What are Capsule Networks?
Overview
As you may know, Deep Learning and its subsidiaries have found their way into many applications, especially in Computer Vision. Capsule Networks is the latest addition to the list of ever-improving fields, as the next iteration to overcome the drawbacks posed by CNNs. Capsule Networks is a leap forward in performance compared to CNN.
Introduction
Capsule networks are a type of neural network architecture that is recently gaining popularity. They were introduced in a 2017 paper by Sabour, Frosst, and Hinton and have been the subject of ongoing research and development since then. The main idea behind capsule networks is to replace traditional convolutional and pooling layers with a more biologically inspired architecture that better captures the spatial relationships between objects in an image.
Why did Capsule Networks Come into Existence?
The inspiration for capsule networks comes from the idea that the human visual system is composed of a hierarchy of "capsules" that process visual information at different levels of abstraction. Each capsule comprises a group of neurons sensitive to specific features of an image, such as the presence of an edge or a particular shape. These features are then combined and passed up the hierarchy to higher-level capsules, which extract more abstract concepts such as the identity of an object or the presence of a face.
Drawbacks of Pooling Layers
One of the main drawbacks of traditional convolutional neural networks (CNNs) is the use of pooling layers, which down-sample the input image and can lead to the loss of important information about the spatial relationships between objects in the image. Capsule networks aim to overcome this limitation by using a different down-sampling mechanism that preserves more spatial information. Here is the list of drawbacks of Pooling later.
- Loss of information:
The pooling operation reduces the feature map's spatial dimensions, resulting in information loss. - Over-aggregation:
Large pooling sizes can cause over-aggregation, where important details are lost. - Translation invariance:
Pooling layers can cause the model to be invariant to small translations in the input, which may only sometimes be desirable. - Parameter-free but has limitations:
, Unlike convolutional layers, pooling layers have no parameters to learn, limiting the ability to model complex interactions between features.
Consider a convolutional neural network (CNN) trained to recognize objects in images. The input images are of size (height, width, and three color channels, respectively). The first layer of the CNN applies convolutional filters to the input image, passing through a pooling layer to reduce the spatial resolution. If the pooling layer uses a kernel with a stride of 2, this will reduce the spatial resolution of the feature maps by a factor of 2, resulting in feature maps of size .
Now, imagine that the CNN is being used to recognize an object that is quite small in the input image and only takes up a tiny fraction of the image. Suppose the pooling layer has reduced the spatial resolution of the feature maps. In that case, the model may be unable to identify the small object because the details are too fine to be captured at a lower resolution.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
What are Capsule Networks?
Capsule networks are composed of a series of layers, called "capsule layers", comprising multiple "capsules". Each capsule is a group of neurons that is sensitive to a specific feature of the input image. The outputs of the capsules in a given layer are then passed on to the next layer, where they are combined and processed further.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
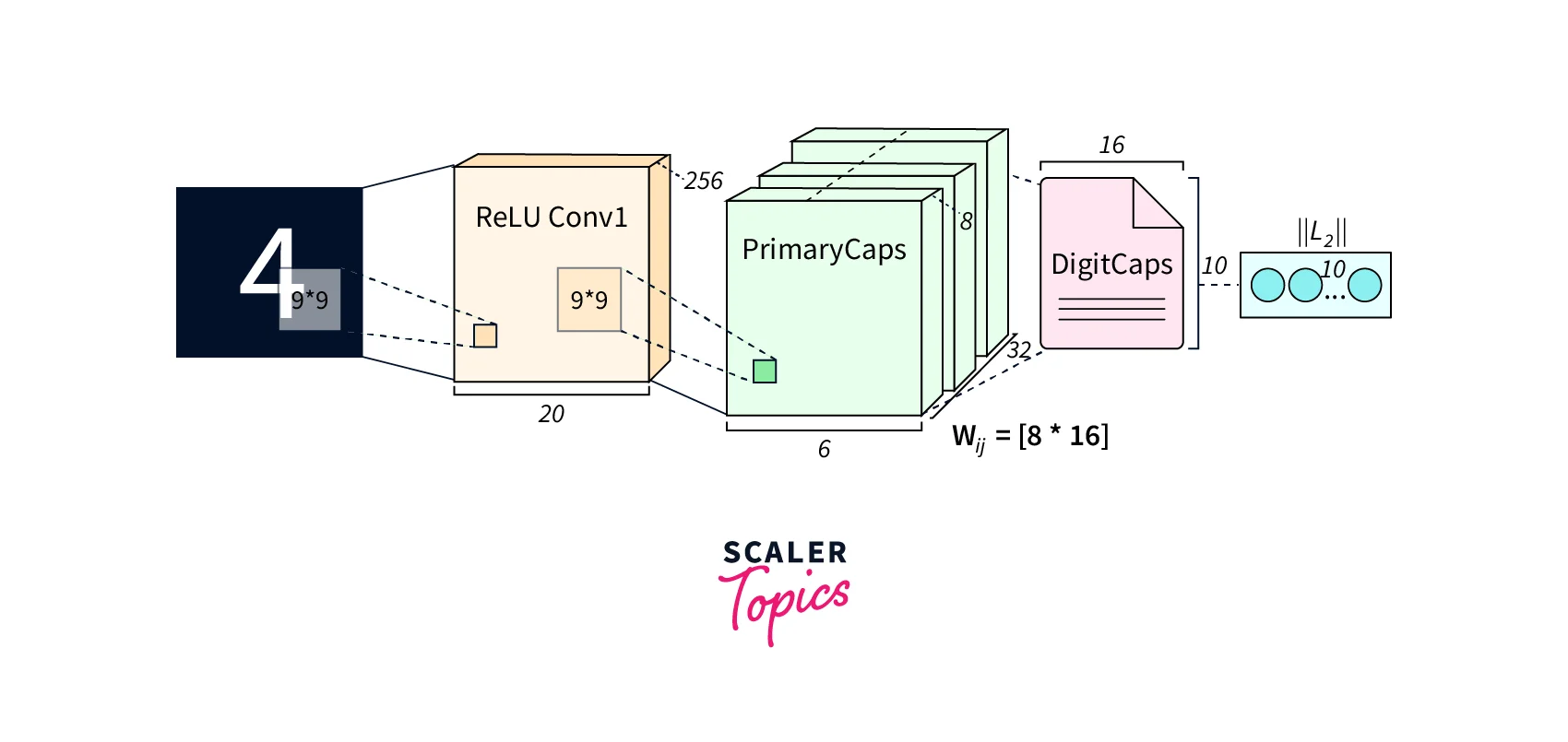
Architecture of the Capsule Network
Capsule networks are a neural network architecture that utilizes vector-based capsules instead of traditional scalar-based neurons in CNNs. The network structure is hierarchical, where the capsules are connected in layers, starting with the primary capsule layer representing basic features, then passed through routing-by-agreement layers that represent complex features and objects. The final layer is a fully connected classifier layer that produces a probability for each class object the network is trained to recognize. One of the main advantages of capsule networks is the preservation of spatial relationships and handling of viewpoint changes which allows for better recognition and understanding of objects and images.
Primary Capsules
The lowest layer of a capsule network is called the "primary capsule layer," which is responsible for processing the raw input image. Each capsule in the primary layer is sensitive to a specific feature of the input image, such as an edge or a particular shape.
-
Convolution:
The primary capsules in a capsule network are created by applying a series of convolutional filters to the input image. Each filter is responsible for detecting a specific feature in the input image, such as an edge or a particular shape. -
Reshape:
The outputs of the convolutional filters are then reshaped into a grid of "capsules", each of which corresponds to a specific location in the input image. -
Squash:
The outputs of the capsules are then "squashed" to ensure that they have a non-negative scalar value, which allows the network to learn more easily to differentiate between objects and backgrounds.
Higher-layer Capsules
The outputs of the primary capsules are then passed to higher-layer capsules, which combine the information from multiple primary capsules to extract more abstract concepts, such as the identity of an object or the presence of a face.
- Routing by agreement:
The outputs of the higher-layer capsules are determined by a process called "routing by agreement," which determines the strength of the connection between capsules in different layers.
Loss Calculation
To train a capsule network, a loss function is calculated based on the difference between the predicted output of the network and the true output.
- Margin loss:
The first loss function used in capsule networks is "margin loss", which ensures that the network can correctly identify objects in an image, even when they are partially obscured. - Reconstruction loss:
The second loss function in capsule networks is called "reconstruction loss". This loss function ensures the network can reconstruct an object from its lower-level features. This is accomplished by training the network to reconstruct an image from the output of the capsule layers.
Turn Learning into Career Growth
Building Capsule Networks in TensorFlow
We'll use TensorFlow to build our Capsule Network on the MNIST dataset.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Importing Libraries
Let's import the required libraries for our model. We'll be using TensorFlow to implement this model.
Initialize Parameters
Next, we'll declare the values of the hyperparameters for the model.
Let's define the number of layers we'll use in our capsule Network Architecture.
Import and Clean Dataset
We'll use the mnist Dataset available in keras for our model. mnist contains images of handwritten numbers from 0 to 9. We'll also normalize the data and implement some basic pre-processing to feed our model.
Next, we'll reshuffle the Dataset so that the model learns the data better.
Define Capsule Network
In the next step, we'll build our capsule Network model. it contains init, squash, call, predict_capsule_output and regenerate_image functions defined in the class. The following code will help to implement these functions.
We'll create an instance of our Capsule Network model with the defined parameters.
We'll define the loss function of our model for our model using the following code.
The next step is to implement the training function. This involves finding the gradients and using the optimizer to update the weights in each iteration.
Let's see the model that we've created.
Output:
Let's create a predict function to obtain the output of our model. This will iterate for 5 Epochs to train our model.
This is the driver code for training our Capsule Network
Output:
Let's evaluate our model using the following code.
Output:
Our capsule Network model has an extremely good Accuracy score of 0.9837
We can change the parameters and hyperparameters and see if there is any change to the performance of our model.
Pros and Cons Capsule Networks
Pros:
- Capsule networks are more robust to image distortions and translations than traditional CNNs
- They can maintain the spatial relationships between objects in an image
- They can handle partially obscured objects better
- They can be used for a variety of tasks, including object recognition and segmentation
- Capsule networks have fewer parameters than CNNs, which makes them more efficient and less prone to overfitting.
- Capsule networks can handle images with multiple instances of an object, while CNNs have problems.
Cons:
- Capsule networks are more complex and computationally expensive than traditional CNNs
- They are a relatively new architecture, and there is still ongoing research to improve their performance and computational efficiency.
Conclusion
- Capsule Networks overcome the problem of translational invariance caused by CNNs.
- Capsule Networks can capture better spatial relationships.
- Capsule Networks uses better downsampling methods that do not cause information loss seen in CNNs.
- Capsule networks perform much better than CNNs but are more computationally expensive.