IRIS Dataset Project
Overview
Machine learning is a sub-section of artificial intelligence that involves teaching algorithms to make data-based decisions and to attempt to behave like humans. There are numerous datasets available for training these algorithms for different tasks. For example, the IRIS dataset covers three classes of flowers: Versicolor, Setosa, and Virginica, with four features each: 'sepal length', 'sepal width,' 'petal length,' and 'petal width.' This IRIS dataset project aims to predict flowers based on their unique characteristics.
What Are We Building?
In this IRIS dataset project, we will build a machine learning model to classify the flower classes within the IRIS dataset. Then, we will evaluate and test the model to see if it gives accurate predictions on the data. So let's get started with our IRIS dataset project.
Pre-requisites
- A basic understanding of machine learning libraries such as Numpy and Pandas is required.
- Understanding classification in machine learning and classification models such as Support vector machine is essential.
- For the code along, knowledge of Google Colab would be beneficial.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
How Are We Going to Build This?
- Environment - We can use Google Colab to work on this online or Spyder/Jupyter Notebook to work offline.
- Importing - We will load the required datasets and libraries.
- Visualisation - Moving on, we will visualize and analyze the dataset to understand underlying patterns.
- Traning the model - We will split the dataset into train and test sets and then use the support vector machine algorithm to train the classifier.
- Evaluation - Further, we will evaluate the trained model.
- Testing - Finally, we will test the model on some inputs to see if it gives us the desired results.
Final Output

Our final output will look like this when the model predicts the results. Our inputs will include four parameters: sepal length, sepal width, petal length, and petal width.
Output:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Requirements
These are some of the libraries and modules we will use for this IRIS dataset project.
- Numpy
- Matplotlib
- Seaborn
- Pandas
- Scikit-learn
Building the Classifier
Turn Learning into Career Growth
Load the Data
Let's understand the dataset a little further. Each observation has four features: sepal length, sepal breadth, petal length, and petal width. There are no empty fields. Each of the three species, setosa, versicolor, and virginica, has 50 observations.
We will begin the IRIS dataset project by loading the dataset, which can be found here. To do so, we will use the Pandas library with its read_csv function.
Output:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Analyze and Visualize the Dataset
Let us visualize the dataset to see if we can find any correlation between the classes in this IRIS dataset project.
Output:
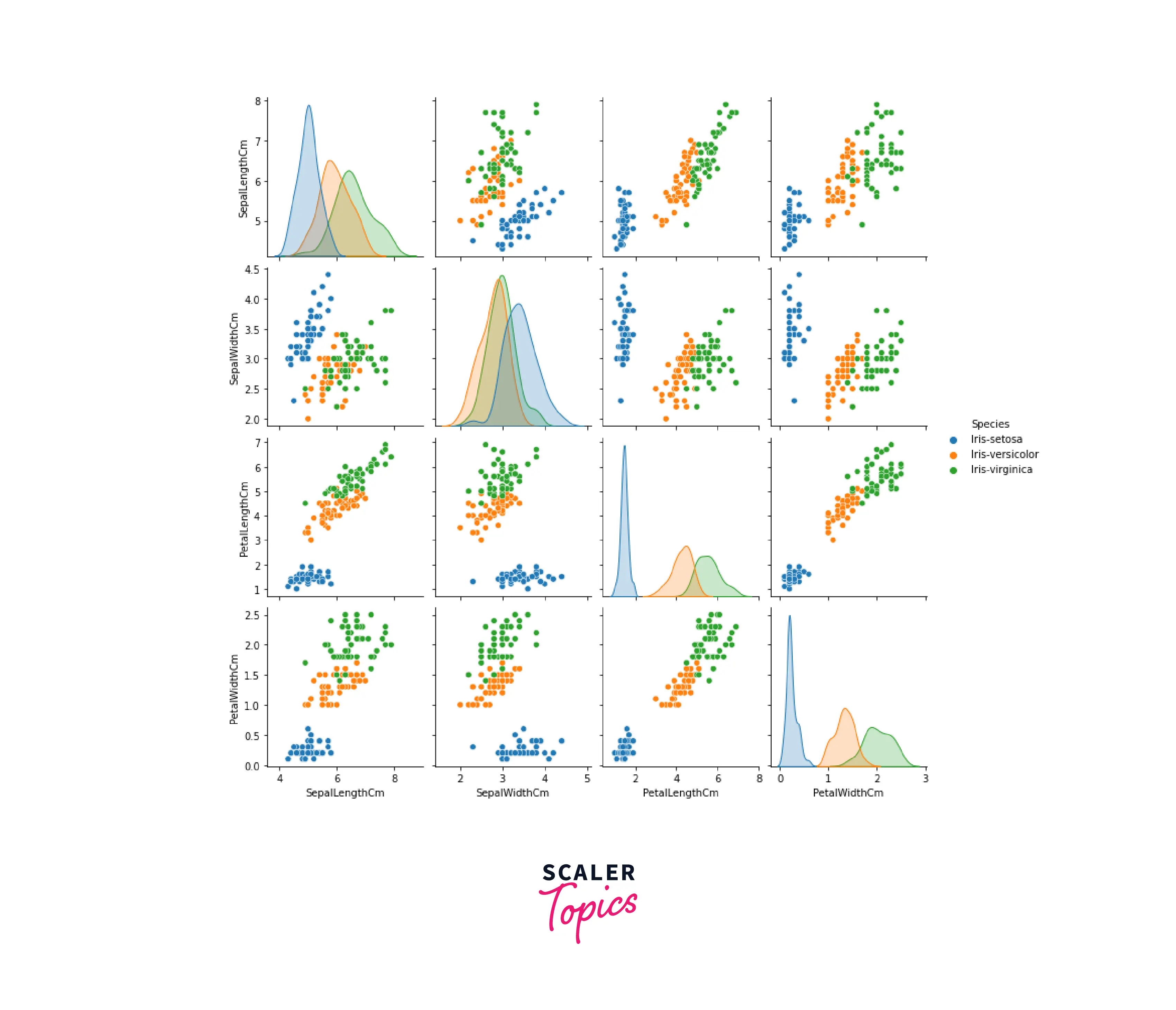
- After graphing the features in a pair plot, it is clear that the relationship between pairs of components of an iris setosa is distinctly different from those of the other two species.
- We can also see that iris virginica is the longest flower and iris setosa is the shortest.
Train the Model
Let us now separate the target values from the features as below. X will have the feature values, and Y will be the corresponding target values.
We divided the entire dataset into training and testing datasets using train_test_split. Later, we'll utilize the testing dataset to assess the model's correctness.
We'll import a support vector classifier using the scikit-learn support vector machine. Then we'll make an object out of it and call it a model. The training dataset is then fed into the algorithm through the model.fit() method.
Now our model is trained and ready to make some predictions.
Model Evaluation
We now predict the classes from the test dataset using our training model. The projected classes' accuracy score is next checked. accuracy_score() returns the percentage of accuracy based on true and forecasted values.
Output:
The accuracy is above 96%.
Model Testing
We take random values based on the average plot to see if the model can predict accurately.
Output:
The model appears accurate.
Conclusion
- We have successfully created a classifier for our IRIS dataset project.
- You can go ahead and try other machine learning models for classification, such as logistic regression, KNN, and random forest and compare their performances on this dataset.