What is LSTM? - Introduction to Long Short-Term Memory
LSTM, an advanced form of Recurrent Neural Network, is crucial in Deep Learning for processing time series and sequential data. Designed by Hochreiter and Schmidhuber, LSTM effectively addresses RNN's limitations, particularly the vanishing gradient problem, making it superior for remembering long-term dependencies. This neural network integrates complex algorithms and gated cells, allowing it to retain and manipulate memory effectively, which is pivotal for applications like video processing and reading comprehension.
Need of LSTM
LSTM was introduced to tackle the problems and challenges in Recurrent Neural Networks. It touches on the topic of RNN. RNN is a type of Neural Network that stores the previous output to help improve its future predictions. Vanilla RNN has a “short-term” memory. The input at the beginning of the sequence doesn’t affect the output of the Network after a while, maybe 3 or 4 inputs. This is called a long-term dependency issue.
Example:
Let’s take this sentence.
The Sun rises in the ______.
An RNN could easily return the correct output that the sun rises in the East as all the necessary information is nearby.
Let’s take another example.
I was born in Japan, ……… and I speak fluent ______.
In this sentence, the RNN would be unable to return the correct output as it requires remembering the word Japan for a long duration. Since RNN only has a “Short-term” memory, it doesn’t work well. LSTM solves this problem by enabling the Network to remember Long-term dependencies.
The other RNN problems are the Vanishing Gradient and Exploding Gradient. It arises during the Backpropagation of the Neural Network. For example, suppose the gradient of each layer is contained between 0 and 1. As the value gets multiplied in each layer, it gets smaller and smaller, ultimately, a value very close to 0. This is the Vanishing gradient problem. The converse, when the values are greater than 1, exploding gradient problem occurs, where the value gets really big, disrupting the training of the Network. Again, these problems are tackled in LSTMs.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
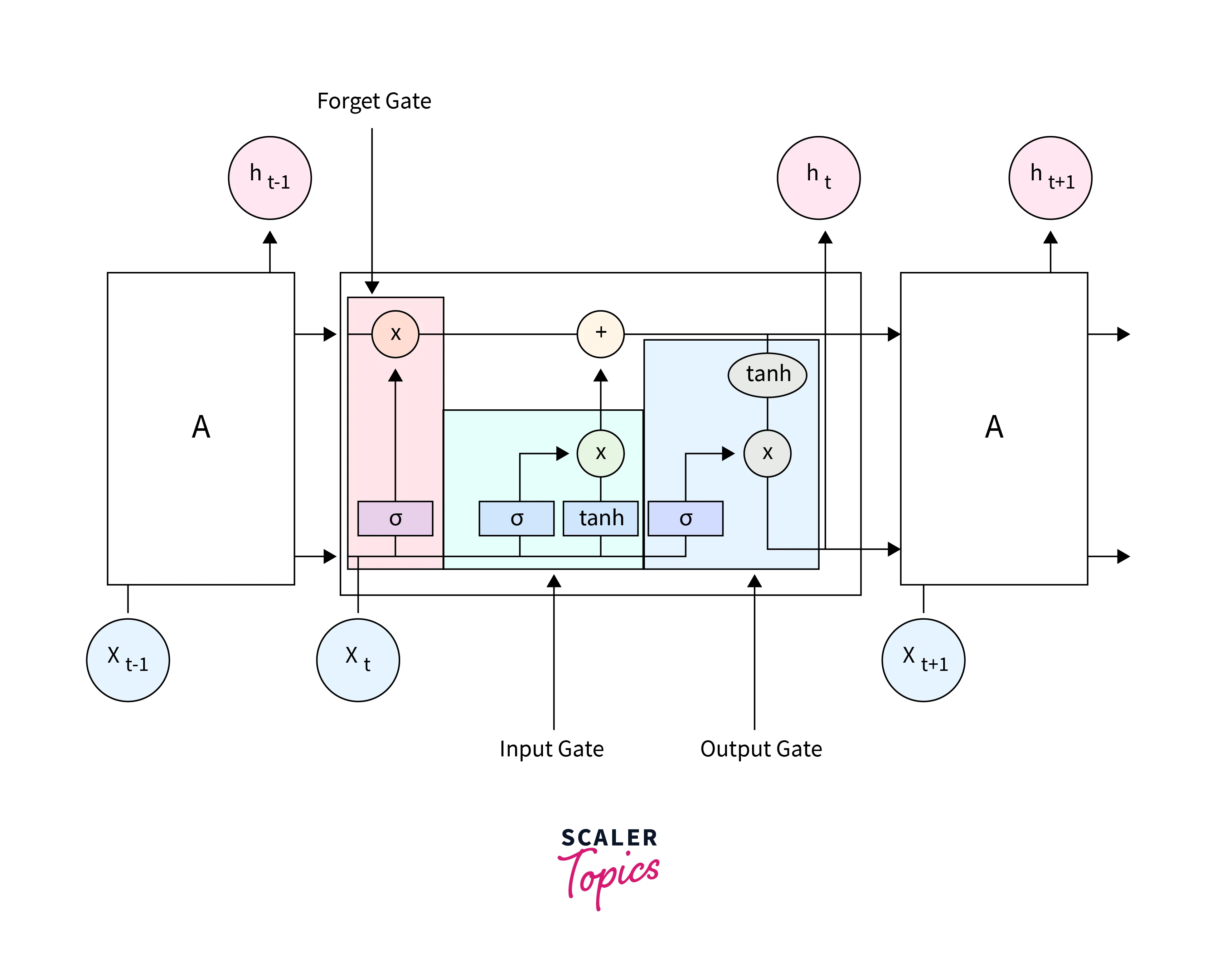
Structure of LSTM
LSTM is a cell that consists of 3 gates. A forget gate, input gate, and output gate. The gates decide which information is important and which information can be forgotten. The cell has two states Cell State and Hidden State. They are continuously updated and carry the information from the previous to the current time steps. The cell state is the “long-term” memory, while the hidden state is the “short-term” memory. Now let’s look at each gate in detail.
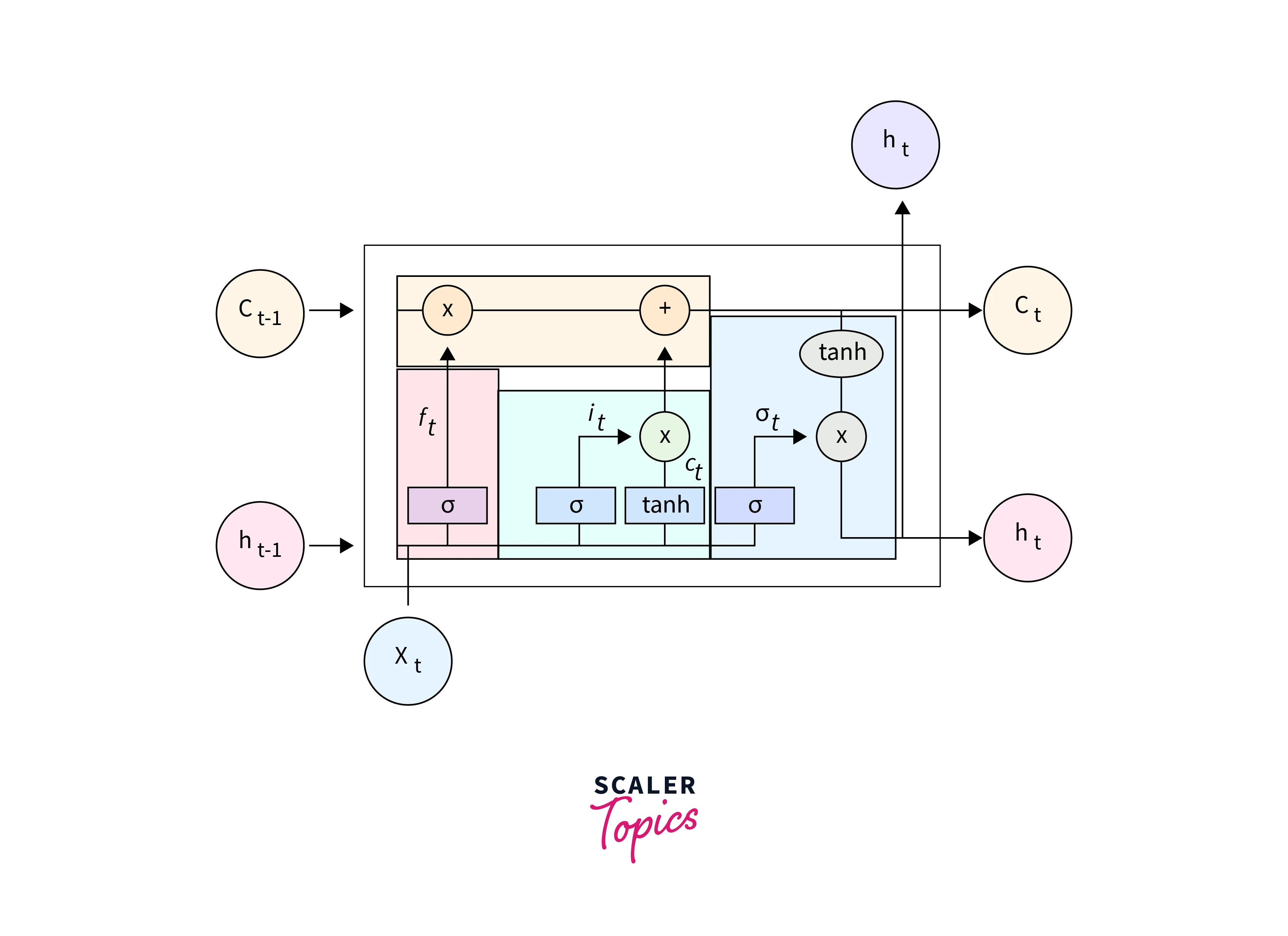
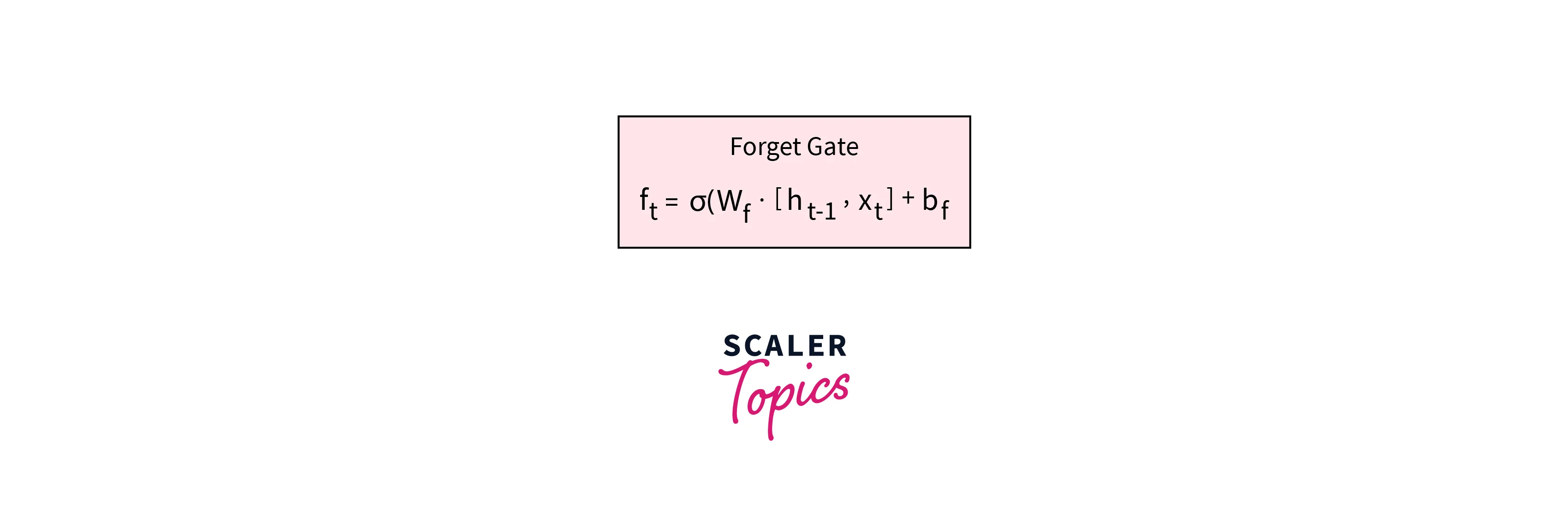
Forget Gate:
Forget gate is responsible for deciding what information should be removed from the cell state. It takes in the hidden state of the previous time-step and the current input and passes it to a Sigma Activation Function, which outputs a value between 0 and 1, where 0 means forget and 1 means keep.
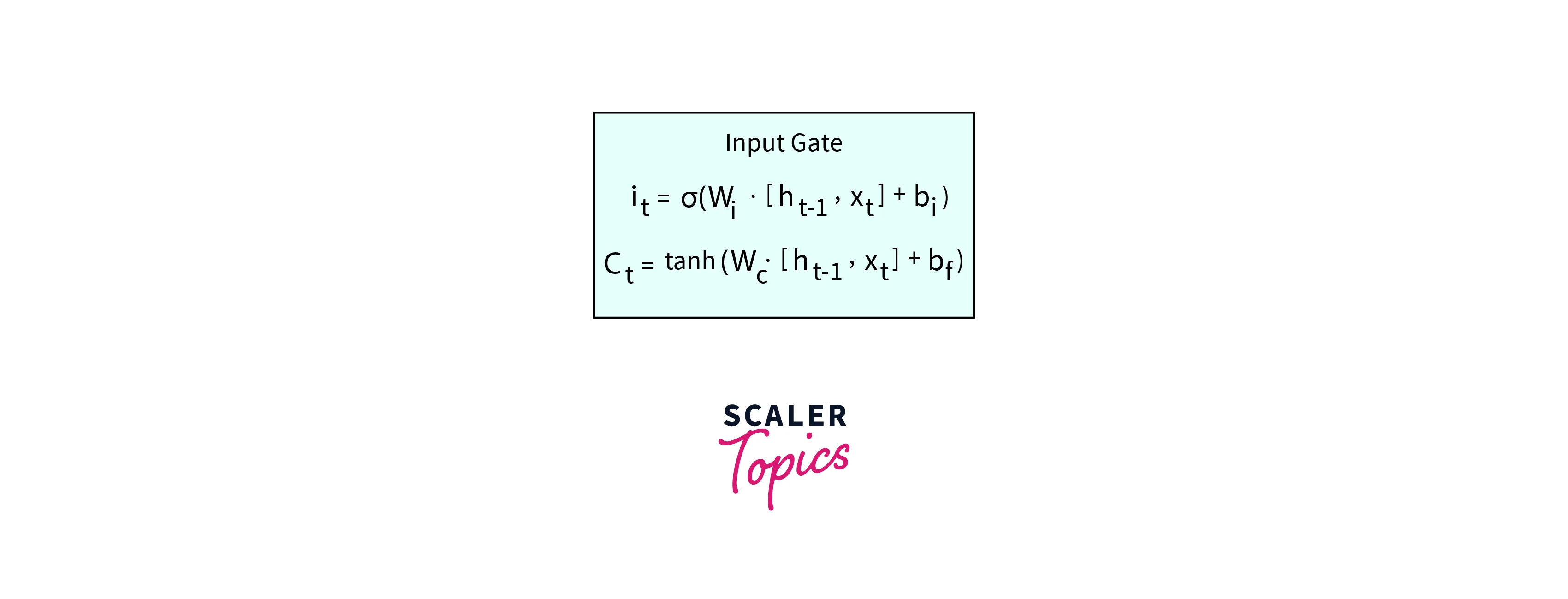
Input Gate:
The Input Gate considers the current input and the hidden state of the previous time step. The input gate is used to update the cell state value. It has two parts. The first part contains the Sigma activation function. Its purpose is to decide what percent of the information is required. The second part passes the two values to a Tanh activation function. It aims to map the data between -1 and 1. To obtain the relevant information required from the output of Tanh, we multiply it by the output of the Sigma function. This is the output of the Input gate, which updates the cell state.
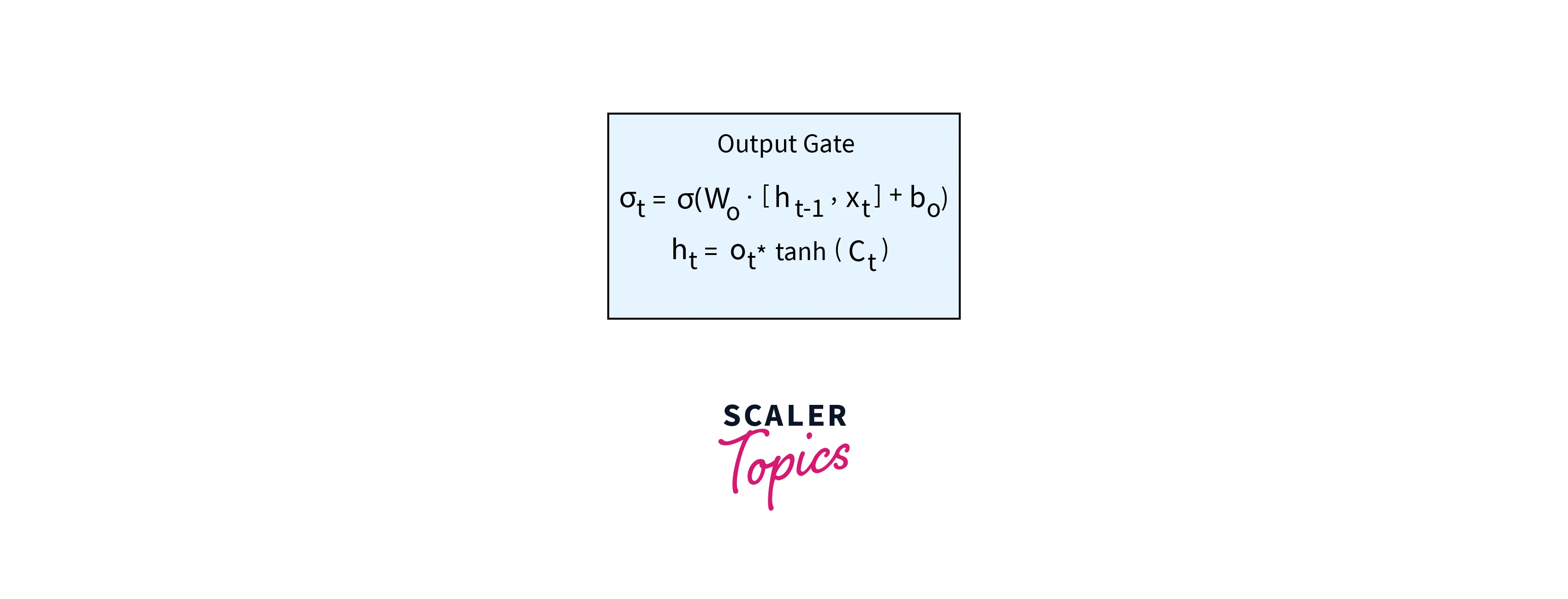
Output Gate:
The output gate returns the hidden state for the next time stamp. The output gate has two parts. The first part is a Sigma function, which serves the same purpose as the other two gates, to decide the percent of the relevant information required. Next, the newly updated cell state is passed through a Tanh function and multiplied by the output from the sigma function. This is now the new hidden state.
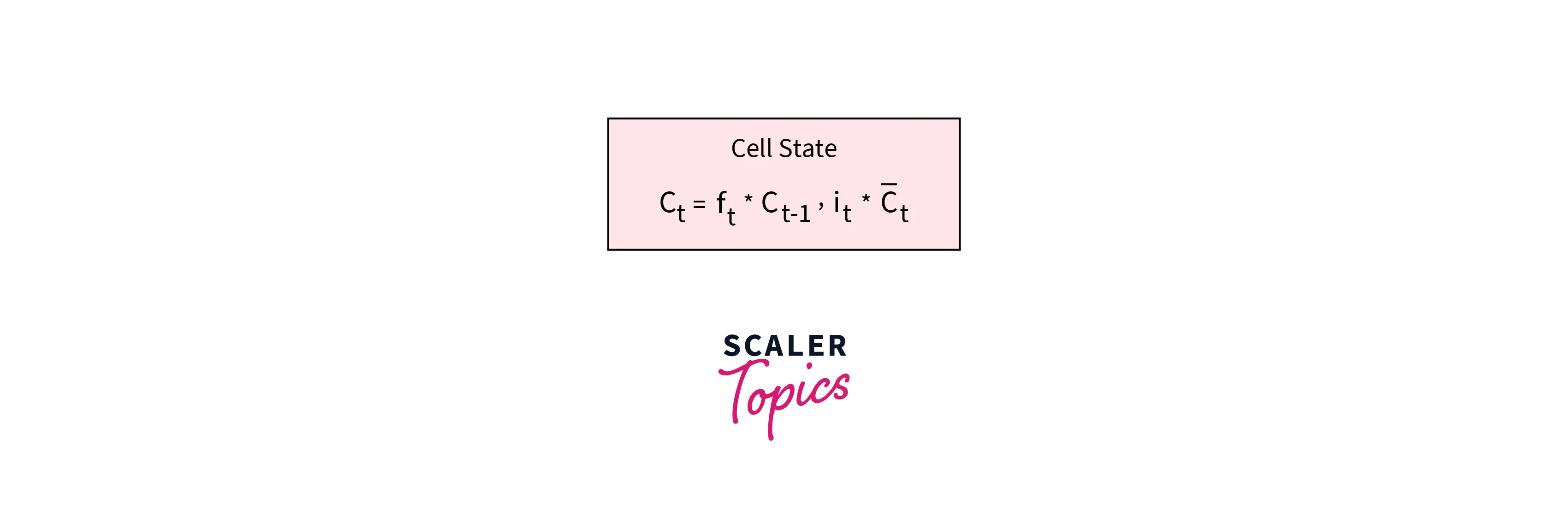
Cell State:
The forget gate and input gate update the cell state. The cell state of the previous state is multiplied by the output of the forget gate. The output of this state is then summed with the output of the input gate. This value is then used to calculate hidden state in the output gate.
How do LSTMs Work?
The LSTM architecture is similar to RNN, but instead of the feedback loop has an LSTM cell. The sequence of LSTM cells in each layer is fed with the output of the last cell. This enables the cell to get the previous inputs and sequence information. A cyclic set of steps happens in each LSTM cell
- The Forget gate is computed.
- The Input gate value is computed.
- The Cell state is updated using the above two outputs.
- The output(hidden state) is computed using the output gate.
These series of steps occur in every LSTM cell. The intuition behind LSTM is that the Cell and Hidden states carry the previous information and pass it on to future time steps. The Cell state is aggregated with all the past data information and is the long-term information retainer. The Hidden state carries the output of the last cell, i.e. short-term memory. This combination of Long term and short-term memory techniques enables LSTM’s to perform well In time series and sequence data.
Applications of LSTM
LSTM has a lot of applications:
- Language Modeling: LSTMs have been used to build language models that can generate natural language text, such as in machine translation systems or chatbots.
- Time series prediction: LSTMs have been used to model time series data and predict future values in the series. For example, LSTMs have been used to predict stock prices or traffic patterns.
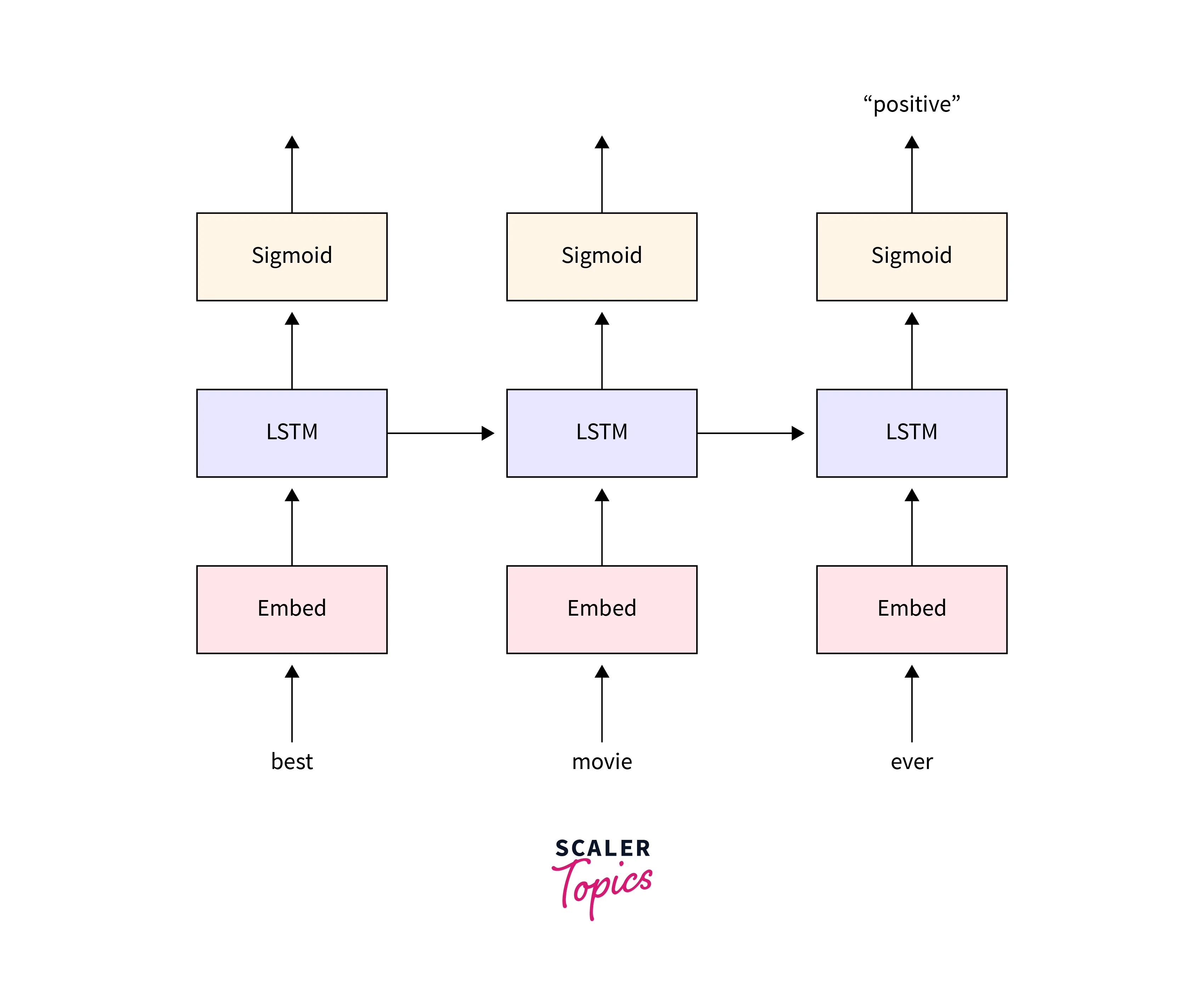
- Sentiment analysis: LSTMs have been used to analyze text sentiments, such as in social media posts or customer reviews.
- Speech recognition: LSTMs have been used to build speech recognition systems that can transcribe spoken language into text.
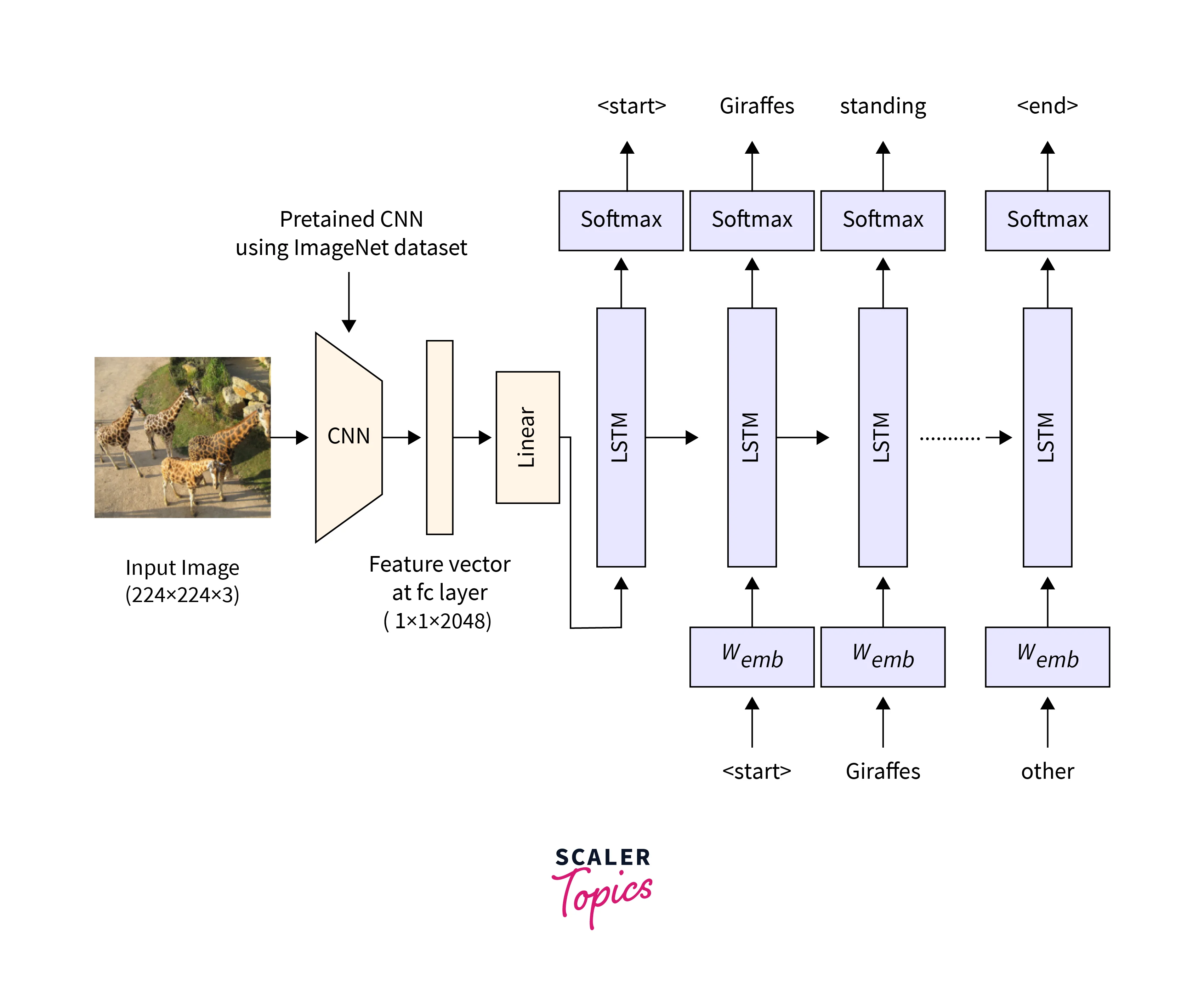
- Image captioning: LSTMs have been used to generate descriptive captions for images, such as in image search engines or automated image annotation systems.
Turn Learning into Career Growth
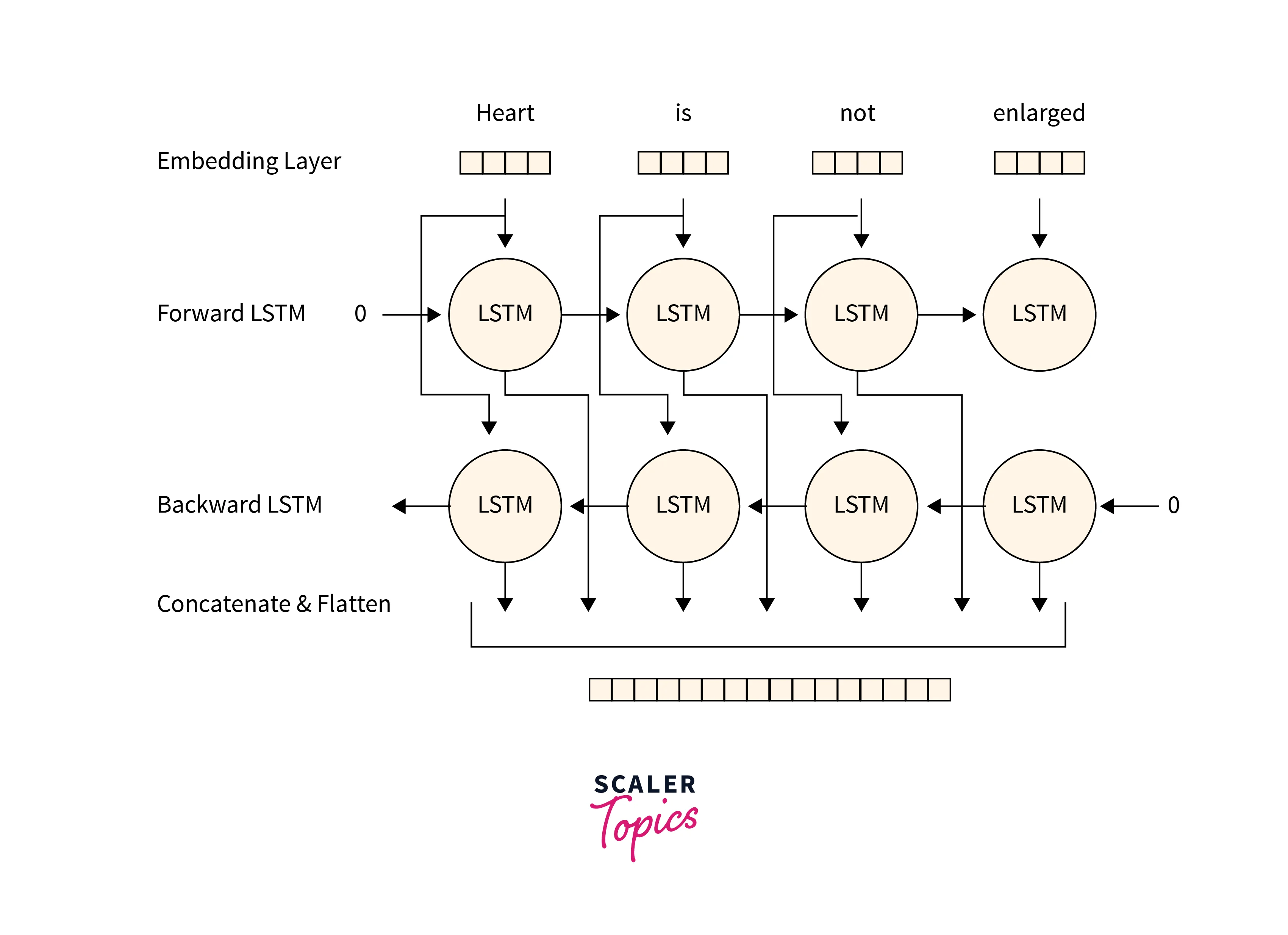
Bi-Directional LSTM
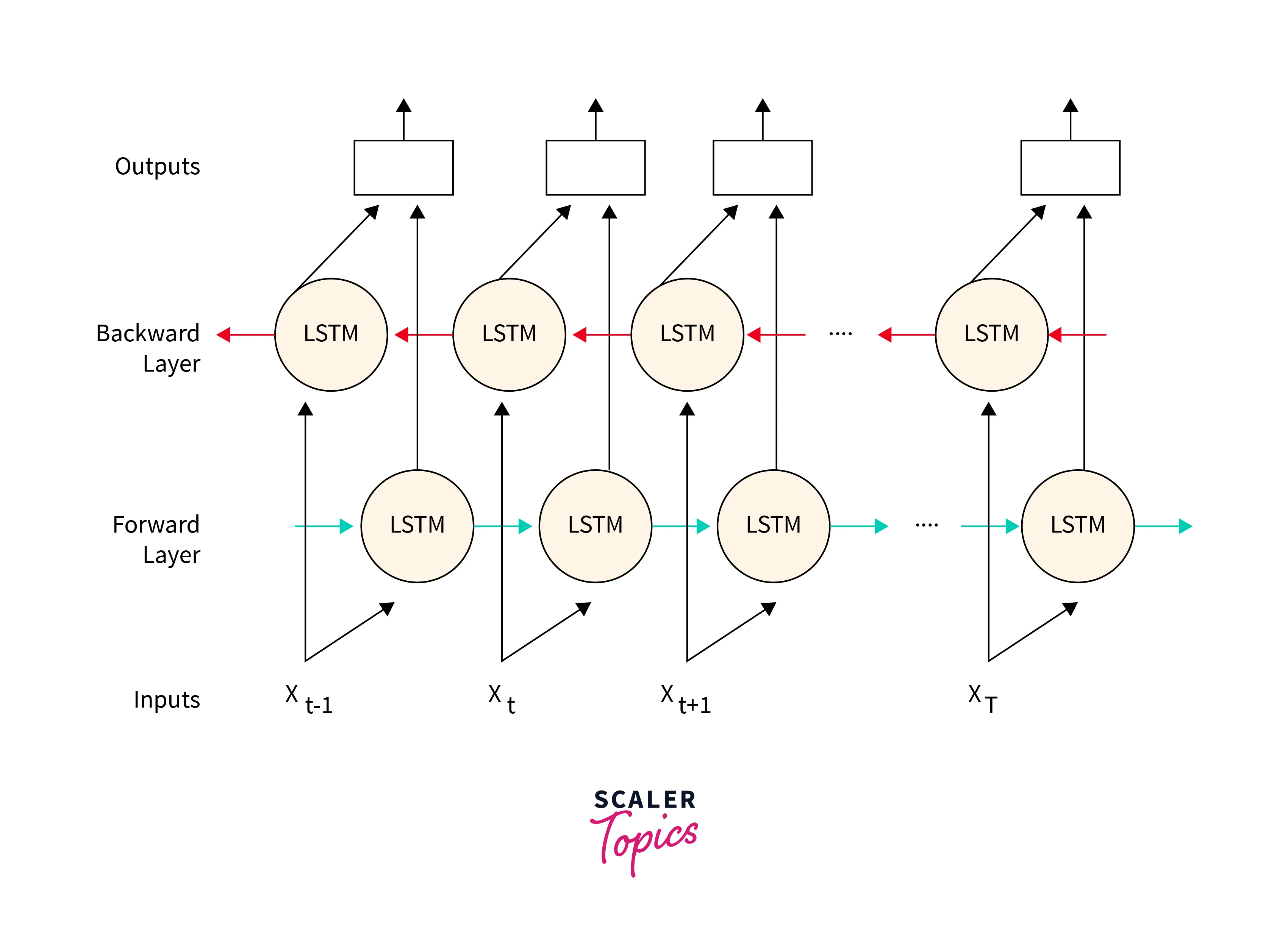
Bi-Directional LSTM or BiLSTM is an enhancement of traditional LSTM Architecture. In this method, we have two parallel LSTM Networks. One network is moving forward on the data, while the other is moving backward. This is very helpful in NLP(Natural Language Processing).
Example:
He went to ______
The model can only predict the correct value to fill in the blank with the next sentence.
And he got up early the next morning
With this sentence to help, we can predict the blank that he went to sleep. This can be predicted by a BiLSTM model as it would simultaneously process the data backward. So BiLISTM enables better performance in Sequential data.
Sequence to Sequence LSTMs or RNN Encoder-Decoders
Seq2Seq is basically many-to-many Architecture seen in RNNs. In many-to-many architecture, an arbitrary length input is given, and an arbitrary length is returned as output. This Architecture is useful in applications where there is variable input and output length. For example, one such application is Language Translation, where a sentence length in one language doesn’t translate to the same length in another language. In these situations, Seq2Seq LSTMs are used.
A Seq2Seq model consists of 2 main components. An Encoder and a Decoder. The Encoder outputs a Context Vector, which is fed to the Decoder. In our example of Language Translation, the input is a sentence. The Sentence is fed to the input, which learns the representation of the input sentence. Meaning it learns the context of the entire sentence and embeds or Represents it in a Context Vector. After the Encoder learns the representation, the Context Vector is passed to the Decoder, translating to the required Language and returning a sentence.
An Encoder is nothing but an LSTM network that is used to learn the representation. The main difference is, instead of considering the output, we consider the Hidden state of the last cell as it contains context of all the inputs. This is used as the context vector and passed to the Decoder.
The Decoder is also an LSTM Network. But Instead of initializing the hidden state to random values, the context vector is fed as the hidden state. The first input is initialized to <bos> meaning ‘Beginning of Sentence’. The output of the first cell(First Translated word) is fed as the input to the next LSTM cell.
Compare LSTM vs. RNN
Here is a comparison of long short-term memory (LSTM) and recursive neural networks (RNNs).
| Long Short-Term Memory (LSTM) | Recurrent Neural Network (RNN) | |
|---|---|---|
| Type of network | Recurrent neural network. | Recurrent neural network. |
| How it works | Uses gates to control the flow of information through the network. | Uses recursive connections to process sequential data. |
| Suitable for | Long-term dependencies. | Short-term dependencies. |
| Common applications | Language modeling, time series prediction, sentiment analysis, speech recognition, image captioning. | Language modeling, time series prediction, speech recognition. |
Ready to embark on a journey into the world of deep learning? Enroll in our Free Deep Learning Course & master its concepts & applications.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Conclusion
- LSTMs are a solution to the issue of RNN long-term dependency.
- LSTMs use gates and 2 states to store information.
- LSTMs work well for time-series data processing, prediction, and classification.
- Seq2Seq model is used for Variable length data.
- Encoder and Decoder use LSTM to implement Seq2Seq.