Ensembling in Machine Learning

Overview
A robust method for enhancing your model's performance is ensemble modeling. Applying ensemble learning over and above any other models you could develop could help significantly. People have utilized ensembling in machine learning models and benefitted from them.
Introduction to Ensembling
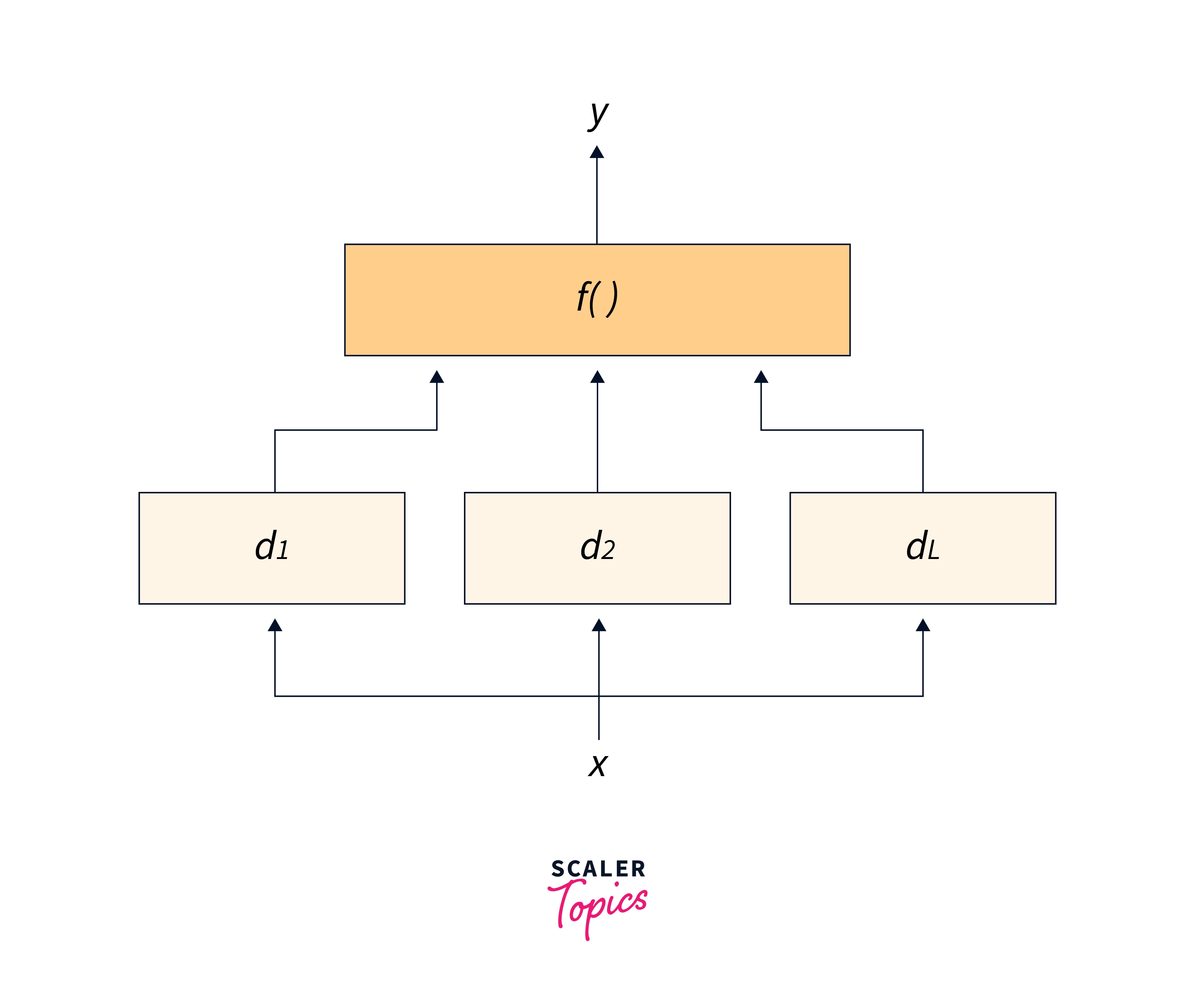
The fundamental idea of ensembling in machine learning is that the weak become stronger when united. A powerful learner, known as the ensemble model, is created by carefully combining weak learners, also known as base models. To tackle a specific classification/regression issue that cannot be learned as effectively by any one of its component learners alone, the ensemble model employs many learning algorithms.
Ensemble Algorithm
Since it can be trained and then used to generate predictions, an ensembling in machine learning is a supervised learning algorithm. The objective of ensemble algorithms is to increase generalizability/robustness over a single estimator by combining the predictions of numerous base estimators constructed with a specific learning technique.
Families of Ensemble Methods
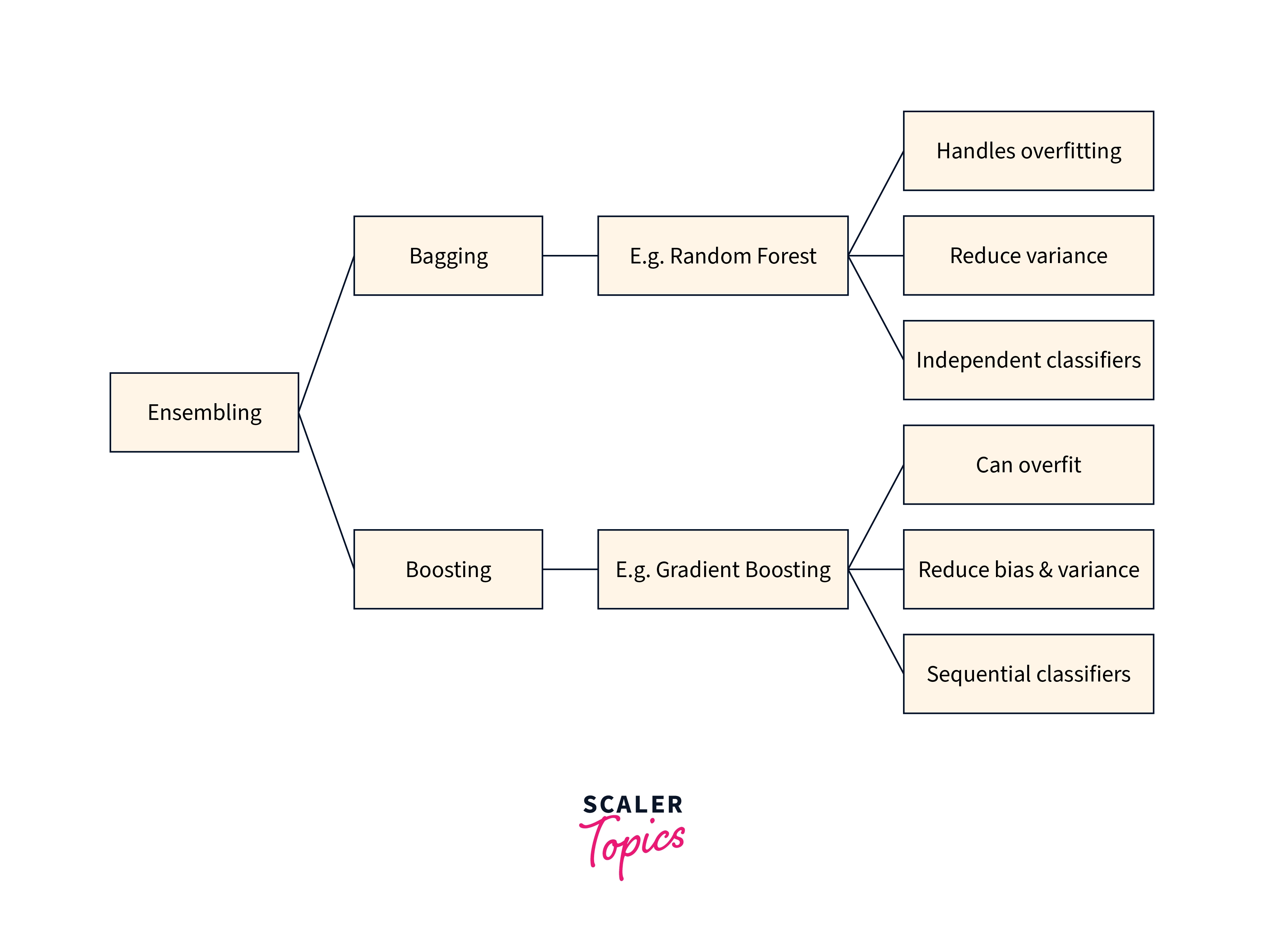
Two ensemble technique families are often distinguished:
- Bagging/Averaging/Voting techniques: The guiding approach is to construct many estimators and then average their predictions independently. Due to its lower variance, the combined estimator performs better on average than any single base estimator. Examples include Bagging techniques and Random Forests.
- Boosting techniques: One attempt to lessen the bias of the combined estimator by building the base estimators successively. The goal is to create a strong ensemble by combining several weak models. AdaBoost and Gradient Tree boosting are two examples.
Advantages of Ensembling
Here are a few advantages of ensembling in machine learning algorithms.
- Ensembling in machine learning is a tried-and-true technique that consistently increases the model's accuracy.
- Ensembling increases the model's stability and robustness, resulting in generally acceptable test case performance.
- An ensemble may be used to identify complicated non-linear correlations in the data and linear and straightforward relationships. This may be achieved by creating a two-model ensemble out of two separate models.
Disadvantages of Ensembling
- Ensemble makes it exceedingly difficult to derive any critical business insights at the conclusion and decreases the model's interpretability.
- It takes a lot of time. Thus real-time applications are not the most effective use for it.
- It takes a lot of skill to master choosing models for an ensemble.
Some Commonly Used Ensemble Learning Techniques
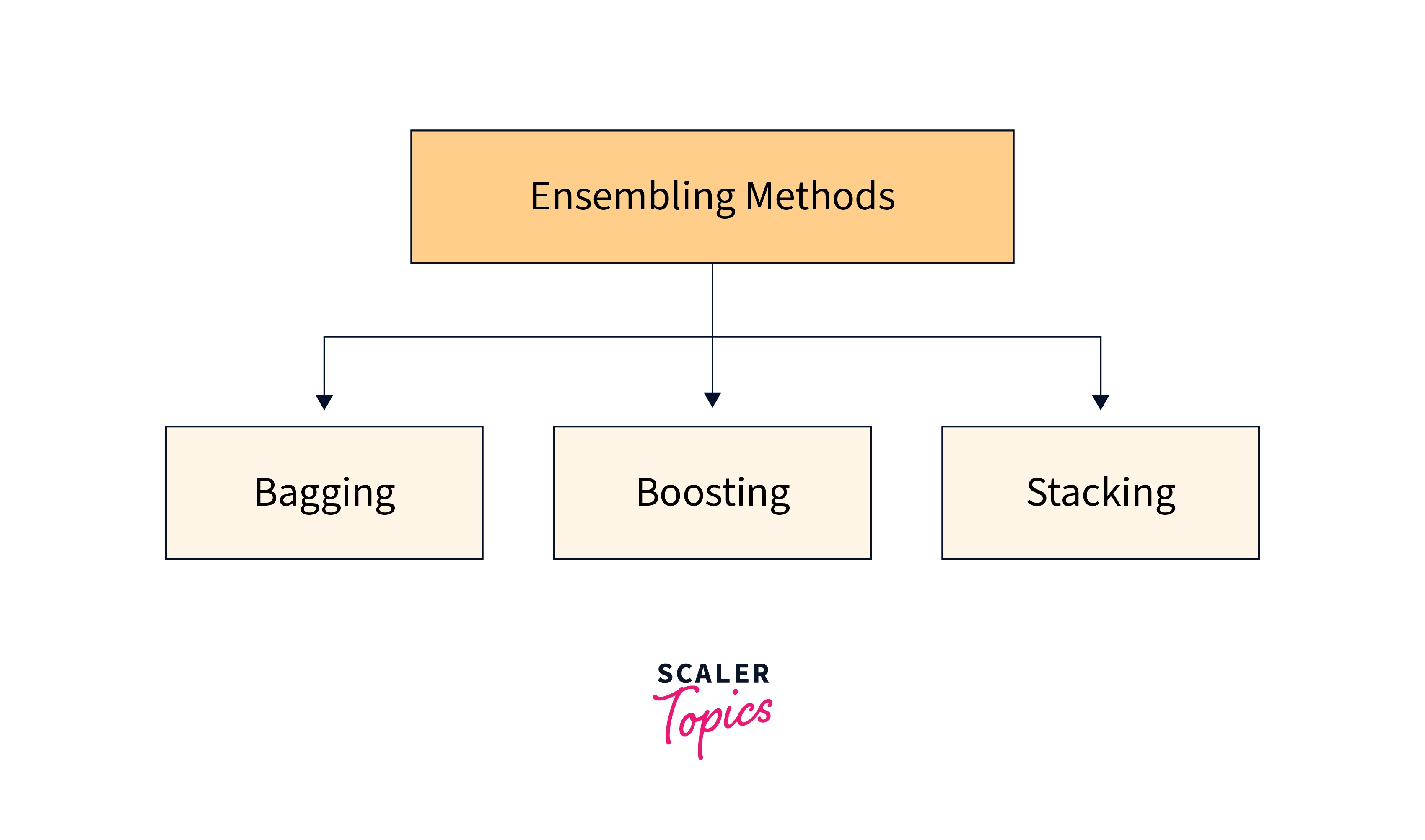
Ensembling in machine learning has seen the following three methods most frequently in action. We will take a quick look at these.
- Bagging
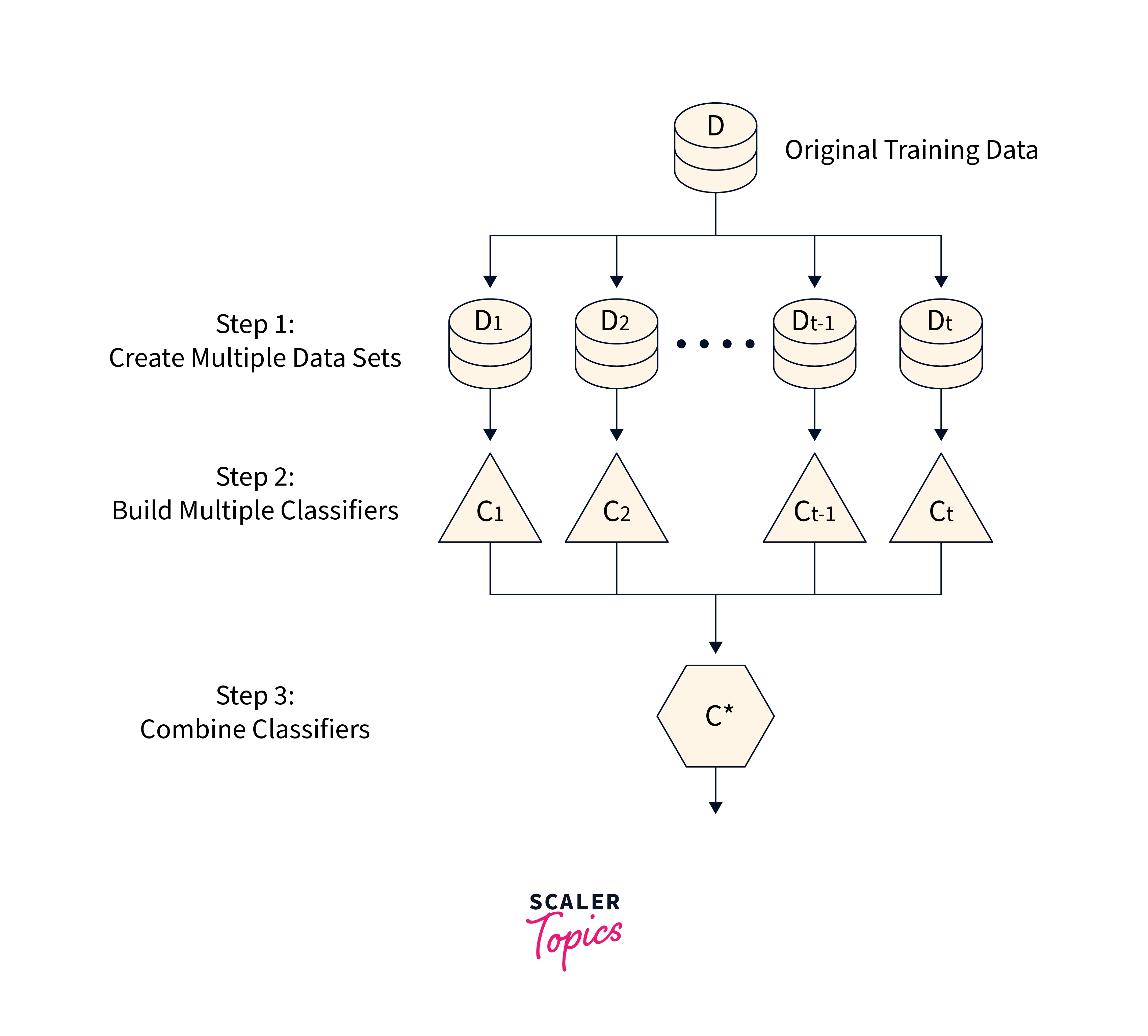
Bagging attempts to apply similar learners on tiny sample populations before calculating the forecasts' average. You may use different learners on various populations for generalized bagging. As you may anticipate, this aids in lowering the variance error.
- Boosting
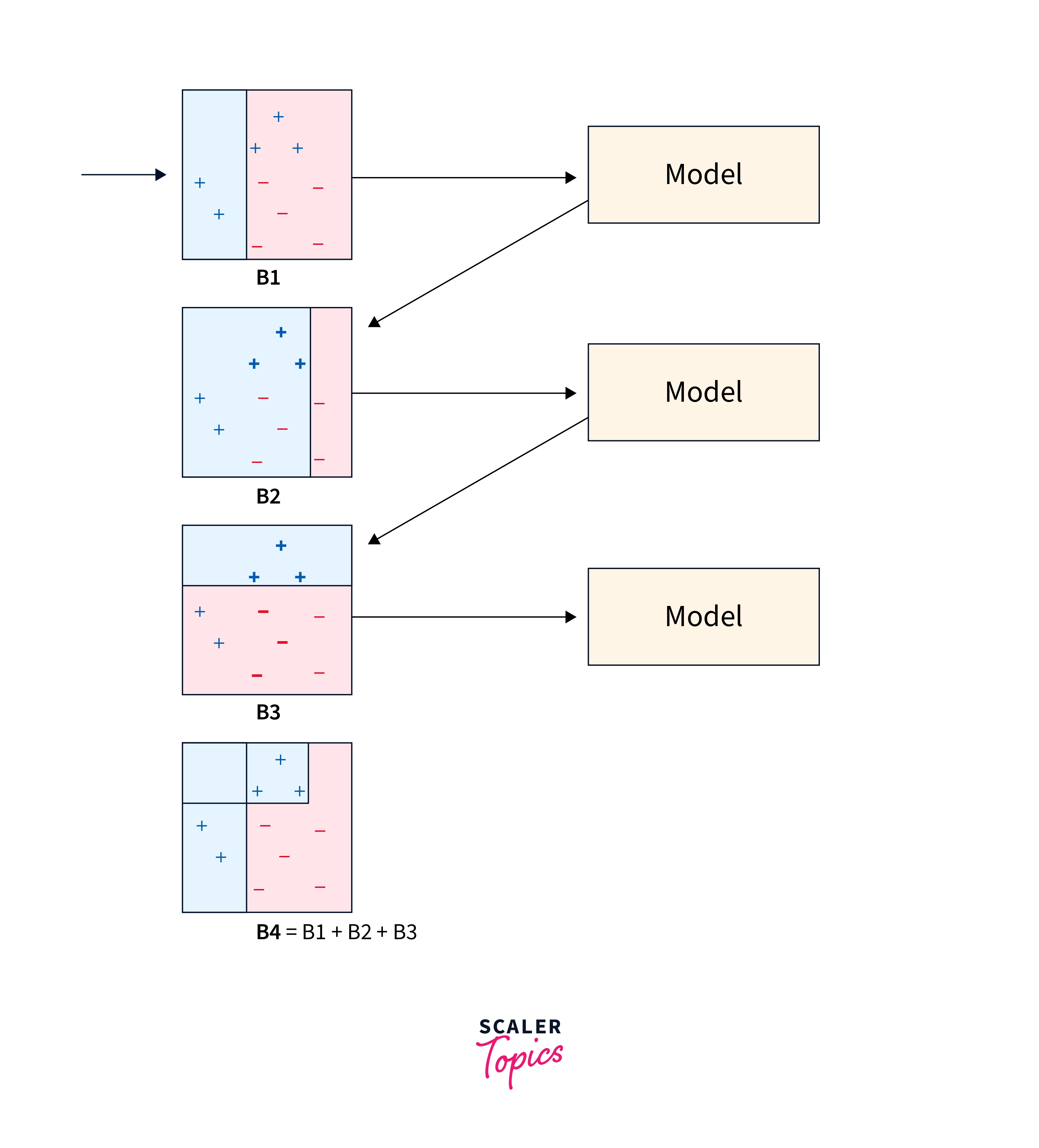
An iterative approach known as boosting modifies the observation weight depending on the most recent categorization. If an observation is mistakenly categorized, an attempt is made to raise its weight and vice versa. In general, boosting reduces bias error and creates powerful prediction models. They occasionally could, however, overfit the training set.
- Stacking
This method of fusing models is quite intriguing. In this case, a learner is used to integrate the output of other learners. Depending on the combining learner we choose, this may result in a reduction in either bias or variance error.
Ensembling Code Implementation in Python
Let us see a demonstration of the averaging ensemble method in Python. Here we used the max voting algorithm, which is commonly used for classification problems. We will use the Heart Disease dataset, which can be found here.
Output:
Conclusion
- We combine weaker learning models to improve their predictions.
- Ensembling in machine learning has two broad families: averaging and boosting.
- Bagging, boosting, and stacking are commonly used ensembling techniques.