What is hyperparameter search in Machine Learning?

Overview
A hyperparameter in machine learning is a parameter whose value regulates how the model learns. Finding the optimum hyperparameters is called hyperparameter search, which involves training models with various hyperparameter settings and seeing how well they perform.
Introduction
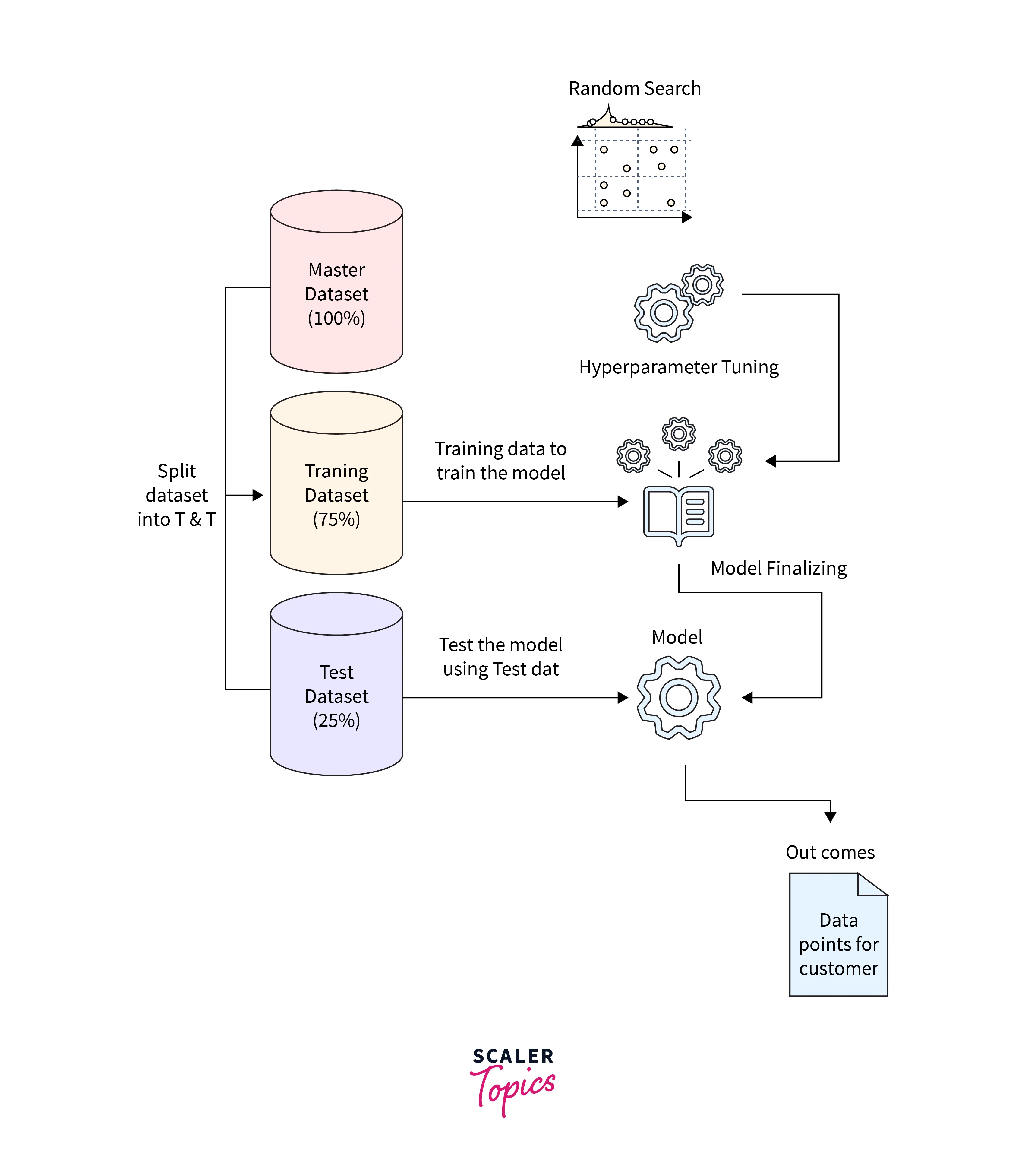
The most crucial step in the training and inference phases is probably finding the proper collection of hyperparameters to obtain the best performance of the machine learning model. This type of search is known as a hyperparameter search. Over the years, several approaches have been created to effectively choose the best collection of hyperparameters. First, we'll talk about the most popular techniques for hyperparameter search.
What are Hyperparameters?
Each machine learning algorithm learns a set of parameters that will result in the best accurate outcome prediction or maximize a certain mathematical measure.
So what makes hyperparameters unique? A hyperparameter in machine learning is a model parameter that regulates the learning process and the choice of models. Before training starts, a hyperparameter's value must be determined.
The hyperparameter directly influences the parameters used for the models. Therefore, although the hyperparameter is not a valid parameter of the model, it is external to the model and is placed higher in the hierarchy.
While the best values for other parameters are determined through training, the best deals for hyperparameters are chosen using expert knowledge or hyperparameter search.
What is a Hyperparameter Search?
Finding the ideal hyperparameters for a learning algorithm is referred to as hyperparameter search, tuning, or optimization. Typically, there are four hyperparameter search methods: grid search, random search, trial-and-error, and Bayesian optimization. While Bayesian uses a sampling strategy, the first three approaches use more or less a brute force approach.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Techniques of Hyperparameter Search
1. Trial and Error
Most often used, this method is straightforward to comprehend. However, according to the model and the application's comprehension, it is a manual procedure that involves experimenting with various combinations.
2. Grid Search
In this brute force approach, each potential combination of each hyper-parameter is tested, and the best one is then used to train the model. It is a thorough search of the model's hyper-parameter space in its whole or a selected subset.
3. Random Search
This search utilizes an iterative approach to find the ideal hyper-parameter values within the hyper-parameter space. Random search selects an arbitrary tuple from the search space. It progresses to better tuples by evaluating them according to predefined criteria rather than forming and assessing every possible tuple.
4. Bayesian Optimization
In this search, the function translating hyperparameter values to the objective function assessed on a validation set is built into a probabilistic model. But first, let's get into more depth about this approach.
Turn Learning into Career Growth
Bayesian Optimization for Hyperparameter Search
Idea
With the help of Bayesian optimization, one may figure out how the values of the hyperparameters translate to the objective function used to calculate the error on the validation set. Here, the hyperparameter values serve as the data points, and the goal is to maximize the efficiency of the objective function that calculates the error on the validation set.
In Bayesian optimization, the function connecting hyperparameter values to the objective function assessed on a validation set is represented by a probabilistic model. Given a collection of hyperparameter values used to train the machine learning model, it calculates the conditional probability of the objective function value for a validation set.
Application
In this case, the goal function parameterized by the hyperparameter values is quite complex and challenging to apply in calculations. A more straightforward process replaces the genuine objective function. The surrogate process is straightforward.
By choosing hyperparameters that perform the best on the surrogate function, Bayesian techniques are utilized to pick the next set of hyperparameter values to assess the genuine objective function. Following are the procedures for applying Bayesian optimization to a hyperparameter search.:
- Build an alternative probability model for the goal function.
- Using Bayes' theorem, identify the best hyperparameters that perform the surrogate model.
- Put the values of these hyperparameters into the actual objective function.
- Update the surrogate model to reflect the new findings.
- Up until the predetermined termination criteria, repeat steps 2, 3, and 4.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Surrogate Function
The chosen hyperparameter values generate the surrogate function, a probability representation of the actual objective function. In essence, it maps the hyperparameter values to the likelihood of achieving a score on the actual objective function.
Acquisition Function
A function computed from the surrogate function and used to direct the choice of the following evaluation point is known as an acquisition function. It is the standard by which the domain of the following objective function point is determined. The new set of hyper-parameters from the domain, which is the search space created by all conceivable combinations of hyperparameter sets, are the issues that are sampled for hyperparameter searches.
Implementation of Grid and Random Search in Python
We'll integrate grid and random search to improve a random forest classifier.
1. Loading the dataset
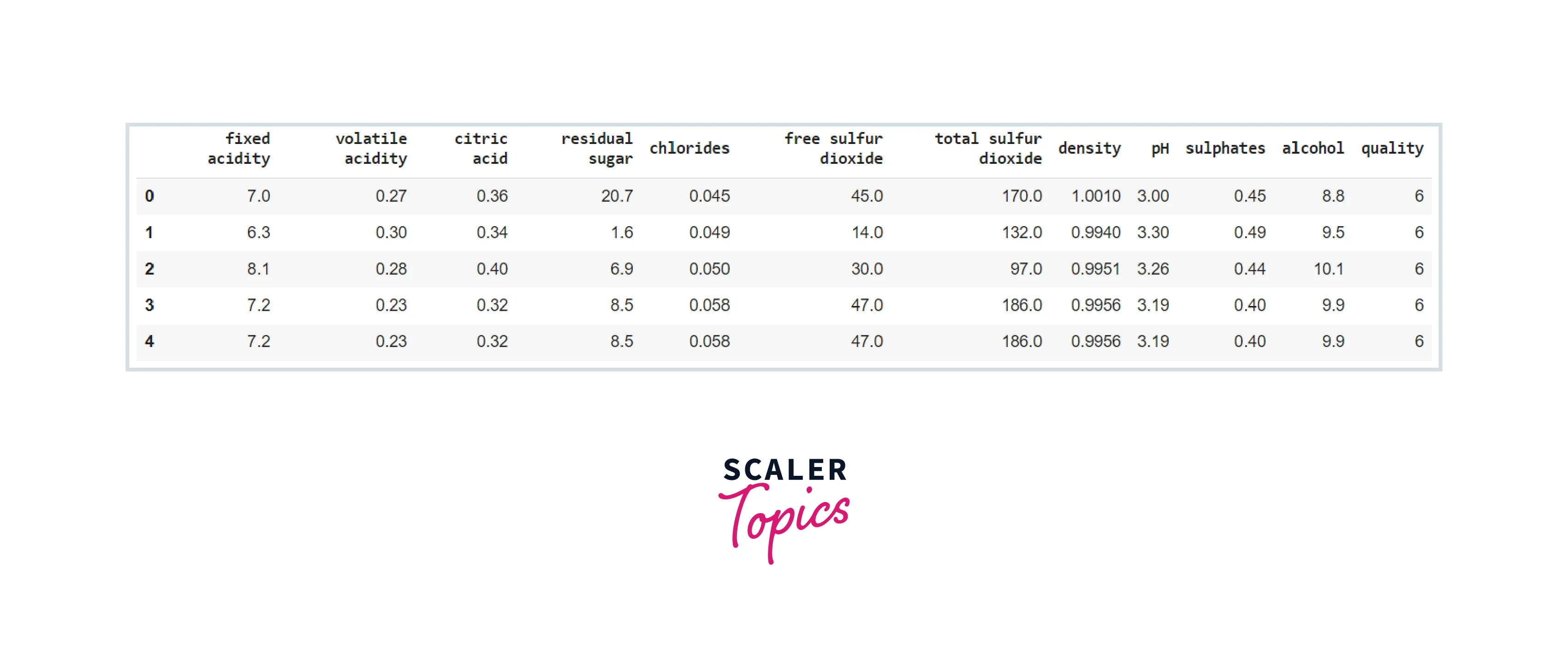
For this example, we will use the Wine Quality dataset, which can be found here.
Output:
2. Data Preprocessing
Values for the goal variable "quality" range from 1 to 10.
We will convert this into a binary classification task by giving a value of 0 to all data points with a quality value of less than or equal to 5 and a value of 1 to the remaining observations.
3. Building the Model
Let's launch a random forest classifier right away. Then, we will adjust this model's hyperparameters to produce the most effective algorithm for our dataset.
4. Implementing Grid Search with Scikit-Learn
Defining the Hyperparameter Space
The dictionary containing several potential values for each of the hyperparameters above will now be created. The best combination of arguments will be found by searching through this area, also known as the hyperparameter space.
Running Grid Search
We must now conduct a hyperparameter search to identify the ideal hyperparameter combination for the model.
Evaluating Model Results
Let's publish the best model accuracy and the collection of hyperparameters that produced this score at the end.
Output:
Let's try the random search now on the same dataset to see if the outcomes are the same.
5. Implementing Random Search Using Scikit-Learn
Defining the Hyperparameter Space
Let's now specify the hyperparameter space for the random search algorithm. Since random search does not test every possible combination of hyperparameters, this parameter space can have a wider range of values than the one we created for the grid search.
Running Random Search
Evaluating Model Results
Run the code below to print the best hyperparameters discovered through random search and the best model's highest accuracy.
Output:
The average accuracy of all the models that have been created is around 0.74.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Conclusion
- Hyperparameter search is the method to determine the best possible hyperparameter values for a given model.
- There are two broad categories of hyperparameter search: brute force and sampling.