Git Blame
The git blame command is essential for tracking file changes, providing a line-by-line breakdown of alterations and their authors. To use it, simply input git blame followed by the file's name. This command resembles git log and aids in collaboration, facilitating the identification of contributors to a file.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Pre-Requisites
The prerequisites for learning the git blame command can be a basic understanding of Version Control Systems, Branching, and Git. Let us discuss them briefly before learning about the git blame command.
A version control system is a tool in software development that tracks the changes in the code, documents, and other important information regarding a certain code base (or project), etc. Git is a version control system that tracks the changes in the code, documents, and other important information regarding a certain code base (or project), etc. Git is free and one of the most widely used version control systems. GitHub is a cloud-based central repository that can be used to host our code for team collaboration. It is a hosting service that is used to manage the git repository in the central server. GitHub is a free (for certain limits) and easy-to-use platform that enables teammates to work together on projects.
What Does Git Blame Do in Git?
The git blame command tells us the changes in the specific file line by line so that we can easily track the developer and the development.
We can use the git blame command by passing the name of the file that we want to track. The overall command for the same is:
The git blame command is somewhat similar to the git log command, we will be learning about the differences between both commands in the later section.






OPTIONS
Let us see the various options provided by the git blame command to tackle various situations.
- -e: The -e option or flag is used to show the email id of the author that has changed the specified file the last time. The git blame command does not show us the email id of the author by default.
- -l: The -l option or flag is used to the full commit hash. The git blame command does not show us the full commit hash but shows only the abbreviated commit hash by default.
- -L: The -L flag or option comes into the picture when we have a very large code file and we only want to check a certain range of the file. So, we can use the -L option and provide the range of tracks to Git. For example, if we want to track the changes in test.md in lines 2 to 5, we can use the command: git blame test.md -L 2,5.
- --first-parent: We use the --first-parent option or command to make Git only follow the very first of the parent for merging the commits when we are performing the blaming of the file. This option is very handy when we have multiple branches and we only want to get the information regarding the current branch and ignore the rest of the branches. We should know that the git commit can have zero or one or more than one parent. The root commits have zero number of parents, merge commits usually have two or more two parents and the rest of the commits usually have a single parent.
- -w: We use the -w option or flag to ignore the changes having only white space changes. This option comes in handy if the author has only added empty lines or switched tabs or added some white spaces then we can use it to ignore such changes.
- -M: We use the -M option or flag to detect the copied or moved files within the same file. Hence, this command will not report to us the name of the last committed author but it will report to us the name of the original author whose files were moved or copied.
- -C: We use the -C option or flag to detect the copied or moved files from different files. Similar to the last flag, this command will not report to us the name of the last committed author but it will report to us the name of the original author whose files were moved or copied.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
How Does It Work?
We use the git blame command along with GUI display tools or IDEs like VS code, Git GUI, etc. to manage large projects.
The working of the git blame command is quite simple, we first need to have a working repository, and as we know that Git always runs in the background and tracks the changes. Now, we can use the commands like git status or git log or git blame to get the various status and details of the working repository. The git log command will tell us the state of the working repository. On the other hand, the git blame command only works with individuals (single file). We can provide the name of the file that we want to track for changes with the git blame command. We can also pass the path of the file along with the git blame command.
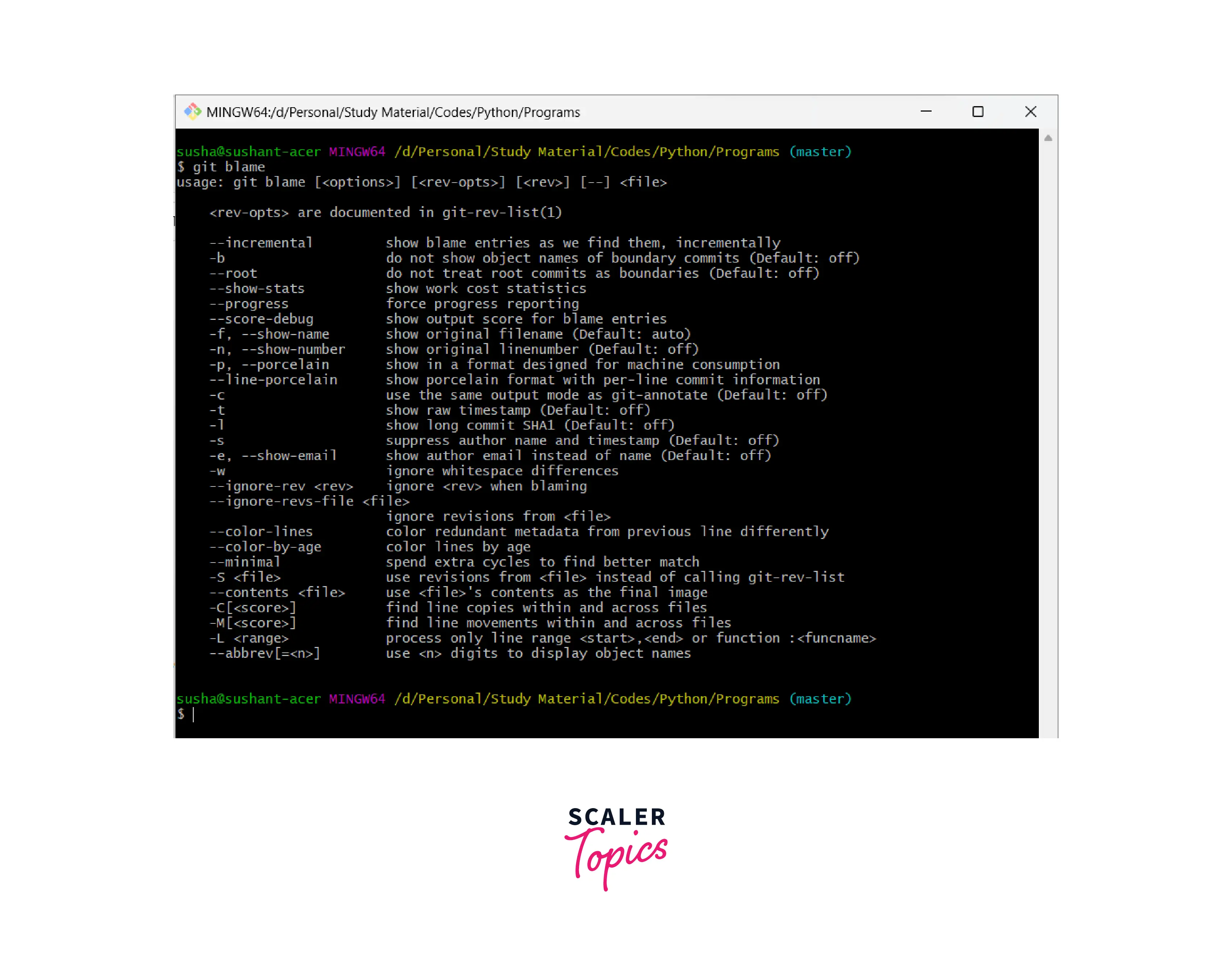
If we only run the git blame command then the details of the git blame command and other help will be shown.
Refer to the example for more clarity.
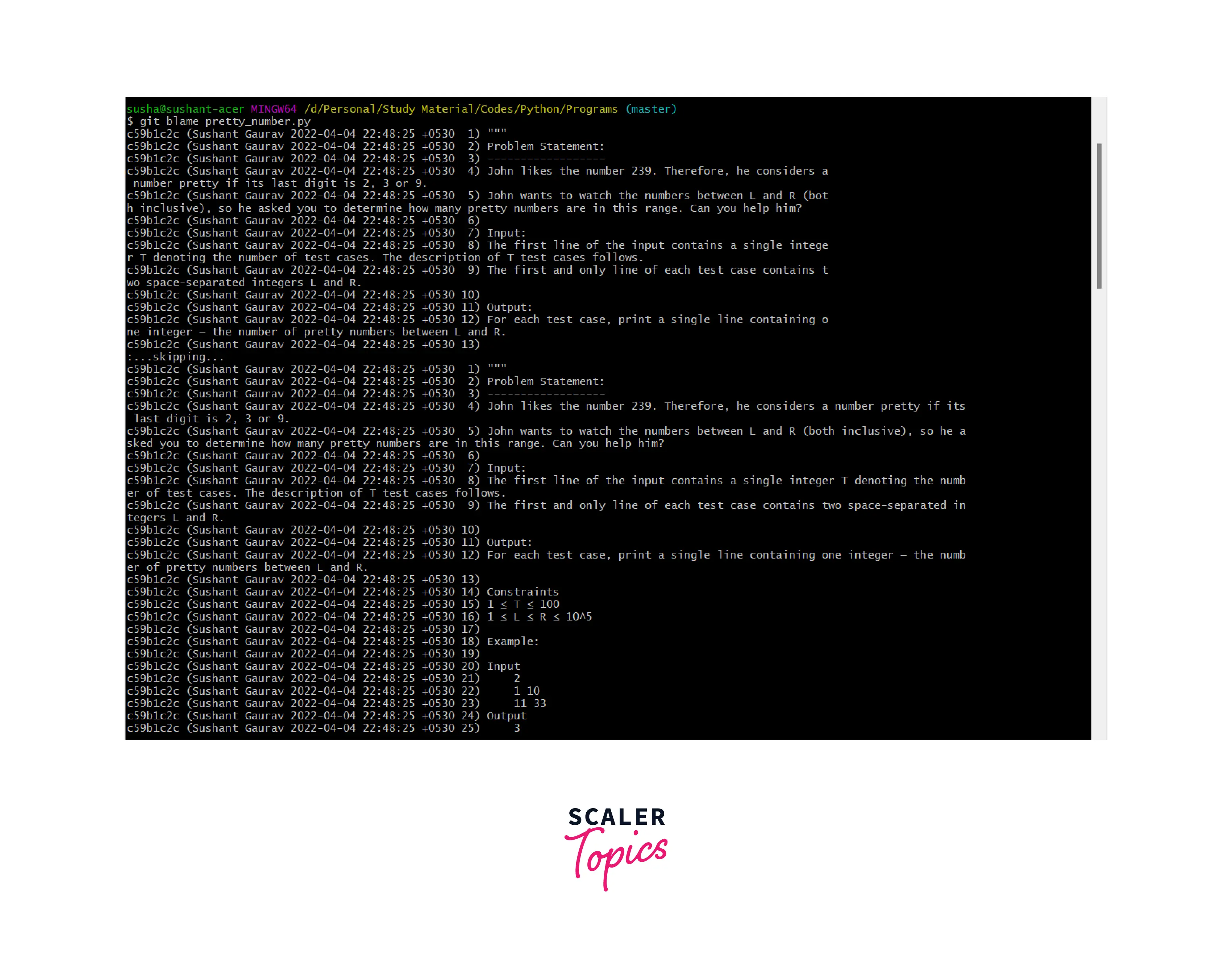
Let us run the git blame command and pass a certain file name to track its changes. Refer to the example for more clarity.
Git Blame vs Git Log
We have discussed a lot about the git blame command. The git blame command is used when we are working with fellow developers to keep track or to check which developer has changed what in any specific file. The git blame command tells us the changes in the specific file line by line so that we can easily track the developer and the development. Let us see how the git log command is different from the git blame command.
The git log command is one of the most commonly used Git commands or a utility tool that displays all the history of the current git repository. The git log command shows us snapshots of the commits or the record of all the commits of the git repository. Now, what is a commitment? Well, a commit is a snapshot of the project's current version(s). So, we track these commits and can revert to a certain commit if we want. Git tracks the changes in a project and saves a certain state that is known as commit.
The git log command displays the following information about the repository:
- Secure Hash Algorithm (SHA) value: It is 40-character checksum data that is generated using the SHA algorithm. It is also known as commit has which is always a unique number.
- author data: It is metadata that shows the name of the author and the email address of the author.
- commit date: The git log command also shows us the timestamp of the commit.
- commit title and message of each commit of the project.
In simpler terms, we can say that the git log command is used for listing and filtering the history of the project. The git log command also helps us to search for particular commits. This command only works on the committed history of the project.
Now usually when we run the git log command, we get stuck on the screen. So, if we want to get back to the Git bash then we need to press q (which means quit) to exit from the frozen screen. Now if we want to navigate on the frozen screen then we can use the following keys:
- k: It is used to move up on the screen.
- j: It is used to move down the screen.
- space bar: It is used to scroll down by a full page and to scroll up by a page.
The git log command can be compared with the git status command. The git status command is used to check the status of the repository. The git status command shows us a large view status of the git repository. We can always use the git status and git log commands to get details of the previous commits.
Turn Learning into Career Growth
Conclusion
- Git is a version control system that tracks the changes in the code, documents, and other important information regarding a certain code base, etc.
- The git blame command tells us the changes in the specific file line by line so that we can easily track the developer and the development.
- We can use the git blame command by passing the name of the file that we want to track. The git blame command is somewhat similar to the git log command. The overall command of performing the tracking of changes is: git blame "file-name".
- The git blame command is used when we are working with fellow developers to keep track or to check which developer has changed what in any specific file.
- The -e option or flag is used to show the email id of the author that has changed the specified file the last time. The git blame command does not show us the email id of the author by default.
- The -l option or flag is used to the full commit hash. The git blame command does not show us the full commit hash but shows only the abbreviated commit hash by default.
- The -L flag or option comes into the picture when we have a very large code file and we only want to check a certain range of the file. So, we can use the -L option and provide the range of tracks to Git.
- We use the --first-parent option or command to make Git only follow the very first of the parent for merging the commits when we are performing the blaming of the file.
- We use the -w option or flag to ignore the changes having only white space changes. This option comes in handy if the author has only added empty lines or switched tabs or added some white spaces then we can use it to ignore such changes.
- We use the -M option or flag to detect the copied or moved files within the same file. Hence, this command will not report to us the name of the last committed author but it will report to us the name of the original author whose files were moved or copied.
- We use the -C option or flag to detect the copied or moved files from different files. Similar to the last flag, this command will not report to us the name of the last committed author but it will report to us the name of the original author whose files were moved or copied.