Boosting in Machine Learning
Overview
One of the most useful and exciting machine learning techniques is Ensemble learning, where we combine several weak models to form a strong one with improved predictions. One such technique is bagging which combines multiple homogeneous weak models and learns from each other independently in parallel and combines them for determining the model average. One major drawback of the bagging algorithm is that it can't deal with mistakes made by individual models. A great alternative that overcomes this drawback is boosted trees or boosting in machine learning.
What is Boosting Machine Learning?
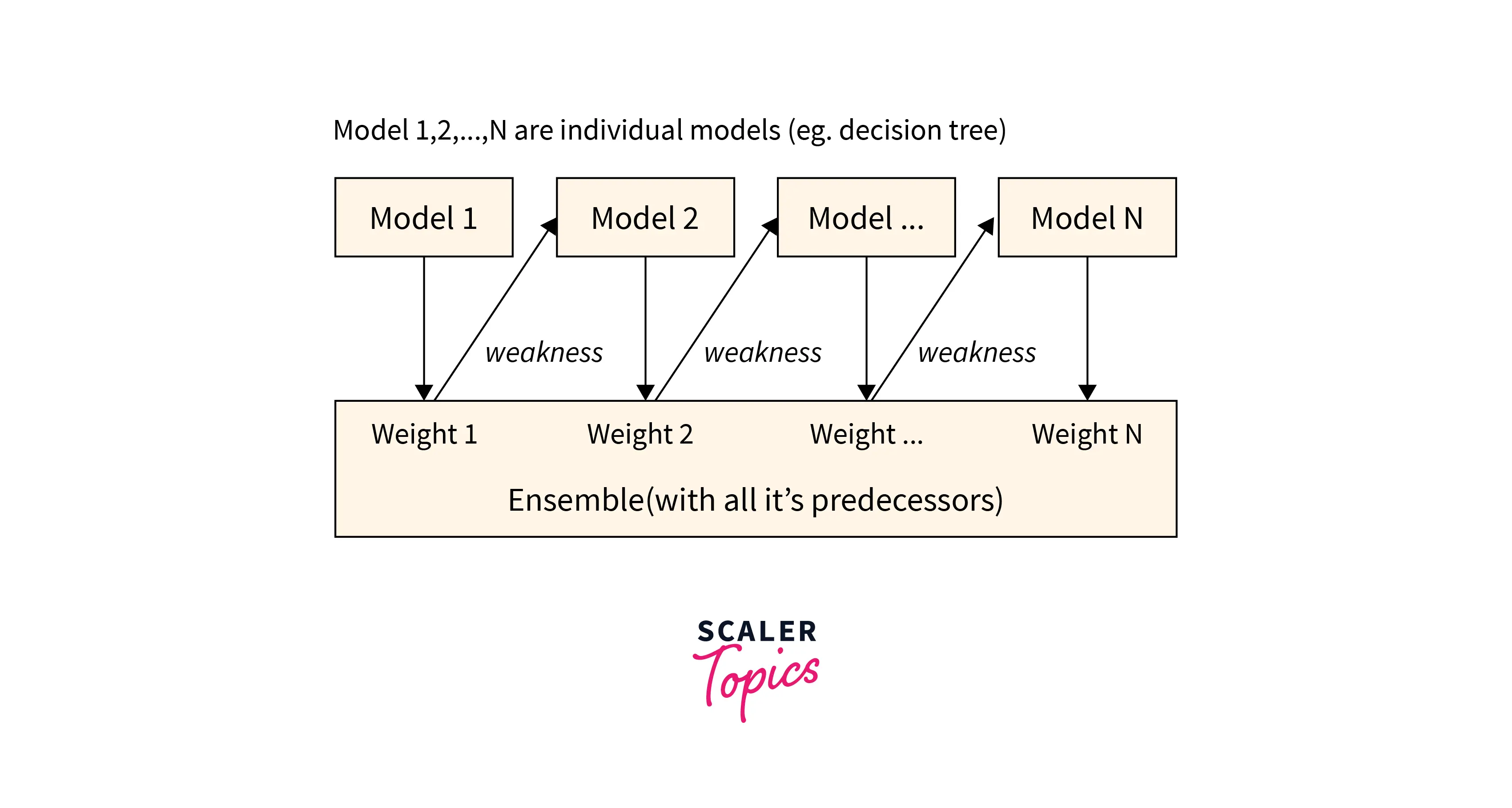
This is an ensemble learning technique with the sole purpose of building a strong classifier from the number of weak classifiers. The weak models are built upon in series. Boosting handles the errors created by previous models. Hence, new models are formed by considering the errors of the previous ones. This type of learning is called sequential learning.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Why is Boosting Important?
Boosting is important in machine learning as it increases the prediction accuracy and performance of machine learning models. It also overcomes underfitting by reducing bias. If one classifier misclassifies a data point, the next one may overcome this and classify it correctly.
Algorithm for Boosting
- We start by initializing the dataset with each data point having the same weight.
- The above dataset is then pushed into the model and we identify the misclassified data points.
- Increase the weight of the wrongly classified data points.
- The second step is repeated until we get the required results.
What are the Types of Boosting?
There are three major types of boosting in machine learning:-
- Adaptive Boosting:- This boosting method is also called Adaboost. It adapts and tries to correct itself in every iteration of the boosting process. It works just like the normal boosting algorithm with the initialization of data points with equal weights and then increasing the weights of the misclassified data points until the required results are met.
- Gradient Boosting:- This method is similar to Adaboost and follows sequential learning. However, Gradient Boosting does not involve increasing the weights of incorrectly classified data points. Instead, optimizes the loss function by generating base learners sequentially. This results in the current learner always being more accurate than the previous one. This method tries to generate accurate results initially instead of step-by-step and can be more accurate than Adaboost.
- Extreme gradient boosting:- This method is also known as XGboost. It is an improvement on gradient boosting as it scales up and increases the computational speed in different ways. It performs parallelization, distributed computing, cache optimization, and out-of-core processing to help in the cause. It uses multiple cores of the CPU so that parallelization is done smoothly.
Benefits of Boosting
- It is easy to implement.
- It is easy to understand and interpret.
- It does not require any data preprocessing and has its own built-in functions.
- It helps to reduce the high bias that is common in machine learning models.
- It handles large datasets efficiently and increases predictive accuracy.
Gradient Boosted Trees
In this process, we combine weak individual learners, decision trees, to develop a strong one. All the trees are connected in series and each tree tries to minimize the error of the previous tree.
 Each new learner fits into the residuals of the previous models in such a way that the model improves.
Each new learner fits into the residuals of the previous models in such a way that the model improves.
Important Hyperparameters
Hyperparameters are the ones that are required to be defined before the training of the model. For a boosting algorithm such as XGBoost, there are a few important hyperparameters.
- The number of sub-trees to train.
- The maximum depth of a tree.
- The learning rate (important).
- The regularization parameters for the weights - L1 and L2 regularization.
- The complexity control (gamma=γ), a pseudo- regularization hyperparameter.
- Minimum child weight, another regularization hyperparameter.
Conclusion
The key takeaways from this article are:-
-
Boosting in machine learning is an ensemble learning algorithm.
-
It builds a strong classifier from the number of weak classifiers.
-
It creates models with better accuracy sequentially.
-
It can also use a gradient mechanism for better computational power and more efficiency.
-
It does not require any data preprocessing as it has built-in functions.