Binning in Machine Learning
Overview
Obtaining the best machine learning model for any ML task is desired by everyone. We all want our model to have the best accuracy and other metrics. If you have built a model and think its accuracy can still be improved then you may need to do some feature engineering. Feature engineering techniques are used to create new features from the existing data. This article revolves around a feature engineering technique called “binning”.
Introduction
Real-world data comes with a lot of noise. Noisy data is data with a large amount of additional meaningless information in it called noise. The dependent variable may have too many unique values to model effectively. There are also outliers, missing, and invalid values present in the dataset; binning helps us to deal with all of these.
What is Binning?
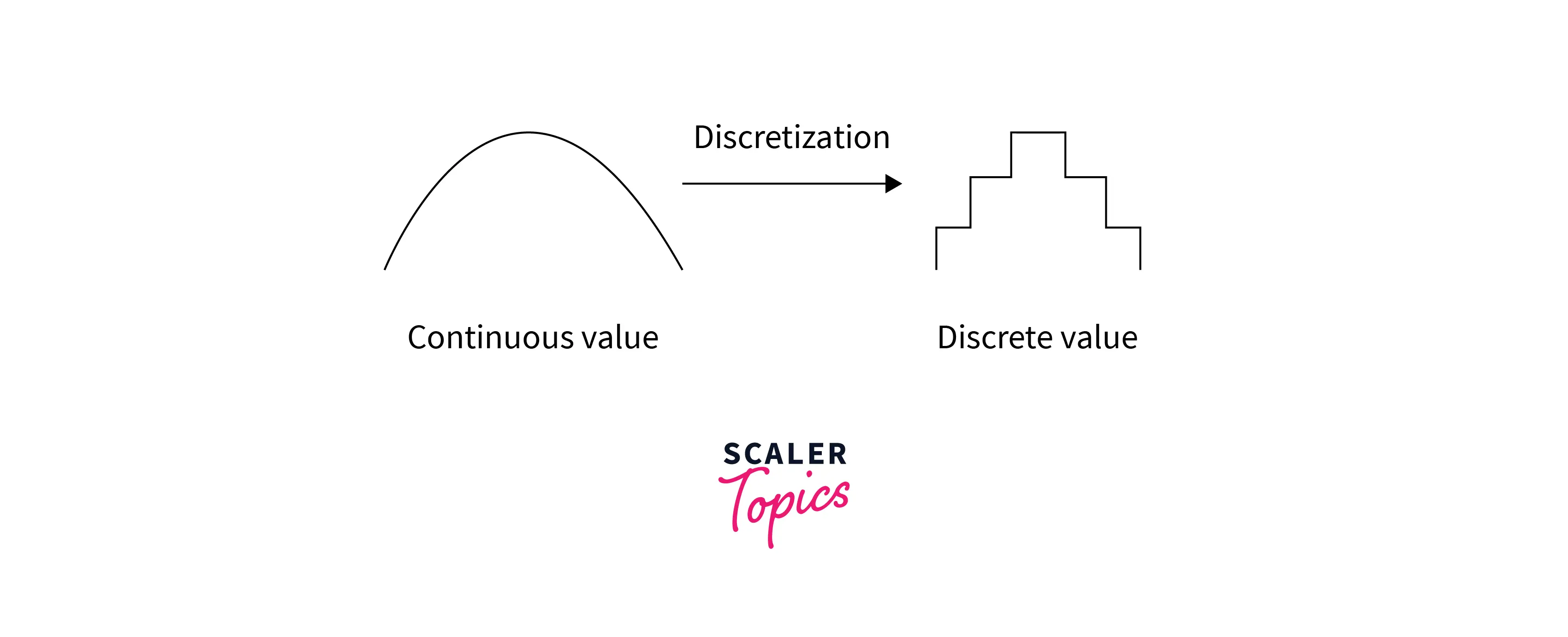
Data binning, or bucketing, is a process used to minimize the effects of observation errors. It is the process of transforming numerical variables into their categorical counterparts.
In other words, binning will take a column with continuous numbers and place the numbers in “bins” based on ranges that we determine. This will give us a new categorical variable feature.
Advantages of binning:-
- Improves the accuracy of predictive models by reducing noise or non-linearity in the dataset.
- Helps identify outliers and invalid and missing values of numerical variables.
Types of Binning
Equal Width (or distance) Binning
This algorithm divides the continuous variable into several categories having bins or ranges of the same width. Let x be the number of categories and max and min be the maximum and minimum values in the concerned column. Then width(w) will be:-
and the categories will be:-
Categories:
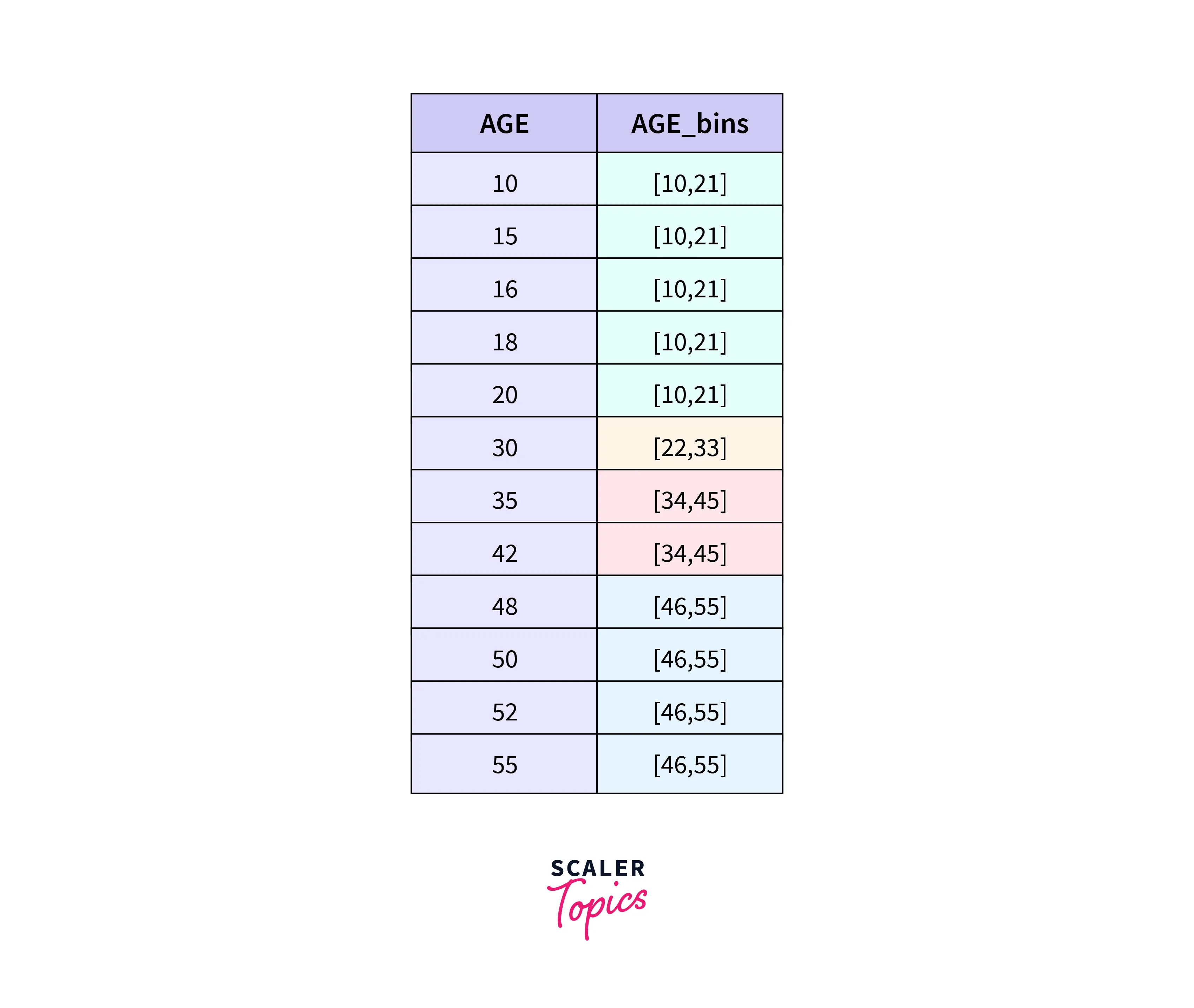
Let's take an example:- Let column X be:-
Here, min= 10, max=55, and let's say the number of categories "x" be 4. Then the width "w" will be : (55-10)/4 = 12.
Then, the continuous data can be converted to categorical:-
Advantages:-
- Simple to implement.
- Ranges provide a good categorical feature.
- Good for unskewed data
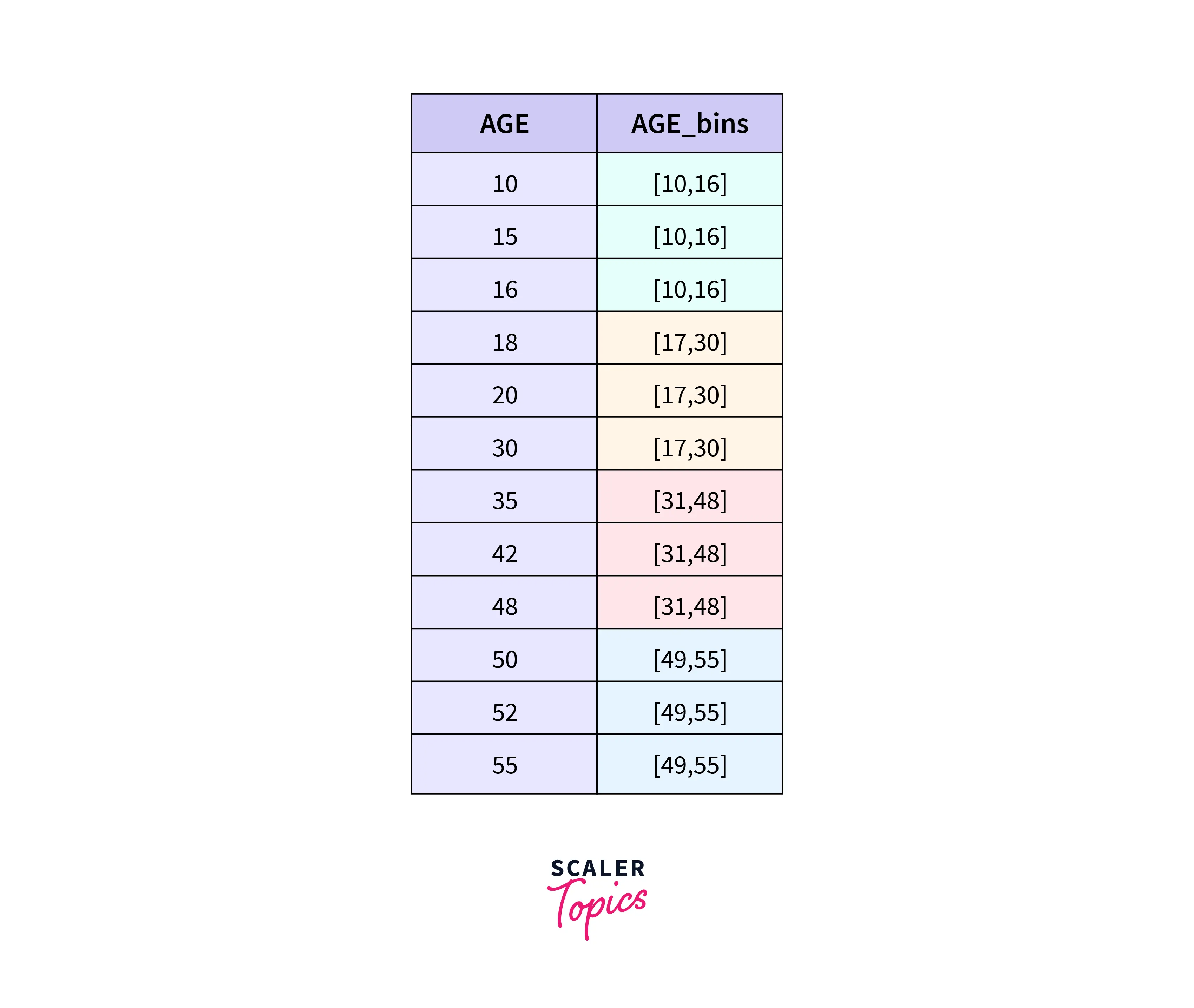
Equal Depth(or frequency) Binning
This algorithm divides the data into categories with approximately the same values.
Let n be the number of data points and x be the number of categories required.
Then the continuous data is converted to categorical as follows:-
Advantages:-
- Easy to understand.
- Simple to implement.
- The data values are distributed (approximately)equally into the formed categories.
- Handles skewed data better than distance binning
Quantile Binning
Quantile Binning is the process of assigning the same number of observations to each bin if the number of observations is evenly divisible by the number of bins. As a result, each bin would end up having the same number of observations, provided that there are no tied values at the boundaries of the bins.
Using fixed-width will not be effective if there are significant gaps in the range of the numerical feature, then there will be many empty bins with no data.
Just like in frequency binning, quantiles are values that divide the data into equal portions. The quantile method assigns values to bins based on percentile ranks.
Python Implementation
First, we define a function to give us the different bins based on the data.
Next, we define a function that would assign each element to the respective bins
Let's try the above function:-
Output:-
Now let's see how we assign the elements to the bins:-
Output:-
Conclusion
The key takeaways from this are:-
- Binning is the process of transforming numerical variables into their categorical counterparts.
- This process improves the accuracy of predictive models by reducing noise or non-linearity in the dataset.
- Binning is primarily of two types: distance and frequency based.