Data Preprocessing in Machine Learning
Overview
Data preprocessing is about preparing the raw data and making it suitable for a machine learning model. Therefore, data preprocessing is the most crucial step while creating a machine-learning model.
Unfortunately, the real-world data is full of inconsistencies, noise, incomplete information, and missing values as it is aggregated from diversified sources using data mining and warehousing techniques. All these necessitate the use of data preprocessing in machine learning.
Introduction to Data Preprocessing in Machine Learning
The real-world data needs processing before feeding it to a machine-learning model. We know that 80% of a data scientist’s time goes into data preprocessing and 20% of the time into model building.
The statement is true because if we feed unclean, noisy data to the model, it will either fail to process it or generate erroneous output. Hence, data preprocessing is a crucial step in machine learning. This article will use examples to teach different data preprocessing steps, like data cleaning, transformation, quality assessment, and transformation.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Why do We Need Data Preprocessing?
-
Improving Data Quality: Data preprocessing is essential for enhancing the quality of data by handling inconsistencies, inaccuracies, and errors, which is critical for ensuring reliable and robust analytics.
-
Dealing with Missing Values: Data preprocessing includes techniques like imputation that are critical for dealing with missing data effectively, as datasets often have missing values which can significantly hinder the performance of machine learning models.
-
Normalizing and Scaling: Data preprocessing helps in normalizing or scaling features, which is especially important for algorithms that are sensitive to the scale of the input. This ensures that all the features are on a comparable scale, which is crucial for the accurate performance of many machine learning algorithms.
-
Handling Outliers: Through data preprocessing, outliers can be identified and managed appropriately. This is important as outliers can have a disproportionate effect on the modeling process and can lead to misleading results.
-
Dimensionality Reduction: Data preprocessing includes techniques such as Principal Component Analysis (PCA) for reducing the number of input features, which not only helps in improving the performance of models but also makes the dataset more manageable and computationally efficient.
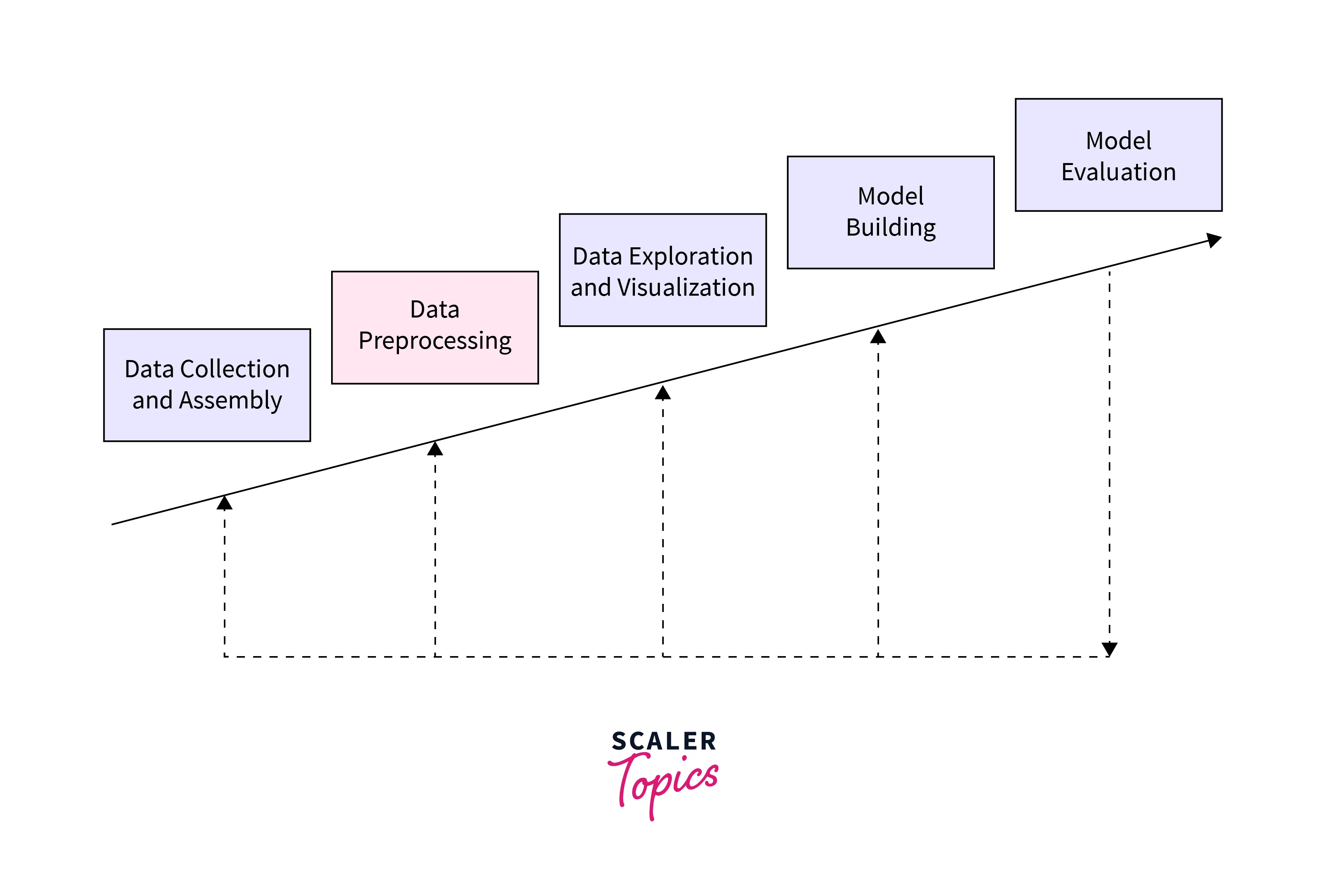
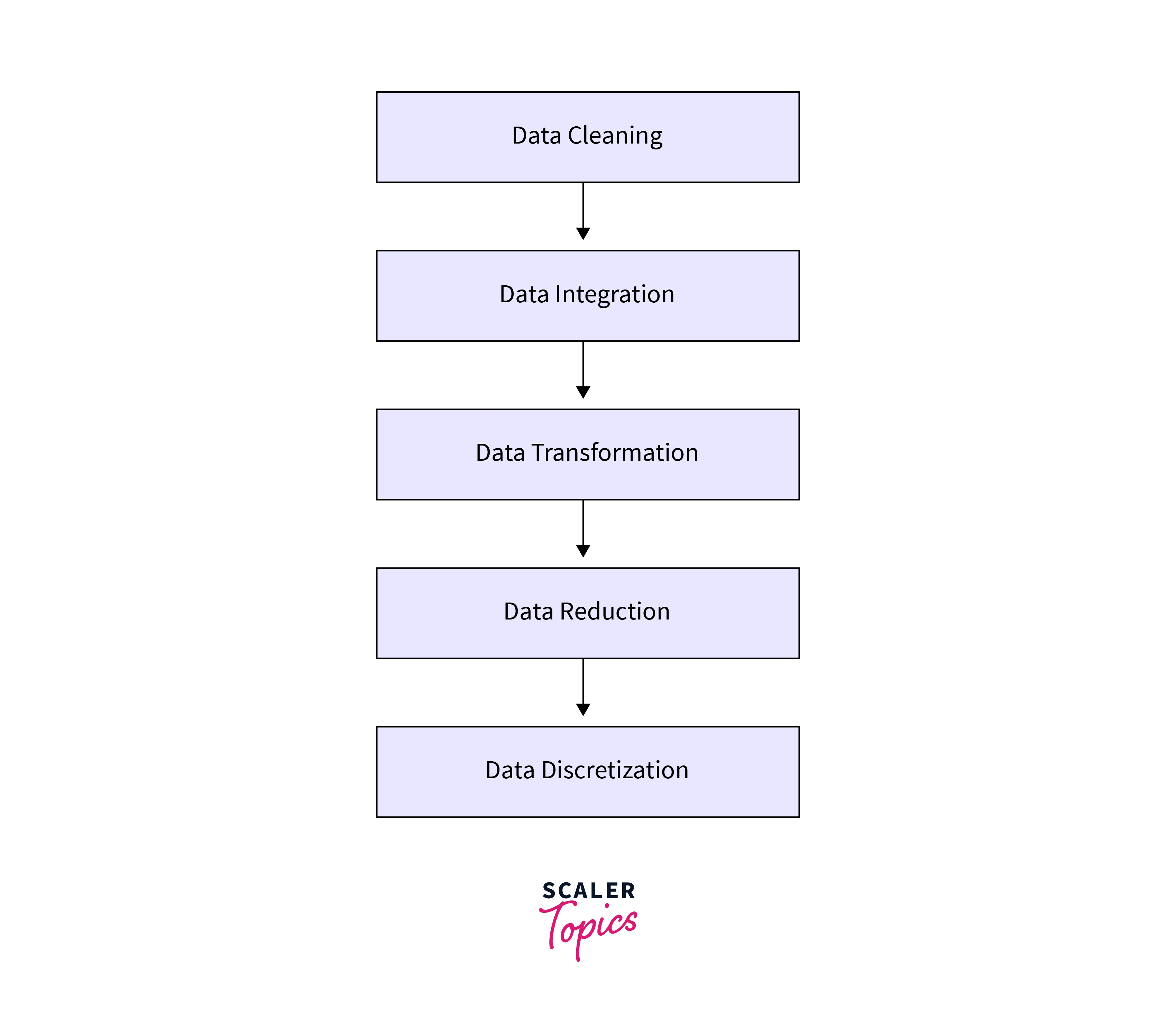
Steps in Data Preprocessing
Data preprocessing consists of several steps. In this article, we will cover the following items:
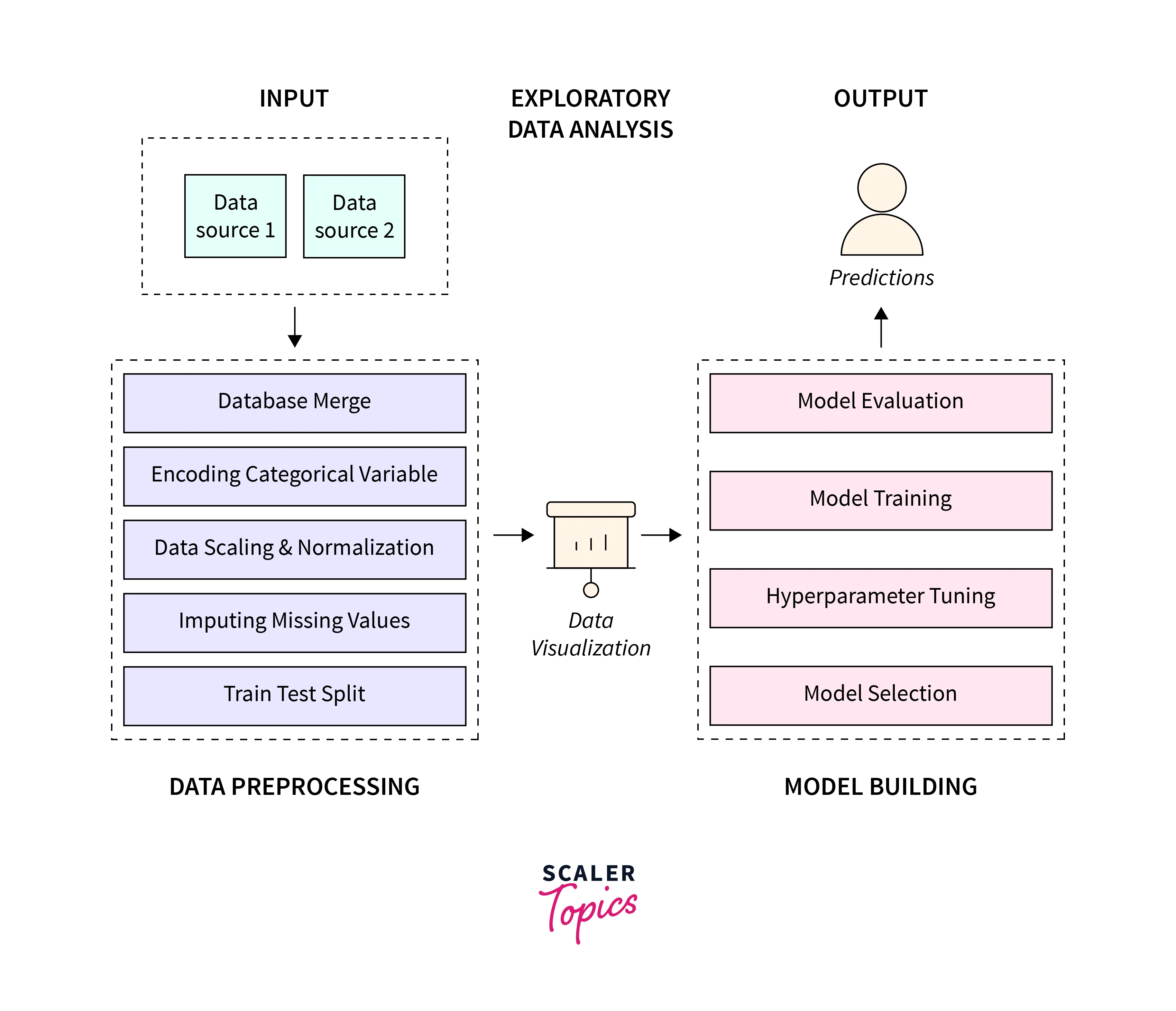
1. Imputing Missing Values:
The missing value is introduced in data for several reasons, including lost data in the channel or sometimes the customer denies providing information(people are reluctant to share their earnings over a survey).
Mean or median is used to impute the value for a numerical feature.
Again, though, the median is preferred as the mean is influenced by the outliers and skewness in the data. The most occurring value, i.e., by mode, is favored for categorical features. When more than a certain percentage(say 40%) of data is missing for a particular column, it's preferred to discard that column instead of imputing it.






2. Removal of Outliers:
BoxPlot helps identify outliers present in data. Next, all the values above and below three standard deviations are considered an outlier and can be removed. It can be achieved using one-line code in python.
3. Data Normalisation:
Normalization is transforming the entire data range so that the data has a mean of 0 and a standard deviation of 1. It does not distort the difference between sample points. It helps optimization functions converge faster. Some standard normalization techniques are discussed below:
-
Min-Max normalization: In this data normalization technique, a linear transformation is performed on the original data. The minimum and maximum values from data are fetched, and each value is replaced according to the following formula.
- Where, A is the attribute data.
- and are A's minima and maximum absolute values, respectively.
- v' is the new value of each entry in the data.
- v is the old value of each entry in the data.
-
Z-score normalization or Zero mean normalization: In this technique, values are normalized based on a mean and standard deviation of the data A. The formula used is .
- Here, v', and v is the new and old of each entry in data, respectively.
- , is the standard deviation and mean of A, respectively.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
4. Encoding of Categorical Variable:
Categorical feature encoding is another essential step in data preprocessing as the machine learning model cannot consume categorical features in their raw form. Categorical varaibles are of two types:
-
Ordinal categorical variables: These variables can be ordered (grades in an exam. Here, one can say that C<B<A). For ordinal categorical features, label encoding is preferred. Label Encoding converts the labels into a numeric form to convert them into a machine-readable format. Here, grades can be mapped to numeric values as follows-> {C:1, B:2, A:3}
-
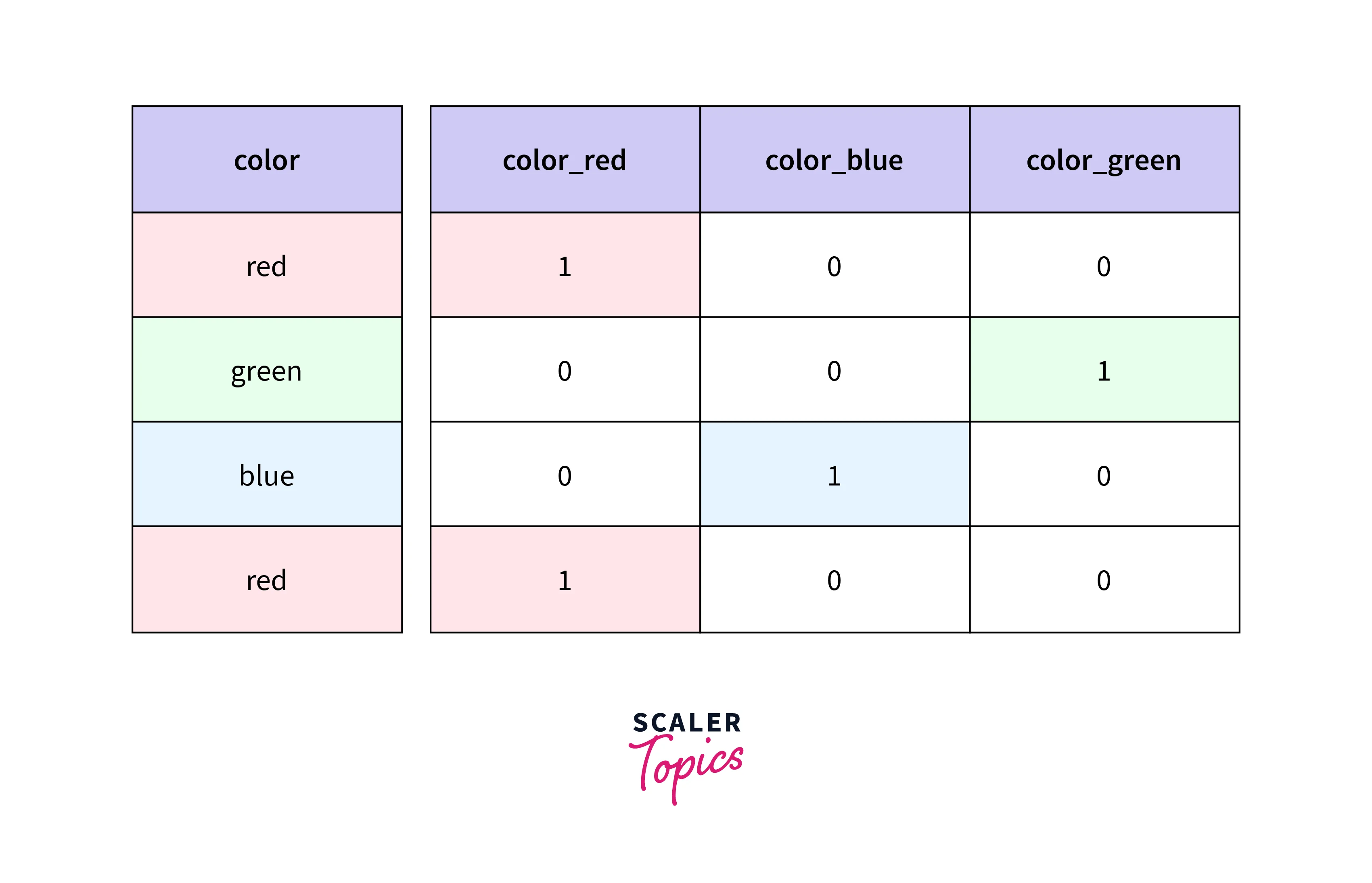
Nominal categorical variables: These variables can’t be ordered (colors of a car). One Hot Encoding(OHE) is preferred in such a situation. In OHE, Each categorical value is converted into a new categorical column and assigned a binary value of 1 or 0 to those columns. The figure below will help to understand the function of OHE.
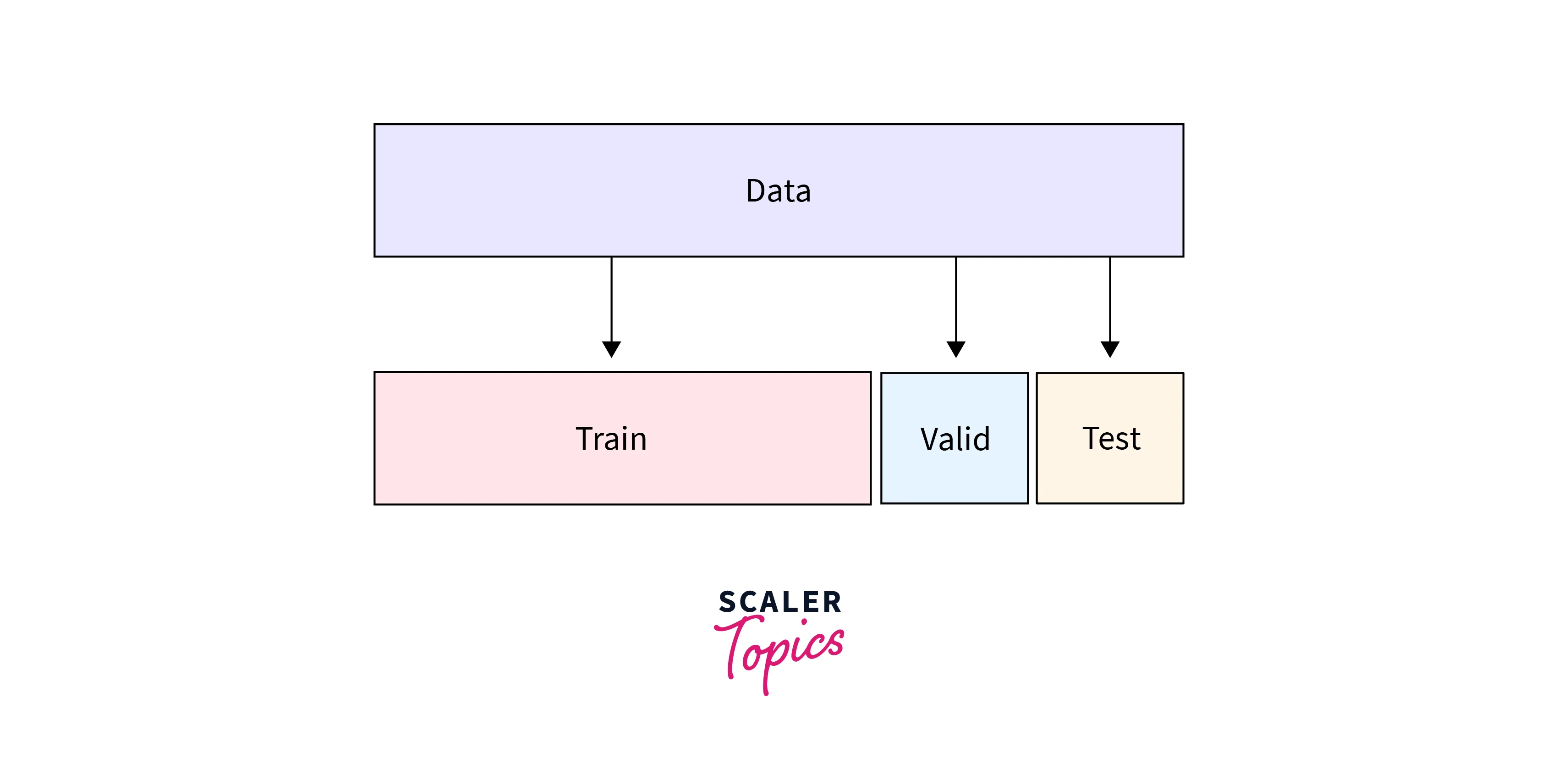
5. Train Validation and Test Split:
After the data preparation, the next step is dividing the data into three parts: training, validation, and test data. First, training data is used to build the model. The model identifies the hidden patterns in this dataset and generates model parameters.
Next, the model is validated on validation data. It helps to determine how the model is performing. Together, Validation and Training accuracy helps to identify any overfitting or underfitting in the data. Validation data also helps to tune the model hyper-parameters. Finally, test data is the unseen data the model uses to predict the output.
Data Preprocessing Examples
Data preprocessing is a crucial step in the data mining process. Below, we are going to show you three simple examples of data preprocessing using Python:
- Handling Missing Values
- Scaling Features
- Encoding Categorical Variables
Let's assume we have a small dataset of people's information that includes their age, height, weight, and country.
Example Data:
| Age | Height (cm) | Weight (kg) | Country |
|---|---|---|---|
| 25 | 175 | 72 | USA |
| 32 | 80 | Canada | |
| 168 | 56 | India |
As you can see, there are missing values in this dataset.
Turn Learning into Career Growth
Example 1: Handling Missing Values
In this example, we will replace the missing values in the 'Age' column with the average age, and in the 'Height' column with the average height.
Output:
Example 2: Scaling Features
Here, we will scale the features 'Height' and 'Weight' between 0 and 1.
Output:
Example 3: Encoding Categorical Variables
Finally, we will convert the 'Country' column from categorical to numerical form.
Output:
In this final output, the 'Country' column has been encoded into numerical features. Each country is represented as a separate column with binary values (0 or 1).
Data Preprocessing: Best Practices
A machine learner practitioner should follow these things about data preprocessing:
- Understanding data, its domain, and each feature's meaning are crucial.
- Visualize data with the help of statistical and visualization tools. It will make data understanding easier.
- Try performing a data quality assessment regarding the number of duplicates, percentage of missing values, and outliers in the data.
- Drop the fields which are intuitively less meaningful. Use feature selection and dimension reduction methods to reduce the dimension.
- Perform feature engineering on remaining attributes and figure out the important done.
Explore a hands-on learning experience with this Data Science Certification Course! Enroll now to gain certification from the best in the field!
Conclusion
- In this article, we have discussed what data preprocessing is in machine learning, why we need to perform data preprocessing in machine learning, different steps of data preprocessing, etc..
- Some examples of data preprocessing and best practices for data processing are also delivered here for a better understanding of readers.
- Data visualization is not discussed here. Instead, it will be delivered in the following article.