Convolutional Neural Network

Overview
Artificial intelligence has seen tremendous growth in recent times. One of the fields that has seen immense growth is Computer Vision. One of the most important aspects accelerating Computer Vision's growth is Convolution Neural Network(CNN). This domain aims to teach the machine to identify and process visual data, like how humans perceive and understand visual data.
What is a Convolutional Neural Network?
Neural Networks are the core of the Deep Learning Domain. Neural Networks have an input layer, hidden layers, and an output layer. Each layer is connected with the other by weights and biases. CNN is a type of Deep Learning Algorithm. CNN is a special Neural Network that performs well for an image or pixel-based data. Convolutional Neural Networks are used in Image/Video Analysis & Classification tasks. The applications for Convolution Neural Networks range from face recognition to self-driving cars.

Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Why are CNNs So Useful?
CNNs can capture the spatial information much better than other models. This is a direct result of the Convolution technique. This Spatial understanding of data helps the model to identify features in images. Usually, the initial Convolution Layers identify the low-level features like vertical and horizontal lines.
The network can identify complex features like Faces and Eyes in the deeper layers. Feature extraction, like the Vertical feature in the first layer, is done by the network during the training phase.
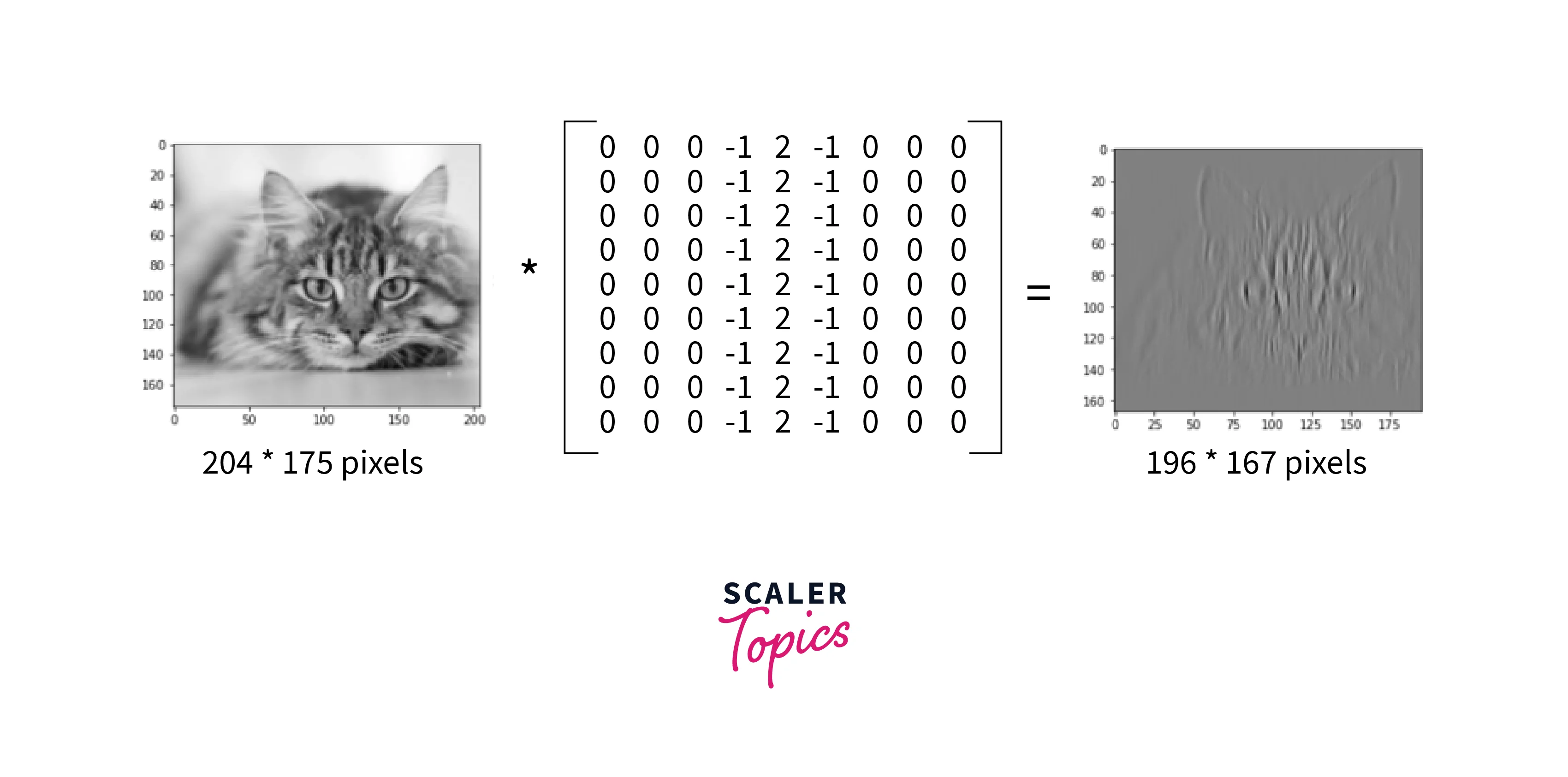
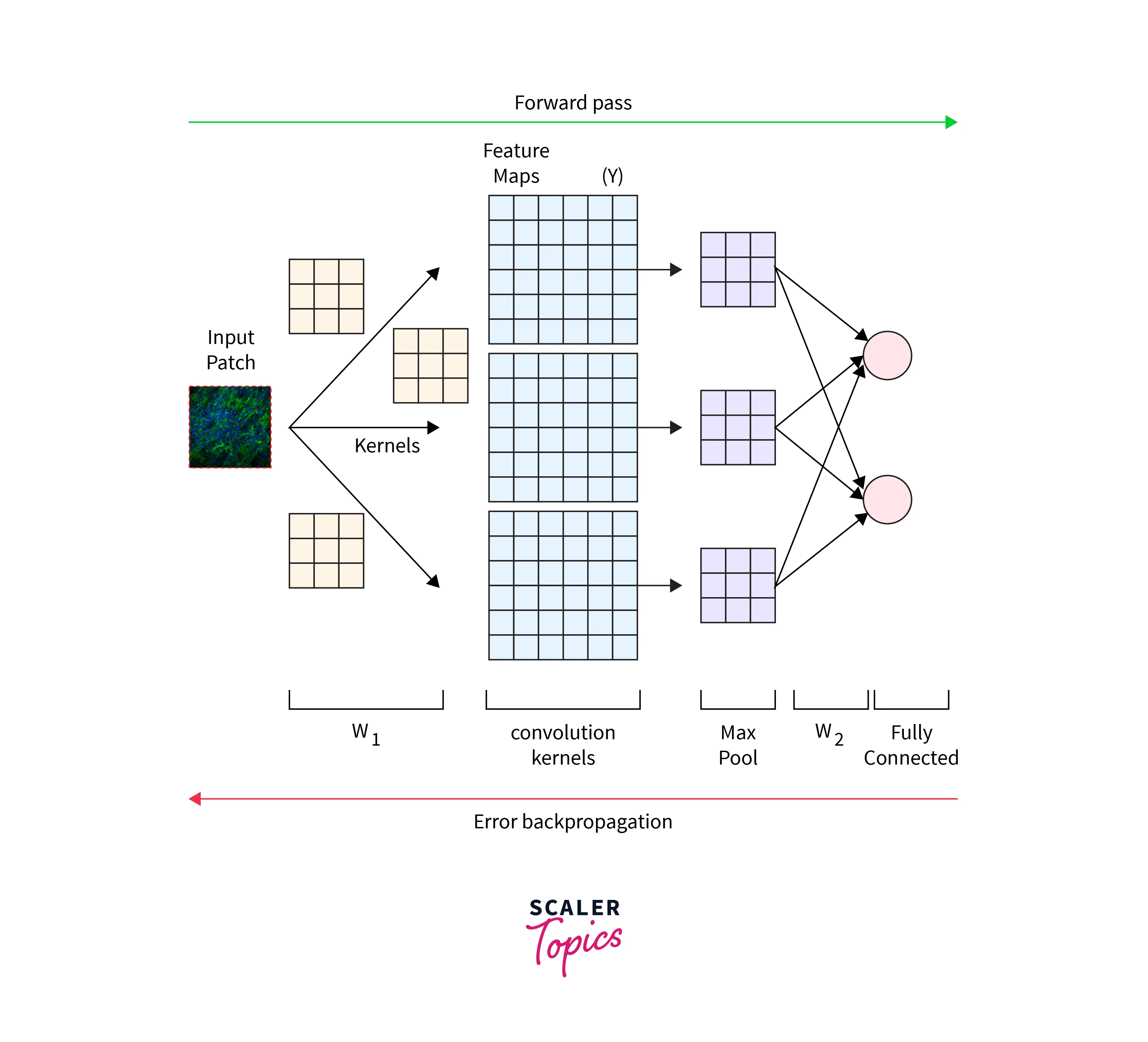
What Happens During the Convolution Operation?
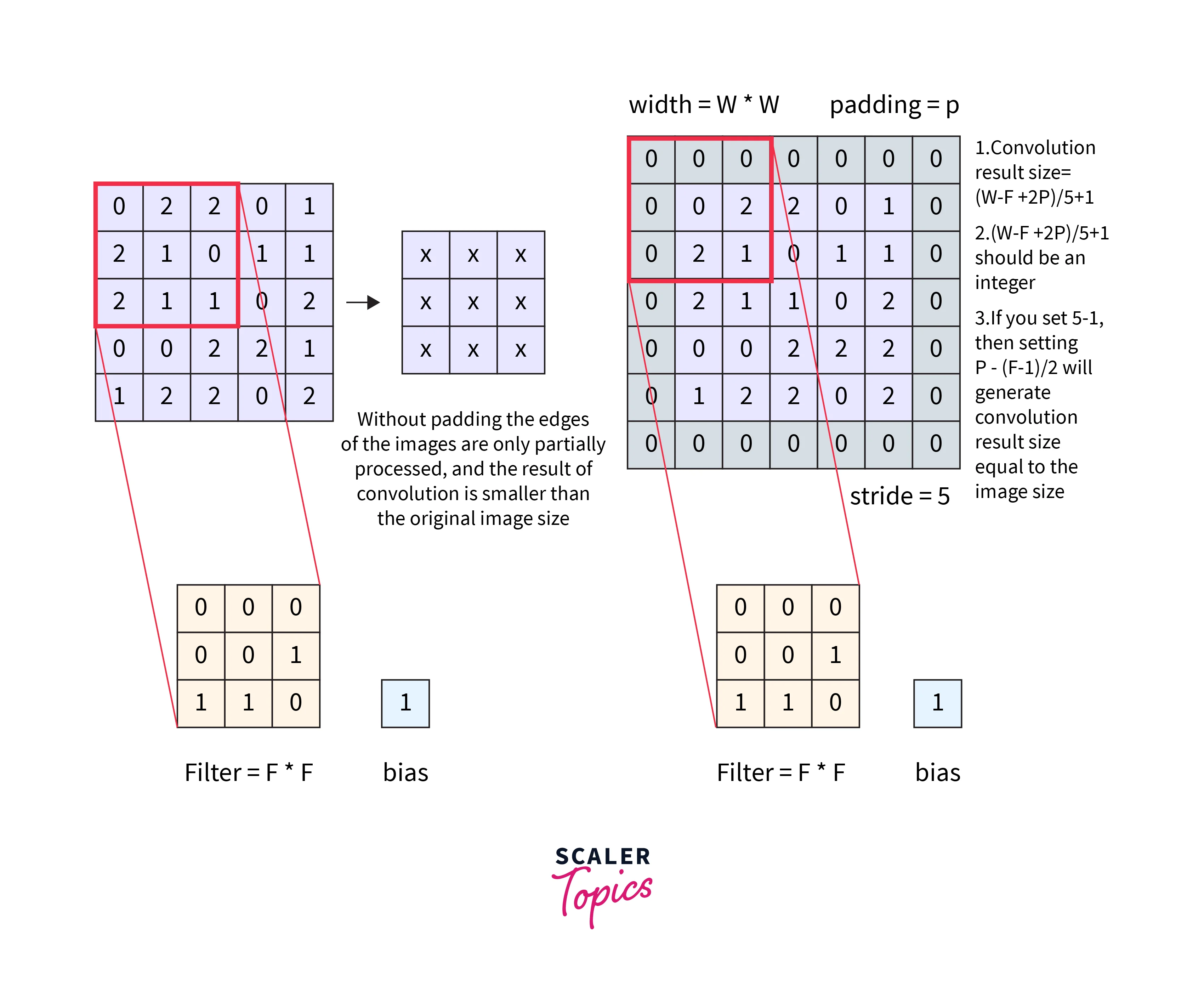
Convolution is a mathematical function which takes two functions(f and g) and produces a third function as output. In image processing, Convolution is indispensable. In place of functions f and g, we use an input image matrix and a special matrix called a kernel(or filter).
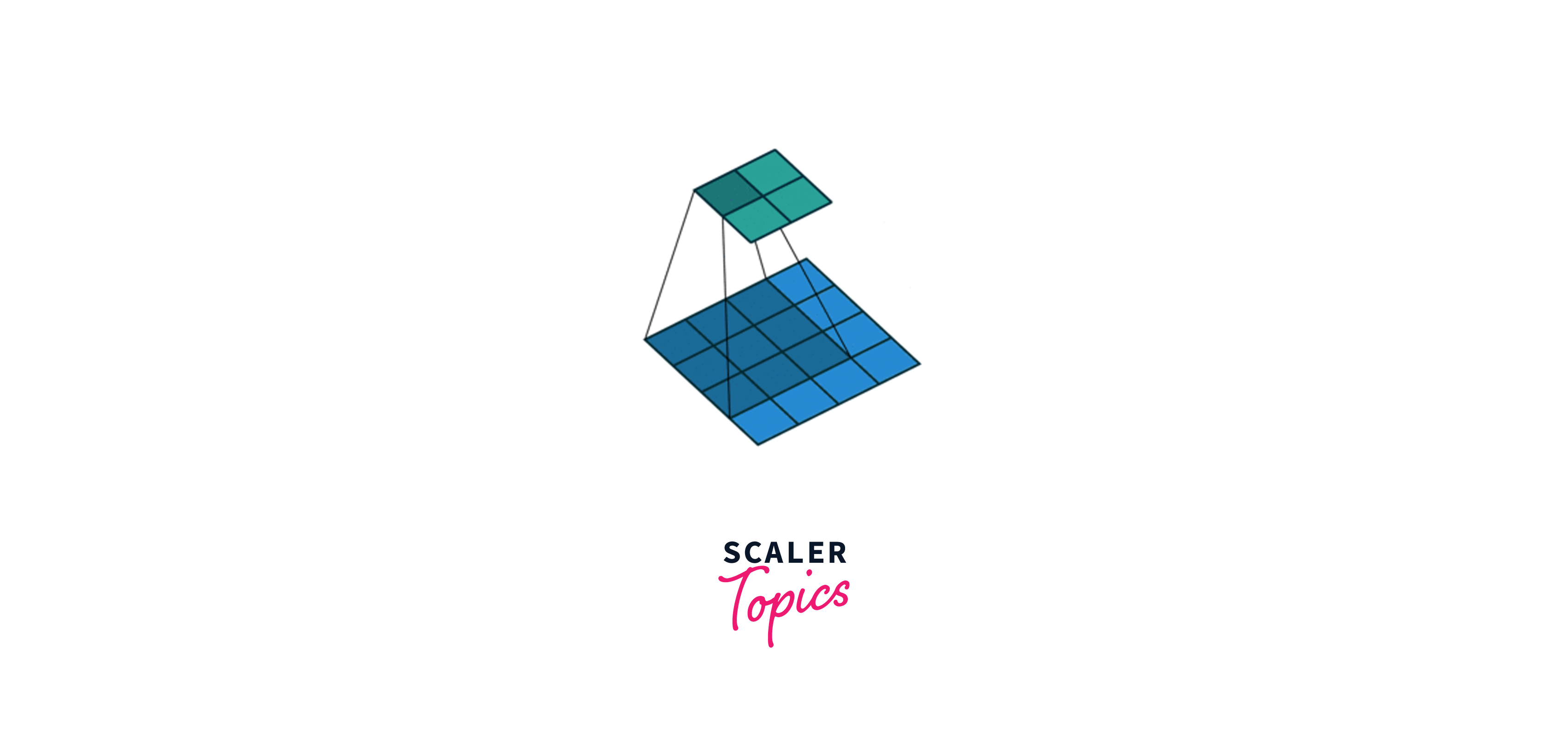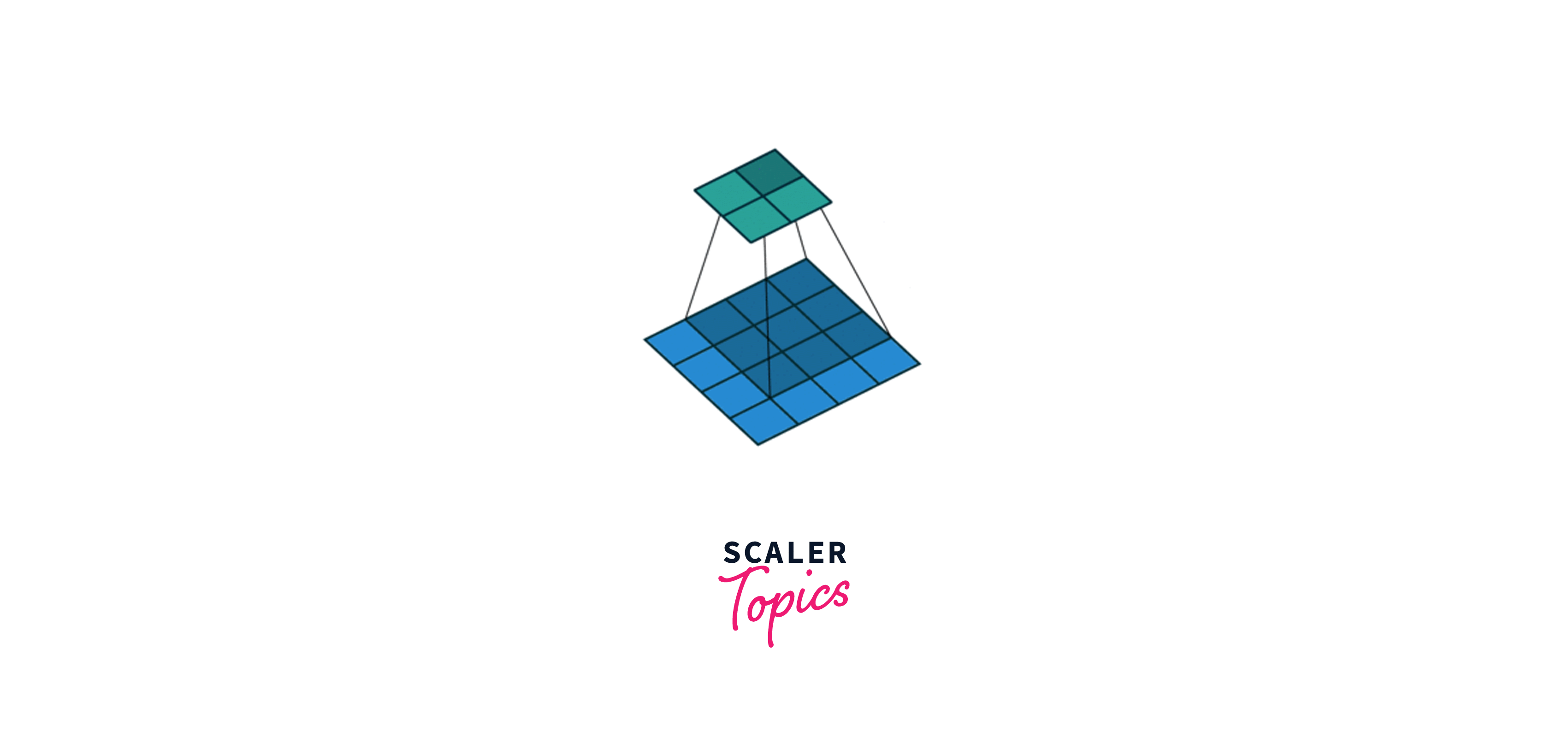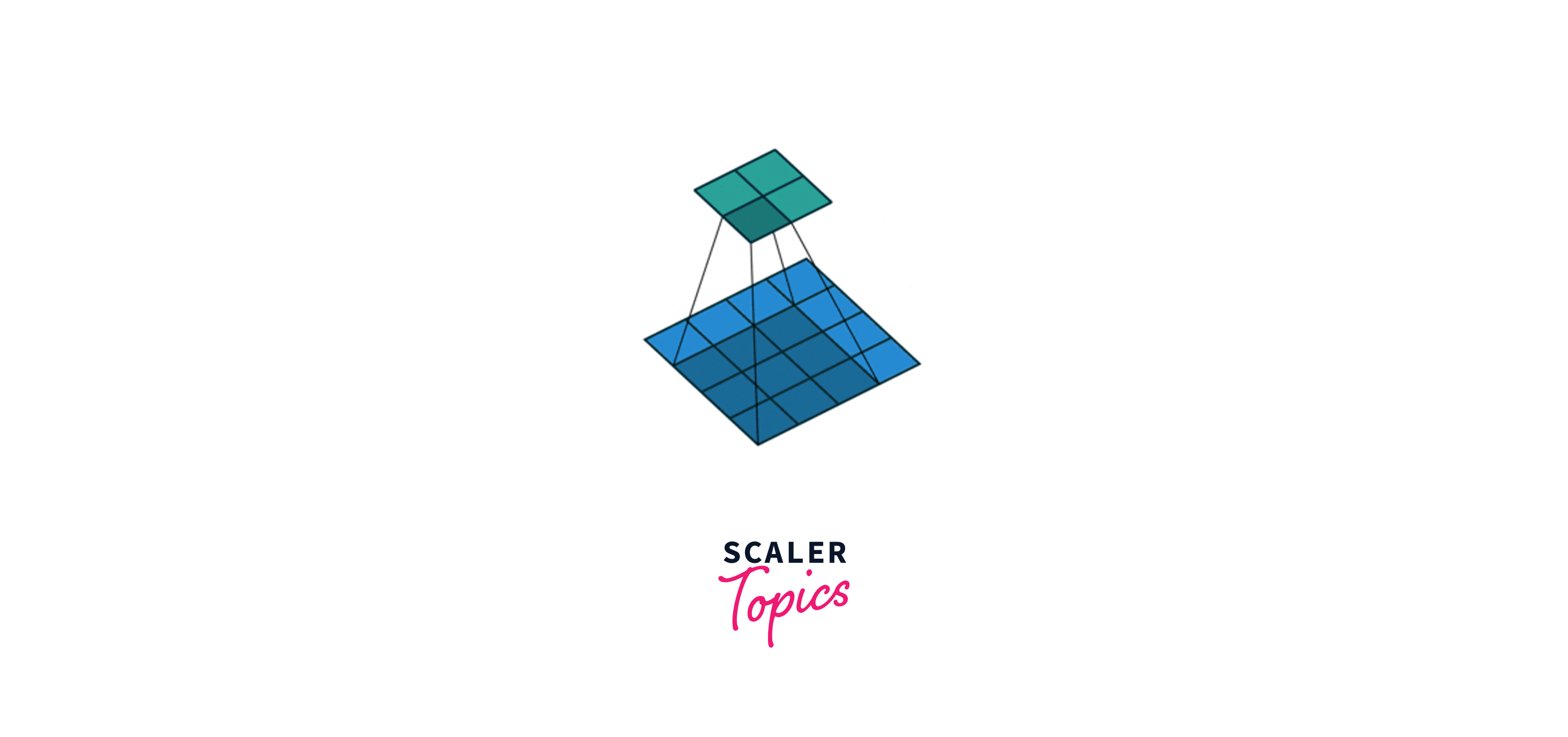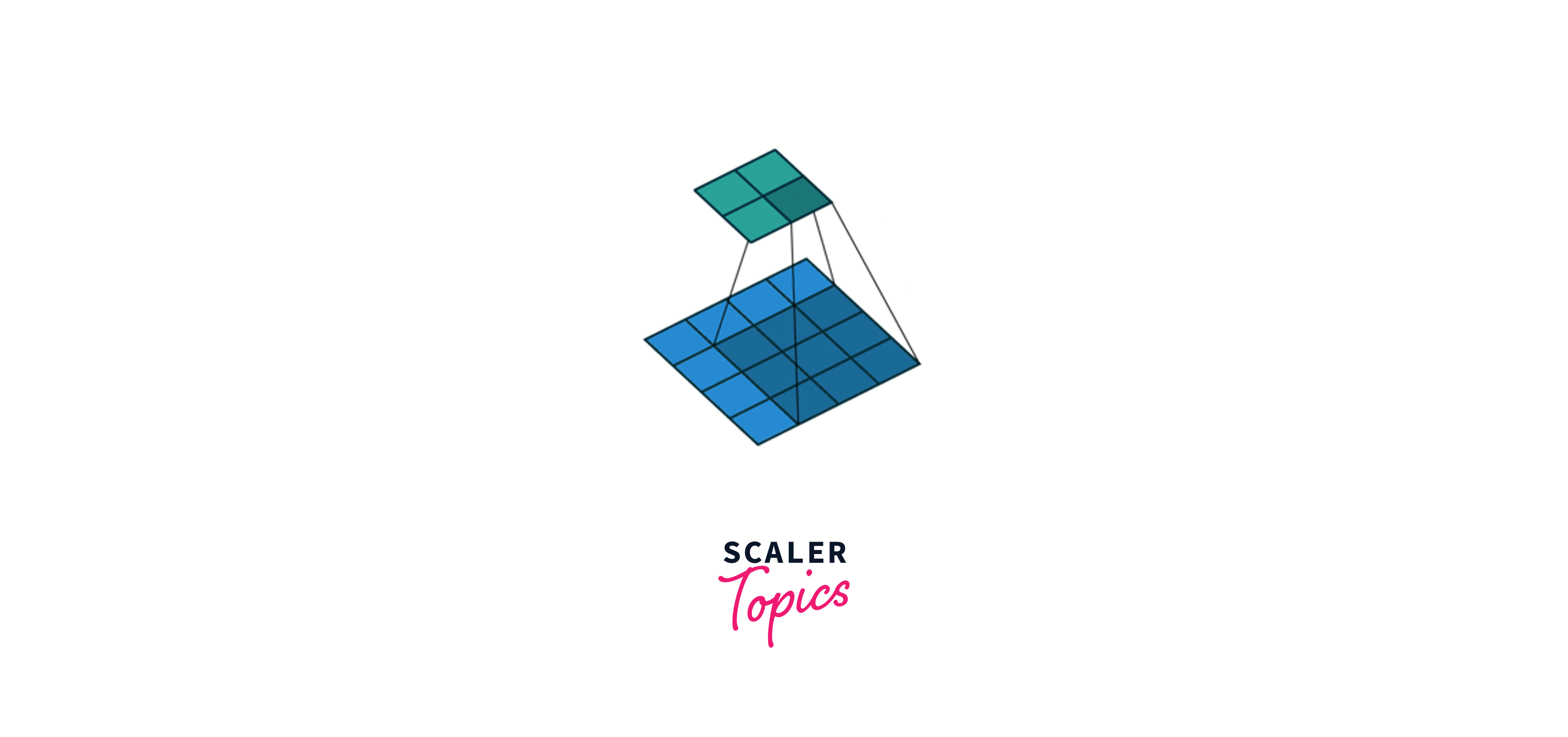
Let’s consider an input image where a value represents each pixel, i.e., a dimension 4x4 matrix. In the above gif, blue represents the input matrix, and cyan represents the output matrix. We use a Kernel of size 3x3(represented by the moving box) and do element-wise multiplication on the input matrix. We start from the top left and stride right while doing element-wise multiplication at each position. Then we go to the next line and traverse the same way. Ultimately, we are left with a 2x2 output matrix. This operation is called Convolution.
Convolutional Neural Network Design
CNN is a deep learning algorithm that takes images or videos as input and is passed through several layers of the Network where different processing techniques are applied in each layer. There are mainly three types of layers:
- Convolution Layer
- Pooling Layer
- Fully Connected Layer
Turn Learning into Career Growth
Building Blocks of CNN Architecture
Convolution layer
The Convolution layer is the main building block of CNN. The CNN layer is followed by a Non-linear activation function. Non-linear activation functions can be used(Tanh, Sigmoid, ReLU). But ReLU is usually used in CNN models as they deliver the best results without the vanishing/exploding gradient problem.
Pooling layer
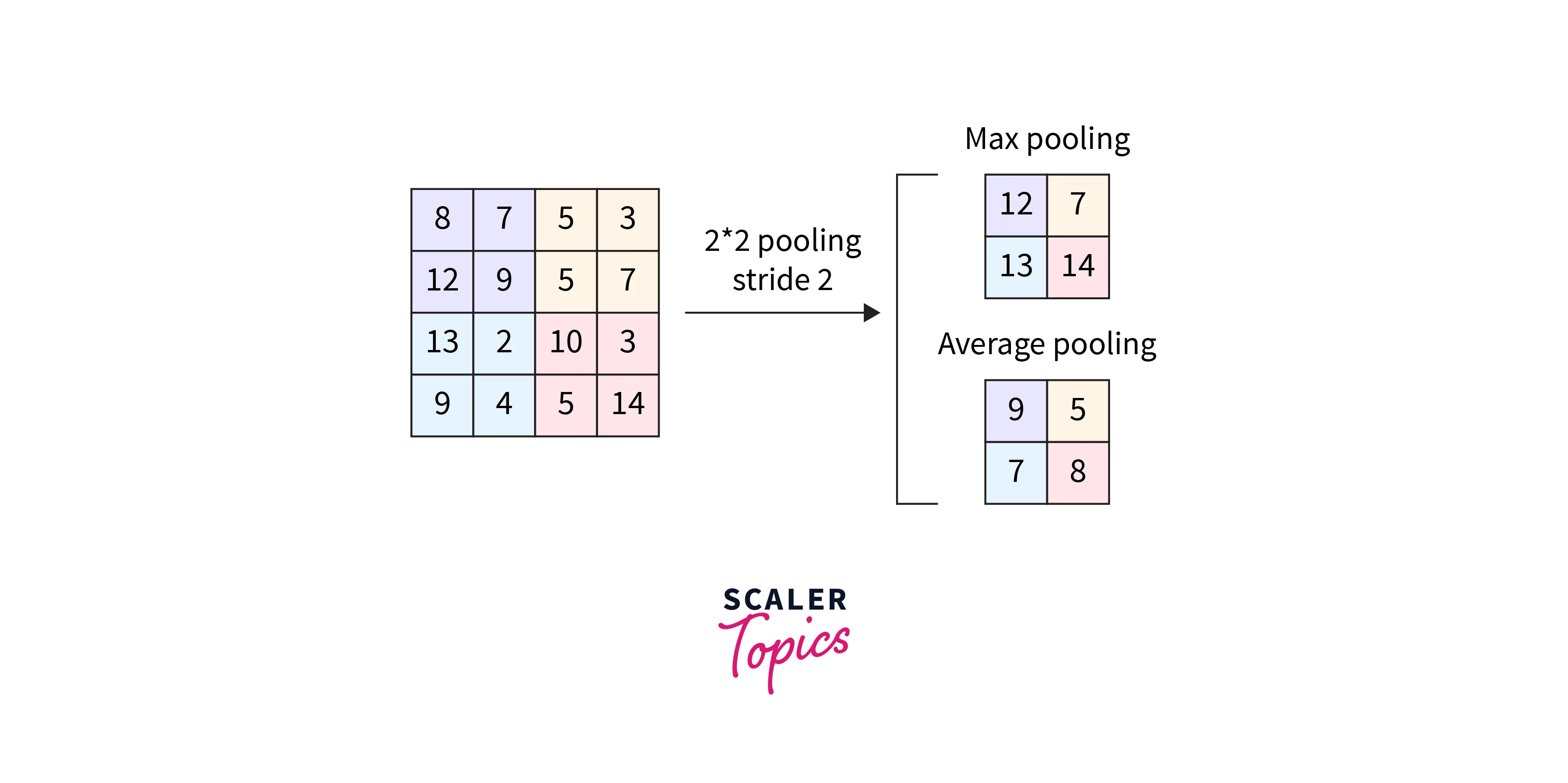
The Pooling layer is used to reduce the dimension of the image. It is also known as Downsampling. The pooling Layer also uses a kernel and moves across the image but performs the pooling operation. Pooling operation reduces the data within the kernel into a single pixel data. There are two types of pooling operation.
- Max Pooling – This operation outputs the maximum value contained in the kernel. In addition, this pooling performs as a “Noise Suppressant”.
- Average Pooling – The average value of the pixels contained in the kernel is returned as the output.
Fully connected layer
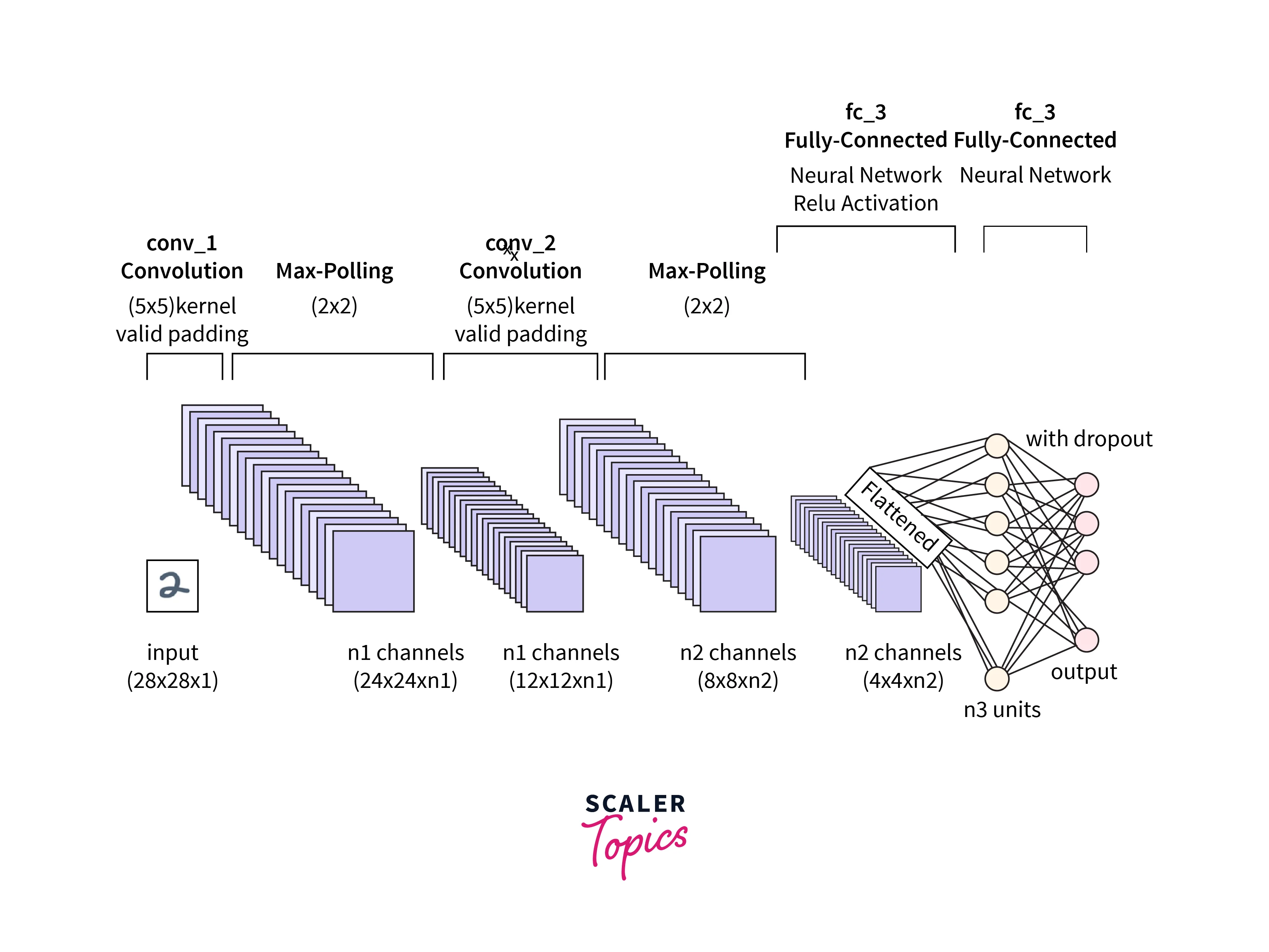
A Fully connected layer(FC layer) is the last stage of the CNN. The input FC layer flattens all the images into an array of values. As the name suggests, FC Layer has all the Neurons connected with all other neurons in the next layer. The next Fully connected Layer applies weights to the flattened values to obtain the label predictions.
Last Layer Activation Function
The last Fully Connected layer uses a SoftMax Activation function at the end to output values in the range [0,1] to get the probability of the classification values. This layer is specific to the task the CNN is used for. For example, if we were implementing an image classification task, we would use a Softmax activation function to get a probability output from the model. If the classification is binary, we will use a Sigmoid Activation Function.
Convolutional Neural Networks vs. Fully-Connected Feedforward Neural Networks
If we feed an image as input to a conventional Feed Forward network, we would flatten the image and send individual pixels as input. However, when we do this, it is very hard for the Network to establish the relationship between a pixel and all its neighboring pixels. So the Convolution technique helps capture all the neighboring data and form a relationship between them. This makes CNN efficient for identifying patterns in Image data.
CNN also reduces the complexity by reducing the number of parameters to be trained compared to a Feed-forward network.
| Feedforward neural network | CNN | |
|---|---|---|
| Architecture | Fully connected layers | Convolutional and pooling layers |
| Weight sharing | No | Yes |
| Local connectivity | No | Yes |
| Activation functions | Any | Often use ReLU or other functions well-suited for image data |
| Suitable for tasks involving | Any type of data | 2D data, such as images |
Training a Convolutional Neural Network (for Image Classification)
The training process of CNN is the same as any other Conventional Feed Forward Network. It uses the Backpropagation algorithm to train.
The input is images represented as matrices with pixel values, and the class to which they belong is used as an output to train the model. Initially, the weights and biases are randomly initialized.
We use a cross-entropy loss function to determine the loss function. For example, we would use a Binary-cross-entropy loss function if it is a Binary image classification task.
We will update the weights based on the loss value using the backpropagation method. Repeating the training multiple times will lead the model to be trained to classify the images into different classes.
Applications of Convolutional Neural Networks
CNN is used in various applications ranging from Medical diagnosis to self-driving cars. Some of its applications are:
- Image classification: CNNs can be trained to classify images into different categories, such as animals, objects, and scenes. This is done by training the CNN on a large dataset of labeled images and using the learned features to predict new, unseen images.
- Object detection: CNNs can detect objects within an image or video, such as pedestrians, cars, or buildings. This is achieved by training the CNN to recognize the specific features of the objects of interest and locate them within the image or video.
- Image segmentation: CNNs can identify and segment different objects or regions within an image. This allows for the isolation and analysis of specific parts of an image, such as the foreground and background.

- Image generation: CNNs can generate new images based on a set of input images. This is done by training the CNN on a dataset of images and then using it to generate new, synthetic images with similar characteristics to the training data.
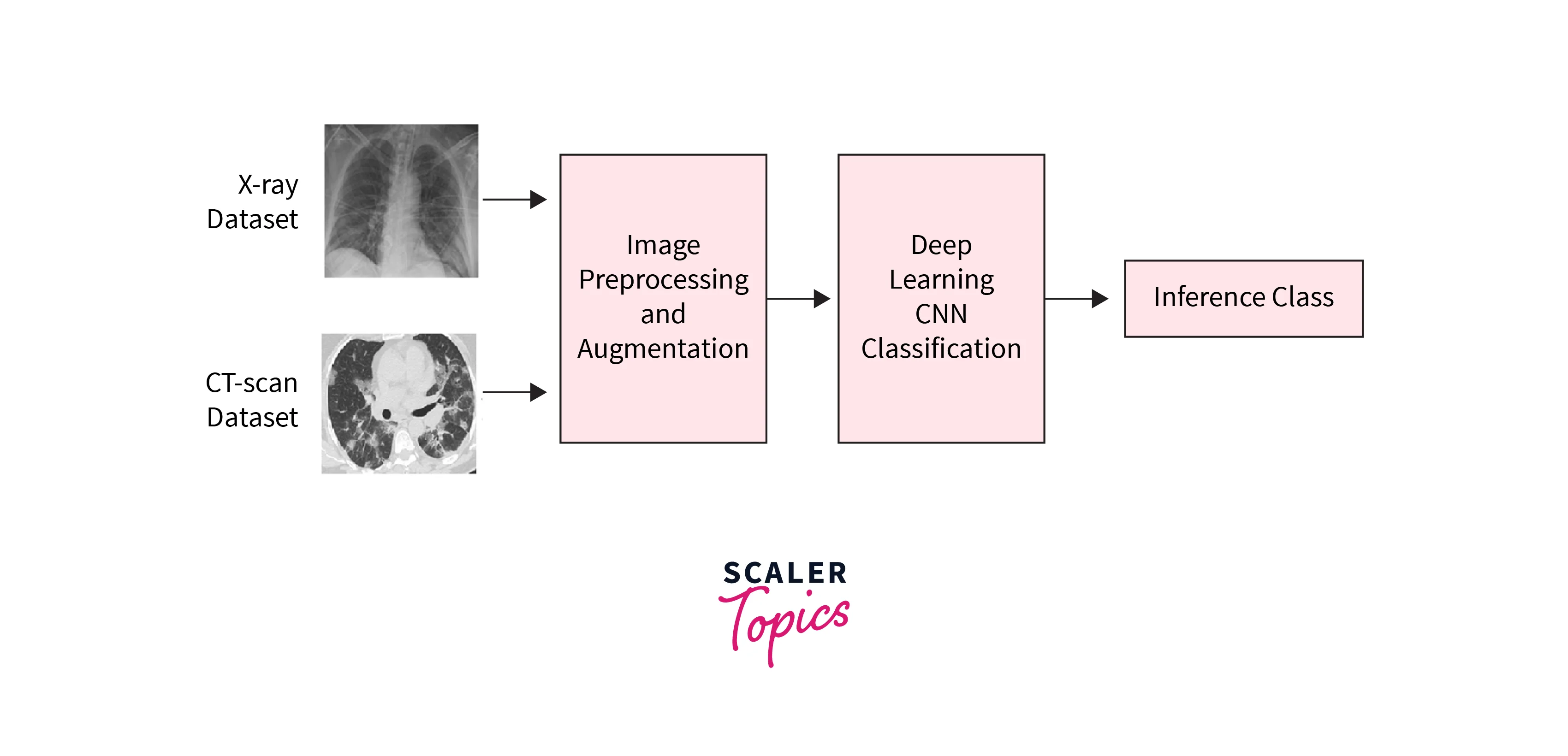
- Medical image analysis: CNNs can be used to analyze medical images such as CT and MRI scans, aiding in diagnosing and treating diseases. This is done by training the CNN on a large dataset of labeled medical images and using the learned features to identify abnormalities or abnormalities in new, unseen images.
Conclusion
- CNN is a Neural Network in Deep Learning type primarily used in Computer Vision problems.
- CNN uses the Convolution operation at its core in the network.
- It has three main layers Convolution, Pooling, and Fully Connected.
- The main hyperparameters are Padding, Stride, and number of Filters.
- CNN performs much better than Feed Forward Network by a huge margin for Images and Videos.