Topics, Partitions, Replicas, and Offsets
Overview
Apache Kafka is an open-source, distributed, publish-subscribe event-driven messaging system. Kafka Topics, Kafka Partitions, and Kafka Offsets play a crucial role in Kafka architecture. Everything related to Kafka be it scalability, durability, message movement, or high performance is contributed by these three components of Kafka. In Apache Kafka, all the messages written in the partitioned log commit model, reside inside the Topic, which can be further divided into partitions. In the partitions, each of the messages will have a specific ID attached to it called the Offsets.
Introduction
Apache Kafka is an open-source, distributed, publish-subscribe messaging system. But there is more to it. When we go deeper into Apache Kafka we often hear terms like partitions, offsets, events, etc. It is very important to understand how the messages in Apache Kafka are stored, what contributes to the scalability, how the replication lays its role, along with the process in which the data records movement. Mostly you will hear, the partitions, which play a critical role in the structural perspective of Kafka storage, along with the processes related to producing and consuming the messages. Hence, if you understand the role of Kafka Topics, Kafka Partitions, and Kafka Offsets in Kafka architecture, all questions around Kafka are mostly solved.
3 Most Important Components of Apache Kafka
As we know that Kafka is an open-source, distributed, publish-subscribe messaging system. You can easily send your message in the Kafka partitioned log commit model, where these messages can be turned feed between processes, systems, clusters, and servers. The three most important components that make up the Apache Kafka architecture are:
- Topics
- Kafka Partitions
- Kafka Offsets
Topics
To start with, the Kafka topic can be defined as a division implemented for classifying messages or data records. The topic name is unique across the entire Kafka cluster. This means that messages are read and sent from defined Kafka topics only. So consumers read data from topics and producers are writing the data to topics. This is analogous to the table we have inside the database in a traditional RDBMS system. So, as we have multiple tables inside a single database, similarly we can have multiple topics inside Apache Kafka. The number of topics is not limited and can be easily identified by their unique name.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Kafka Partitions
Now we have the topics inside Apache Kafka. These topics are split into various segments known as Kafka partitions. Users need to specify the number of partitions it wants to create in a Kafka topic. Though the number of partitions is not limited it is seen that more partitions are often seen when you have a high throughput system.
Kafka Offsets
Once the topics are split into various Kafka partitions in Apache Kafka, each of the partitions needs to be assigned a defined ID to it so that it is easier to recognize in a specific partition. As the Kafka partitions are containing the data records or messages, each of these messages within a partition needs to be assigned an incremental ID. This incremental ID is with respect to the position, the message holds inside the Partition. This specific ID has defined an Offset.
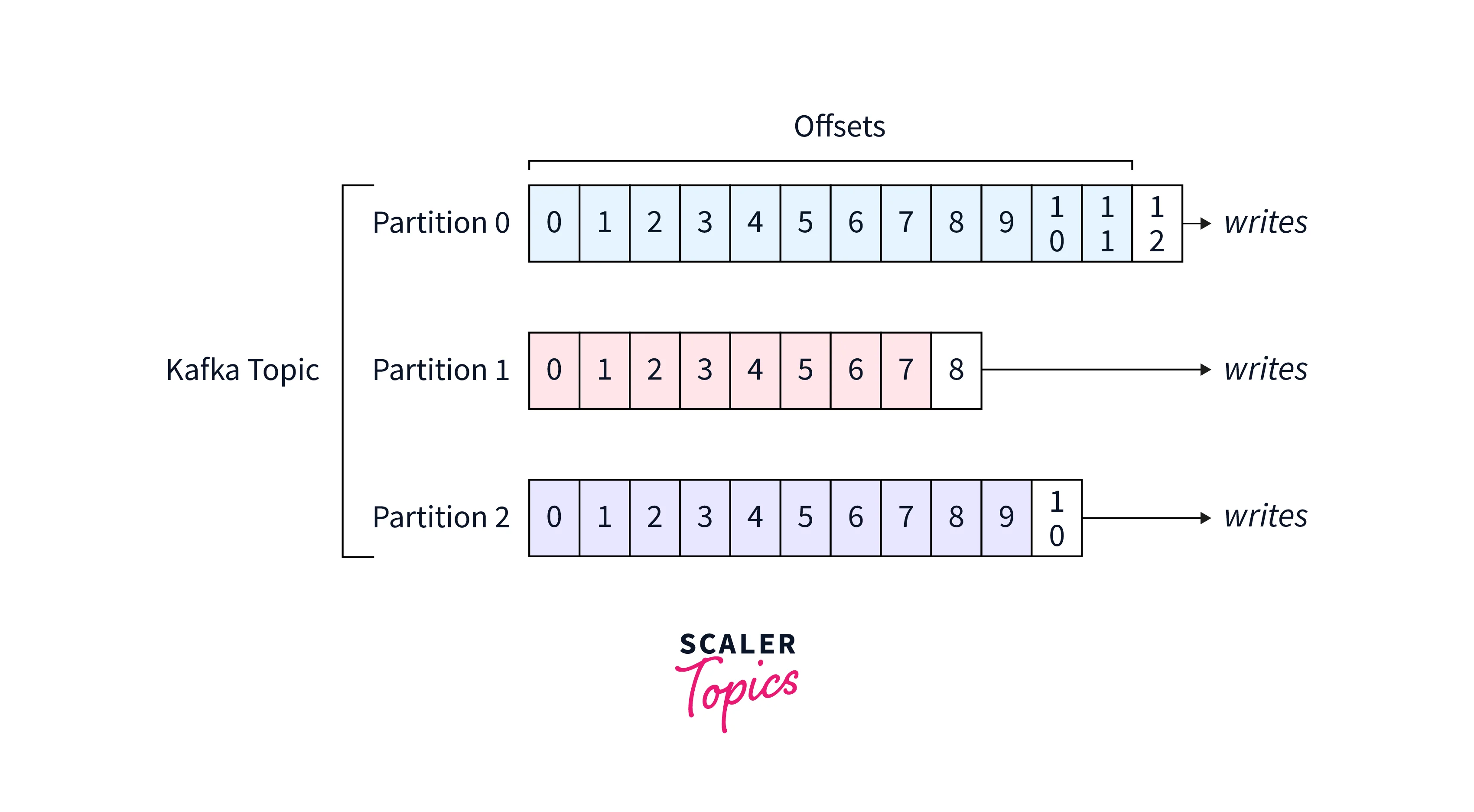
Brief Example:
As seen from the illustration above, we can see how the three Kafka partitions are independent of each other. All the messages written to each partition are independent with their unique offset value at their own speed which makes the offsets also independent. Hence, each message or data record has coordinates of the Offset number, in which partition, and under which topic.
As seen in the illustration, the topic has three independent partitions. In partition 0, you have messages with offset from 0 to 11, and the new message that shall be written will be having the offset number 12. In partition 1, the offset range from 0 to 7, while the new message that will be written will have the offset number 8. Similar is the case for partition 3, with the newest message specifying the offset as 10.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Topic Example
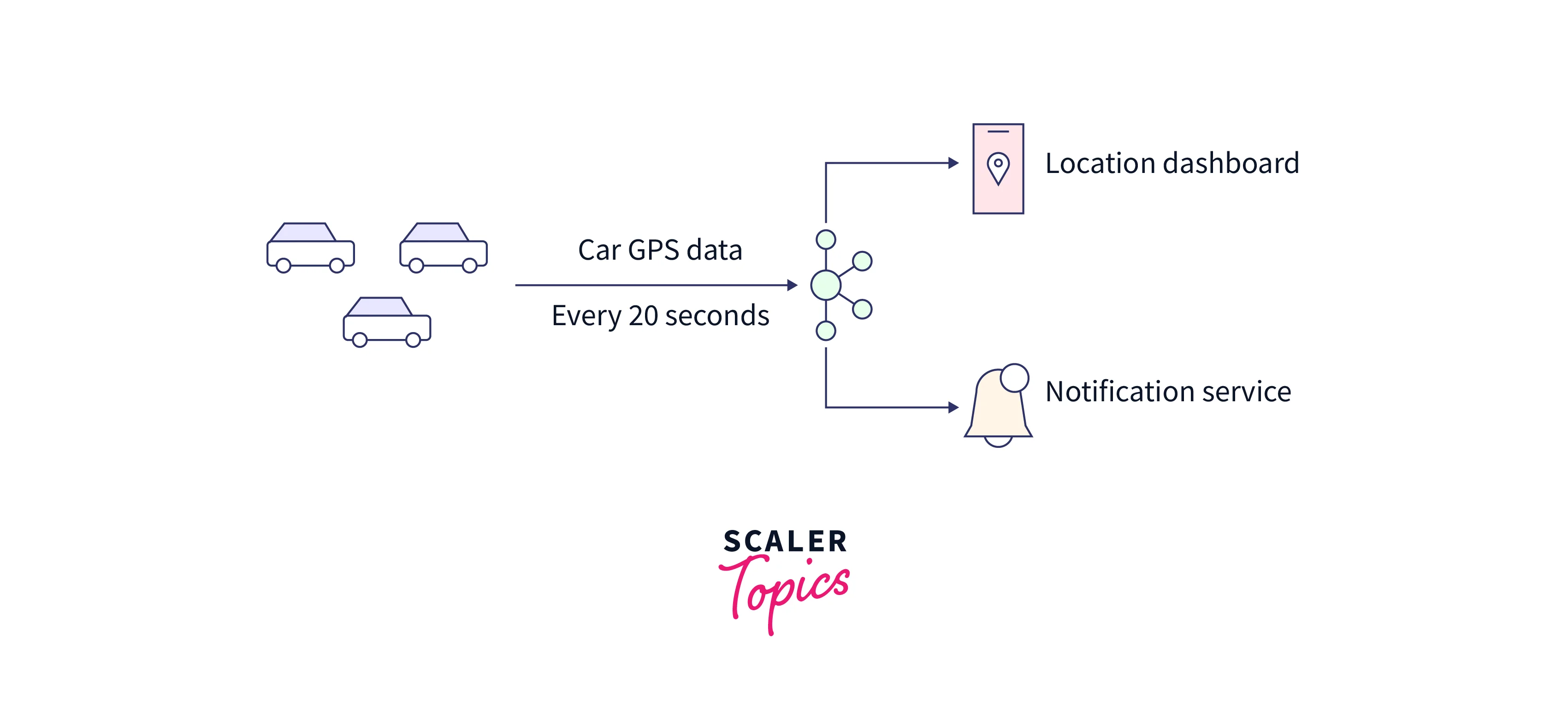
Now we understood the concept around Kafka's topic with an example. Suppose we want to onboard all the buses in an application for the users to track their buses. Now, with the Kafka cluster, we shall have each bus from the fleet of buses and we now start by positioning them in Kafka. These positions for each bus shall be shown on a dashboard or the web application so that the admin of these buses can have a look what is the real-time state of each bus. We start by creating a Kafka topic and naming it 'bus_tracking'. Inside the 'bus_tracking' topic we shall contain the position of all the buses in real-time. Every bus shall send its position every 30 seconds which will be the messages that shall be moving in Kafka. In the message information like 'bus_ID', 'bus_capacity', 'bus_metrics', and 'bus_average_speed'. This will help to understand the position of which bus along with the individual bus's position.
With so much information in the messages, we can also create a topic with 5 partitions. As we studied more partitions lead to more throughput traveling through your topic which can be decided with your capacity and testing team. As the data receiving is real-time, this web application will allow the bus admin to look into all the possibilities of where the bus is located, why some buses are running at high speed, what is the capacity of each bus, or even if some bus needs maintenance and can help the bus admin keep a track of when the bus is reaching the stop and send him the notification once it reaches the destination.
The below illustration shows how we can use Kafka topics, and partitions in real-life scenarios:
Key Points to Remember in Topics, Partitions, and Offsets
To sum up, the key points to remember in the topic, Kafka partitions and Kafka offset are described below. All the points have an example reference to the illustrative diagram given below to help gain a better idea.
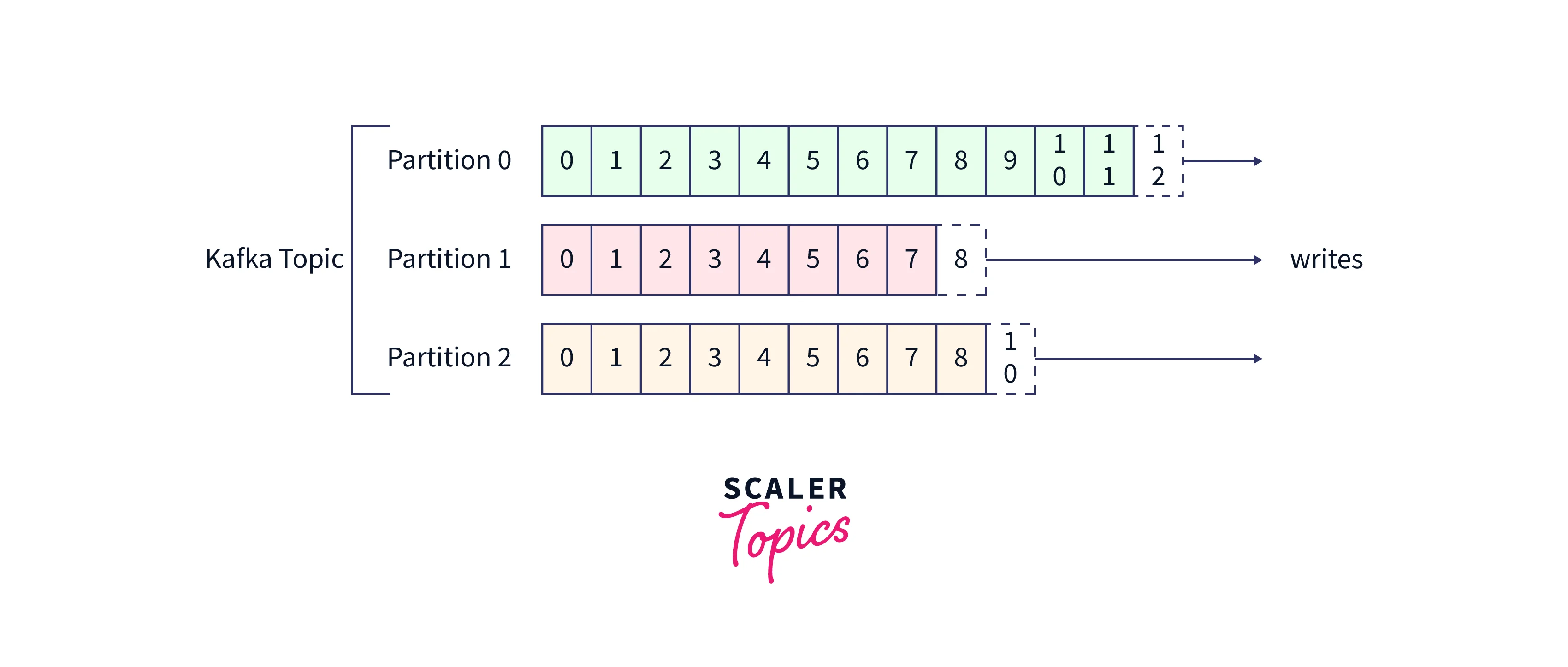
- Each partition has its own distinct order for the messages inside that specific Kafka partition.
- Across different Kafka partitions, no ordering sequencing is followed.
- Each Kafka offsets has information for a defined partition. As seen in the illustration above, the information for kafka offset number 6 in Kafka partitions 2 is entirely different from Kafka offset number 6 in Kafka partitions 3.
- The message retention time period in Kafka needs to be set which by default is one week. The message can only be set for a limited period of time. The message retention time period in place helps Kafka to renew the disk and protect from any run out of disk space. Hence, once a message has passed its retention time period the message gets removed from the log.
- It is important to keep an eye on while sending the data or the message into the partition in Kafka topic as Kafka is immutable. This also means that when the message in Kafka offsets number 5 in partition 2, you cannot change it or overwrite it. In case you have written bad data in the Kafka topic, the recovery mechanism should be placed.
- Don't forget to assign an appropriate key to the message. If not, then it may lead to the message sent to a Kafka topic getting assigned to a random partition.
- It is possible to have as many partitions as you require. It is not so common to have 30, 50, 70 up to 1000 Kafka partitions in a topic unless you are working with a really high throughput topic.
Turn Learning into Career Growth
Topic Naming Convention
In this section, we shall be discussing the naming convention you could be using for naming a Kafka Topic.
While there is no restriction when it comes to naming a Kafka topic, and you can use whatever name you like to name a Kafka topic. But when you start setting the Kafka cluster in the production environment, you need to lay down certain naming guidelines internally, so that it is easier to manage the cluster. Following guidelines can also be implemented for naming a Kafka Topic.
Syntax: The syntax used is as below:
Parameters:
We shall now be discussing each parameter that needs to be passed for renaming a Kafka topic.
Message Type: Below are a few of the message type and their explanations.
- logging: This is used primarily for logging the data like ghy4j, Syslog, etc.
- queuing: This is used for traditional queuing use cases.
- tracking: This is usually implemented when you need to track events like page views, user clicks, etc.
- user: This is implemented for user-specific data like test topics, scratch, etc.
Dataset Name: This is used to represent the dataset name similar to how we give a name to a database in traditional RDBMS systems. This is used for categorizing the various topics together.
Data Name: This is used to represent the data name similar to how we name a table in traditional RDBMS systems. You also add any notations specific to your project (differentiate your project from another in your organization).
Implementing the snake_case: Lastly, it's recommended to always use a casing while naming. Hence, to keep it simple and readable 'snake_case' is appreciated. In snake_case, all the naming is done in lowercase along with an underscore between each naming.
How to Choose the Number of Partitions in A Kafka Topic?
We know each topic in Kafka has partitions in it, which helps to split the message across parallel brokers in the cluster. With this method of parallelism, Kafka achieves high scalability and hence supports various consumers and producers simultaneously. Linear scaling for both consumer and producer is made possible by the partitioning method.
In this section, we shall answer how we can efficiently choose the number of partitions in a Kafka topic. While there can be many factors to be considered before choosing the number of partitions. Below are a few of them:
- Calculate the throughput depending on the anticipated future usage. This should be done well in advance as adding partitions later while sending messages to partitions based on keys is quite challenging.
- Calculate the maximum throughput (in MB/s), that is expected for your environment. You need to validate how much you will be achieving when consuming the messages from a single partition.
It is true that having more Kafka partitions in a topic is beneficial in many ways.
- Users achieve better parallelism as the number of partitions is directly dependent on offering more parallelism. This also offers better throughput.
- The high number of brokers in the Kafka cluster offers more partitions that can start to leverage it. Like, for a cluster having 5 brokers in total, where a topic has 3 partitions, they only leverage three brokers. This lead to inefficient resource usage as the other 2 is left idle.
- Offering more consumers to start consuming from the Kafka log, and hence achieve more scale. Like, 5 partitions in Kafka will allow at most 5 active subscribers to consume from the Kafka log.
While this may push you to add more partitions to fill in the gap, it is important to understand that having a maximum number of partitions causes some disadvantages too.
- When the number of Kafka partitions in a topic is more, there is supposed to be more load on the Zookeeper. It is so, as for every partition, Zookeeper elects a partition leader. And as the partitions are more, more time will be spent by Zookeepers on them. To avoid this, users need to opt for a Zookeeper-less Kafka.
- With more partitions, Kafka is bound to explore more files at once. Although there is a limit from the operating system, on how many files can be opened, users are pointed to always modify this limit to a higher value as per their operating system settings.
To help you choose wisely, always make sure to follow the below guidelines while selecting the correct number of partitions for your Kafka partition.
- Having a high number of Kafka partitions per topic is good for parallelism, but absurdly increasing the number of Kafka partitions to something like 1000, or 2000 should not be done, unless all 1000, and 2000 are getting fully needed.
- For a larger number of clusters, more than 12 brokers, then it is recommended to have two times, 2X, the number of brokers you hold.
- In a situation where you have a high throughput producer or the demand for it is going to increase in near future, it is recommended to consider the producer throughput too. In this case, keeping the number of Kafka partitions at 3X the number of brokers will work.
- For the smaller number of clusters, less than 6 brokers, then it is recommended to have three times, 3X, the number of brokers you hold. As with time, as more brokers are added, you can still adjust as the number of partitions will be enough to look at it.
- There might be a situation when the above recommendation might not work like if you have 30 subscribers waiting to consume the message from Kafka, then having at least 30 partitions in your topic is the key irrespective of your cluster size. Hence, keeping a regular check on the number of subscribers in a group at the desired peak throughput is important.
How to Choose the Replication Factor of A Kafka Topic?
When we talk about Kafka's reliability and fault tolerance, we need to consider the replications that need to be done for the partitions in Kafka. But can we choose the replication factor of a Kafka topic randomly? Will that give us the best-optimized reliability and fault tolerance?
To answer this, with this section of the article, we should understand how choosing the correct replication factor of a Kafka topic is crucial along with the advantages linked with it. We know that Kafka partitions reside in the Afka topic and we may think instead of relating the Kafka partition what if we replicated the Kafka topic. But to clear the air, replicating the topic in Kafka would not be consumer parallelism. We always should be replicating the number of partitions residing inside a Kafka topic.
The points that we must keep in mind while selecting the replication factor are listed below:
- The maximum replication factor for a partition in the Kafka topic is 4.
- The minimum replication factor for a partition in the Kafka topic is 2.
- The recommended replication factor for a partition in the Kafka topic is 3.
- With 3 replicas of the partition, we get the optimal balance between fault tolerance and performance. It is also observed that many cloud providers offer 3 data centers/availability zones in a region.
It's good to opt for a higher replication factor as it offers better resilience for your applications. For a replication factor that says X, it is observed that up till X-1 broker might fail. This does not impact the availability of the applications.
Now, though we want to always be protected from any disaster (if only) and we process to keeping the replication factor of a Kafka topic as high as possible, there are certain disadvantages linked to it as well.
- When you choose the maximum replication factor for your systems, producers experience higher latency. This happens because the number of data replication has increased for all the replica brokers.
- This also demands more disk space for your application. Which might also weigh heavy on your pocket. As more disk space amounts to more costs.
To help you choose wisely, always make sure to follow the below guidelines while selecting the correct replicator factor for your Kafka partition.
-
Recommended replication factor is 3. Ensure to have 3 brokers for the same.
-
Setting your replication factor to 1, offers no fault tolerance. This resonates with no replicas for your data being created at all, which if any disaster hits, all your data can be lost.
-
You can always go for a better broker when performance issue starts to hit even with a higher replication factor. There are fewer chances that reducing the replication factor would help that.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Writing Records to Partitions
We have been talking a lot about the Kafka partitions and how the Kafka partition is crucial in the Kafka architecture for writing and reading the records. But have you wondered how a publisher decide how a record should be written to a partition?
To answer that we shall look into three broad ways, out of which the record is written in the partitions.
- Specify a specific partition key to define the partition.
- Creating a custom partitioner for writing the record.
- Offering Kafka to decide the partition
Let us understand each of them one by one.
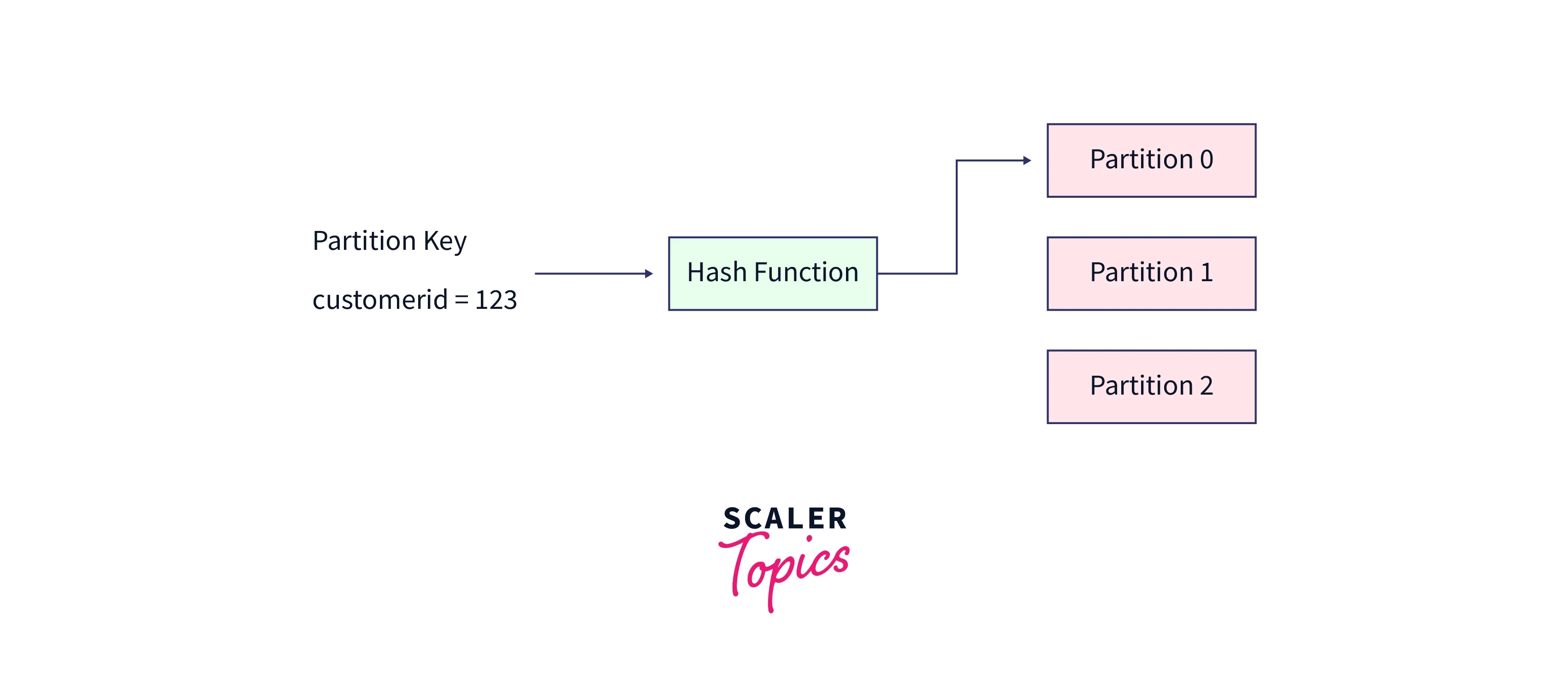
Specifying a Specific Partition Key to Define the Partition : When a publisher wants to send a record into the partition, it can make use of a partition key to direct messages at a defined partition. This partition is mostly derived from the application context. The user ID or any unique device ID can be one of the examples of a partition key. With the help of a hashing function, the partition key is processed to create the partition assignment. It is this partition, where all the records consisting of the same partition key will arrive. In this way, if your records need to be grouped as per the context, you can easily define a partition key to keep the related messages together, and with the order in which they must be consumed b the subscriber.
Well, it is good to define a partition key for keeping the records in a similar context together but this has one disadvantage too. If a partition key is defined based on the country having more population than others, then the partition where the more populous partition key is directed will have more traffic drawn to it, while the other topics remaining traffic is negligible. This can sometimes pose a broker to breaking down as seen in the below illustration. Hence, a partition key must be wisely chosen, so that the traffic is well distributed across the partitions and broker skewness does not arrive.
Creating a Custom Partitioner for Writing the Record
Sometimes with the business rules, the partition assignment can be done. The publisher can create its own custom partitioner for writing the record using some other business rules.
Offering Kafka to Decide the Partition
With the round-robin partition assignment, Kafka decides the partition key for the records that are being pushed by the publisher, and no partition key is specified from the publisher's end. These records are evenly written across all the Kafka partitions under a specific topic. However, here the ordering of data records is highly affected as Kafka favors even alignment of data between the partitions than following the order of the data records.
Hence, for contexts where sequencing is important always choose to give a well-distributed partition key to retrieve data records in the sequenced order as it was written, or else for random unrelated events. Let Kafka efficiently balance the load across the various partitions in the topic.
Reading Records from Partitions
So far we learned how you can write into the Kafka partitions. In this section, we shall learn how we can read records from Kafka partitions. We know that the subscribers have to pull the data records or the messages from the Kafka topic partitions instead of Kafka pushing it on the subscribers. A subscriber will always read the messages in the same order in which it was written to the Kafka topic partitions, once it is connected to a partition in a broker.
By keeping a track of the offset, subscribers can keep a track of the data record or the messages that a consumer has already consumed or not. This way the offset of a message plays the role of a subscriber side cursor. Once a message is read from the Kafka topic partition, the subscriber will advance its respective cursor and continue to consume the message. It is entirely dependent on the subscriber when it is reading the message from the Kafka partitions.
Be it remembering the last read offset, resuming from the last read offset, and advancing to another within a partition, Kafka does help in any of it. If the subscriber is successful in corrective remembering the last offset read, it can very easily resume reading even after recovering from a disaster (if any).
As we know with Kafka multiple subscribers can consume them from the same partitions at the same point in time, each reading the message from a different offset. The consumer group is a widely known concept in Kafka where various consumers consume a given topic as a group. Here, the same group-id value is assigned to the same consumer group. This concept of consumer group makes sure that within this group the message is read by only a single subscriber. Kafka ensures that every partition is getting consumed by one subscriber in the group, whenever there is a consumer group for a partition of a topic.
As shown below, partition 1 and 2 is being consumed by only consumer C2 from consumer group A.
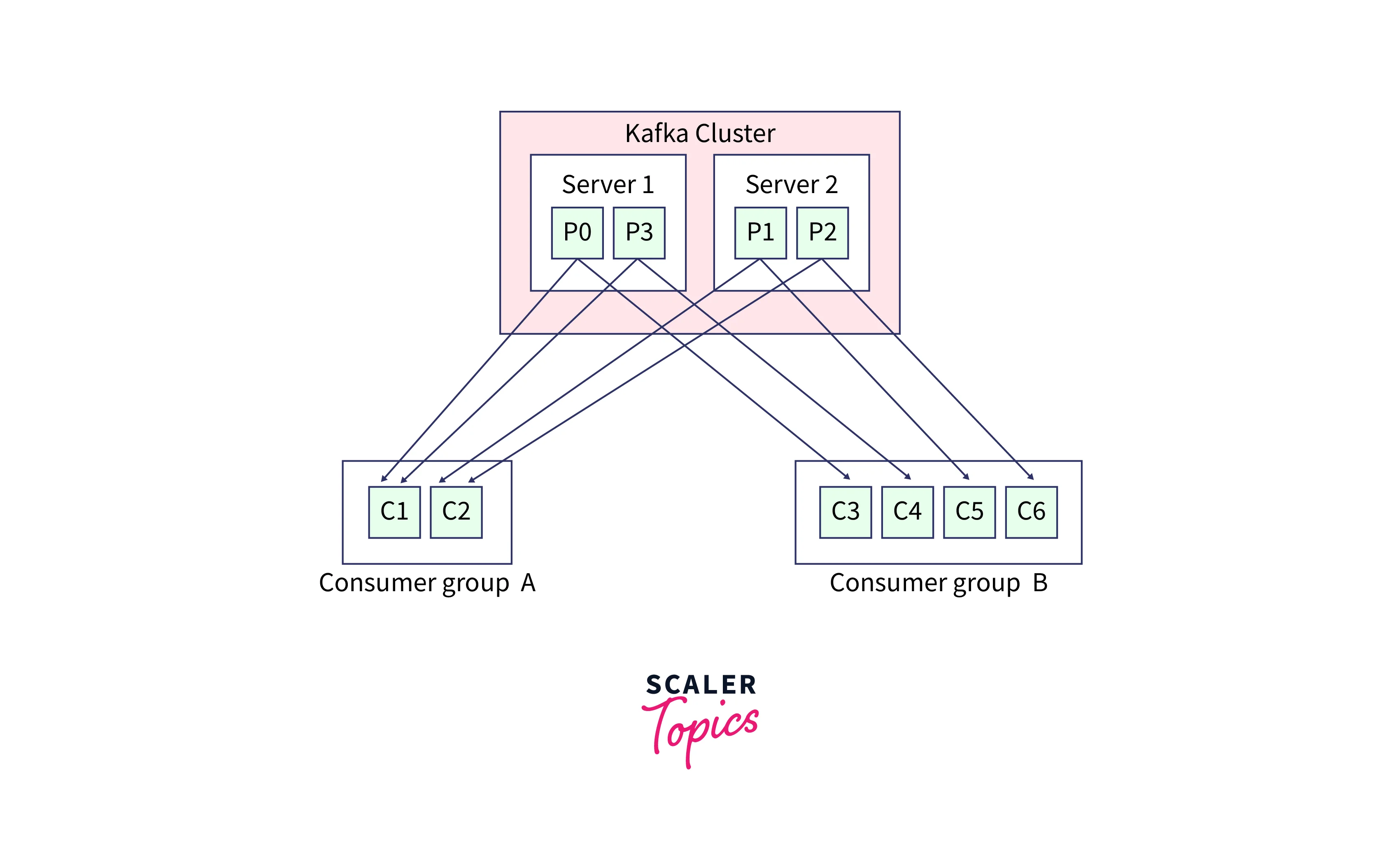
With the concept of consumer groups in Kafka, the subscribers are able to efficiently parallelize and process the messages with high throughput. Whereas, the number of partitions in a topic determines the maximum parallelism that can be achieved for a group. As in the above illustrations, the partition is 2 for both Server 1 and Server 2, therefore even if Consumer Group B has more consumers, than Consume group A, still both will have an equal parallelism rate of consuming data.
Then you must be thinking why have four consumers in one consumer group rather than having a similar number of the consumer as the number of partitions as in Consumer group A having 2 consumers for 2 partitions? This is where the great strategy to combat the issue of hot failover comes in.
If the 2 partitions from Server 2 are serving Consumer Group B having 4 consumers, then at first only 2 consumers will be working and consuming the messages while the other two will be left idle. This case is similar to how the situation will resonate for Consumer Group A also. But when any consumer fails, in both the Consumer Grup, A, and B, A will not be able to recover while one of the idle consumers can start to cover up and start consuming the message from the assigned partition.
Hence, the degree of parallelism depends on the number of partitions, while having more the consumer will significantly recuse whenever a failure occurs.
Conclusion
- In Apache Kafka, all the messages written in the partitioned log commit model, reside inside the Topic, which can be further divided into partitions. In the partitions, each of the messages will have a specific ID attached to it called the Offsets.
- Topic needs to have a unique name across all the clusters.
- Setting your replication factor to 1, offers no fault tolerance. This resonates with no replicas for your data being created at all, which if any disaster hits, all your data can be lost.
- With the 3 replicas of the partition, we get the optimal balance between fault tolerance and performance. It is also observed that many cloud providers offer 3 data centers/availability zones in a region.
- Kafka ensures that every partition is getting consumed by one subscriber in the group
MCQs
- Which of the following resembles the hierarchy of the RDBMS system?
Primary ID -> Rows -> View -> Table
- Option 1 Partition -> Topic -> Partitions -> Message.
- Option 2 Offset -> Message -> Partitions -> Topic.
- Option 3 Topic -> Partitions -> Message -> Offset.
- Option 4 Message -> Partitions -> Offset -> Topic.
Correct Answer: Option 2
- What will the offset be for a message in the Kafka partition which is already having 9 messages in it?
- a. 9
- b 10
- c 11
- d 8
Correct Answer: a
- What is the maximum replication factor possible for a partition in Kafka?
- a. 2
- b. 3
- c. 4
- d As per requirement/user.
Correct Answer: c