Hadoop Streaming
Hadoop Streaming, a versatile feature since Hadoop 0.14.1, empowers developers to write MapReduce programs in languages like Ruby, Perl, Python, C++, and more without being confined to Java. This utility leverages UNIX standard streams, allowing any program that reads from standard input (STDIN) and writes to standard output (STDOUT) to act as mappers or reducers. With Hadoop Streaming, non-Java developers find an accessible path to process vast amounts of data using familiar tools and languages, enhancing the Hadoop ecosystem's flexibility and inclusivity.
How Hadoop Streaming Works
Hadoop Streaming works by using Unix pipes to connect the output of a mapper or reducer written in a non-Java language to the input of the next stage in the MapReduce pipeline.
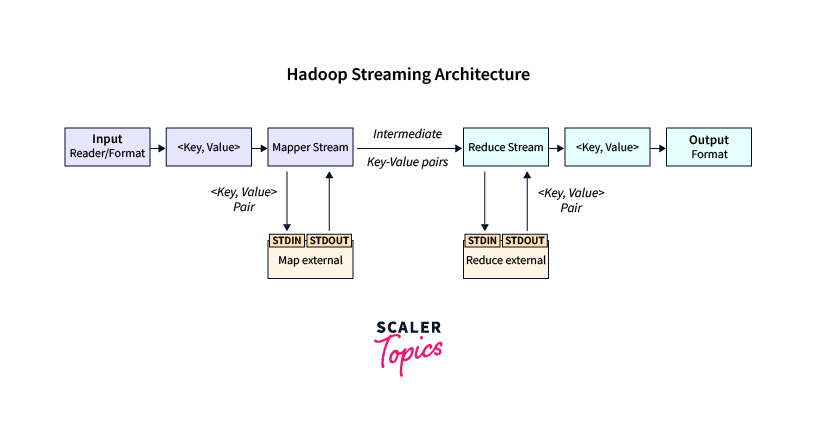
The six steps involved in the working of Hadoop Streaming are:
- Step 1: The input data is divided into chunks or blocks, typically 64MB to 128MB in size automatically. Each chunk of data is processed by a separate mapper.
- Step 2: The mapper reads the input data from standard input (stdin) and generates an intermediate key-value pair based on the logic of the mapper function which is written to standard output (stdout).
- Step 3: The intermediate key-value pairs are sorted and partitioned based on their keys ensuring that all values with the same key are directed to the same reducer.
- Step 4: The key-value pairs are passed to the reducers for further processing where each reducer receives a set of key-value pairs with the same key.
- Step 5: The reducer function, implemented by the developer, performs the required computations or aggregations on the data and generates the final output which is written to the standard output (stdout).
- Step 6: The final output generated by the reducers is stored in the specified output location in the HDFS.
The distributed nature of Hadoop enables parallel execution of mappers and reducers across a cluster of machines, providing scalability and fault tolerance. The data processing is efficiently distributed across multiple nodes, allowing for faster processing of large-scale datasets.
Hadoop Streaming Commands
To execute Hadoop Streaming jobs, you need to use the hadoop jar command and specify the streaming JAR file along with the necessary input and output paths. The streaming JAR file contains the required libraries and classes that enable the interaction between the Hadoop framework and the non-Java programs used as mappers and reducers.
Syntax:
Explanation:
- hadoop-streaming.jar The Hadoop Streaming JAR file.
- <input_path>: Input path in the Hadoop Distributed File System (HDFS)
- <output_path>: Output path in the HDFS.
- <mapper_command>: Commands or scripts to be used as the mapper.
- <reducer_command> Commands or scripts to be used as the reducer.
Streaming Command Options
Hadoop Streaming provides several command options to customize job execution.
| Option | Explanation |
|---|---|
| -inputformat | The input format class. |
| -outputformat | The output format class. |
| -numReduceTasks | Number of reducer tasks. |
| -partitioner | the partitioner class. |
| -combiner | The combiner command or script. |
| -input | The input path for the MapReduce job. |
| -output | The output path for the MapReduce job. |
| -file | Includes additional files with the job submission. |
| -mapper | The mapper command or script. |
| -reducer | The reducer command or script. |
| -cmdenv | Sets environment variables for the streaming tasks. |
| -inputDelimiter | The input delimiter for splitting lines into key/value. |
| -outputDelimiter | The output delimiter for key/value pairs. |
| -numMapTasks | The number of mapper tasks. |
| -cacheFile | The files to be cached on the cluster. |
| -cacheArchive | The archives are to be cached on the cluster. |
Let us explore the following options in this section:
- Using a class as -mapper and -reducer options.
- Packaging with -file option.
- The -combiner option is used with the -inputformat and -outputformat options.
- The -cmdenv option for environmental variables.
Specifying a Java Class as the Mapper/Reducer
We can also use Java classes as mappers and reducers by specifying the Java class name in the command.
Syntax:
Example:
Let's consider we have a Java class named WordCountMapper as the mapper and WordCountReducer as the reducer. These classes implement the logic for counting the occurrences of words in a given text.
Output:
Explanation:
- Map input records: Total number of records read by the mapper.
- Map output records: Total number of intermediate key-value pairs emitted by the mapper.
- Map output bytes: Total size of the data output by the mapper in bytes.
- Reduce input groups: Number of unique keys (words) received by the reducer.
- Reduce shuffle bytes: Size of the intermediate data transferred during the shuffle phase.
- Reduce input records: Total number of key-value pairs received by the reducer.
- Reduce output records: Final output records generated by the reducer.
- Spilled Records: Number of records written to disk during the MapReduce job execution.
- Shuffled Maps: Number of mappers whose output was shuffled.
- Failed Shuffles: Number of shuffles that failed.
- Merged Map outputs: Number of map outputs merged during the shuffle phase.
- GC time elapsed (ms): Time taken by the garbage collector during the job execution.
- Total committed heap usage (bytes): Total amount of heap memory used during the job.
In this example, output will be stored in the /wordcount_output directory in HDFS. It will contain the word as the key and its corresponding count as the value.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Packaging Files With Job Submissions
To include additional files with your job submission, such as libraries or configuration files, we can use the -file command option.
Syntax:
Example:
Let us package a Python script named my_mapper.py and a configuration file named my_config.properties with the Hadoop Streaming job.
Output:
The output will be the word count of the words in the input file and will be stored in the /output file in HDFS.
Explanation:
The my_config.properties is the configuration file which has properties that can be accessed during data processing. The following is the my_config.properties file,
The my_mapper.py file performs the following,
- Use the configparser library to read the configuration properties from my_config.properties.
- The mapper() function reads input from standard input.
- Splits each line into words, and emits key-value pairs for each word with the specified delimiter.
The following is the my_mapper.py file,
The /input_data.txt represents the input file path in HDFS.
Specifying Other Plugins for Jobs
Hadoop Streaming also supports plugins, such as combiners, partitioners, and input/output formats.
Syntax:
Example:
Explanation:
- combiner_script.py: Reduces the amount of data sent to the reducer by combining intermediate results locally, hence optimizing the data flow.
- com.example: Package name of the java classes.
- com.example.CustomInputFormat: Provides logic for reading input data and splitting it into input splits.
- com.example.CustomOutputFormat: Provides logic for writing the output data, validating the output specifications, and implementing the output committer which performs the final commit of the job output.
Setting Environment Variables
Hadoop Streaming enables you to set environment variables for your streaming tasks by using the -cmdenv option.
Syntax:
Example:
Explanation:
In this example, we will implement a word count program to count the number of a particular word repeated in the data.
- CUSTOM_VARIABLE: Desired word to be counted. The value Hello is set as a system environmental variable specified by this name.
The mapper_script.py file is,
The above file, reducer_script.py performs the following functions,
- Retrieves the value of the CUSTOM_VARIABLE environment variable from the operating system using the os library.
- Reads the key-value pair from the standard input, which is the output generated by the mapper.
- Compares the keys or words with the environmental variable and uses the word_count variable to keep track of the count.
- Outputs the word count.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Generic Command Options
Hadoop Streaming provides various generic command options to control job execution and define specific behaviour.
Here's a tabulation of some generic Hadoop commands with their names and explanations:
| Command | Explanation |
|---|---|
| conf | Displays the configuration values |
| fs | Provides namenode details for connection |
| D | Sets the Hadoop configuration option |
| jt | Connects to the JobTracker |
| files | Specifies files to be copied to the MapReduce cluster |
| archives | Specifies archives to be unarchived and made available |
| libjars | Specifies JAR files to be added to the classpath |
Specifying Configuration Variables with the -D Option
The -D option allows you to specify custom configuration variables for your streaming job.
Syntax:
Turn Learning into Career Growth
Specifying Directories
- Hadoop Streaming allows directories as input or output paths.
- When a directory is specified as the input or output all files within that directory are processed.
Syntax:
Explanation:
- dfs.data.dir Local directories where Hadoop DataNodes store the data blocks of HDFS.
- cluster.local.dir: Local directory on each node used for general temporary storage during job execution, where temporary files, logs, and other job-related data are stored.
- mapred.local.dir: Specifies the local temporary directories used by individual tasks (mappers and reducers) during job execution.
- mapred.system.dir: Directory where Hadoop stores system-related files, including job-specific configuration files and framework-level data.
Example:
Specifying Map-Only Jobs
If we only need the map phase of a MapReduce job and don't require any reduction step, we can use the -D option provided by Hadoop Streaming to set the configuration.
Syntax:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Specifying the Number of Reducers
We can specify the number of reducers using the -numReduceTasks option or the -D option. This allows you to control the parallelism and resource allocation for the reduction phase.
Syntax:
Example:
Explanation:
- By default, if the mapreduce.job.reduces option is not specified, the job will have a single reducer.
- It is preferred to increase the number of reducers to improve parallelism and distribute the workload.
Customizing How Lines are Split into Key/Value Pairs
We can customize the delimiters used for splitting key-value pairs using the -inputDelimiter and -outputDelimiter options to match your data format or the -D option to configure the system configurations.
Syntax:
Example:
Explanation:
- By default, Hadoop Streaming uses a tab (\t) as the separator to split lines into key/value pairs.
- The keys can be composite keys containing multiple fields. The stream.num.map.output.key.fields is used to inform the framework about the structure of the map output keys.
- The stream.map.output.field.separator option specifies that the lines should be split into key/value pairs using a comma(,) as the separator.
Working with Large Files and Archives
Hadoop provides the -files and -archives options to assist in managing and making these files available to the job.
Making Files Available to Tasks
The -files option allows you to specify additional files that need to be made available to the mappers and reducers during job execution. These files can be either local files or in HDFS as these files gets automatically copied.
Syntax:
Explanation:
-
<file1>: Represents the path to the file that you want to include in the job.
-
The file will be available in the current working directory of the mappers and reducers.
Making Archives Available to Tasks
You can also make archives or compressed files using the -archives option. Archives can contain multiple files along with this you can specify archive files, such as .tar.gz or .zip files, that need to be unarchived.
Syntax:
Explanation:
Hadoop automatically unarchives the specified archive files. You can access the unarchived files using their names or the symbolic link names, if specified.
Conclusion
- Hadoop Streaming is a component of Hadoop that allows users to create and run MapReduce jobs using scripts or commands in different programming languages.
- Hadoop Streaming supports various command options for customization, such as specifying Java classes, packaging files, setting environment variables, and more.
- The -D option is used to set configuration variables for specifying directories, creating map-only Jobs, fixing the Number of Reducers, customization of how lines are split into key/value pairs, and much more.
- Working with large files and archives is performed through the -files and -archives options, enabling the distribution of resources across the cluster.