How Does Git Work?
Git, developed by Linus Torvalds in 2005, is a free, open-source distributed version control system, contrasting with older centralized systems like SVN and CVS. Its distributed nature means developers possess a complete local history of their repositories. While initial cloning might be slower, subsequent operations like commit, merge, and log are notably faster. Git excels in supporting features like branching, merging, and history rewriting, paving the way for innovative workflows like pull requests that enhance team collaboration and code review processes. Despite its widespread adoption in software development, many developers only scratch the surface, relying on GUI clients or IDE integrations without delving into Git's intricacies.
Understanding Git's backend operations is crucial; lack of depth might lead to unforeseen challenges. This overview draws inspiration from a course on collaborative Git usage, emphasizing the importance of grasping its internal workings. While not a comprehensive Git tutorial, this insight aims to illuminate the mechanics behind Git's functionality.
Stages in Git
The stages in Git can be classified into three: Modified Stage, Staged State, and Committed Stage.

Let's take a simple example to understand these stages.
-
Modified Stage - You have your final assignment coming up, and you start gathering notes. You take every good note available from your friends. That is, you're modifying your collection of notes.
This is what the modified stage in Git is. In this stage, you make changes to your files but don't save them. This is the preparation stage, just like the days before your exam.
-
Staged State - This is the stage where you have finalized the notes and saved them in a place. You filter out the pages and remove the redundant ones.
In this stage, your files are ready to be committed to the GitHub repository. Git does not commit these files and only adds them in the staging area. In this stage, you can still modify your files and then add them again in the staging area. These files are still not committed, and they are prepared to be committed to Git.
-
Committed Stage - This is the final stage where you use your documents in action, i.e., submit your assignment to your teacher. Your teacher will keep a record of these files just like Git.
In Git, the committed stage is where you save your files to Git, just as your teacher saved your documentation. Commit messages are also necessary to describe what changes you have made to your code or what new features you have added. Also, it is recommended to write a descriptive commit message to understand more about the changes in the future.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
How Git Keeps Track of Our Files (SHA)
A Git project involves many moving parts, and we often work with multiple files at once. Git creates something called the Secure Hash Algorithm (SHA) to keep track of all the files. The SHA is a series of cryptographic hash functions. Each commit is assigned an SHA hash function. Due to this, duplicate files can be identified more easily and given the same identifier as the original files, thus saving storage space.
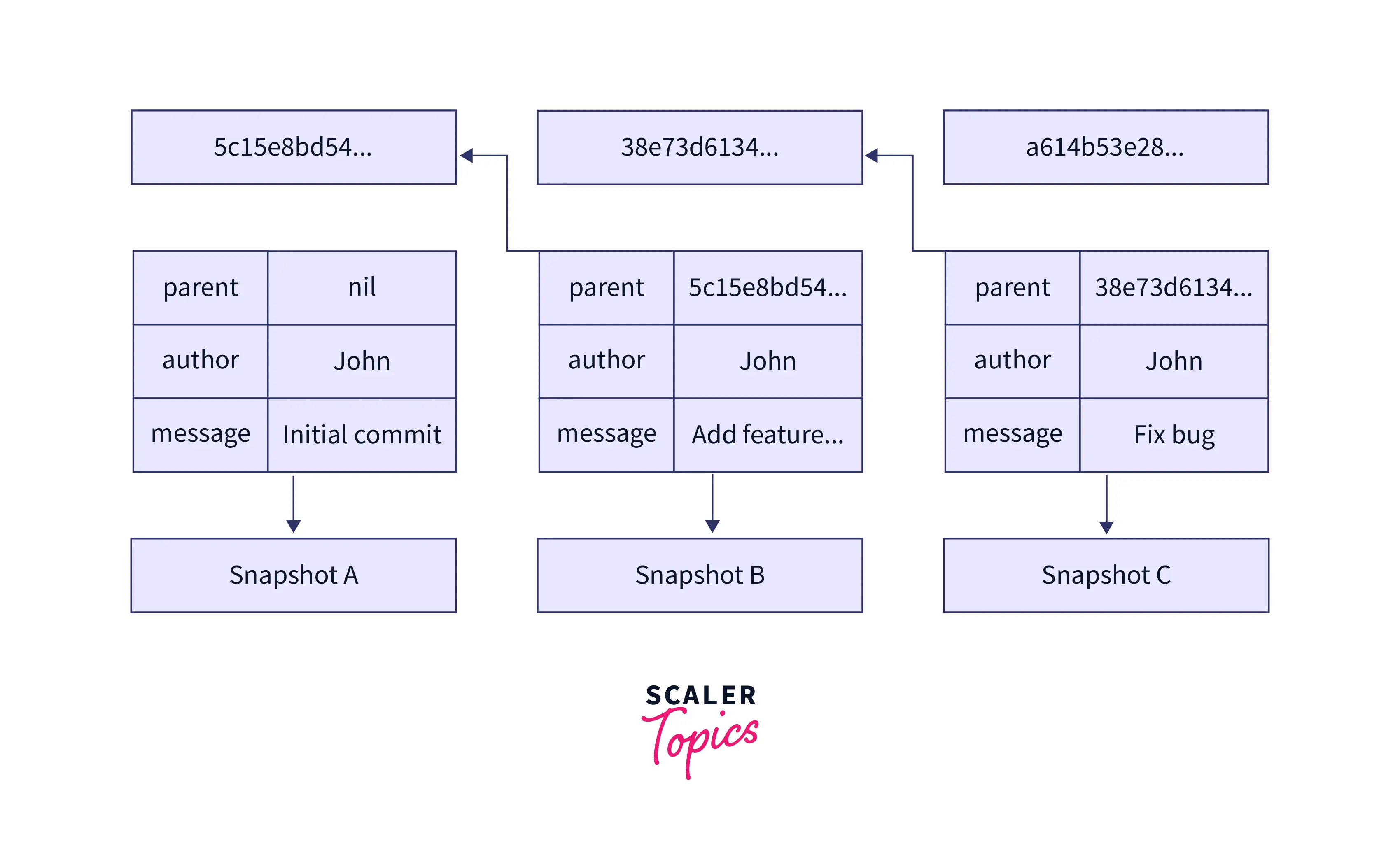
With SHA, referencing in Git becomes easier, such as searching for a commit, modifying those files, or reverting the changes.
Your HEAD must be pointing at the latest commit on the main branch or master branch when you start a project. Except for the initial commit, every commit has a parent commit.
Each commit is assigned SHA numbers. Creating a branch creates a copy of your files. And when you switch between branches, the HEAD will now point to the latest commit of the switched branch.
It is called headless or detached HEAD when a branch has been deleted. If we don't have their hash, we can't access them. In addition, there is no HEAD pointing at them, so we need their hash to access them. It is also possible to check them out as individual branches so that we can still have access to them.
Git has no access to any of the commits in the previous branch if we switch from one branch to another.
Git Internals
When you initialize Git in a project, you will see a directory as .git. This contains all the internals contents of .git - objects, refs, HEAD, config.

Let's have a look at each one of them.
- objects: All the repos files are stored in this directory, which acts as a database. Encoding and compression are used to protect their content.
- refs: Under the .git/refs directory, references are stored as normal text files containing pointers to commit objects. The hash of an object is necessary if you need to modify it. The hashes are difficult to remember, so Git provides references. Hashes of commit objects are stored in these refs.
- HEAD: In this file, you can find the path to the reference that points to the current branch you are working on.
- config: This file contains the repository configuration.
- branches: This is a slightly deprecated way to store shorthands for specifying URLs for git fetch, git pull, and git push. You can store a file as branches/<name>, and then the name can then be used instead of the repository argument.
- hooks: The hooks are customized scripts used by many Git commands. As a default, git init will install a handful of sample hooks, but all of them will be disabled.
- info: A directory containing additional information about the repository can be found here.
- remotes: Contains shorthand for URLs and default refnames used when fetching, pulling, and pushing remote repositories.
- logs: This directory stores information about changes to refs.
Git Workflow
A Git workflow is a guide or prescription for using Git to do tasks consistently and effectively. Git workflows empower DevOps teams and developers to use Git efficiently and regularly. Git gives users a great deal of latitude in how they handle changes. Git places a strong emphasis on flexibility. Thus there isn't a set way to work with it. Make sure the team is in agreement on how the flow of changes will be implemented while working with a team on a Git-managed project. An established Git process should be created or chosen to make sure the team is on the same page.'
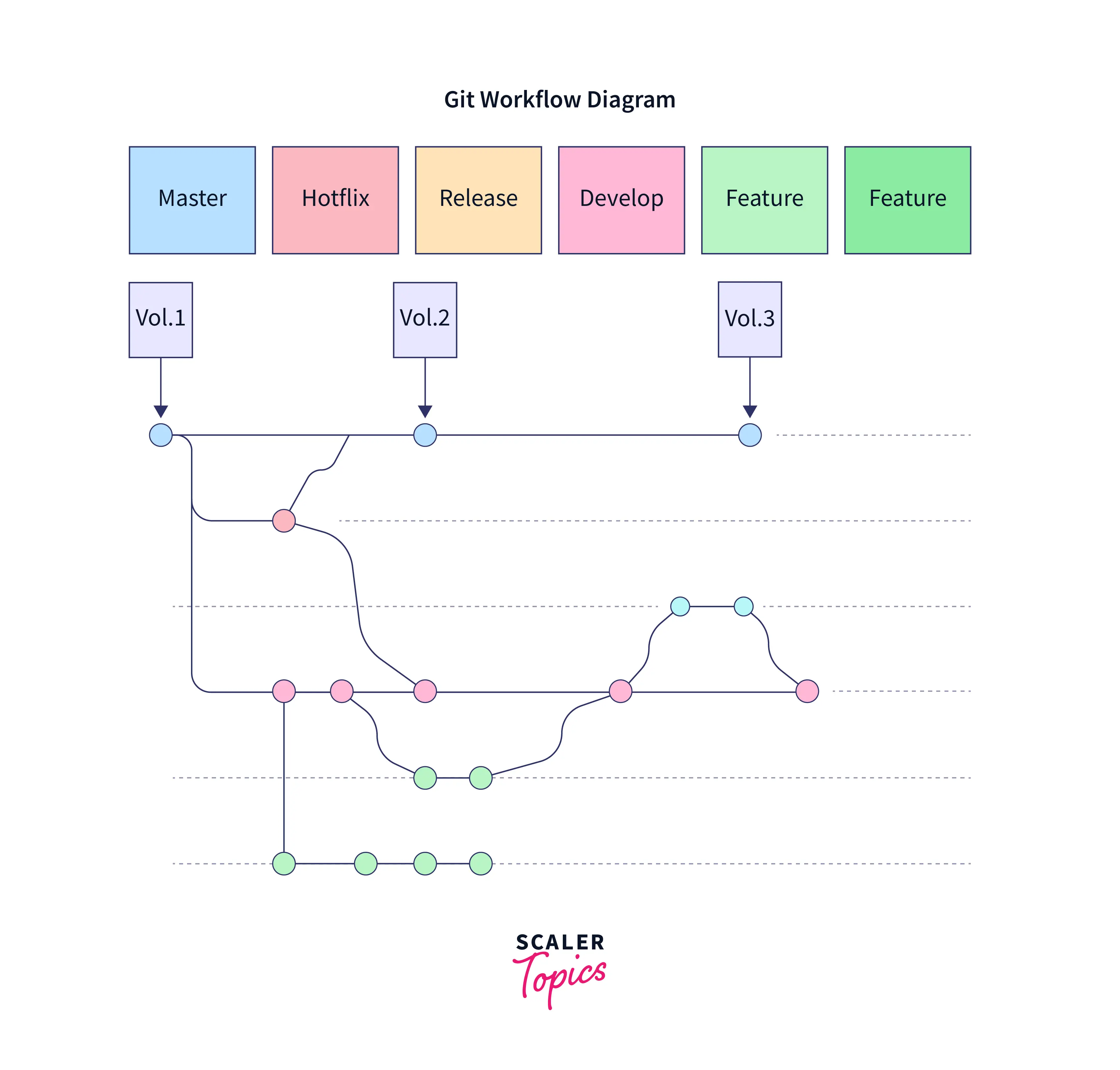






How Does It Work?
The first step for developers is to clone the main repository. They edit files and make changes in their local copy of the project as they would with SVN, but these new commits are saved privately and are entirely separate from the main repository. This allows programmers to put off syncing upstream until an appropriate breakpoint. Developers "push" their local main branch to the central repository to make updates to the official project. Similar to the svn commit, however, it adds all local commits that aren't already in the main branch in the central repository.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Initialize the Central Repository
The central repository must first be set up on a server by someone. You can initialize an empty repository if the project is new. Otherwise, you'll need to import a Git or SVN repository that already exists.
The following steps may be used to establish bare central repositories, which are repositories without a working directory.
Use a legitimate SSH identity for the user, your server's domain or IP address for the host, and the place where you want to keep your repository for /path/to/repo.git. Keep in mind that the repository name often has the .git prefix added to signify that it is a bare repository.
Hosted Central Repositories
Using third-party Git hosting services like Bitbucket Cloud or Bitbucket Server, central repositories are frequently set up. The hosting service takes care of the initialization of a basic repository described above for you. Using the address provided by the hosting service, your local repository can connect to the central repository.
Turn Learning into Career Growth
Clone the Central Repository
The complete project is then locally copied by each developer. The git clone command is used to do this:
A shortcut named origin is created by Git when you clone a repository because it anticipates that you'll want to connect and interact with the "parent" repository.
Make Changes and Commit
Once a repository has been locally cloned, a developer can make changes by editing, staging, and committing. The staging area lets you make changes without having to include them in the working directory before committing. This enables you to produce commits that are very focused, even if you've made several local modifications.
Remember that John may repeat this procedure as many times as he likes without being concerned about what is happening in the main repository because these commands make local commits. When huge features need to be divided up into smaller, more atomic parts, this may be quite helpful.
Push New Commits to Central Repository
Newly committed modifications to the local repository. To communicate with other project developers, these changes will need to be pushed.
By using this command, you may push fresh committed changes to the main repository. It is conceivable that while pushing updates to the main repository, updates from another developer may have already been pushed that contain code that conflicts with the updates that are being made. Indicating this dispute, Git will emit a notice. It will be necessary to first run git pull in this case. In the part that follows, this conflict scenario will be further developed.
Managing Conflicts
The developer must download the most recent central commits and rebase their modifications on top of them before publishing their feature. To say anything similar would be to say, "I want to add my adjustments to what everyone else has done." The outcome is a history that is fully linear, just like in conventional SVN operations.
Git will halt the rebasing process and offer you a chance to resolve conflicts manually if local changes directly clash with upstream contributions. Git's usage of the same git status and git add tools for both creating commits and resolving merge conflicts is a useful feature. New developers may easily handle their own merges as a result.
Conclusion
- By now, you may have a better understanding of Git's importance in the life of a programmer. The tool makes life much easier for software developers and saves you time.
- In Git, developers can keep track of their projects' changes using a distributed version control system.
- The stages in Git can be divided into three stages: Modified Stage, Staged State, and Committed Stage.
- In modified stage, you can add or delete your files, whereas in staged stage, you add these files to Git without committing them and in committed stage, you save your files in Git, i.e., commit them.
- Each commit is assigned an SHA hash function.
- .git file contains all the internals contents of .git - objects, refs, HEAD, config.