Introduction to Machine Learning in R
Overview
At its core, machine learning involves the development of algorithms that can improve their performance over time by learning from data. The process starts with feeding the algorithm a set of data points, known as the training data, which includes the input features and the corresponding desired output or target. The algorithm then learns patterns, relationships, and trends within the data to create a model that can accurately predict new, unseen data.
How Machine Learning Works?
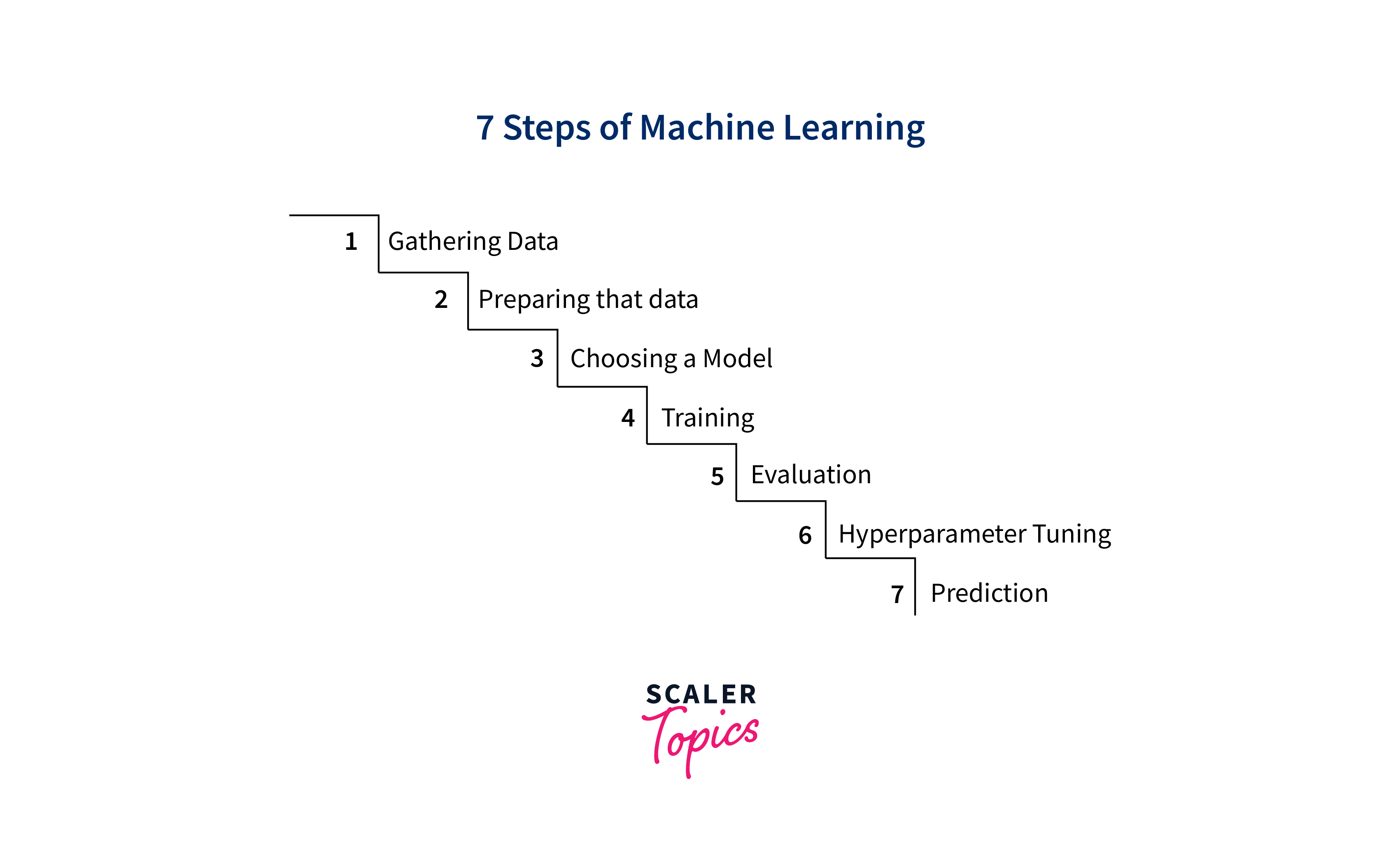
The machine-learning process can be broken down into several key steps:
-
Data Collection and Preparation:
Gathering relevant and high-quality data is the foundation of machine learning. This involves cleaning the data, handling missing values, and ensuring that the data represents the problem you're trying to solve. -
Feature Selection and Engineering:
The right features (input variables) are crucial for model performance. Feature engineering involves creating or transforming new features to enhance the model's ability to capture patterns. -
Model Selection:
Choosing an appropriate machine learning algorithm is essential. Different algorithms are suited for different types of problems. Common algorithms include decision trees, support vector machines, and neural networks. -
Training the Model:
During this step, the selected algorithm is fed the training data to learn the underlying patterns. The algorithm adjusts its parameters iteratively to minimize the difference between its predictions and the actual target values. -
Evaluation:
The trained model's performance is evaluated using accuracy, precision, recall, and F1-score, depending on the problem's nature (classification, regression, etc.). This helps us understand how well the model generalizes to new, unseen data. -
Hyperparameter Tuning:
Algorithms often have hyperparameters that control their behavior. Tuning these hyperparameters can significantly impact the model's performance. Techniques like grid search or random search are used to find optimal values.Hyperparameter tuning is the process of fine-tuning settings in machine learning models that are not learned from data, such as learning rates, regularization strengths, and architecture parameters. Proper tuning ensures the model's optimal performance by striking a balance between overfitting and underfitting.
-
Testing and Deployment:
Once a satisfactory model is obtained, it is tested on a separate dataset, the testing or validation set, to ensure it performs well on new data. After thorough testing, the model can be deployed in real-world applications.
Types of Machine Learning
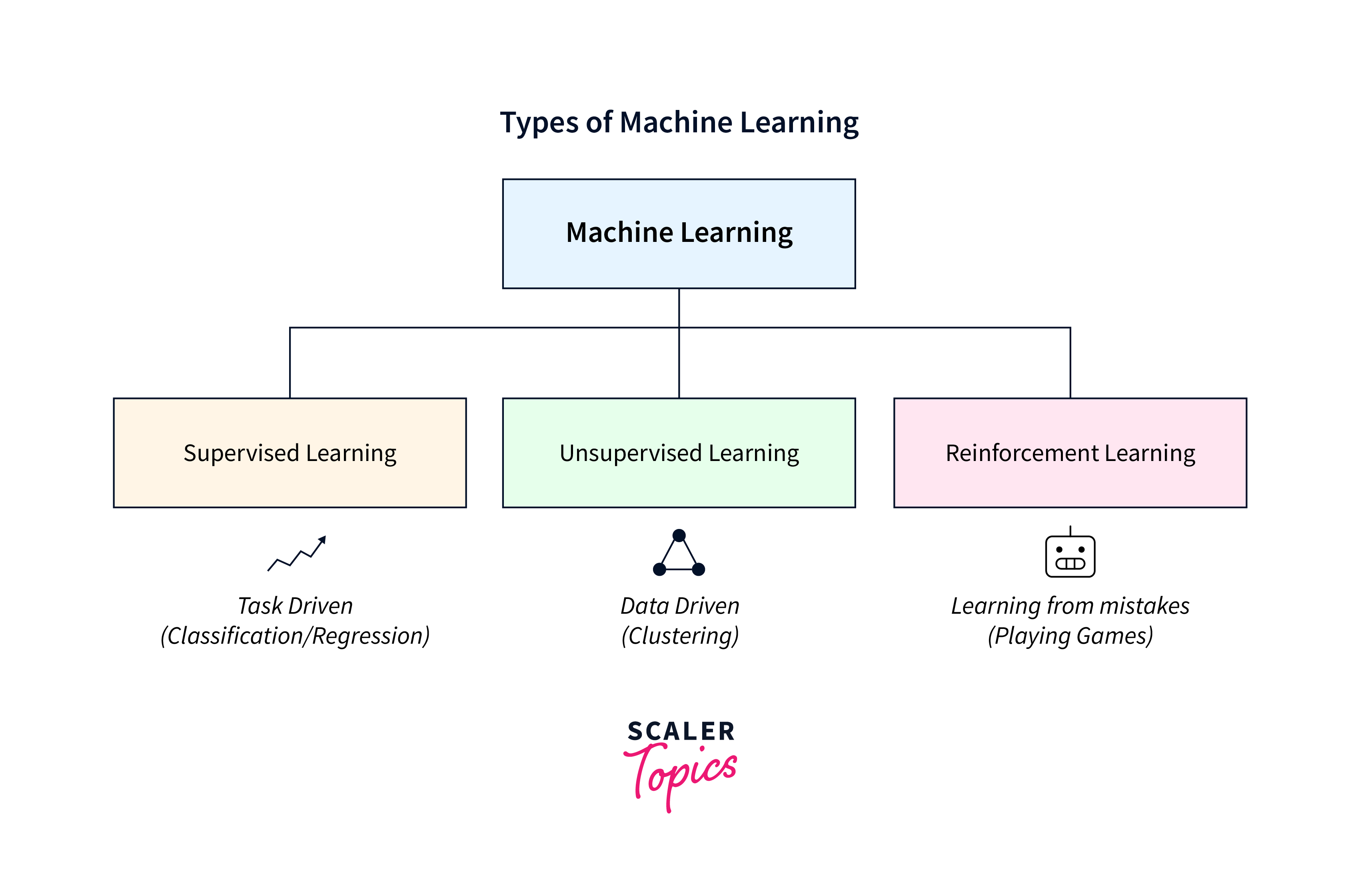
A. Supervised Learning
Supervised learning is the most common and straightforward form of machine learning. In this approach, the algorithm learns from a labeled dataset consisting of input features and corresponding target values or labels. The algorithm aims to learn a mapping from inputs to outputs to predict the correct output for new, unseen data.
The process of supervised learning involves:
- Data Collection:
Gather a labeled dataset where the inputs and their corresponding outputs are known. - Training the Model:
Feeding the algorithm with the labeled data to learn the underlying patterns and relationships between inputs and outputs. - Model Evaluation:
Assessing the model's performance on new, unseen data using metrics like accuracy, precision, recall, and F1-score.
Common applications of supervised learning include:
- Classification:
Assigning inputs to predefined classes. For example, email spam detection. - Regression:
Predicting a continuous numeric value. For example, predicting house prices based on features like area and number of bedrooms.
In R, libraries such as 'caret', 'randomForest', and 'glm' offer tools for implementing various supervised learning algorithms.
B. Unsupervised Learning
Unsupervised learning involves working with unlabeled data, where the algorithm's task is to identify patterns, clusters, or structures within the data without predefined targets. This type of learning is often used when the relationships between data points are not explicitly known, and the goal is to gain insights into the data's underlying distribution.
Key aspects of unsupervised learning:
- Clustering:
Grouping similar data points into clusters. Applications include customer segmentation and image segmentation. - Dimensionality Reduction:
Reducing the number of input features while retaining as much meaningful information as possible. Methods such as Principal Component Analysis (PCA) are included within this classification.
Unsupervised learning is valuable for exploratory data analysis and pattern recognition. R provides libraries like 'cluster,' 'factoextra,' and 'dplyr' for implementing unsupervised learning techniques.
C. Reinforcement Learning
Reinforcement learning involves training an agent to take action in an environment to maximize a cumulative reward. The agent learns through trial and error, receiving feedback as rewards or penalties based on its actions. The goal is to find the optimal action sequence that yields the highest cumulative reward over time.
Core components of reinforcement learning:
- Agent:
The learner interacts with the environment and takes action. - Environment:
The external system with which the agent interacts. It provides feedback to the agent based on its actions. - Rewards:
Numeric values that indicate the desirability of an action. The objective of the agent is to acquire a policy that optimizes the total reward over time.
Reinforcement learning finds applications in robotics, game playing, autonomous systems, and more. In R, libraries like 'ReinforcementLearning' and 'rllib' provide tools for implementing reinforcement learning algorithms.
Types of Machine Learning Problems

This article explores various types of machine learning problems, their significance, and how they can be addressed using the R programming language.
1. Classification Problems:
Classification is a fundamental machine learning problem that categorizes data points into distinct classes or categories. Each data point is associated with a set of features, and the task is to predict which class the data point belongs to. This problem is prevalent in various domains, such as finance, healthcare, and natural language processing.
In a classification problem:
- Input: Data points with features.
- Output: Discrete class labels.
Examples of classification tasks include:
- Email spam detection (spam or not spam).
- Image classification (identifying objects in images).
- Sentiment analysis (determining text sentiment).
In R, libraries like 'caret', 'randomForest', and 'xgboost' provide tools to implement classification algorithms.
2. Regression Problems:
Regression is another core machine-learning problem that predicts a continuous numeric value based on input features. In contrast to classification, where the output is categorical, regression predicts a real-valued output. This problem is essential for tasks where the relationship between input variables and the desired output is continuous.
In a regression problem:
- Input: Data points with features.
- Output: Continuous numeric values.
Examples of regression tasks include:
- House price prediction is based on features like area, bedrooms, and location.
- Temperature forecasting based on historical weather data.
R offers libraries like 'lm' (linear regression), 'randomForest,' and 'caret' for implementing regression algorithms.
3. Clustering Problems:
Clustering is an unsupervised learning problem that involves grouping similar data points based on their intrinsic characteristics. The algorithm identifies clusters or groups in the data without predefined class labels. Clustering is valuable for discovering hidden patterns and segmenting data into meaningful categories.
In a clustering problem:
- Input: Unlabeled data points.
- Output: Clusters or groups of similar data points.
Examples of clustering tasks include:
- Customer segmentation for targeted marketing strategies.
- Image segmentation for medical image analysis.
R provides libraries like 'cluster,' 'factoextra,' and 'dplyr' for implementing clustering techniques.
4. Anomaly Detection:
Anomaly detection, also known as outlier detection, focuses on identifying data points that deviate significantly from the norm. These anomalies can indicate fraudulent activities, system faults, or data quality issues. Anomaly detection is crucial for maintaining the integrity and security of data-driven applications.
In an anomaly detection problem:
- Input: Data points with features.
- Output: Identification of anomalies.
Examples of anomaly detection tasks include:
- Detecting credit card fraud based on transaction history.
- Identifying faulty machinery in an industrial setting.
R offers libraries like 'AnomalyDetection' and 'DMwR' for implementing anomaly detection algorithms.
5. Recommendation Systems:
Recommendation systems are widely used to suggest items or content to users based on their preferences and historical interactions. These systems are significant in personalized marketing, content delivery, and enhancing user experience.
In a recommendation system problem:
- Input: User preferences and item attributes.
- Output: Recommendations for items to users.
Examples of recommendation system tasks include:
- Movie recommendations on streaming platforms.
- Product recommendations on e-commerce websites.
R libraries like 'recommenderlab' and 'recosystem' provide tools for building recommendation systems.
Implementation of Machine Learning with R
For this example, let's consider a simple classification problem: predicting whether a passenger on the Titanic survived based on features like age, gender, and ticket class.
Step - 1: Data Preparation
Load the required libraries and the dataset. Split the data into features (X) and target variables (y).
Step - 2: Preprocessing
Handle missing values and encode categorical variables.
Step - 3: Splitting Data
Divide the data into training and testing sets.
Step - 4: Training the Model
Choose an algorithm and train the model.
Step - 5: Model Evaluation
Evaluate the model's performance using the testing set.
Step - 6: Model Deployment
After evaluating the model, it's ready for deployment in real-world scenarios.
Advantages to Implement Machine Learning Using R Language
- Rich Ecosystem of Libraries and Packages:
R boasts extensive libraries and packages specifically designed for machine learning. These libraries implement various algorithms, making it easy to experiment with different techniques without coding from scratch. Libraries like caret, randomForest, xgboost, and keras cover a broad range of machine learning algorithms, from basic to advanced. - User-Friendly Syntax:
R's syntax is concise and intuitive, making it an excellent choice for those new to programming and machine learning. Its syntax closely resembles mathematical notation, allowing data scientists to express complex operations readably. This simplicity enables faster experimentation and understanding of algorithms. - Data Analysis Capabilities:
R's origins lie in statistics and data analysis, making it well-suited for data manipulation, exploration, and visualization. Before building a machine learning model, thorough data analysis is essential, and R's tools like dplyr and ggplot2 provide a seamless way to preprocess and visualize data.
- Interactivity and Rapid Prototyping:
R's interactive nature is advantageous for quick prototyping and experimentation. It allows you to test code snippets, visualize data, and iteratively refine your models. This interactivity is especially beneficial for exploring different approaches and finding the best-fitting model. - Support for Reproducibility:
R's script-based nature promotes reproducibility in data analysis and machine learning projects. You can save your work in scripts, making it easy to revisit and reproduce results later. This is crucial for collaboration, sharing findings, and maintaining a record of your experiments. - Community and Resources:
R has a thriving and enthusiastic community of data scientists, statisticians, and machine learning practitioners. This community contributes to the development of libraries, provides tutorials, answers questions on forums, and shares their expertise through blog posts and online courses. Access to this wealth of resources can accelerate your learning and problem-solving process. - Seamless Integration with Statistics:
Machine learning often involves statistical concepts, and R's foundation in statistics allows for seamlessly integrating these concepts into your machine learning projects. You can easily test hypotheses, explore distributions, and assess model significance within the same environment. - Parallel and Distributed Computing:
R offers parallel and distributed computing tools, enabling you to leverage multiple processors or machines to speed up computations. This is particularly beneficial when dealing with large datasets or complex algorithms that require significant computational resources. - Cross-Domain Applicability:
R is versatile and applicable across various domains, from finance and healthcare to marketing and natural language processing. This adaptability makes R a valuable tool for practitioners across various industries. - Visualization Capabilities:
Visualization is crucial for understanding data and model results. R's 'ggplot2' package and other visualization libraries allow you to create sophisticated and informative plots, effectively conveying insights and results.
Application of R in Machine Learning
- Predictive Modeling:
Predictive modeling is a cornerstone of machine learning, and R excels in this domain. R's libraries, such as 'caret' and 'randomForest,' offer tools for building predictive models for classification and regression tasks. This is crucial in industries like finance for credit scoring, healthcare for disease prediction, and marketing for customer segmentation. - Natural Language Processing (NLP):
R has gained prominence in NLP due to libraries like 'tm' and 'quanteda,' which facilitate text preprocessing, sentiment analysis, topic modeling, and more. NLP applications include sentiment analysis of social media data, automatic categorization of documents, and chatbot development. - Image Analysis:
Though not the primary domain for R, it still has packages like 'imager' and 'EBImage' for image analysis. R is used to preprocess images, extract features, and feed them into machine learning models. Medical imaging, quality control in manufacturing, and satellite image analysis are some areas where R's image analysis capabilities shine. - Time Series Analysis:
R is well-suited for time series analysis, which involves modeling and forecasting data points indexed over time. Libraries like 'forecast' and 'prophet' are used for stock price prediction, energy consumption forecasting, and demand estimation. - Fraud Detection:
R is frequently used in fraud detection applications, where algorithms learn patterns from historical data to identify suspicious transactions. The ability to preprocess data, implement complex algorithms, and interpret results makes R an excellent choice for building fraud detection models. - Healthcare and Medical Research:
In the healthcare sector, R is used for medical image analysis, disease prediction, drug discovery, and patient outcome modeling. The 'survival' package is commonly used for survival analysis, which estimates the probability of an event occurring over time. - Marketing and Customer Analytics:
R aids in customer segmentation, churn prediction, and recommendation systems for marketing purposes. Companies can tailor their marketing strategies more effectively by analyzing customer behavior and historical data. - Environmental Monitoring:
R finds applications in environmental sciences for tasks like climate modeling, pollution analysis, and biodiversity prediction. It allows researchers to process and analyze large volumes of environmental data efficiently. - Social Sciences and Education:
Social sciences and education researchers use R for data analysis, hypothesis testing, and building predictive models. This helps in understanding student performance, educational outcomes, and social trends. - Automated Machine Learning (AutoML):
R's libraries like 'autoML,' 'mlr,' and 'caret' provide tools for automated model selection, hyperparameter tuning, and performance evaluation. AutoML streamlines the process of building effective models by automating repetitive tasks.
Conclusion
- Machine learning involves training algorithms to learn from data and make predictions or decisions without explicit programming.
- Supervised Learning:
The algorithm learns from labeled data, making predictions on new data. - Unsupervised Learning:
The algorithm discovers patterns in unlabeled data, useful for clustering and dimensionality reduction. - Reinforcement Learning:
The agent learns by acting in an environment to maximize rewards. - Data collection and preparation are foundational for accurate model training.
- Feature selection and engineering enhance the model's ability to capture patterns.
- Model selection involves choosing an appropriate algorithm based on the problem.
- R's libraries and packages like 'caret,' 'randomForest,' and 'xgboost' support many algorithms.