Blending in Machine Learning
Overview
One might refer to Machine Learning as the foundation of the world of Artificial Intelligence. It is the method by which we can get a computer to operate without any programming at all. The precision and accuracy of the machine learning model are increased with each instance of computation that it performs using the data that we feed it.
Every hour, new techniques and algorithms are developed in this expanding environment, improving the accuracy and precision of our machine-learning models. In this article, we will learn about one such technique in Machine Learning, blending.
Pre-requisites
To follow along with this article,
- A basic understanding of classification and regression algorithms in Machine Learning is required.
- Google Colab would be ideal if you were to code along with this article.
- Since we will be combining multiple Machine Learning algorithms, a knowledge of bagging and boosting would be necessary.
- Along with bagging and boosting, concepts of stacking in Machine Learning must be clear.
Introduction
As we discussed earlier in this article, scientists and Machine Learning enthusiasts developed many up-and-coming techniques to improve the field. A dedicated team of researchers is working on the concept of aggregating multiple models to enhance the overall accuracy and efficiency of Machine Learning models. That is where Blending comes in.
In this article, we will discuss what Blending is, and how it is better than a standard and plain Machine Learning model.
What is Blending?
To improve the overall effectiveness of the model, ensemble learning, a branch of machine learning, combines many models of the same (or different) types.
Blending is one of the many ensemble machine-learning techniques that make use of a machine-learning model to figure out how to blend predictions from several ensemble member models in the most effective way. It is similar to Stacking (another ensemble learning technique). Hence it might get interchanged in some illustrations like magazines and research papers.
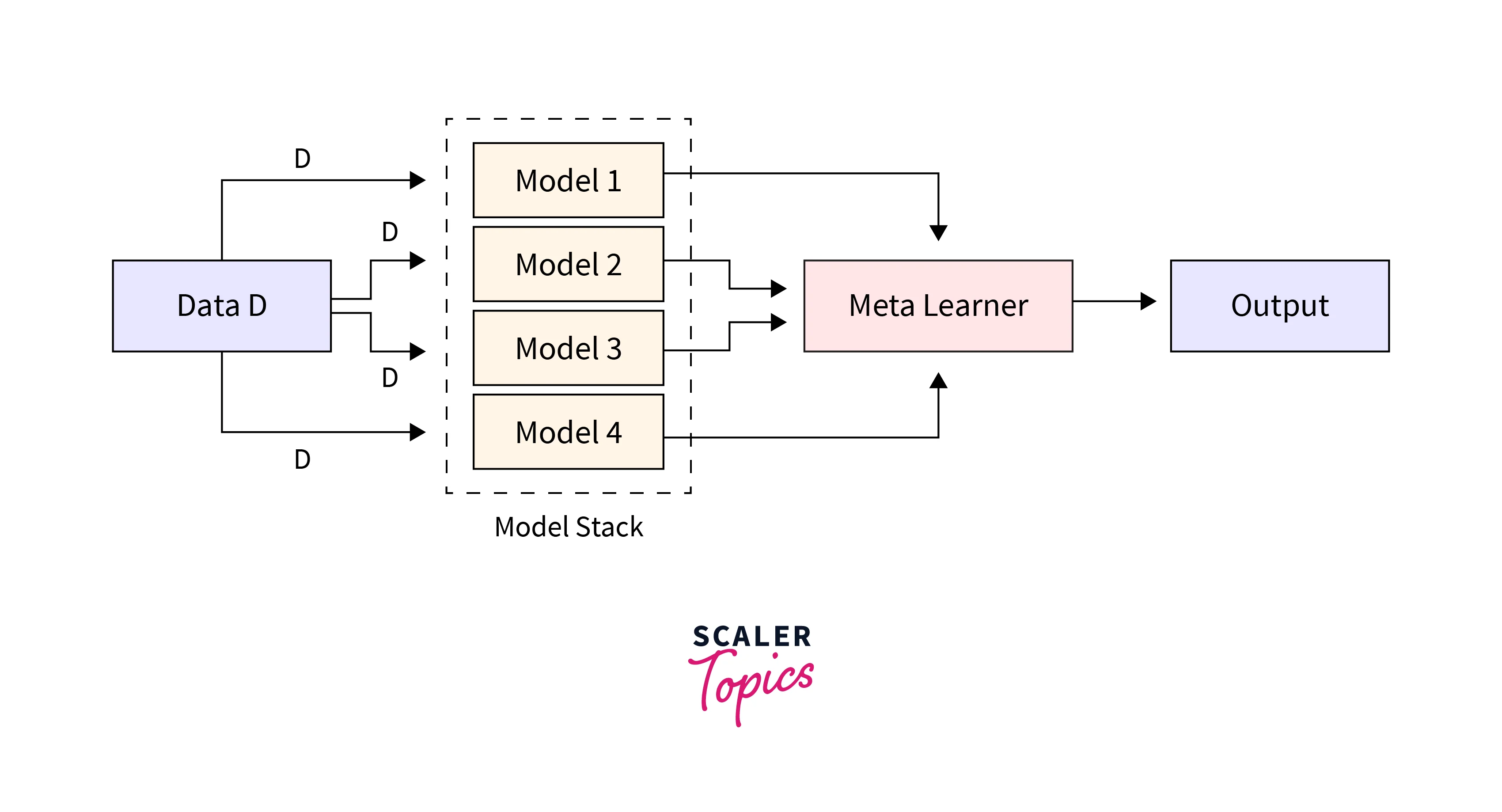
The architecture of a blending and most of the ensemble learning models consists of two or more base models, also known as level-0 models, and a meta-model, or level-1 model, which integrates the predictions of the base models. The meta-model (main model) is trained on the predictions made by the base models on out-of-sample data.
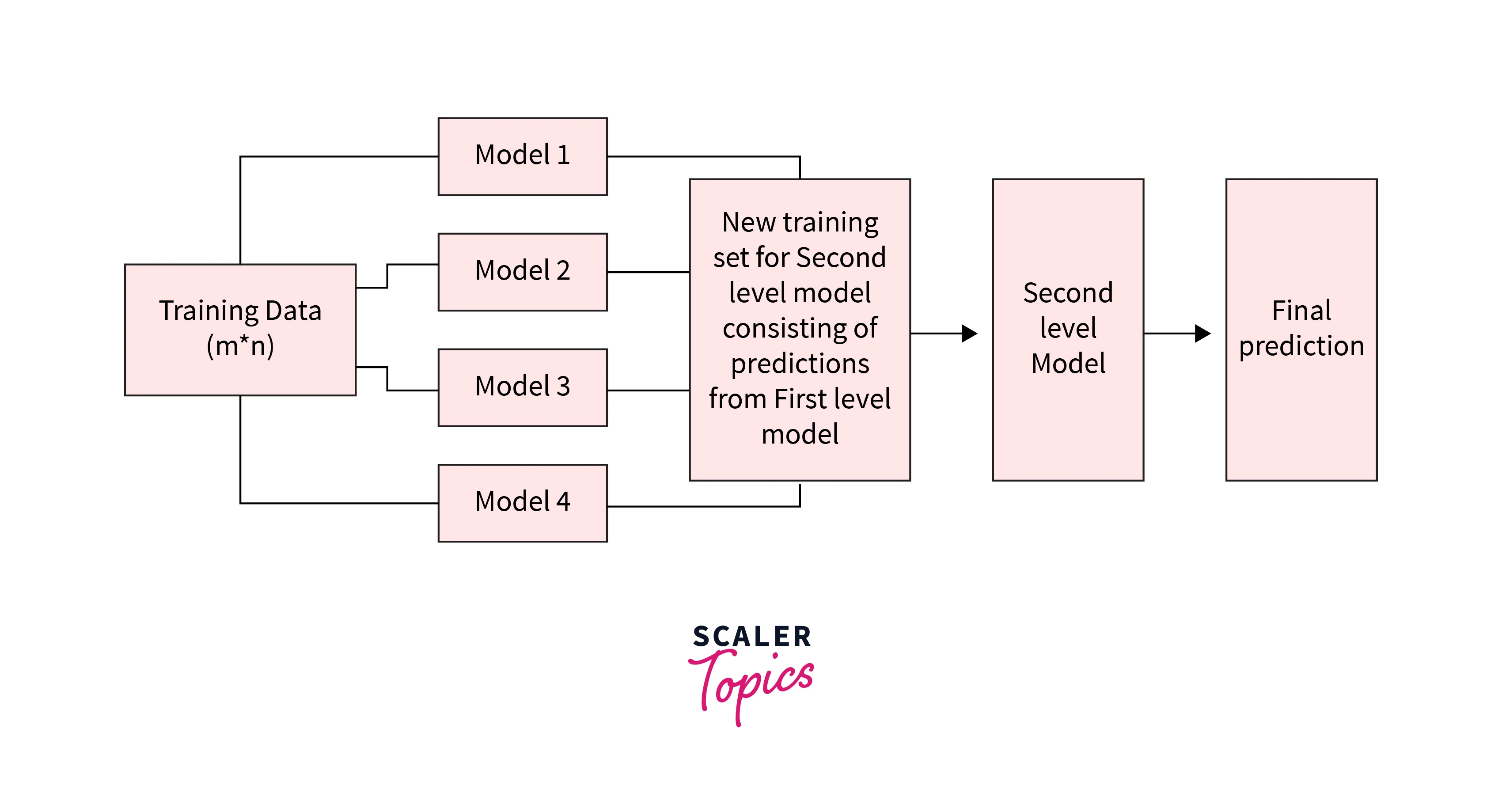
Now that we understand the basics of blending and ensemble learning, let's go on and learn how to create a blending ensemble
-
Blending Ensemble
The scikit_learn library in python is the library that is home to all of the standard Machine Learning algorithms. Unfortunately, it doesn't natively support blending directly. Hence, we will use our models to create a blending ensemble.
In this code snippet, we create some base classifiers (weak learners), followed by the meta-model. In this case, we use the Logistic Regression model. Then, we receive the predictions of the testing dataset, which determines the training data for the meta-model. Finally, we stack the weak learners' predictions and move on to level-1 training.
Developing a Blending Ensemble
Now that we have learned how to create a blending ensemble in python let us go forward and create robust blending ensembles for classification and regression problem statements.
-
Blending Ensemble for Classification
To get started with creating a blending ensemble for classification, we would need to create a dataset. For this example, we will use the make_classification() function in sklearn_datasets to create one.
Like the code snippet above, we will create a get_models() function to aggregate all the classification models.
We will then call the fit_ensemble() method to fit the blending ensemble on the train and testing data, and the predict_ensemble() will generate predictions for us.
Output
-
Blending Ensemble for Regression
The technique to create a blending ensemble for regression problems is quite similar to the one we learned earlier. For regression problems, we would be using different algorithms as weak learners, such as Linear Regression, SVR, and Decision Trees Regressor.
Output
Difference Between Blending and Stacking
As we have seen throughout this article, stacking (aka Stacking Generalization) and Blending are similar in a lot of ways. Both of them work by combining multiple models; predictions are made on the training and validation datasets etc. They do have a few differences, though.
Blending
Blending employs a validation set that is 10-15% of the training set to train the next layer.
Stacking
Stacking uses out-of-fold predictions for the train set of the following layer.
Conclusion
- In this article, we learned about Blending, an ensemble method by which we aggregate a few weak learners (models) and use a holdout (validation) set from the train to make predictions.
- We also understood how to make a blending ensemble from scratch.
- To conclude, we created blending ensembles for classification and regression problem statements.