Text Generation with Tensorflow
Overview
Character-level RNNs are the recurrent neural network that processes input data at the character level rather than at the word level like traditional RNNs. We can use them for various natural language processing tasks, including language translation, text classification, and text generation. However, character-level RNNs have limitations, such as longer training time and lower overall performance than word-level models on some tasks.
What are We Building?
In this article, we will build a character-level Recurrent Neural Network (RNN) using Tensorflow. An RNN is a type of neural network that is well-suited to processing sequential data such as text. A character-level RNN operates on individual characters rather than entire words, allowing it to process and text generation one character at a time. Here is a breakdown of the steps we will follow:
- Preprocessing the data.
- Building the model.
- Training the model.
- Text generation using the trained model.
Pre-requisites
Here are some of the major topics that we will cover in this article:
- Recurrent Neural Networks (RNNs) are a type of neural network that can process sequential data, such as time series or natural language.
- Long Short-Term Memory (LSTM) cells are a specific type of RNN designed to retain information over longer periods, allowing them to handle sequences with long-term dependencies better.
- Text preprocessing is the process of cleaning, tokenizing, and normalizing text data to prepare it for use in machine learning models.
- TensorFlow is an open-source software library for machine learning that allows for the creation of complex and large-scale neural networks. It supports RNNs and LSTMs and can be used for various tasks, including natural language processing and computer vision.
It would be helpful to have a basic understanding of these topics before proceeding with the tutorial. If you are still familiar with these topics, consider reading more before continuing.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
How are We Going to Build This?
To build the character-level RNN, we will follow these steps:
- Preprocess the data:
We will start by preprocessing the text data to train the RNN. This will involve converting the text to a numerical form that can be input into the network and splitting the data into training and test sets. - Build the model:
We will define the model architecture next. This will involve choosing the type of RNN cell to use, the size of the model, and the number of layers. - Train the model:
Once the model has been defined, we will train it on the training data. This will involve feeding the input data through the network, using the output to calculate the loss and backpropagating the error to update the model weights. - Text generation:
Finally, we will use the trained model to generate new text by starting with a seed sequence and repeatedly sampling the output to develop the next character.
Output:
However, once you have completed the article, you should have a character-level RNN model to text generation one character at a time. You can use this model to generate text similar to the training data or create new and original text.
Requirements
To follow along with the code provided, you will need to have the following libraries and modules installed:
- TensorFlow:
This machine learning library will build and train the LSTM model. You can install TensorFlow by running pip install tensorflow or pip install tensorflow-cpu (if you don't have a GPU). - NumPy:
This numerical computing library will manipulate data and perform calculations. You can install Numpy by running pip install numpy.
In addition to these libraries, you will need the Shakespeare dataset, which we can download here.
Building Character Level RNN with TensorFlow
Building a character-level Recurrent Neural Network (RNN) with TensorFlow is a multi-step process. This guide will provide an overview of the steps involved, starting with the simpler ones and progressing to the more complex ones.
Import the Libraries
First, we'll import the necessary libraries. We'll be using TensorFlow and NumPy.
Turn Learning into Career Growth
Load the Dataset
Next, we'll load the dataset. We'll use a pre-processed version of the Shakespeare dataset downloaded for this example.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Preparing the Dataset
This can be done using python's built-in set() and enumerate() functions, as shown in the code snippet below. The set() function extracts all the unique characters from the text, while the enumerate() function assigns a unique integer to each character. The result is two dictionaries: one map characters to integers (char_to_int), and another maps integers to characters (int_to_char). We will use these dictionaries later to encode and decode the text data as input and output for the RNN.
LSTMs for Text Generation
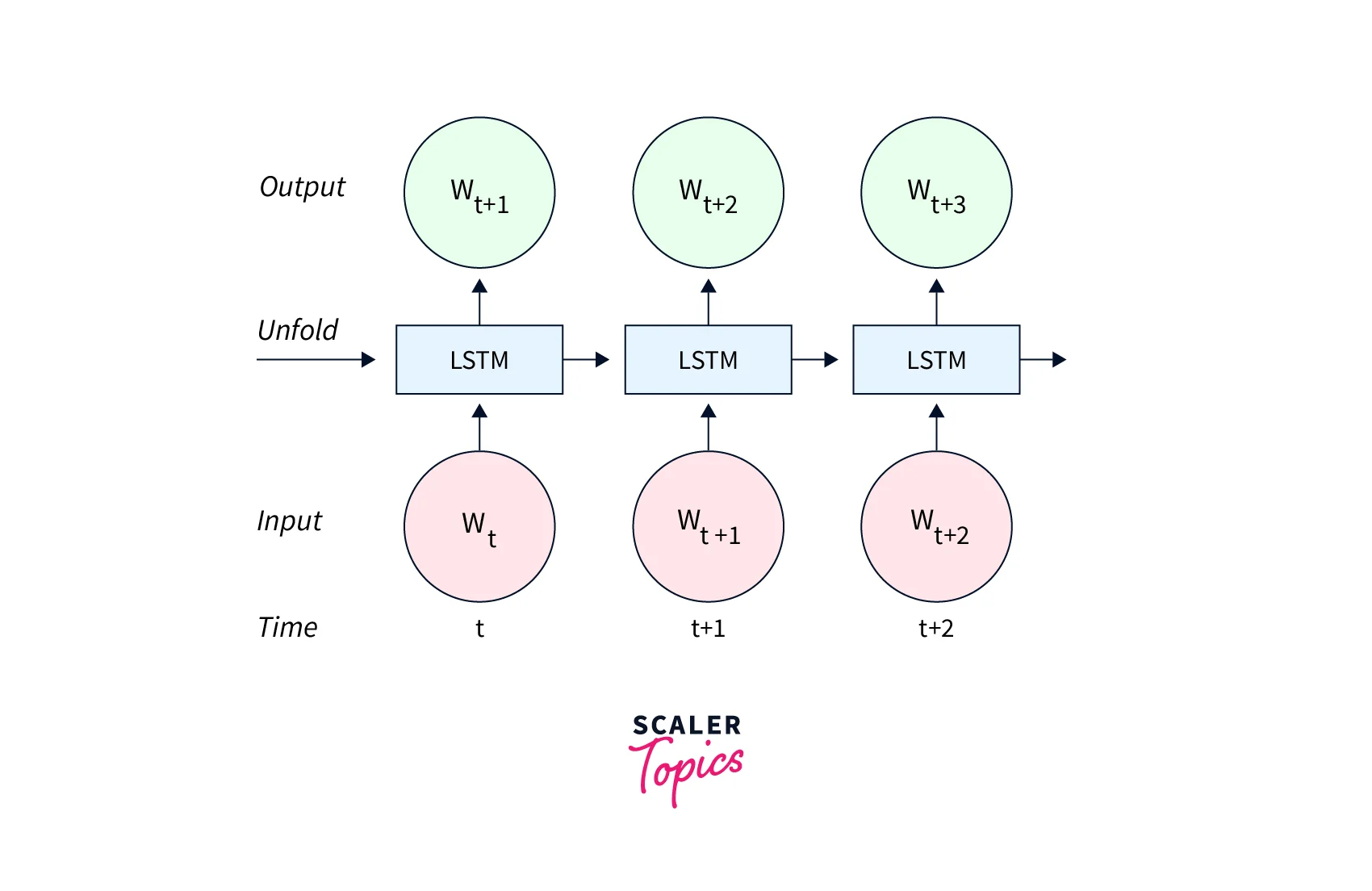
The first step is creating a list of unique characters and mapping each to a unique integer. This can be done using python's built-in set() and enumerate() functions. Then, we create training examples and labels by creating a sliding window over the text, where the input is a sequence of characters, and the label is the next character in the sequence. We pad the input sequences to be all the same lengths and convert the labels to a definite format.
Now that we have our training examples and labels, we'll need to pad them so they all have the same length. We'll use zero padding for this.
We use TensorFlow's Sequential API to build the LSTM model for text generation, adding an Embedding layer, an LSTM layer, and a Dense layer with a softmax activation in sequence. The Embedding layer converts input data into a dense vector representation, the LSTM layer processes the sequence data, and the Dense layer produces the output.
The output dimension of the Embedding layer should be the number of unique characters in the dataset, and the units of the LSTM layer and the Dense layer should be the same.
With the model compiled, we can now start training.
Generating the Text
With the model trained, we can now use it for text generation. To do this, we'll define a function that takes in a seed sequence and generates a specified number of characters.
Now we can DO text generation by calling the generate_text function with a seed sequence and the number of characters to generate.
Ouput:
What’s Next?
You can extend the project in many ways to add more features and functionality. Here are a few ideas:
- Experiment with different model architectures:
You can try using different numbers of layers or types of layers (e.g., GRU, RNN) to see how it affects the model's performance. - Use a different dataset:
The Shakespeare dataset is quite small, so you should try using a larger dataset to see if it improves the quality of the generated text. There are many publicly available datasets that you can use for text generation, such as Project Gutenberg or The Internet Archive. - Fine-tune the model:
You can try adjusting the model's hyperparameters, such as the learning rate or the batch size, to see if it improves the performance. Try using early stopping or learning rate decay techniques to prevent overfitting. - Add additional functionality:
You can add features to the text generation function, such as specifying the generated text's length or the sampling process's temperature. You can also integrate the text generation function into a web application or a command-line interface.
Conclusion
- RNNs are effective at processing sequential data such as text.
- LSTM cells can help improve the performance of an RNN by allowing it to retain long-term memory.
- We must preprocess text data before we can use it to train a model.
- Tensorflow provides a convenient and powerful toolkit for building and training RNNs.
Building a character-level RNN is a great way to learn more about neural networks and natural language processing and can serve as a starting point for more advanced projects in these areas.