Introduction to Sequence to Sequence Models
Overview
Google first released sequence-to-sequence models for machine translation. Before it, the translation operated in an extremely ignorant manner. It was automatically translated into its intended language without considering the syntax or sentence structure of each word you typed. Sequence-to-sequence models used deep learning to transform the translation process. When translating, it considers the current word or input and its surroundings.
It is employed in many applications, including text summarization, conversational modeling, and image captioning.
Introduction to sequence-to-sequence Model
The many-to-many architecture of an RNN is what the sequence-to-sequence model (seq2seq) uses. Its ability to transfer arbitrary-length input sequences to arbitrary-length output sequences has made it useful for various applications. Some of the uses are Language translation, music creation, speech creation, and chatbots are all included in the sequence-to-sequence models concept.
In most cases, the length of the input and output differ. For example, if we take a translation task. Let's assume we need to convert a sentence from English to French.
Consider the sentence "I am doing good" to be mapped to "Je vais bien". We can see that the input feed has four words, but where in the output, we would see only three words. Hence, this algorithm handles these scenarios with varying input and output sequence lengths.
The architecture of the sequence-to-sequence model comprises two components:
-
Encoder
-
Decoder
The Encoder learns the embeddings of the input sentence. Embeddings are vectors comprising the meaning of the sentence. Then the Decoder takes the embedding vectors as input and tries constructing the target sentence.
In simple words, in a translation task, the Encoder takes the English sentence as input, learns the embedding from it, and feeds the embeddings to the decider. The Decoder generates the target French sentence using embedding fed.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Use Cases of the Sequence to Sequence Models
Many of the technologies you use every day are based on sequence-to-sequence models. For instance, voice-activated gadgets, online chatbots, and services like Google Translate are all powered by the sequence-to-sequence model architecture. Among the applications are the following:
- Machine translation - The seq2seq model predicts a word from the user's input, after which each subsequent word is predicted using the likelihood that the first word will appear.
- Video captioning - To understand the temporal structure of the sequence of frames and the sequence model of the generated sentences with RNNs, a sequence-to-sequence model for Video captioning was developed.
- Text summarization - Using neural sequence-to-sequence models, an effective novel method for abstractive text summarization has been made available (not restricted to selecting and rearranging passages from the original text)
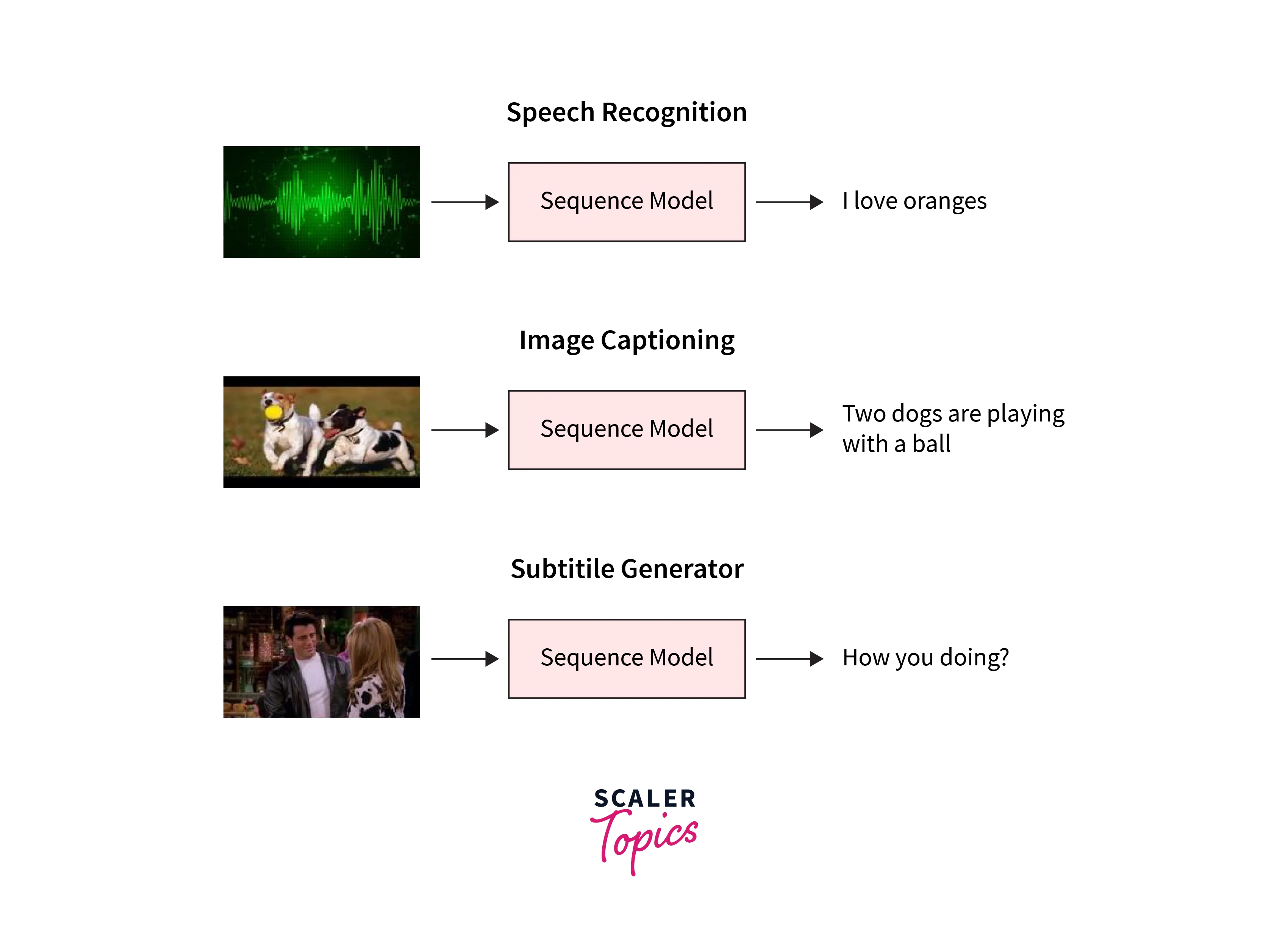
Any sequence-based problem can be solved using this technique, especially if the inputs and outputs come in various sizes and classifications.
Encoder-Decoder Architecture
An overview of the model is illustrated in the diagram below. Both have the Decoder on the right and the Encoder on the left. The Encoder and decoder output are combined to predict the following word at each time step.
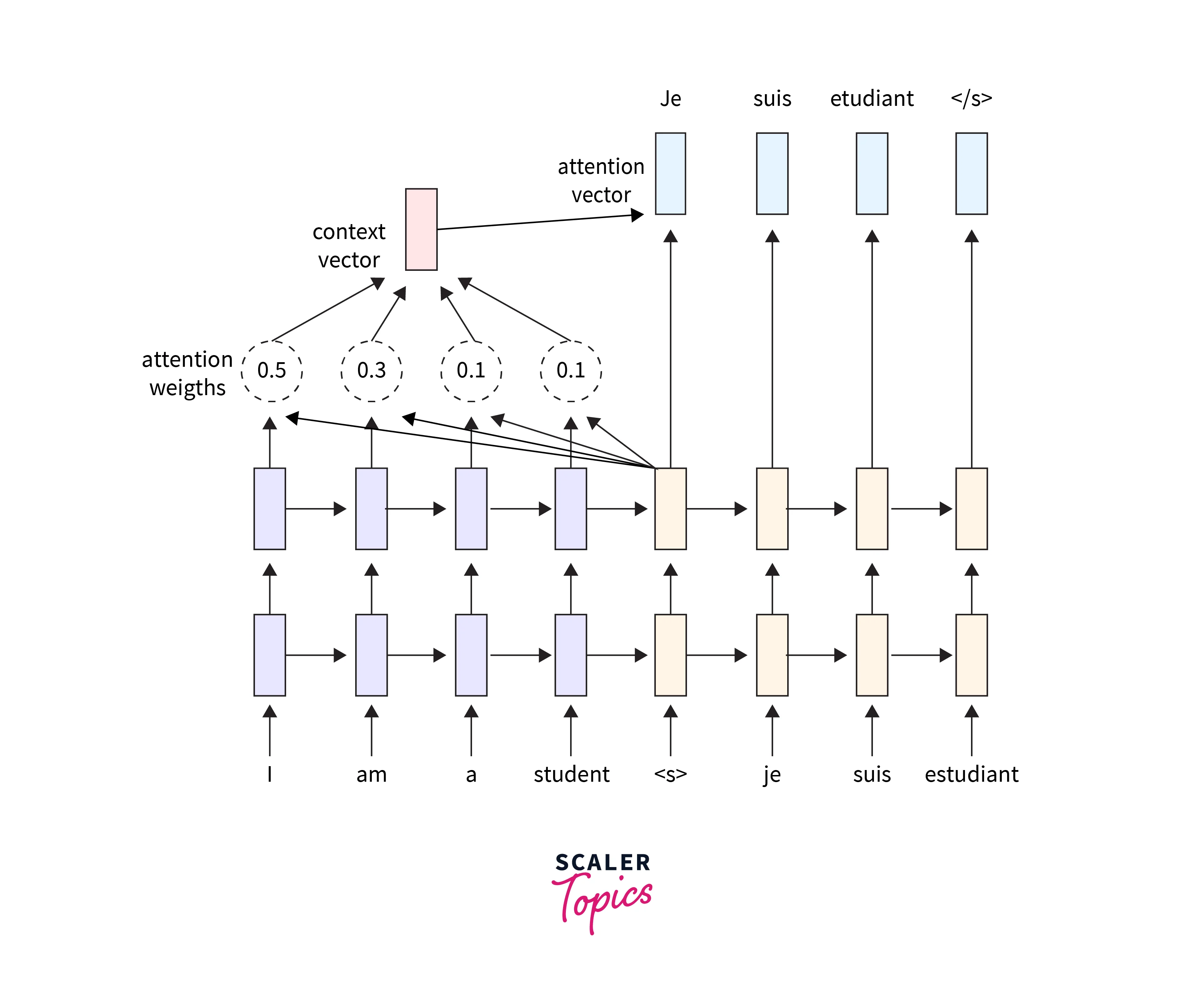
One sequence is converted into another via sequence to sequence model (sequence transformation). It uses a recurrent neural network (RNN) or, more frequently, an LSTM or GRU to get over the vanishing gradient issue. The output from the preceding stage serves as the context for each item. One Encoder and one decoder network make up the main parts. First, the Encoder converts each item into a corresponding hidden vector that includes the item and its context. Then, with the previous output as the input context, the Decoder reverses the process and produces the vector as an output item.
-
Encoder- Transforms the input words into matching hidden vectors using deep neural network layers. Each vector represents the current word and its context.
-
Decoder- To create the following hidden vector and ultimately predict the following word, it uses the current word, its hidden states, and the hidden vector created by the Encoder as input. Apart from these two, numerous optimizations must result in the following additional sequence-to-sequence model components.
-
Attention- The input to the Decoder is a single vector that must contain all of the context-related data. Large sequences cause difficulty with this. As a result, the attention mechanism lets the decoder focus on specific input sequences and generate an attention vector.
-
Beam Search- The Decoder chooses the word with the highest probability as the output. But because greedy algorithms are the root of the issue, this does not necessarily produce the optimal outcomes. As a result, beam search is used, suggesting potential translations at each stage. A tree of the top k-results is created to do this.
-
Bucketing- Because both the input and the output of a sequence-to-sequence model are padded with zeroes, variable-length sequences are conceivable. However, if we put the maximum length at 100 and the sentence is just three words long, there will be a significant loss of space. So, we apply the bucketing concept. First, we create buckets of varying sizes, such as (4, 8), (8, 15), and so forth, where 4 is the maximum input length and 8 is the maximum output length.
Input and Output Sequences of Equal Length
You can easily create similar models with a Keras LSTM or GRU layer when the input and output sequences are the same lengths.
This strategy has a drawback because it presumes you can generate target[...t] for given input[...t]. Unfortunately, the whole input sequence is usually required before generating the target sequence. That works in a few situations (such as adding strings of digits), but it could be more effective for most use cases.

Turn Learning into Career Growth
Language Translation Using the seq2seq Mode
As discussed above, let's learn how the encoder and decoder work to handle tasks that map input and output of different lengths.
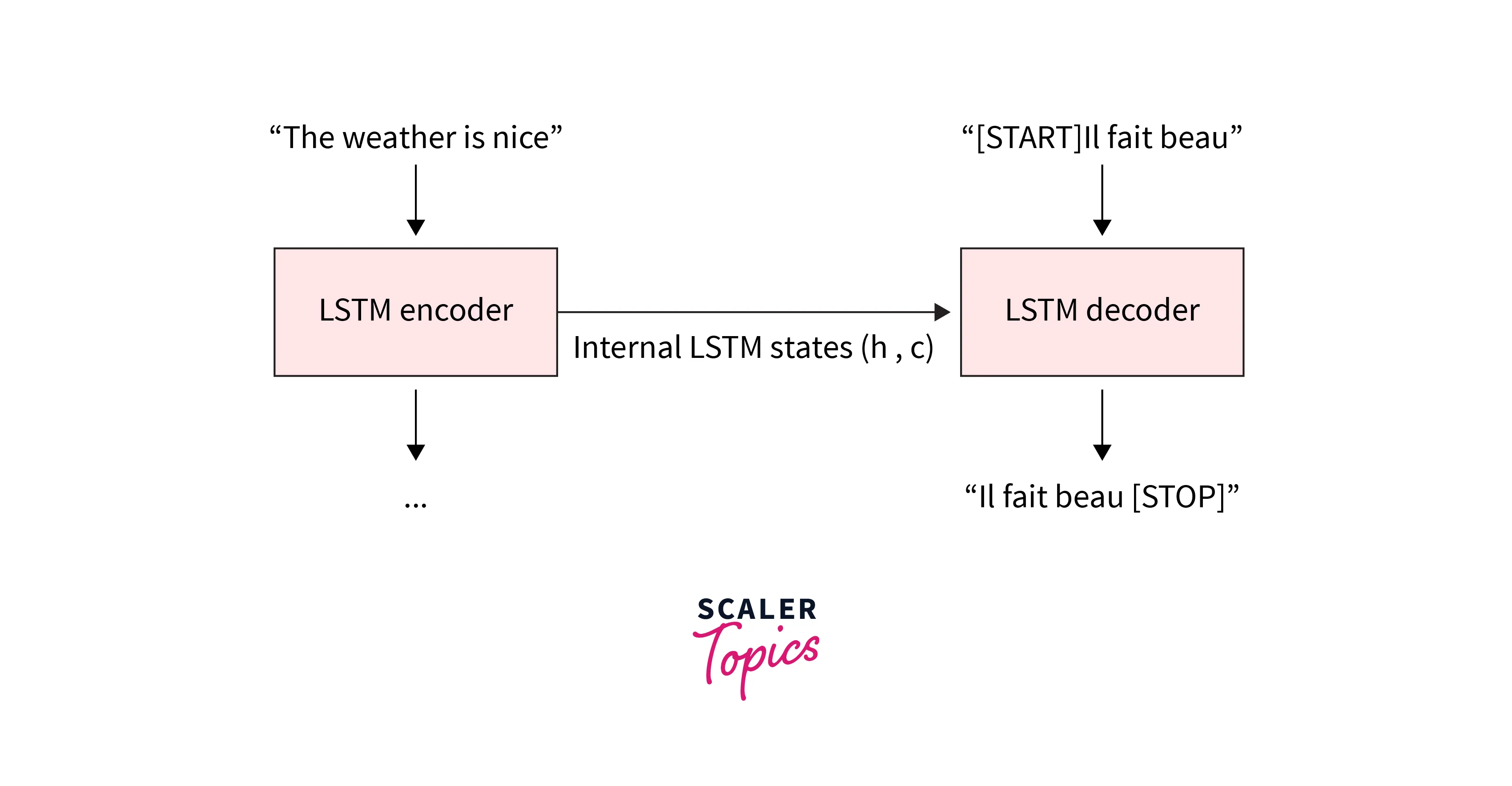
We try to translate a sentence from English to French. Let the sentence be, "The weather is nice."
Encoder
The basic structure of an encoder is an RNN with LSTM or GRU cells(control what information to keep or what to throw). Another option is a bidirectional RNN. Instead of using the output from the Encoder, we feed the input sentence into it, and we use the hidden state from the last time step as the embeddings.
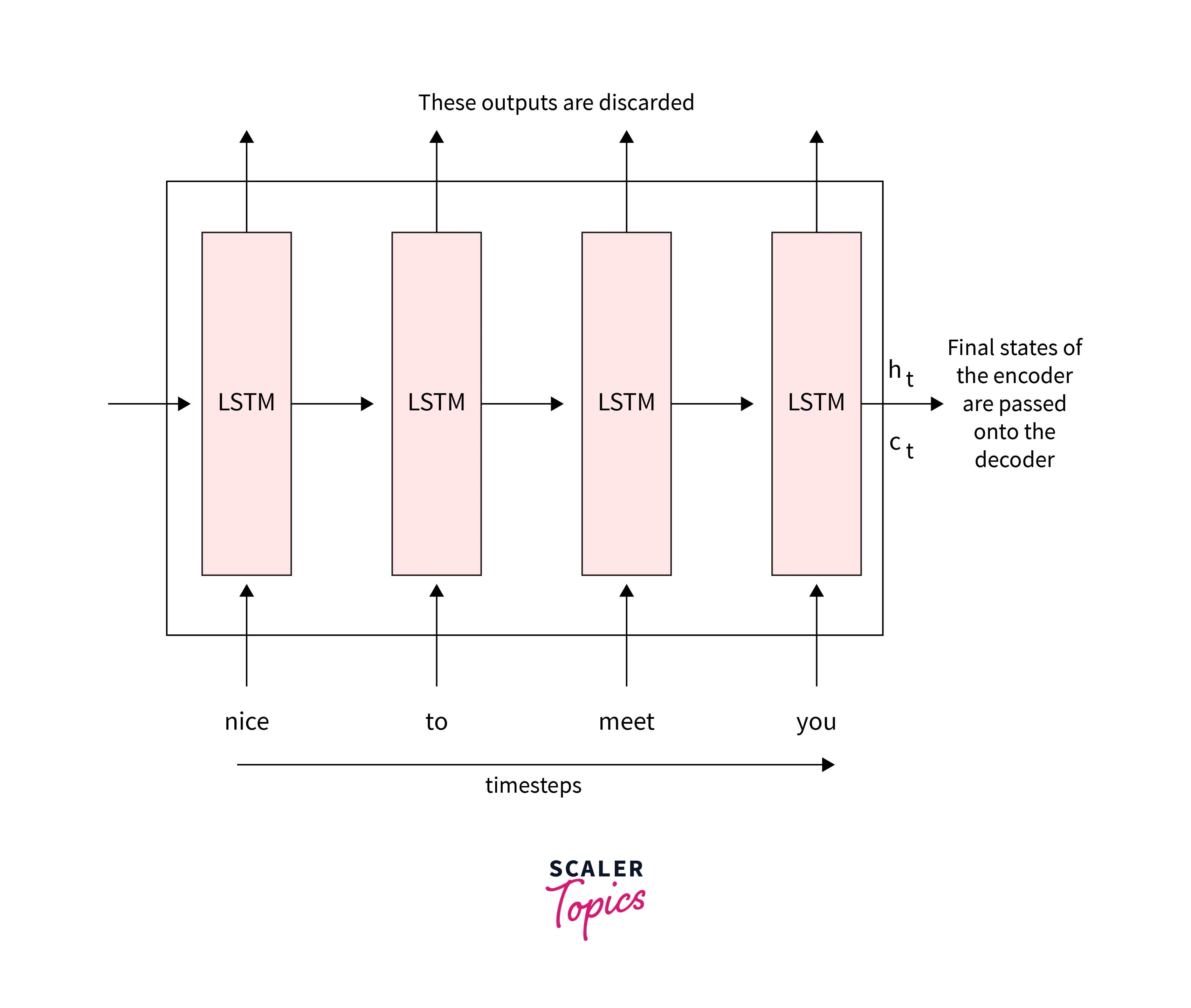
As a first step at a time steps , To the LSTM cell, we pass the input , which is the first word from the source sentence. The model randomly initialized the hidden state with the input(); the LSTM cell computes the first hidden state, , as:
In the next step at time , we pass the input, , the next word from the sentence "weather", to the Encoder. Along with this, we also pass the previously hidden state to the cell and compute the hidden state :
The process repeated all over the source sentence. Thus the final hidden layer captures the context of all the words from the source sentence. Here the English sentence "The weather is nice" is the source. The words processed in the layers would be "The,", "Weather", "is", and "nice".
Since the final hidden layers hold context, this forms the embedding , which is otherwise known as the context vector:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Decoder
A decoder is an RNN with LSTM OR GRU cells. The Decoder aims to generate the output from the given input sentence. Now, we will learn about the working of the Decoder to generate the output using the vector Z generated by the Encoder.
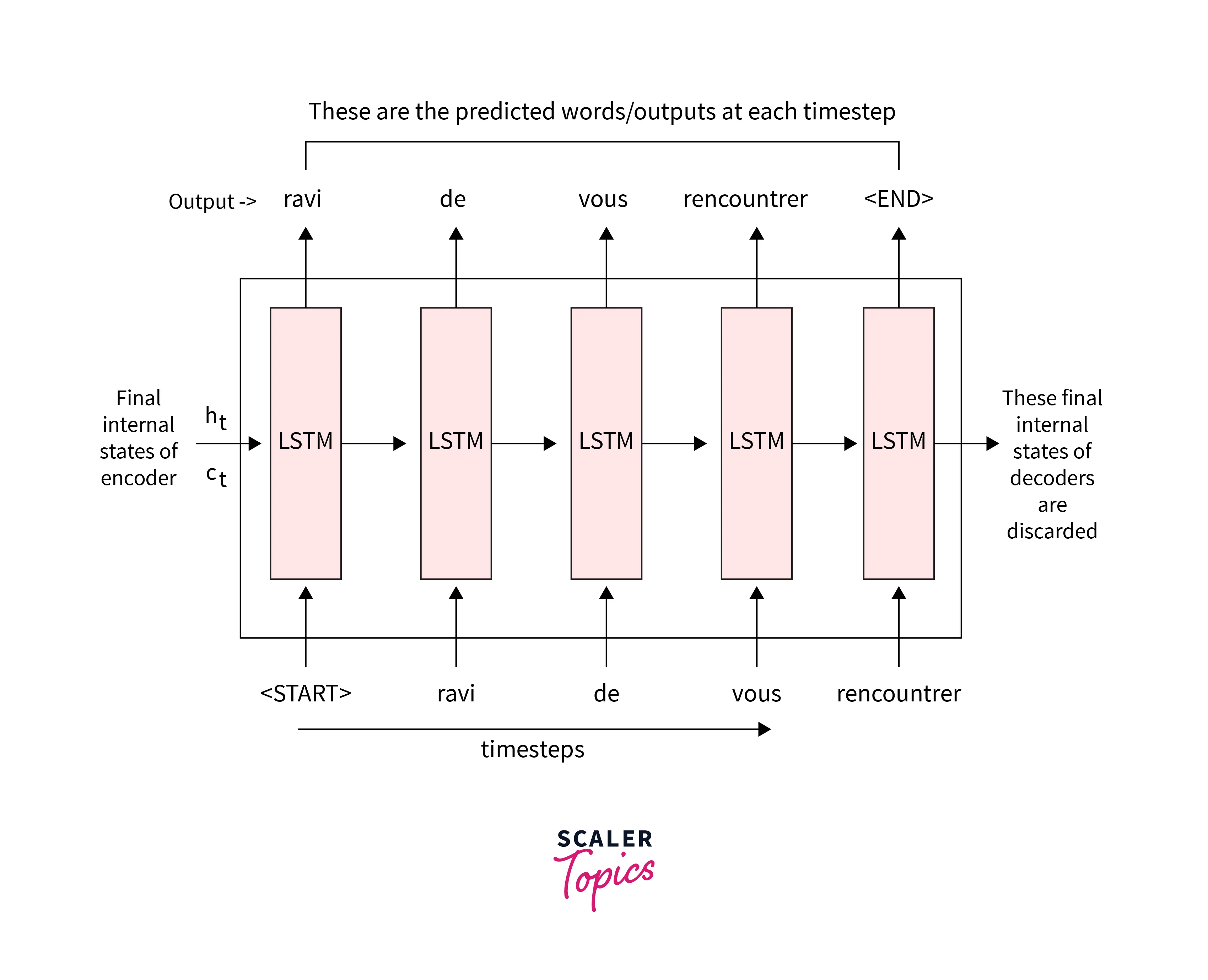
We provide the Decoder with <sos>, which denotes the beginning of the sentence, as input. So, after receiving <sos>, the decode attempts to guess the target sentence's first word.
We initialize the first hidden state of the Decoder with the vector generated by the Encoder instead of initializing them with a random value. Next, we feed the predicted output and the hidden state from the previous time step as input to the Decoder at the current time step and then predict the current output.
We need to predict the output sentence, a French sentence mapping the English sentence that feeds as input to the model. Then, we feed the Decoder hidden state, which returns the scores of all the words in our vocabulary to the corresponding input.
We convert them into probabilities and use the softmax function, which squashes the values between 0 to 1. Then, we select the high-probability valued word for the mapping to the input.
Thus, the sequence-to-sequence model changes the source sentence into the destination sentence in this manner.
Drawbacks of Encoder-Decoder Models
This architecture has two main disadvantages, both of which are length-related.
- First off, its architecture has considerably less memory. You're attempting to squeeze the full sentence to translate into that last hidden state of the LSTM. Typically, They only have a few hundred units (or floating-point integers); the more you try to fit into this restricted dimensions vector, the lossier the neural network is compelled to be. It can be quite helpful to think of neural networks regarding the "lossy compression" that must be done.
- Second, a neural network is more challenging to train the deeper it goes. For recurrent neural networks, the sequence length determines how far the network extends over time. As a result, the gradient signal from the recurrent neural network learns vanishes as it moves backward, resulting in vanishing gradients. Hence this remains a basic issue even with RNNs designed to help prevent disappearing gradients, like the LSTM.
Conclusion
- Sequence-to-sequence (Seq2Seq) models excelled at tasks including text summarization, image captioning, and machine translation.
- They make handling tasks with different input lengths and the expected output much easier.
- Additionally, models like Attention Models and Transformers are available for longer, more complex sentences.