Model Optimization
Overview
Model optimization refers to the process of improving the efficiency and performance of a machine learning model, which we can achieve through techniques such as hyperparameter tuning, careful selection of the model architecture, model compression, data preprocessing, and performance optimization strategies like using a GPU, concurrency, caching, and batching.
Model optimization aims to achieve the best possible performance from a model while minimizing the computational resources and time required to train and evaluate the model.
Introduction to Model Optimization
Model optimization is a crucial step in the machine learning pipeline as it allows for improving model performance. Several techniques can be used for model optimization, such as hyperparameter tuning, regularization, and pruning. Hyperparameter tuning involves adjusting the model parameters not learned during training, such as the learning rate or the number of hidden layers.
Regularization is a technique used to prevent overfitting by adding a penalty term to the loss function. Pruning is a technique used to remove unnecessary parameters or connections from the model, which can lead to faster computation time and lower memory usage. Additionally, various tools and libraries are available that provide built-in functionality for model optimization, such as TensorFlow and PyTorch.
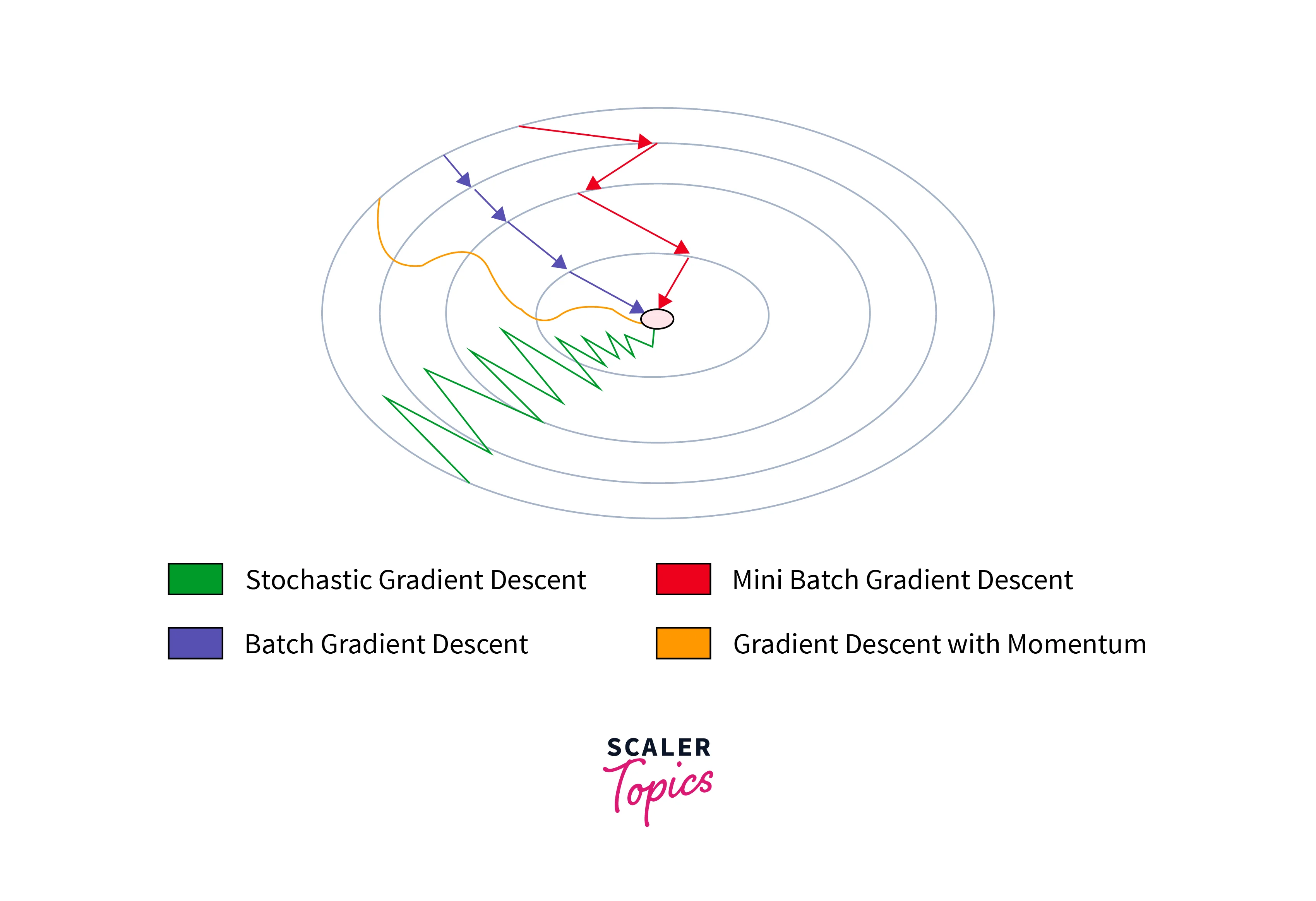
The above image describes different optimization techniques used in deep learning.
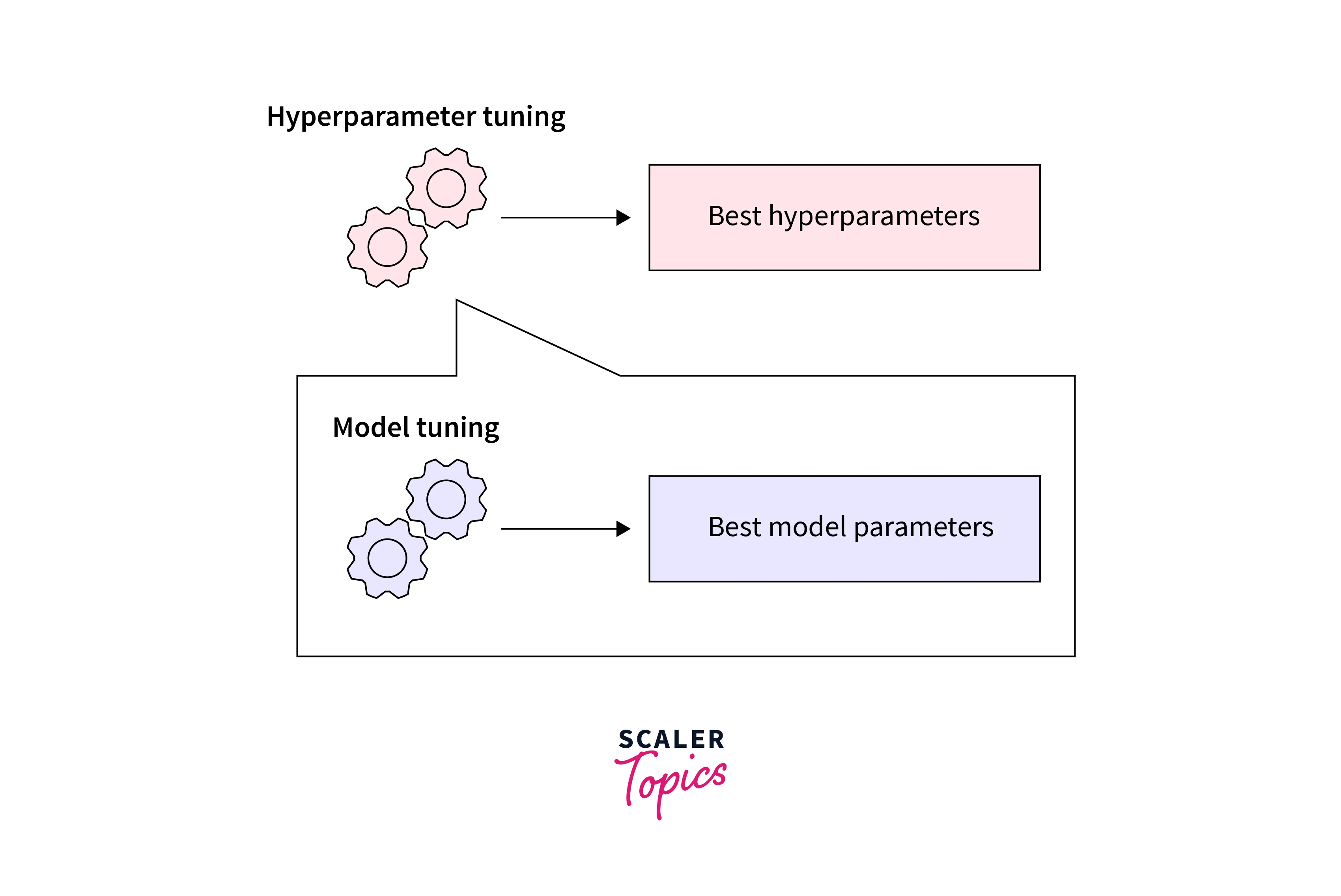
Hyperparameter Tuning as Optimization
Hyperparameter tuning refers to selecting the best set of hyperparameters for a machine-learning model. Hyperparameters are the parameters of the practitioner's model instead of the parameters learned during training.
One way to approach hyperparameter tuning is to treat it as an optimization problem. This means that you can define an objective function that measures the performance of the model on a validation set and then use an optimization algorithm to search for the set of hyperparameters that minimizes (or maximizes, depending on the objective) this function. Some common optimization algorithms for hyperparameter tuning include grid search, random search, and gradient-based optimization methods such as Adam or L-BFGS.
Another way to approach hyperparameter tuning is to use a Bayesian optimization method, which models the distribution of possible hyperparameter configurations and iteratively selects the next set of hyperparameters to try based on this model. This can be more efficient than grid or random search, especially when the number of hyperparameters is large and the search space is continuous.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Challenges Faced When Deploying a Machine Learning Model
Several challenges can arise when deploying a machine-learning model in production:
- Data quality and availability:
The model may be trained on a certain type of data, but the data may differ in production. This can lead to poor performance of the model. - Performance:
The model may perform better in production than during testing. This can be due to various factors, such as changes in the data distribution or the presence of unseen data. - Scalability:
The model may need to handle many predictions at once, which can be challenging if the model is not designed to be scalable. - Maintenance:
The model may need to be retrained or updated over time as new data becomes available or the requirements of the application change. - Data quality and availability:
The model may be trained on a certain data type, but the data may differ in production. This can lead to poor performance of the model. - Explainability:
A model's predictions may only sometimes be easily interpretable or understandable. This can concern certain applications, such as healthcare or finance, where explainability is critical. - Bias:
you may train a model on biased data, which can lead to unfair or inaccurate predictions in production. This is especially important when working with sensitive data, such as demographics. - Security:
A deployed model may be vulnerable to attacks, such as adversarial examples or model stealing. Ensuring the security of a deployed model is an important consideration, especially when dealing with sensitive data or high-stakes applications.
Making ML Model Deployment More Efficient
To make machine learning model deployment more efficient, some strategies you can use include:
- Ensuring the model is robust and generalizable:
This can be achieved through careful feature engineering and regularization during model training. - Using efficient model architectures and optimization algorithms can help improve the model's performance and scalability.
- Implementing effective model monitoring and evaluation:
This can help to identify problems with the model early on so that they can be addressed before they have a major impact. - Using automated model training and deployment pipelines can help streamline updating and deploying the model and make it easier to incorporate new data and changes to the application.
- Using cloud-based machine learning platforms can handle the scalability and maintenance challenges of deploying a machine learning model and often provide additional tools and resources to help with model training and deployment.
Performance Optimization
Performance optimization refers to improving the efficiency and speed of a machine learning model. We can use several strategies to optimize the performance of a model
GPU or No GPU
Using a graphics processing unit (GPU) can significantly speed up the training of a deep learning model, as GPUs are specifically designed for parallel computations. However, training the model on a CPU may be more efficient if the model is small or the dataset is small.
Turn Learning into Career Growth
Concurrency
If the model is being used for inference (i.e., making predictions) rather than training, concurrency (e.g., multiple threads or processes) can help speed up the prediction process.
Model Distillation
Model distillation is a technique that involves training a small, efficient model to mimic the behavior of a larger, more accurate model. This can speed up the inference process, as the smaller model is faster to evaluate than the larger model.
Model Quantization
Model quantization refers to reducing the precision of the weights and activations in a model, which can significantly reduce the memory and computational requirements of the model.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Caching
Caching refers to storing the results of computations in memory so they can be reused later on without recomputing. We can use this to speed up the inference process, especially if the same inputs are passed to the model multiple times.
Batching
Batching is a common technique used to speed up the training process of machine learning models. It involves dividing the data into smaller chunks, or "batches," and processing them in parallel. By processing multiple samples simultaneously, the model can take advantage of the parallel processing capabilities of modern hardware, such as GPUs.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Conclusion
- Model optimization is an essential part of the machine learning process, as it helps improve a model's efficiency and performance.
- We can use various techniques to optimize a model, including hyperparameter tuning, model compression, data preprocessing, and performance optimization strategies like GPU, concurrency, caching, and batching.
- Deploying a machine learning model in production can be challenging and requires careful consideration of data quality, performance, scalability, and maintenance issues.
- By carefully selecting the appropriate optimization techniques and strategies, practitioners can improve the efficiency and performance of their machine learning models and ensure that they can meet the demands of a production environment.