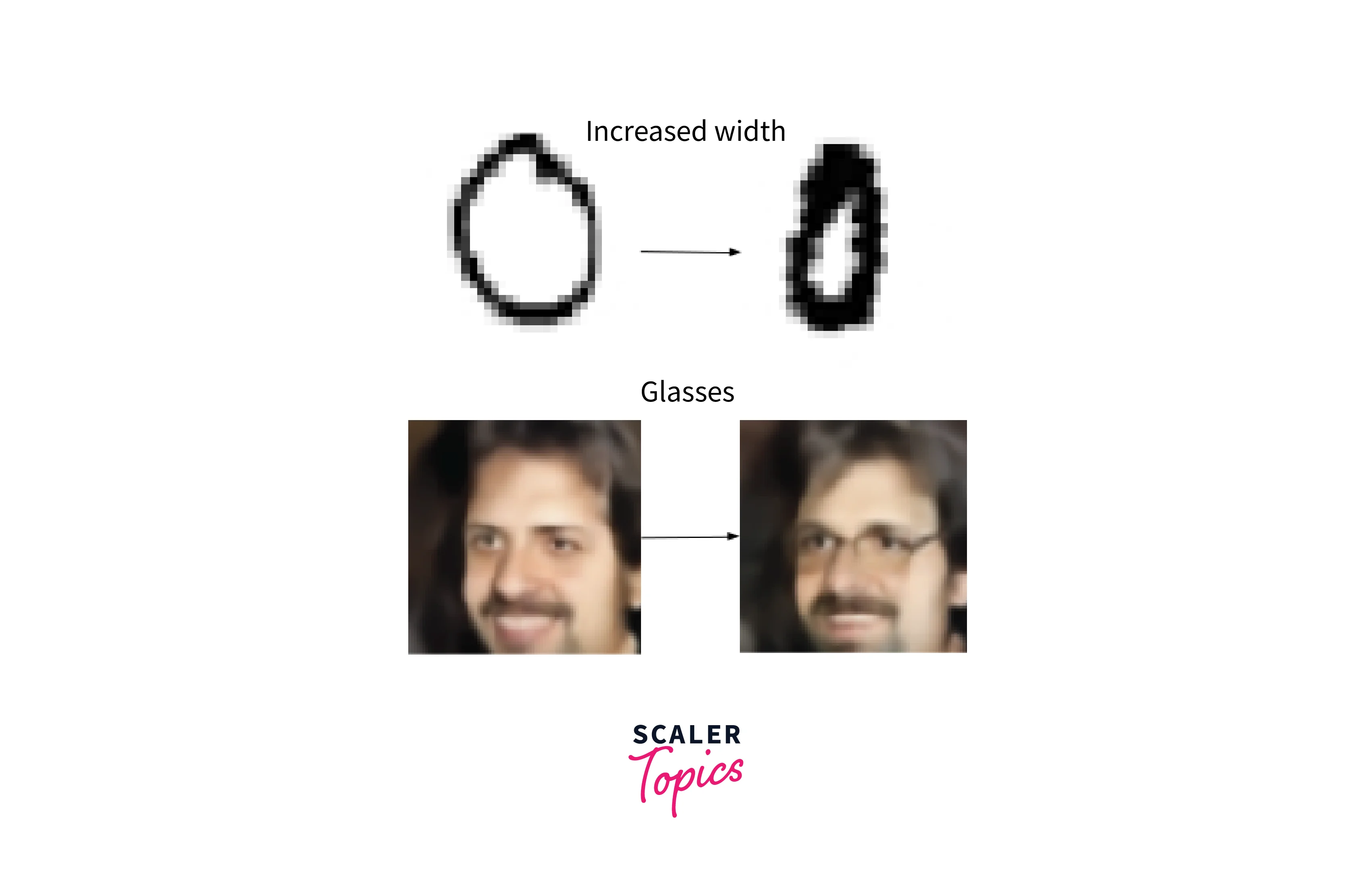
- Variational autoencoder (VAE): A VAE is a generative model that can generate new data samples similar to the training data. It consists of an encoder network and a decoder network, but the encoder outputs two values: a mean and a variance. These values are used to sample a latent code from a normal distribution, passed through the decoder to generate the output data.
How to Train Autoencoders?
To train an autoencoder, you need to do the following:
- Prepare the training data: Autoencoders are trained using supervised learning, so you need a labeled dataset consisting of input and output data pairs. The input data is passed through the encoder, and the output data is the target that the decoder tries to reconstruct.
- Define the autoencoder architecture: This includes the number of layers and units in the encoder and decoder networks, the activation functions, and regularization techniques (e.g., dropout).
- Choose a loss function and an optimizer: The loss function measures the difference between the input data and the reconstructed data, and the optimizer adjusts the weights and biases of the network to minimize the loss. Common loss functions for autoencoders include mean squared error (MSE) and binary cross entropy (BCE).
- Train the autoencoder: During training, the autoencoder takes a batch of input data, passes it through the encoder to produce a latent representation, and then passes the latent representation through the decoder to produce the reconstructed data. The loss is then calculated between the input data and the reconstructed data, and the gradients are backpropagated to update the weights and biases of the network. This process is repeated until the loss converges to a minimum.
- Evaluate the performance of the trained autoencoder: After training, you can evaluate the performance of the autoencoder on a test dataset to see how well it can reconstruct unseen data. You can also use the latent representation produced by the encoder as a feature extractor for other tasks, such as classification or clustering.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Implementation of Autoencoders
Before diving into the code, it's important to understand the basic building blocks of an autoencoder and the different types of autoencoders. Autoencoders are composed of two main components: the encoder and the decoder. The encoder takes in the input data and maps it to a lower-dimensional latent space, while the decoder takes the latent representation and reconstructs the original data. Understanding the architecture and types of autoencoders will help to understand the implementation process better.
Once we understand the basics, we can implement autoencoders using various tools and libraries. Here is an example of how you might implement autoencoder with fashion mnist data :
Load the Fashion MNIST Dataset
Turn Learning into Career Growth
Define Autoencoder Model
This code defines a simple autoencoder with a single hidden layer in the encoder and a single output layer in the decoder using the ReLU activation function. The model is then compiled with the binary cross entropy loss function and the Adam optimizer and trained on the input data x_train. You can adjust the model architecture and training parameters (e.g., number of epochs, batch size) to suit your needs.
Define Encoder and Decoder Model
After training, you can use the autoencoder model to encode the input data and reconstruct the output data
You can also define the encoder and decoder models separately:
This allows you to use the encoder model to encode the input data and the decoder model to reconstruct the output data.
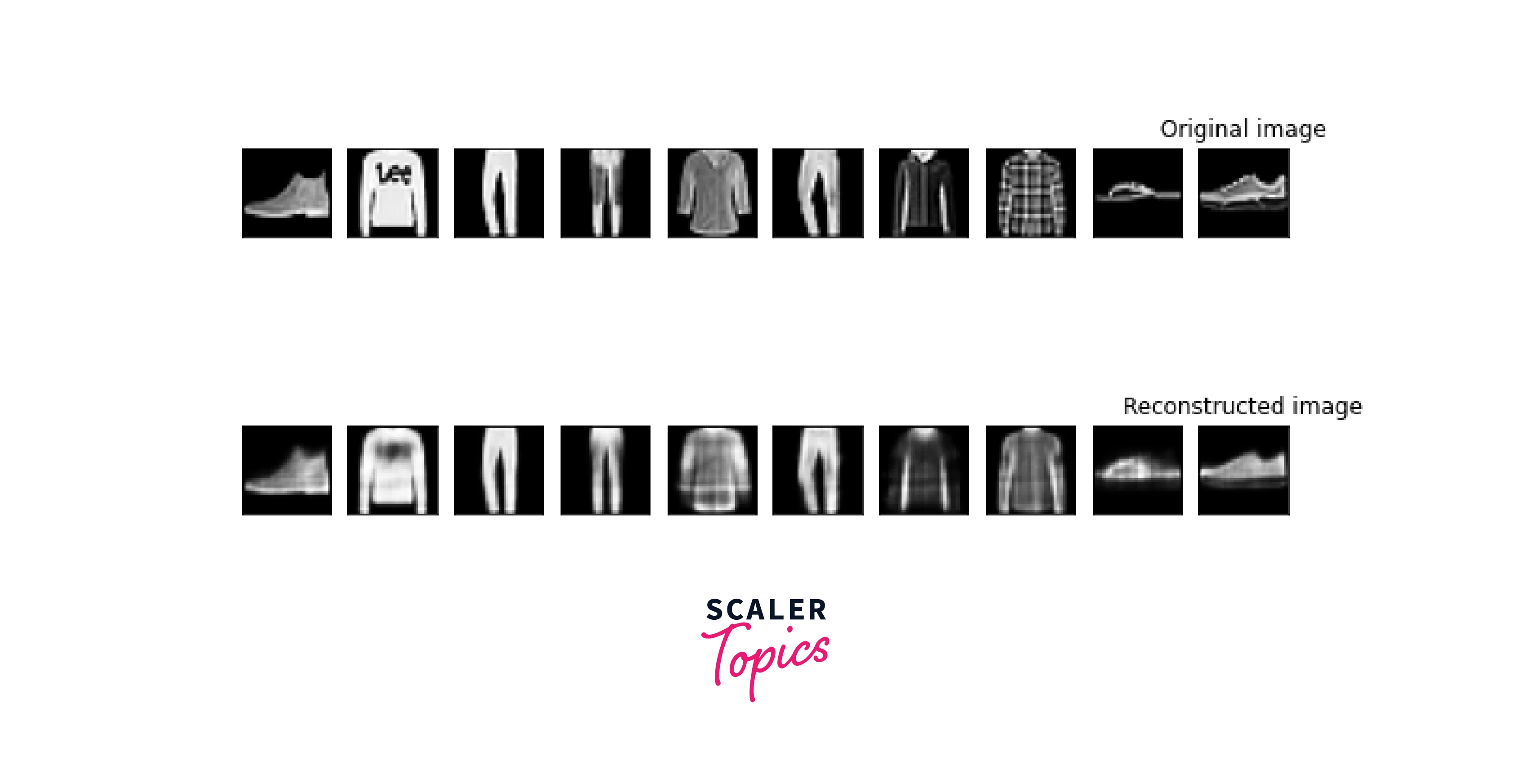
Plot the Original and Reconstructed Images
You might visualize the latent representation and reconstructed data for a simple autoencoder that processes grayscale images:
Output
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Applications of Autoencoders
Autoencoders are a versatile technique with a wide range of applications. Here are a few examples of how autoencoders are used:
- Dimensionality reduction: Autoencoders can reduce the dimensions in a dataset, making it easier to visualize and analyze the data.
- Feature extraction: The latent representation learned by the encoder can be used as a set of features for other tasks, such as classification or clustering.
- Anomaly detection: Autoencoders can be trained to reconstruct normal data and then used to detect anomalies in new data. If the reconstruction error is high for a given data point, it may be considered an anomaly.
- Data denoising: Denoising autoencoders can be trained to remove noise from data, such as corruptions or missing values.
- Image generation: Variational autoencoders (VAEs) can generate new images similar to a training dataset. VAEs learn a probabilistic model of the data distribution and can sample latent codes from this distribution to generate new data.
- Semi-supervised learning: Autoencoders can be used in a semi-supervised learning setting, where only a small portion of the data is labeled, and the rest is unlabeled. We can train the autoencoder to reconstruct the labeled data and then used to label the unlabeled data by reconstructing it and using the label of the closest reconstructed data point.
Data Compression Using Autoencoders
Data compression is reducing the amount of data needed to represent a given piece of information. Autoencoders can be used for data compression by learning a compressed representation of the input data through the encoder and then reconstructing the original data through the decoder. Before diving into the details of data compression using autoencoders, it's important to understand the basic principles of data compression and how autoencoders can be used to achieve it. To use an autoencoder for data compression, you need to define the architecture of the autoencoder and train it on a labeled input and output data pairs dataset. The input data is the data that you want to compress, and the output data is the same as the input data. During training, the autoencoder minimizes a loss function that measures the difference between the input and reconstructed data.
After training, you can use the encoder model to compress the data by encoding it into the latent space and the decoder model to decompress it by reconstructing it from the latent space. The size of the latent space is a hyperparameter of the autoencoder, which determines the compression level. A smaller latent space results in a more compressed representation of the data, while a larger latent space results in a less compressed representation.
Unlock the potential of deep learning with our expert-led free Deep Learning certification course. Enroll now and get certified!
Conclusion
- Autoencoders are neural networks that can learn to compress and reconstruct data.
- They consist of an encoder and decoder network trained to minimize a loss function.
- Autoencoders have many applications, including dimensionality reduction, feature extraction, and data denoising.
- They can be trained on various data types and used in different settings, such as classification and image generation tasks.