Git Terminology
Overview
Git is a version control system that tracks the changes in the code, documents, and other important information regarding a certain code base (or project), etc. Git is free and one of the most widely used version control systems. We can use Git through the command line and its graphical user interface (GUI). The command line or terminal version of Git is known as Git Bash; the GUI version of Git is known as Git GUI. There are various key terminologies used in Git. Some of the important terminologies are: Git repository, Git working directory, Git remote repository, Branch, Blob, Tree, Commit, Clone, Fork, Merge, Pull, Push, Cherry-Pick, Fetch, etc.
Introduction
Git is free and one of the most widely used version control systems developed by Linus Torvalds in 2005. A version control system is a tool in software development that tracks the changes in the code, documents, and other important information regarding a certain code base (or project), etc. There are two types of Version Control systems: ' Centralized Version Control Systems (CVCS)andDistributed Version Control Systems (DVCS)`.
Git can extensively handle changes in small to very large projects. Git smartly monitors the changes in our project (whether small or large) and helps us keep track of these changes made in the source code of our project. Git saves the various versions of our project into a special folder named Git repository. The Git repository consists of files having different versions of the project. To make Git track a certain project, we must first initialize the project folder. After the initialization, Git starts tracking the project folder.
Let us look at some of the features of Git which make it one of the most widely used version control tools:
- Git is free and `open-source software, so anyone can use it for development.
- Git is used to track the changes made in the source code.
- Multiple users can work together using Git.
- We can create multiple branches in Git, which makes development easier.
- Git creates a backup of our project so that we can get the source code in case of data loss.
- Git allows multiple collaborators to work on a project.
- Git performs well when it comes to version control systems. It is comparatively faster than other version control systems.
- Git manages the versions of the directory and handles the security using the cryptographic method SHA-1.
- Git allows us to push the work to a central repository like GitHub.
- Git provides us with the facility of branching so that we can parallelly develop some parts of the project without hampering the original code base.
Basic Terms
Now that we are familiar with Git and its advantages let us learn some of the most useful and key terminologies used in Git.
Git Repository
A repository is a folder or directory that can store files of various types like (HTML files, CSS files, Python files, C++ files, images, documents, databases, etc.). We can also include a license and a README file that keeps the information about the repository. A repository can be compared with the normal file system in every operating system. The git repository has a structure similar to a directory of the operating system's file system.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Git Working Directory
As the name suggests, a git working directory is nothing but a directory containing all the files that Git tracks. Git will track all the files in the directory and update if any change happens.
Git Remote Repository
A repository hosted or stored on the remote server is known as a git remote repository. As we have compared a git repository with a file system, similarly, we can compare a git remote repository with the remote file system. A good example of a remote git repository can be GitHub. A remote repository helps us to help or host on a server which allows us to share our code and files easily with fellow developers. We have a remote server, GitHub, where we can host our local git repository. This will allow fellow developers to view our work. The other developers can contribute to our projects as our git remote repository (public) is visible. Hence, it supports community development and helps each other without any deed.
Branch
A branch is an independent line of development that adds certain features and fix bugs without hampering the main project. So, we can develop new features in parallel, and when the development is completed, we can add them back to the main project. By default, all the GitHub repository has the master branch, which can be used for production.
So, a new branch is a copy of the master branch, which is created for bug fixes and for the addition of new features. After the bug is fixed or new features are added, we can merge the branch to the master branch. The git branch command enables us to perform parallel development. The command can create, rename, list, and delete branches.
Command for Creating a New Branch
Command for Listing All the Branches
or
Git Tree-Related Terminology
Let us learn about Git objects and some key terminologies in the Git tree.
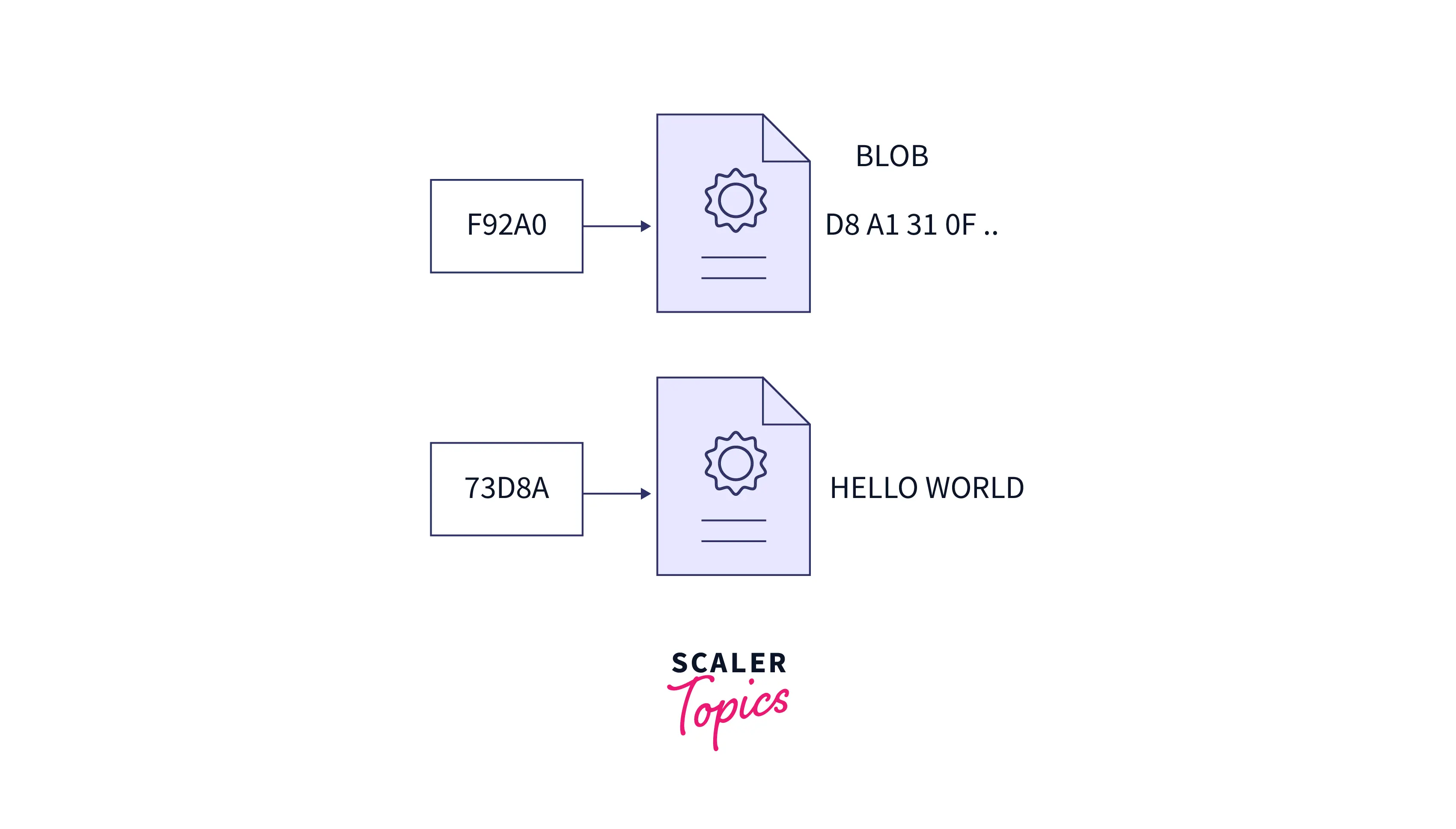
1. Blob
As we know, git stores the project's data in the .git folder. Blobs are similar to files, but Bob only stores the data, not the metadata (like the content of files, when it was created, etc.). In simpler terms, we can say that blobs are nothing but a stream of binary data. So a blob does not register the creation date, name, etc. Git manages the directory versions and handles the security using the cryptographic method SHA-1. Now blobs are identified using these SHA-1 hashes. The SHA-1 hash is a 20 bytes stream of data that usually represents the 40 characters in the hexadecimal form.
Please refer to the image provided below for more clarity.
2. Tree
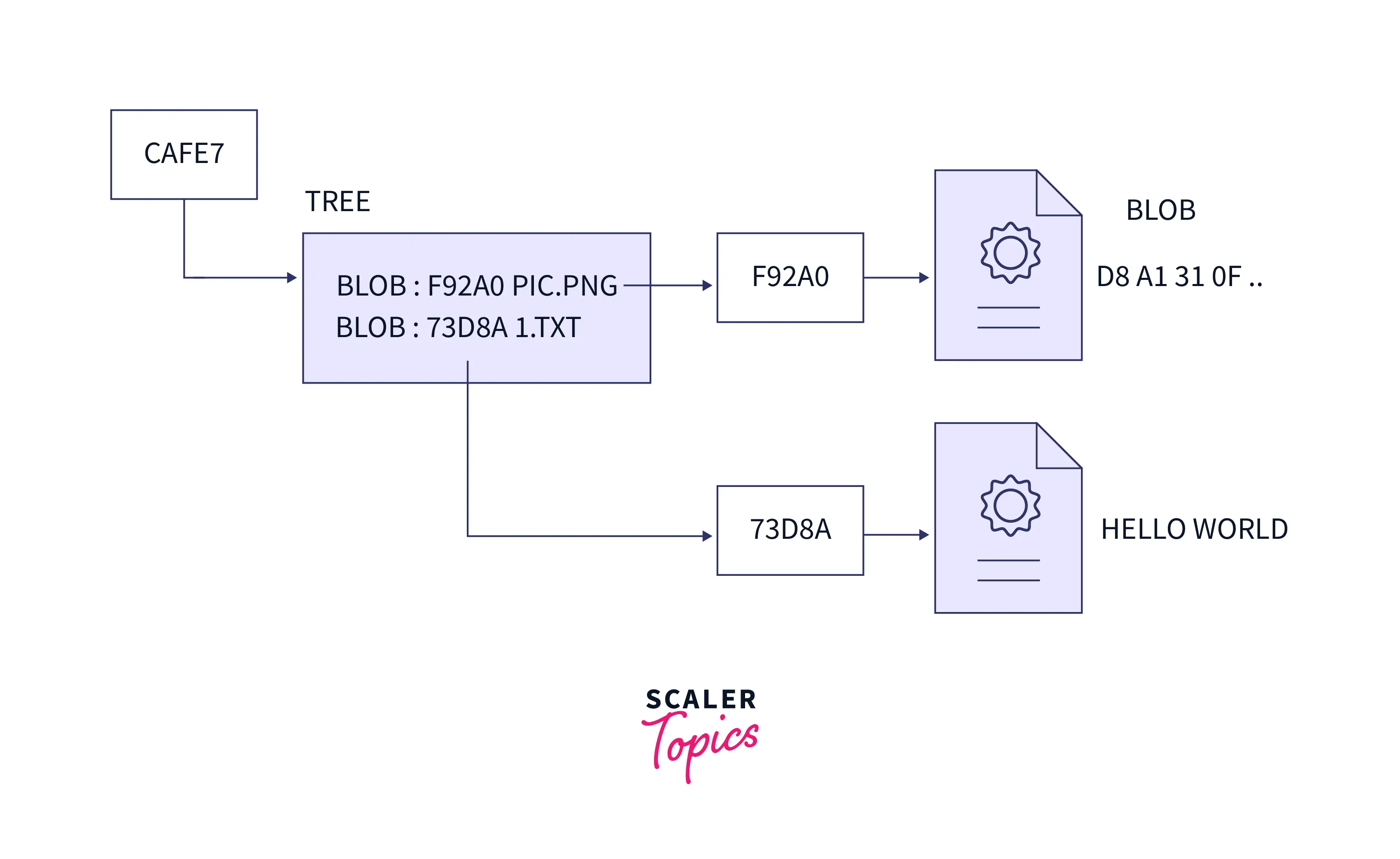
Now to understand trees in Git, we should be familiar with the concept of a directory in the operating system. A directory contains the hierarchal order of files and folders. A tree can be visualized as a directory that can be used for listing files, blobs, and other trees. Just like blobs, trees are also identified by SHA-1 hashes. We used these SHA-1 values to refer to the objects (blobs, files, and other trees).
Please refer to the image provided below for more clarity.






3. Commit
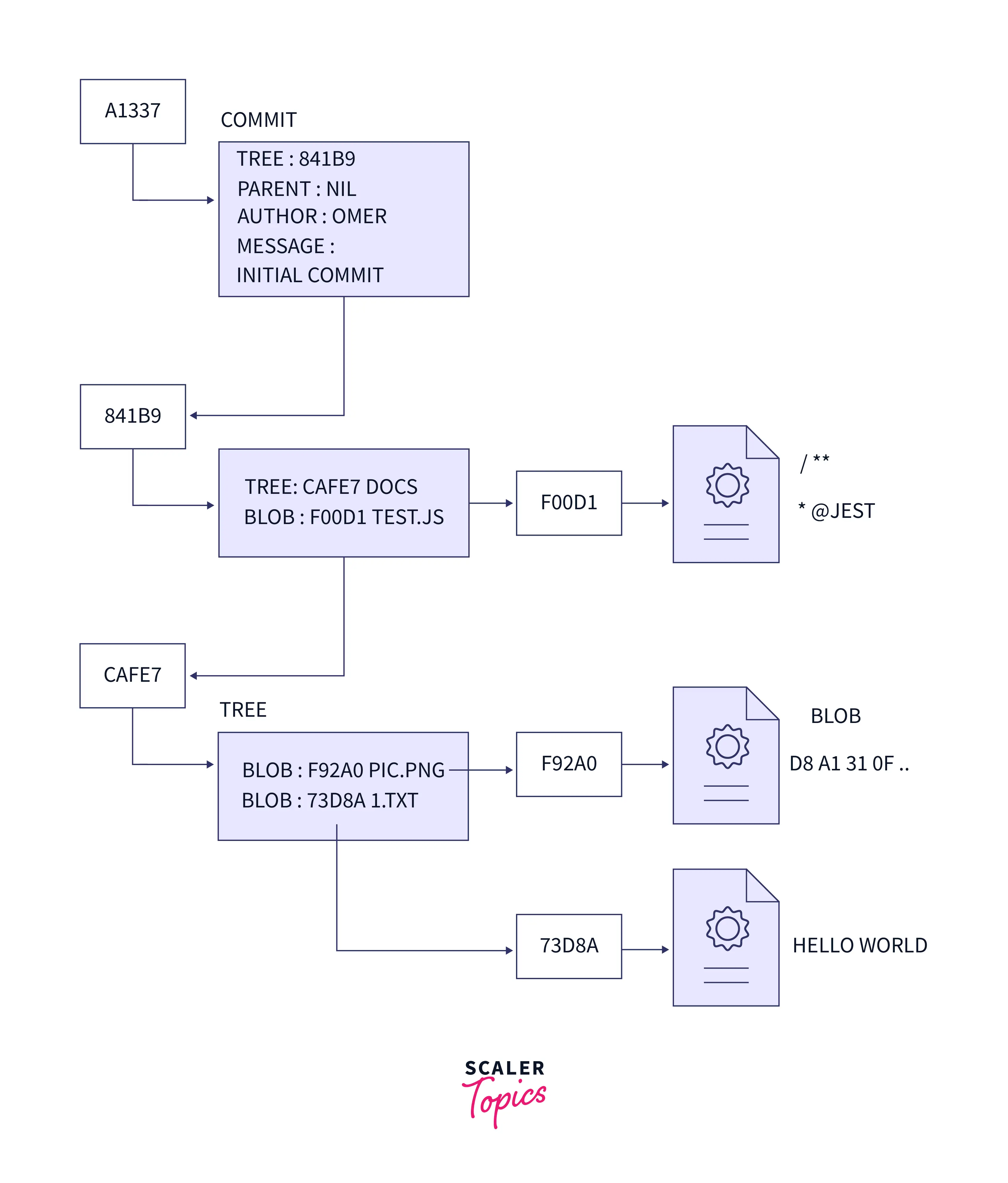
Git tracks the changes in a project and saves a certain state known as commit. A commit is a snapshot of the file's current version(s). It saves a log message and a unique commit id of the current modifications made to the git repository. When we use the git commit command, the changes are saved in our local system, along with a short message related to the commit is also stored, which is provided by the user along with the command.
So, we track these commits and can revert to a certain commit.
In simpler terms, we can say that the commit is the snapshot of the current working tree.
Please refer to the image provided below for more clarity.
Let us look at some of the most commonly used tags of the git commit command.
1. -m
The -m tag provides a commit message without opening the text editor prompt.
Syntax:
2. -a
The -a tag includes only the tracked files (those added using the git add command.)
Syntax:
3. --amend
Using the --amend tag, we can achieve a lot of functionalities like modifying the last commits and opening a system-specified text editor prompt.
Syntax:
4. -am
The -am tag combines the -a tag and -m tag. It allows us to add the commit message to the tracked files.
Syntax:
Commands
Let us now look at the various commands associated with git.
1. Clone
Suppose we want to clone some other developer's work (which is stored in the form of the central repository). In that case, we can use the sample command that is git clone repository, to copy the whole repository into our local system. Suppose we have developed a project and we have hosted the project on the remote repository (server), and the data on our local system got deleted due to some issue. Then we can easily clone our very own repository, and in this way, our data will always be stored in a safe place and will not be affected by any loss from the local system.
In the above command, git clone repository, we need to provide the address of the remote repository we want to clone. If we are using GitHub, there is a button called the clone button; we can get the repository's address by clicking on the button. After copying the repository's address, we will run the command on the Git shell, and Git will clone the central repository to our local system.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
2. Fork
In the above section, we have discussed the Git clone command, which is used to clone the remote repository to the local system; the Git fork command is quite similar to the Git clone command. We use the Git fork command to fetch the changes from the remote repository to the cloned local repository. We used the Git fork command in the development process in cases such as bug fixing, feature adding, etc. We first fork the repository; then, we run the repository on our local system for testing. After the testing, we make changes such as bug fixing or any extra addition of features then we push our changes to the forked repository.
Please refer to the later sections to learn more about Push and Pull requests.
Let us look at some of the differences between git fork and git clone.
- The git fork command creates an independent copy of our git repository; on the other hand, the git clone command creates a linked copy that will be used to synchronize with the target repository.
- Git fork is performed on GitHub, i.e. on the remote repository; on the other hand, the git clone command is performed on git only.
- Clone is a process of cloning a repository; on the other hand, forking is a concept of the development phase.
3. Merge
Git merge is used to merge multiple commits of various branches into a single branch. We perform branching for parallel new feature(s) development and bug fixing. Once the bug is fixed or the new feature is added, we can merge these into a single branch. The git merge command can also be considered an alternative to the git rebase command, used to merge branches. For merging branches, git takes the head points of the commits, and it will first find the common base commit among the branches and perform a merge commit to combine the changes of each commit sequence. There are five types of merges in git; they are: Fast Forward, Recursive, Ours, Octopus, Resolve, and Subtree.
The git merge command is also considered an alternative to the git rebase command. Now the major difference between the git rebase, and git merge is that when we perform git rebase, then the commits will be merged linearly; on the other hand, if we use the git merge command, then all the commits will be merged in a time altogether.
The various commands that are used in git merging.
The basic git merging command:
1. The command to merge a certain commit of the active branch.
2. The command to merge a certain branch.
4. Pull/Pull Request
In the above section, we have discussed Git clone and Git fork commands used to clone and fork the remote repository to our local system. Now, after cloning and forking, the Pull request command comes into the picture. We make Pull requests after changing the local repository. We ask the repository maintainer to merge our branch (containing changes) to the working remote repository by creating the pull request. The reviewer or the maintainer checks our changes and then merges the branch into the main branch using the Merge command we discussed in the above section.
5. Push
As the name suggests, the Push command is used to push our local system repository (or any changes in the local system repository) to the remote repository. The Git push command takes two arguments. The first is the repository, and the other is the branch name to which we are pushing the changes.
The commands- Git clone, Git fork, Git pull, and Git push- are used frequently when working on the repository hosted in GitHub.
Let us look at some of the differences between push and pull commands in git.
- The git push command asks the maintainers to update their branch by our commit; conversely, the git pull command gets our commit and updates our branch.
- The git pull command fetches the changes from the GitHub repository to our local repository and merges them. On the other hand, the git push command only sends our commits history from the local repository to GitHub (central repository).
6. Cherry-Pick
If we want to cherry-pick a change from one branch to another, we use the cherry-pick command. We generally use the cherry-pick command to pick the changes to form the testing branch (beta-branch) to the master branch (master or main project). We can analyze the cherry-pick command as copying the old changes from one branch to another.
7. Fetch
Suppose the developers have made changes on the central repository (remote); then we need to fetch those changes to our local repository, so the Git fetch command is used. The Git fetch command downloads the changes into a file along with all the commits of the changes. We use the command git fetch -all to fetch all the changes in the local repository's branches.
Turn Learning into Career Growth
HEAD, Index
As we know that a commit is the snapshot of the current working tree. Now head can be referred to as a pointer that resembles the topmost commit of a branch in a certain repository. Irrespective of the current state of the repository or the branch, the most recent commit that we have made is termed the HEAD of the repository. Whenever we make a new commit, the latest commit becomes the HEAD of the branch.
Please refer to the image provided below for more clarity.
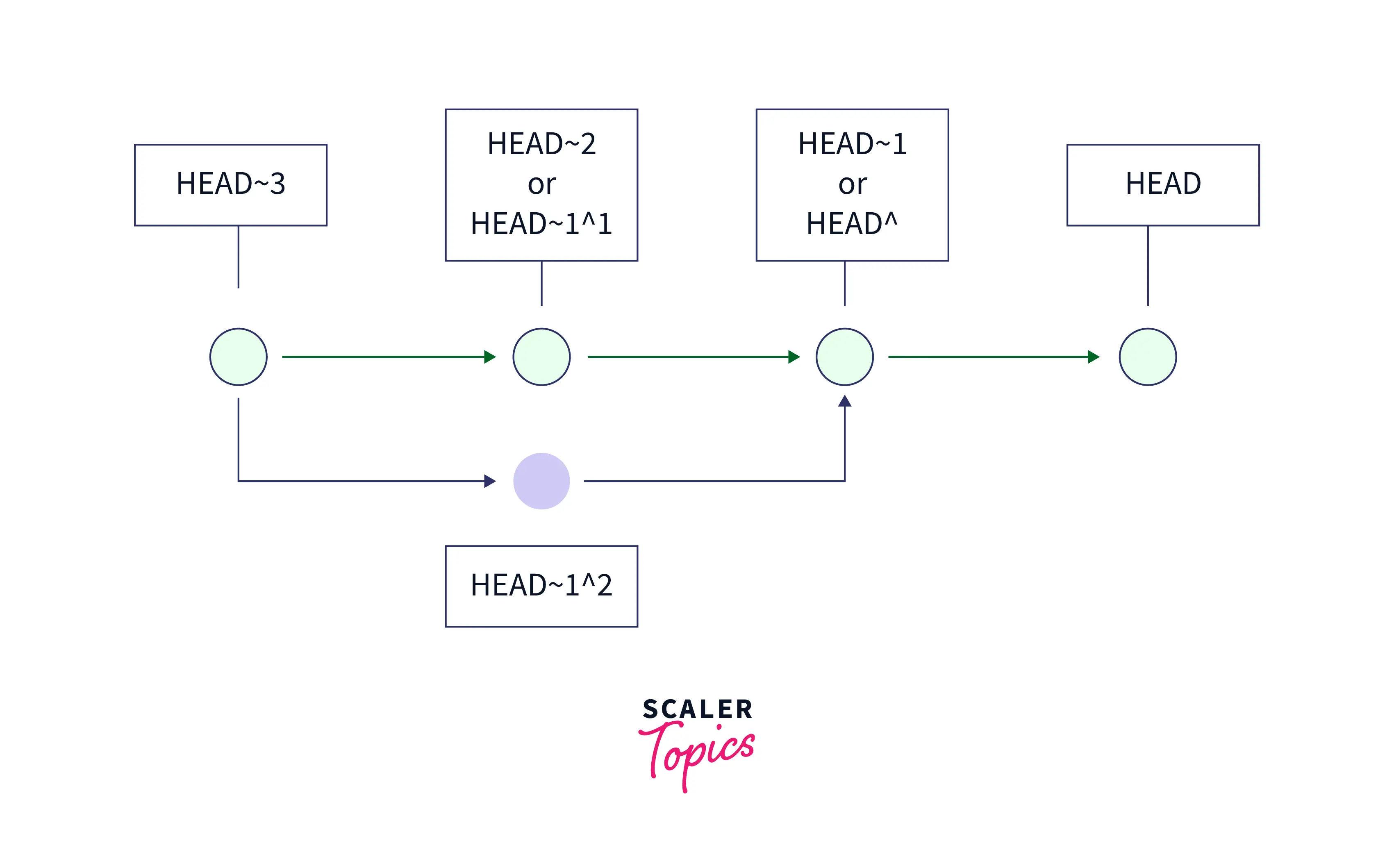
An index is used between the working directory and the local git repository. An index is made in cache memory that allows us to logically list all related modified files that are to be committed together. An index is a simple overview of the files that constitute the latest commit. We use an index to select a bunch of files from the list of modified files (present in the working directory) and then perform a commit using an appropriate commit message.
If we do not use an index, all the modified files in the staging area are committed simultaneously. So we use an index for progressive commits.
Let us now look at some of the differences between HEAD and index in Git.
- The HEAD pointer points to the last commit of the branch. On the other hand, the index is a space in the staging area where the preparation of new commits happens.
- We use the index to populate the list of files we last checked out in our working directory. On the other hand, HEAD is a snapshot of our last commit on a specific branch.
- The index is used in case of commits; however, HEAD comes into the picture after creating a commit.
Revert and Reset
Revert and Reset are grant access commands. The git revert command is used to revert from a commit. We can visualize the git revert command as the undo command used in various areas.
On the other hand, the git reset command is used to reset the changes made in the working tree of a repository. The git reset command changes the indexing as well as the working tree.
Refer to the later section for more details about the reset command.
Upstream/Downstream
Suppose that we have made some changes in the local repository and we want to send those changes to the project for merging; this sending of changes to the remote repository's main branch is termed upstream in git.
Similarly, if we are downloading or cloning the repository, the information flows from the remote repository to the local repository, i.e., downstream. This downloading or cloning of the remote repository is termed downstream in git.
Git Diff
As the name suggests, diff stands for the difference. The git diff command determines the difference between the index and the working tree. In simpler terms, we can say that the git diff command shows the difference between the head and the index.
The git diff command shows us the changes staged for the commit.
Squash
The git squash command helps us combine two or more commits into a single commit. It also allows us to specify a new commit message to the changes. The git squash command squashes two or more commits to the index of the working repository. For squashing, the command picks are the previously made commit, and the newly made commit. We can say that the git squash command groups all the changes before merging them.
In scenarios with multiple commits, we can use the git squash commands to squash them into a single commit.
Rebase
The git rebase command is used to move the feature branch to the tip of the master branch. The git rebase command is an alternative to the git merge command, which is also used to merge or combine two branches. The git rebase command merges the commits linearly; on the other hand, the git merge command will merge the commits in a time.
Git also provides an interactive merging. The git interactive rebasing is a tool that is used to edit, reorder, rewrite, etc. the current commits. We can only perform the interactive git rebasing on the current branch. The rebase command will check the root commit and perform a series of commits, one after the other, at the tip of the master branch commit. Git also provides us with the advanced rebasing option; we can use the --onto command along with the rebase to activate a more powerful git rebasing.
Git rebase is a crucial command mainly used in the development phase. As we have discussed, we create branches to perform parallel development. Now once the development is done, we commit the changes. We use the git rebase command to merge these commits at the master branch's tip.
Various commands associated with the git rebasing are:
Now if we want to continue with the changes made, then we can run the command:
On the other hand, if we are not happy with the current change and we want to ship this change, then we can run the command:
Remove
Remove or git rm command is used to remove the files from the index of the current working directory. The git rm command removes the files from the index, the working tree, and the git repository. The git rm command is one of the most powerful commands for removing directories and files from a git repository.
Reset
The git reset command is used to reset the changes made in the working tree of a repository. The git reset command changes the indexing as well as the working tree.
The git reset command deals with the index and working tree and resets the head pointer to the previously made commit. There are three forms of the git reset command, and depending on the command type, the resetting is made.
The first form of the git reset command is a soft reset. Only the reference pointer is reset when we pass the -soft flag with the git reset command.
The second form of the git reset command is a hard reset. Unlike the soft reset, the hard reset resets almost everything, like resetting the staging index and resetting to the specified commit. We generally use the hard reset command at the time of merge conflict. We use the -hard to mention the hard reset.
The third and last form of the reset command is mixed reset. We can achieve the mixed reset using the -mixed flag. Only the pointers are updated in mixed reset, and the staging index is reset to a specified commit.
Conclusion
- Git is a version control system that tracks the changes in the code, documents, and other important information regarding a certain code base (or project), etc. There are various key terminologies used in Git.
- A repository is a folder or directory that can store files of various types.
- A git working directory is nothing but the directory containing all the files that Git tracks. A repository hosted or stored on the remote server is called a git remote repository.
- A branch is an independent line of development used to add certain features and fix bugs without hampering the main project.
- Git tracks the changes in a project and saves a certain state known as commit. A commit is a snapshot of the file's current version(s).
- The git fork command creates an independent copy of our git repository; on the other hand, the git clone command creates a linked copy that will be used to synchronize with the target repository.
- Git merge is used to merge multiple commits of various branches into a single branch.
- The git push command asks the maintainers to update their branch by our commit; conversely, the git pull command gets our commit and updates our branch.
- The git fetch command downloads the changes into a file along with all the commits of the changes.
- The HEAD pointer points to the last commit of the branch. On the other hand, the index is a space in the staging area where the preparation of new commits happens.
- The git revert command is used to revert from a commit. The git reset command is used to reset the changes made in the working tree of a repository.
- The git diff command determines the difference between the index and the working tree.