Building a Neural Network from Scratch
Overview
Neural Networks are used extensively in the field of Deep Learning. A Neural Network model tries to learn whatever data it is presented with. The training of Neural networks has various steps which are iterated multiple times. The goal of the model is to fit the data better with each iteration. Usually, Neural Networks are built with various Deep Learning frameworks like Keras or TensorFlow. We'll see how to build a Neural Network using Numpy and Python to understand how a Neural Network works on a fundamental level.
Introduction
Neural networks are machine learning algorithms inspired by the structure and function of the human brain. They are composed of layers of interconnected "neurons", that process and transmit information.
Neural networks are commonly used for image classification, language translation, and speech recognition tasks. They are particularly powerful for handling complex, nonlinear relationships in data.
Training a neural network involves adjusting the weights and biases of the connections between neurons to minimize a loss function that measures the difference between the predicted output of the network and the true output.
How Does a Neural Network Work?
A neuron is a fundamental building block of a neural network. It is a simple processing unit that receives input, performs computations on the input, and produces an output.
Here is a simple example of a neuron:
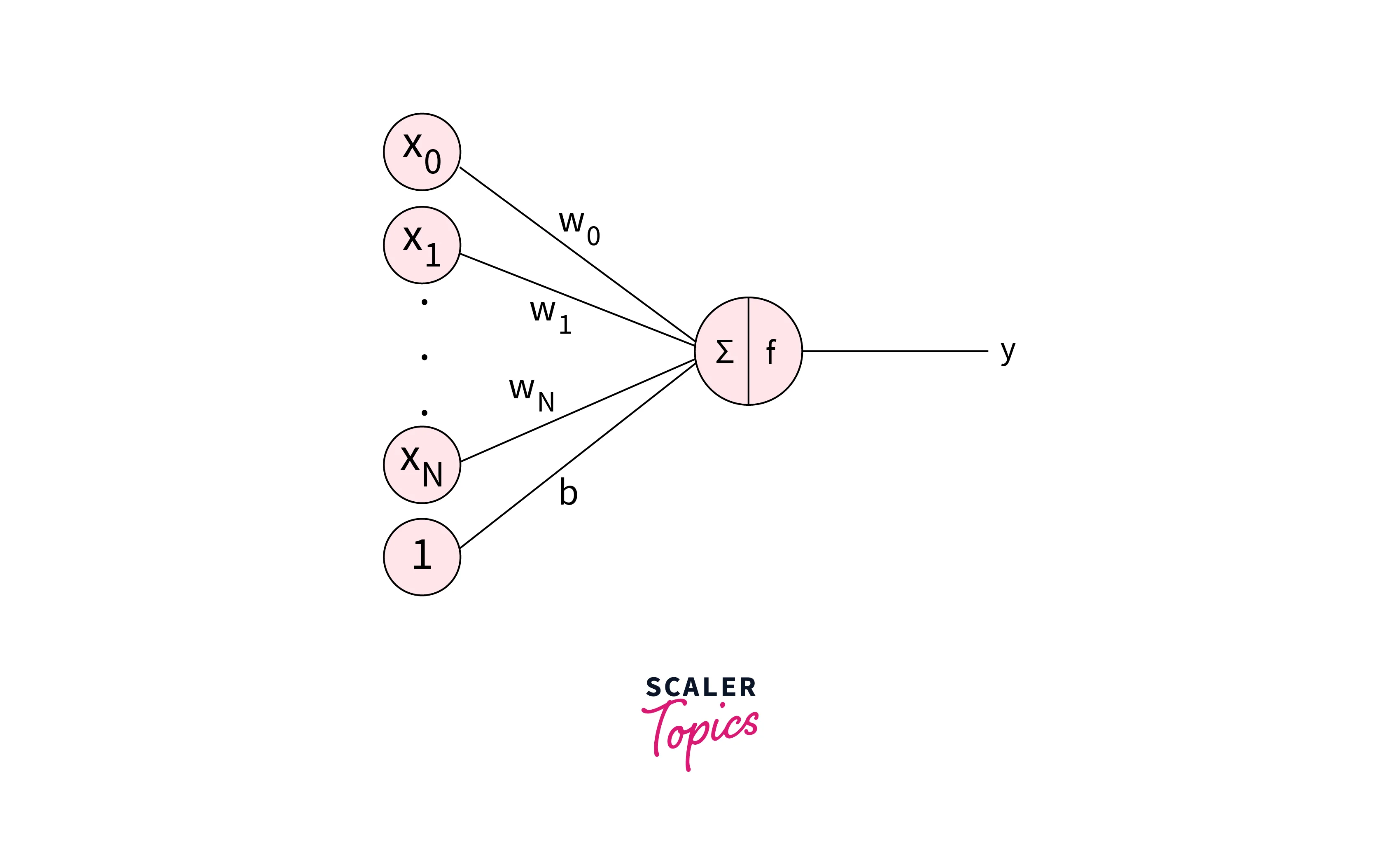
In this example, the neuron receives input , , and through its connections and has weights , , and associated with those connections. The weighted sum of the inputs is calculated as follows:
The weighted sum z is then passed through an activation function f, which produces the output y of the neuron:
The activation function f is a mathematical function that determines the neuron's output based on its input. Several types of activation functions can be used, including the sigmoid function, the tanh function, and the ReLU function.
The output y of the neuron is then passed on to other neurons in the network through its connections.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Visualizing a Neural Network
Building Blocks
A neural network comprises several building blocks that work together to process and transmit information. Here are some of the key building blocks of a neural network:
- Neurons:
Neurons are the fundamental processing units of a neural network. They receive input, perform computations on the input, and produce an output. Neurons are organized into layers and are connected through weighted connections. - Layers:
Layers are collections of neurons that work together to process the input data and produce the network output. In a neural network with one hidden layer, there are three layers: an input layer, a hidden layer, and an output layer. In a neural network with multiple hidden layers, additional layers exist between the input and output layers. - Weights:
Weights are the values that determine the strength of the connections between neurons. They are adjusted during training to optimize the performance of the neural network. - Bias:
A bias is a constant value added to the weighted sum of the inputs received by a neuron. It is used to shift the neuron's activation function, allowing the network to learn more complex patterns in the data. - Activation function:
The activation function of a neuron is a mathematical function that determines the neuron's output based on its input. It introduces nonlinearity into the network, allowing it to learn more complex patterns in the data. Some standard activation functions include the sigmoid function, the tanh function, and the ReLU function.
Coding a Neuron
A simple neuron only consists of the weights and biases it's connected to. We can create a Neuron class with weights and bias initialized.
Forward Propagation
In Forward Propagation, the input value passes through the weights W1 and the activation Function to the hidden layer. The Hidden Layer values are passed through weights W2 and another activation function to obtain the output values.
Turn Learning into Career Growth
Back Propagation
In back Propagation, we calculate the error value and use the error value to obtain the derivative values. In that order, we calculate the gradient of W2, the Hidden layer, and W1.
Backpropagation has two steps,
- Calculate the loss,
- Calculate the gradients
We calculate the loss in the error variable by finding the difference between the predicted value and the True value.
Next, we use the error value to find the gradients of W2, H, and W1.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Initialize the Weight Values
The weights are initialized to the required neuron number at the input, hidden layer, and output. We initialize with random values.
Updating Weights
The weights are updated after each iteration using the learning rate value and the calculated derivative of the weights.
Understanding the MNIST Dataset

The MNIST (Modified National Institute of Standards and Technology) dataset is widely used for training and testing machine learning models, particularly for image classification tasks. It consists of a training set of 60,000 grayscale images of size 28x28 pixels and a test set of 10,000 images.
Each image in the MNIST dataset is a handwritten digit from 0 to 9, and the task is to classify the images based on the digit they depict. The images are normalized and centered, and there is little variance in the size or orientation of the digits.
How to Prepare the Data?
The MNIST dataset is loaded with the train and test set already split. MNIST consists of 2-dimensional images. Since our model is linear, we will flatten the 2d image to obtain a 1-dimensional array of all the pixel values. The data is then reshaped to fit our model. The photos are , so we will flatten the images to 784 values. We convert the data to float. The data is then normalized so that all the values lie between 0 and 1.
The y values are categorically encoded to have 10 unique values.
How to Train Your Neural Network?
Let's look at how to build a Neural Network Model. The whole model can be defined using the class Model with the neuron initialized in the _init_ function.
After we create the model, we implement the data pre-processing steps, as seen above. Pre-processing is followed by the training phase, where we initialize the model and use the optimized function to train the model. The number of Epochs, learning rate, and batch size are defined.
We Evaluate the model using the Forward propagation to obtain inferences.
Accuracy is a commonly used metric to evaluate the performance of a machine learning model. It is the proportion of correct predictions made by the model out of all predictions. It is a widely used metric for classification problems.
Accuracy = (Number of correct predictions) / (Total number of predictions)
Conclusion
- It is important to carefully design the architecture of the network, including the number of layers and the number of neurons in each layer, to ensure that it is well-suited to the task at hand.
- Training a Neural Network has various steps, such as Forward Propagation, Backward Propagation, weight initialization, and updation.
- Training a neural network from scratch involves adjusting the weights and biases of the connections between neurons to minimize a loss function.
- The Data must be pre-processed to fit the model we are working with. Pre-processing also helps with making the model fit the data better.
- We've learned how to build a Neural Network from Scratch and all the associated steps.