Introduction to Recurrent Neural Network (RNN)
Overview
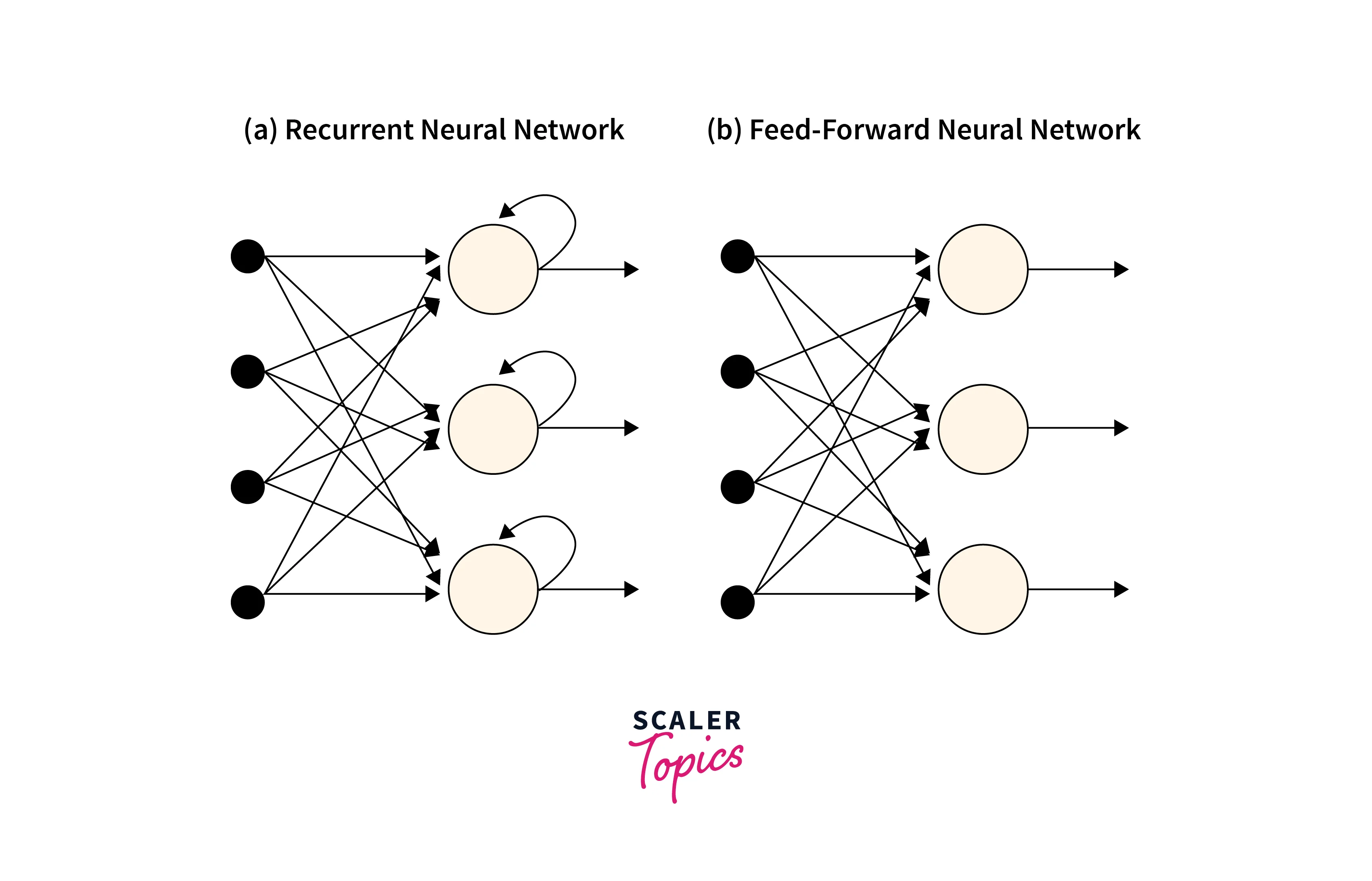
Recurrent Neural Networks in deep learning are designed to operate with sequential data. For every element in a sequence, they successfully carry out the same task, with the outcomes depending on previous input. For example, these networks can store the states or specifics of prior inputs to create the following output in the sequence due to the concept of memory.
What is RNN?
Standard Feedforward Neural Networks are only suitable for independent data points. To include the dependencies between these data points, we must change the neural network if the data are organized in a sequence where each data point depends on the one before. A unique kind of deep learning network called RNN full form Recurrent Neural Network is designed to cope with time series data or data that contains sequences.
The idea of "memory" in RNNs enables them to store the states or details of earlier inputs to produce the subsequent output in the sequence. Different types of RNNs are based on the number of inputs and outputs. They are:
- One-to-one
- One-to-many
- Many-to-one
- Many-to-many
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
How does the RNN Neural Network Work?
As we know, the single weight parameter flows through the model layers in a standard feedforward network. On the other hand, a recurrent neural network in a deep learning model contains a feedback loop that predicts the output using the previous hidden state along the input. So, let's unfold an RNN neural network and understand it in detail.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Unfolding Recurrent Neural Network
Recurrent Neural Networks(RNNs) in deep learning are so-called because they consistently complete the same task for every element in a sequence, with the results depending on earlier calculations.
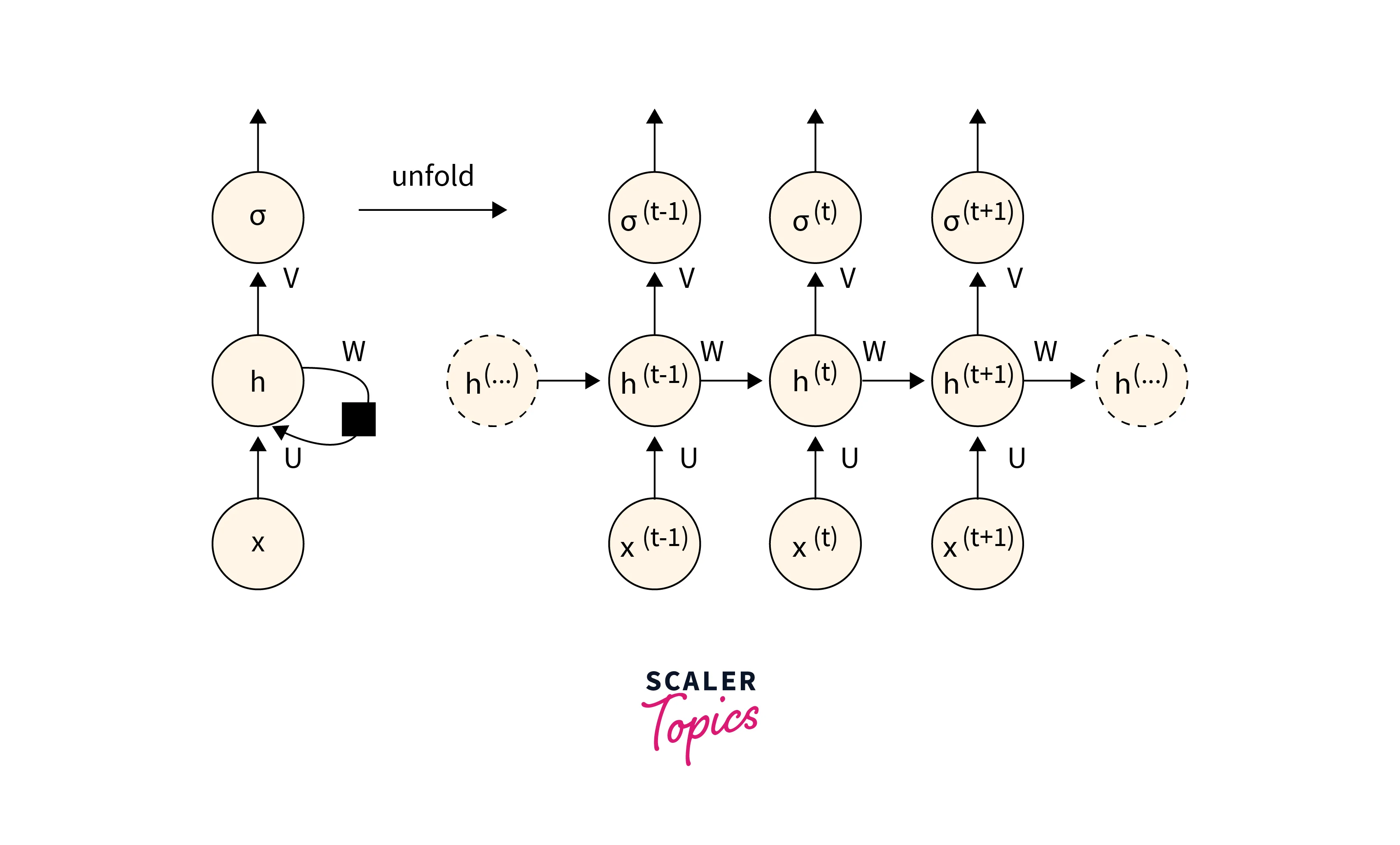
The above diagram displays an RNN neural network in notation on the left and an RNN becoming unrolled (or unfolded) into a complete network on the right. Unrolling refers to writing out the network for the entire sequence. The network will be unrolled into a 3-layer neural network, one layer for each word, for instance, if the sequence we are interested in is a sentence of three words.
Input:- At time step t, is used as the network's input. For instance, the one-hot vector x1 might represent a word in a text.
Weights:- The Recurrent neural network in deep learning has hidden input connections that are parameterized by a weight matrix , connections for hidden-to-hidden recurrent connections that are parameterized by a weight matrix , and connections for hidden-to-output connections that are parameterized by a weight matrix . These weights are shared over time.
Hidden Layer:- acts as the network's "memory" and represents a hidden state at a time t. The hidden state from the previous time step is used to calculate :
Types of RNN
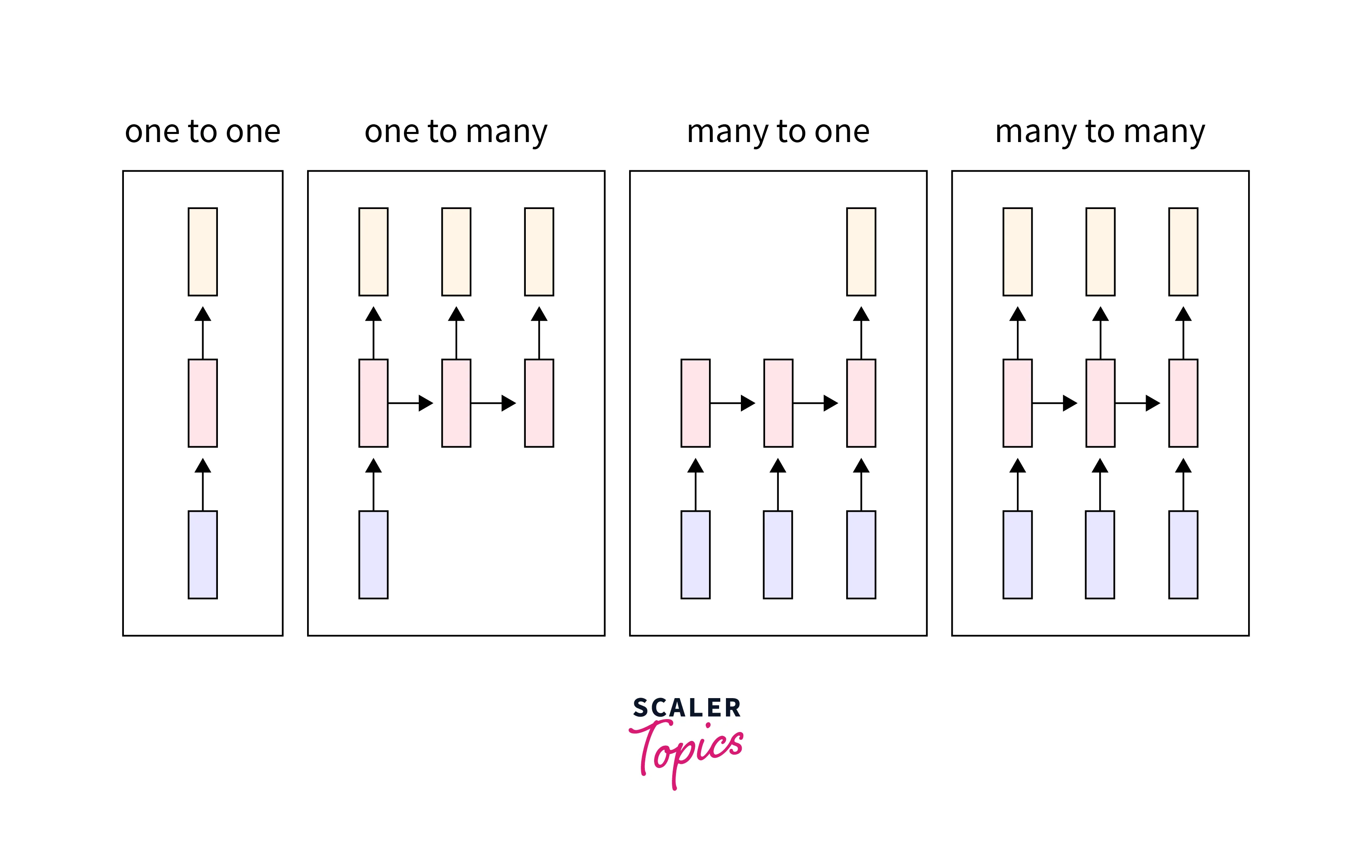
One-to-One:
One-to-One RNNs are the most basic RNN neural network types because they only support a single input and output. It operates like a regular recurrent neural network in deep learning and has set input and output sizes. Image Classification contains the One-to-One application.
One-to-Many:
A form of RNN known as one-to-many produces several outputs from a single input. It accepts a fixed input size and outputs a series of data. You can find applications for it in image captioning and music generation.
Turn Learning into Career Growth
Many-to-One:
A series of inputs are needed for a fixed output to be displayed. When a single output from numerous input units or a series of them is required, many-to-one is used. A typical illustration of this kind of recurrent neural network in deep learning is sentiment analysis.
Many-to-Many:
The output is produced via a many-to-many model when each input is read. In other words, a many-to-many model can understand the characteristics of each token in an input sequence.
Based on equal and unequal units of input and output, this model is further classified into two types:
- Equal Unit Size.
- Unequal Unit Size
Backward Propagation Through Time (BPTT)
The Backpropagation Through Time (BPTT) technique applies the Backpropagation training method to the recurrent neural network in a deep learning model trained on sequence data, such as time series. Since RNN neural network processes sequence one step at a time, gradients flow backward across time steps during this backpropagation process.
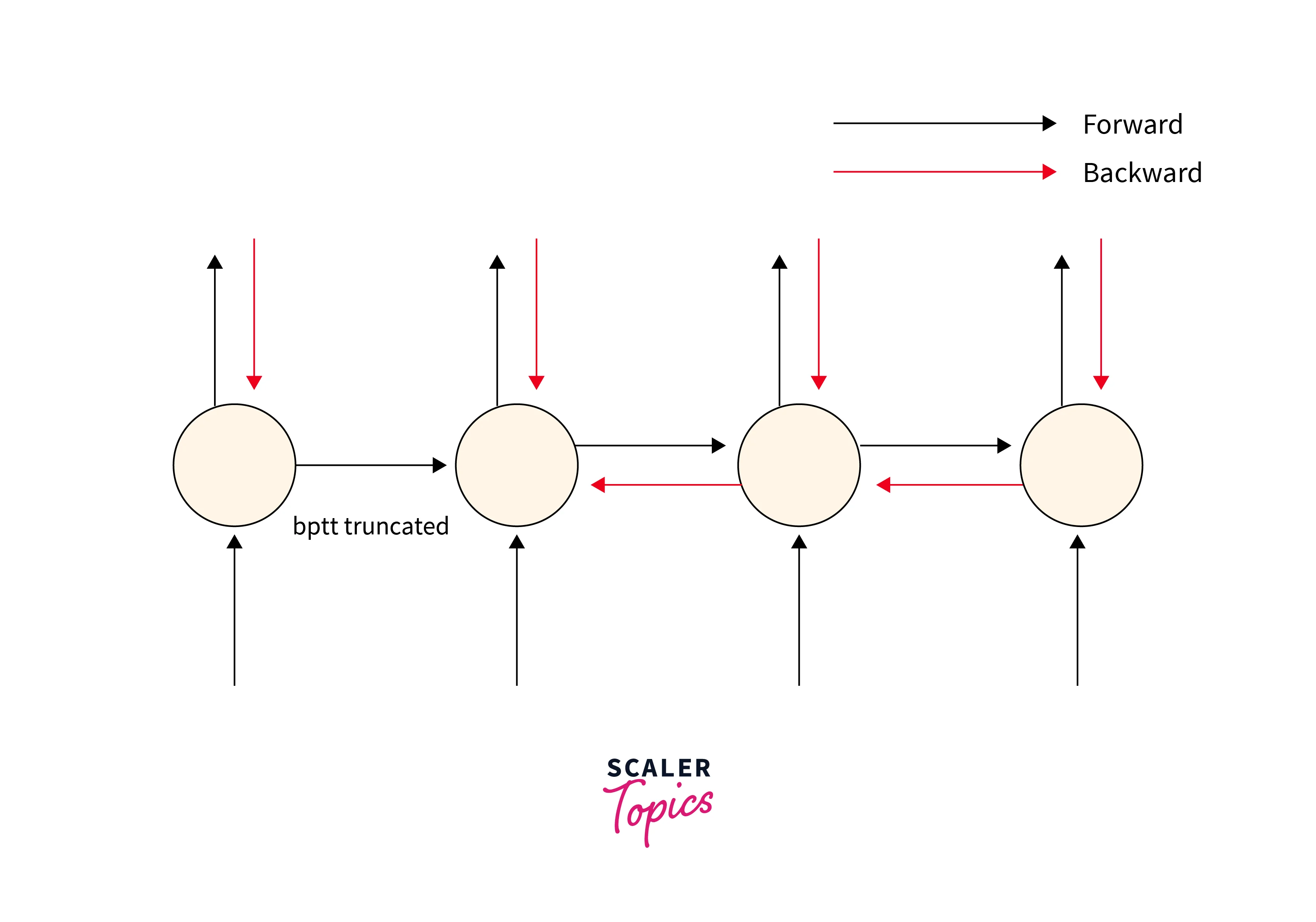
Each timestep has a single network copy, a single output, and a single input timestep. By unrolling each input timestep, BPTT operates. Then, errors are computed and totaled for each timestep. Finally, the weights are adjusted, and the network is rolled back up. At each time step, we calculate the loss. The loss at all time steps is added to determine the overall loss. The cross-entropy loss is the loss function that we use:
Here, the predicted output, at a given time step , is shown alongside the actual output .
The final overall loss with layers can be expressed as:
Our objective is to reduce the loss. By determining the RNN's optimal weights, we can reduce the loss. RNNs have three weights, input to hidden U, hidden to hidden W, and hidden to output V. Therefore, we can choose the best gradient descent algorithm to determine the ideal weights and update the weights following the weight update rule. We first calculate the gradients of the loss function to each weight:
The algorithm can be summed up as follows:
- Give the network a series of input and output pair timesteps.
- Update weights and roll up the network, and repeat.
- Calculate after unrolling the recurrent neural network in deep learning, then unroll the errors over each timestep.
This relies on the number of derivatives needed for a single weight update if input sequences comprise input sequences with thousands of timesteps. As a result, weights may disappear or explode (go to zero or overflow), making slow learning and model skills noisy.
Advantages and Disadvantages of Recurrent Neural Networks
The following are a few advantages that Recurrent Neural Networks offer:
- The processing of sequential data.
- Ability to remember and preserve primary outcomes.
- When calculating new results, consider the most recent and previous results.
- The model size does not change as the input size does. Over time, it distributes weights to other components.
Some of the disadvantages of RNN are:
- Problems with vanishing and gradient explosion.
- The challenge of training an RNN is quite challenging.
- Using Tanh or Relu as an activation feature prevents it from processing long sequences.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Different RNN Architectures
Short-term memory is a problem for recurrent neural networks. They will need more time to transfer information from earlier time steps to later ones if a sequence is lengthy. RNNs may exclude crucial details from the start if you're trying to process a paragraph of text to make predictions.
GRUs and LSTMs were developed to answer short-term memory problems. They possess inbuilt components known as gates that can control the information flow. These gates can learn which data in a sequence should be kept or ignored. To create predictions, it can convey relevant data along the extensive chain of sequences by doing this.
Speech synthesis, speech recognition, and text production all use this architecture. You can even use them to create video captions.
Applications of RNN
- It helps resolve time-series issues like stock market forecasts.
- It assists in resolving problems with sentiment analysis and text mining.
- The development of NLP technology, machine translation, speech recognition, language modeling, etc., uses RNNs.
- Besides other OCR uses, it aids in picture captioning, video tagging, text summarization, image identification, and facial recognition.
Ready to transform your AI skills? Our Deep Learning Course will equip you with the tools to understand, design, and implement complex neural networks.
Conclusion
- The Recurrent Neural Networks came to a close with examples of RNN neural network applications and their use in processing sequential input.
- RNNs can solve time-series and data sequence problems more effectively than conventional feedforward algorithms.
- You have learned much about RNN in this article, including its types, uses, and architecture. You have also known about its applications.