K-Means Clustering in Machine Learning
Overview
Earlier, we learned that unsupervised machine learning algorithms make inferences using the dataset where the label is not present. K-means clustering in machine learning is one of the most straightforward and famous unsupervised machine learning algorithms. A cluster is a collection of data points aggregated based on certain similarities. The objective of K-means clustering in machine learning is simple: it groups similar data points and discovers underlying patterns. It needs a fixed number(k) of clusters in a dataset to achieve this objective.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
What is the K-Means Algorithm?
K-means clustering in machine learning is one of the most simple yet powerful unsupervised machine learning algorithms. K-means clustering in machine learning works by creating a centroid for a desired number of classes and then assigning data points to clusters based on which reference point is closest. One of the crucial caveats of K-means algorithms is choosing the value of K. Here, we have discussed a popular method for selecting the value of K in the K-means algorithm in machine learning. The algorithm has several applications, including document classification, image segmentation, recommendation systems, etc.
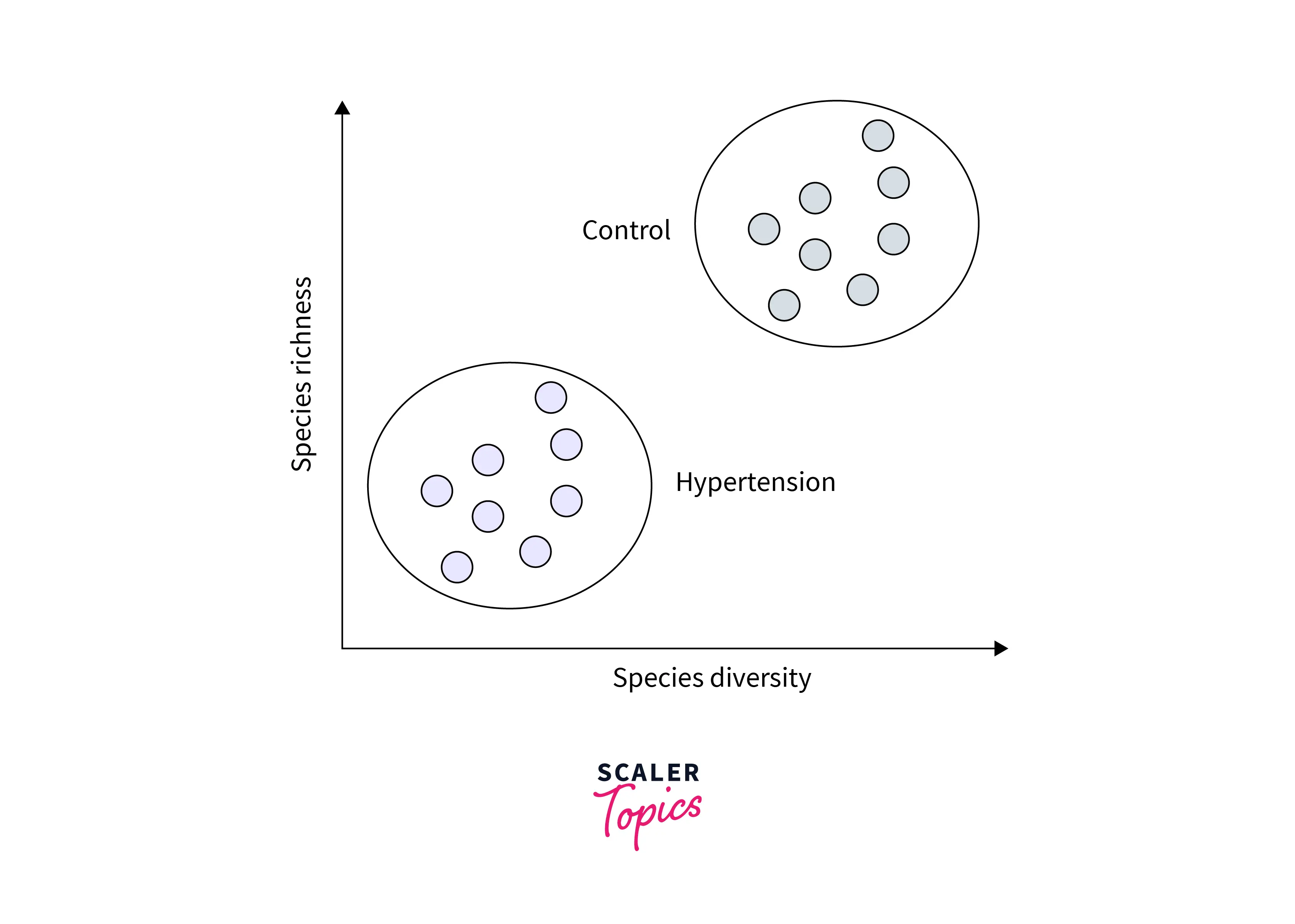
How Does the K-means Algorithm Work?
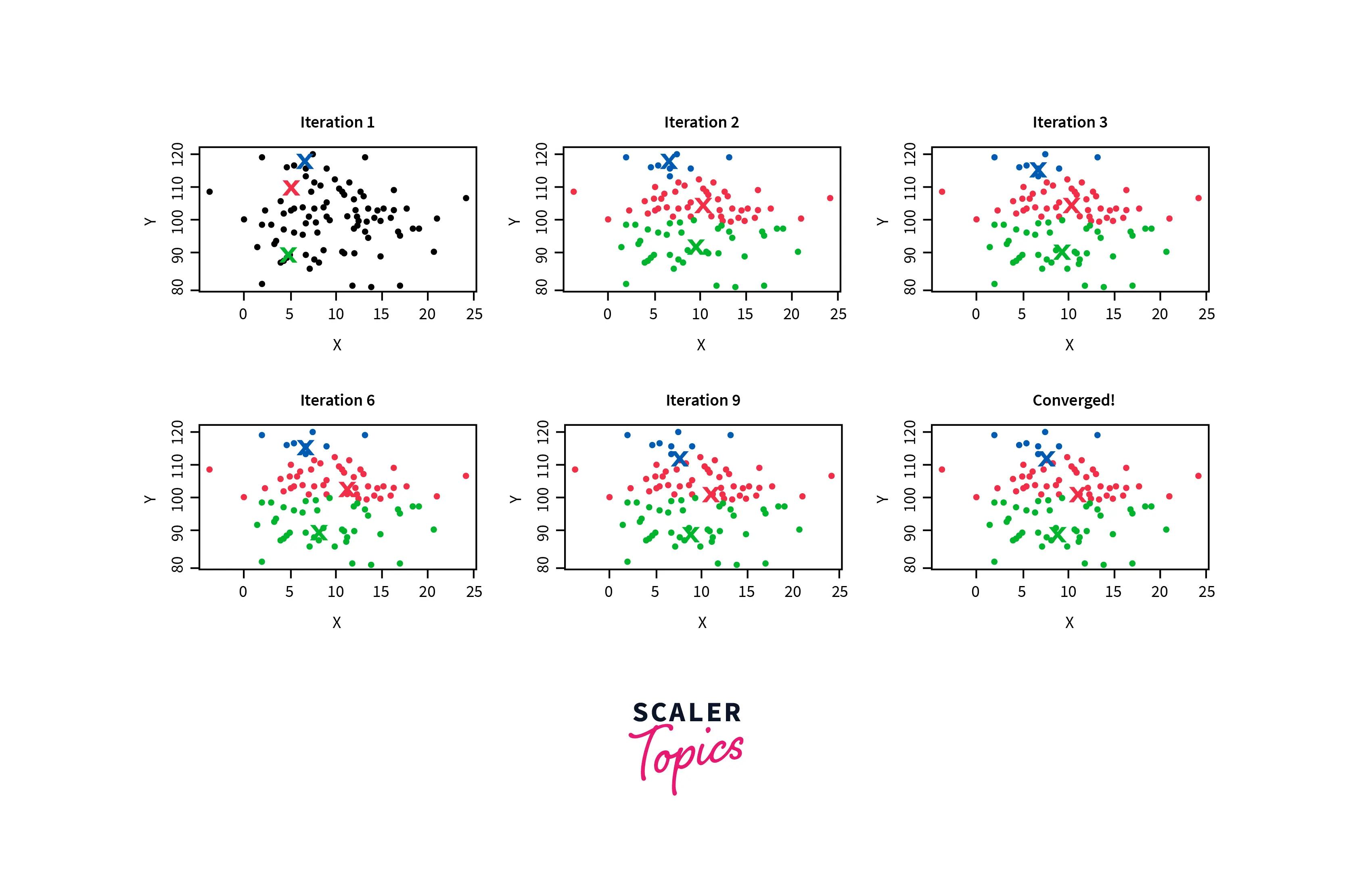
The working of the K-Means clustering in machine learning is explained in the below steps:
- Step 1: First, decide the number of clusters, i.e., K.
- Step 2: Select random K points or centroids. The centroids may not be from the input dataset.
- Step 3: Assign each data point to its closest centroid. It will form the predefined K clusters.
- Step 4: Calculate a new centroid of each cluster, taking an average of samples belonging to the same cluster.
- Step-5: Repeat step 3, which means reassigning each datapoint to the new closest centroid of each cluster.
- Step-6: If no new reassignment occurs, then the model is ready. Else, go to step 4.
How to Choose the Value of K Number of Clusters in K-means Clustering?
The elbow method is used to determine the optimal value of K to perform the K-Means Clustering in machine learning. It plots the loss function by changing K. As the number of clusters increases, there will be fewer elements in the cluster. Hence, average distortion will decrease. The point where the distortion declines the most is the elbow point.
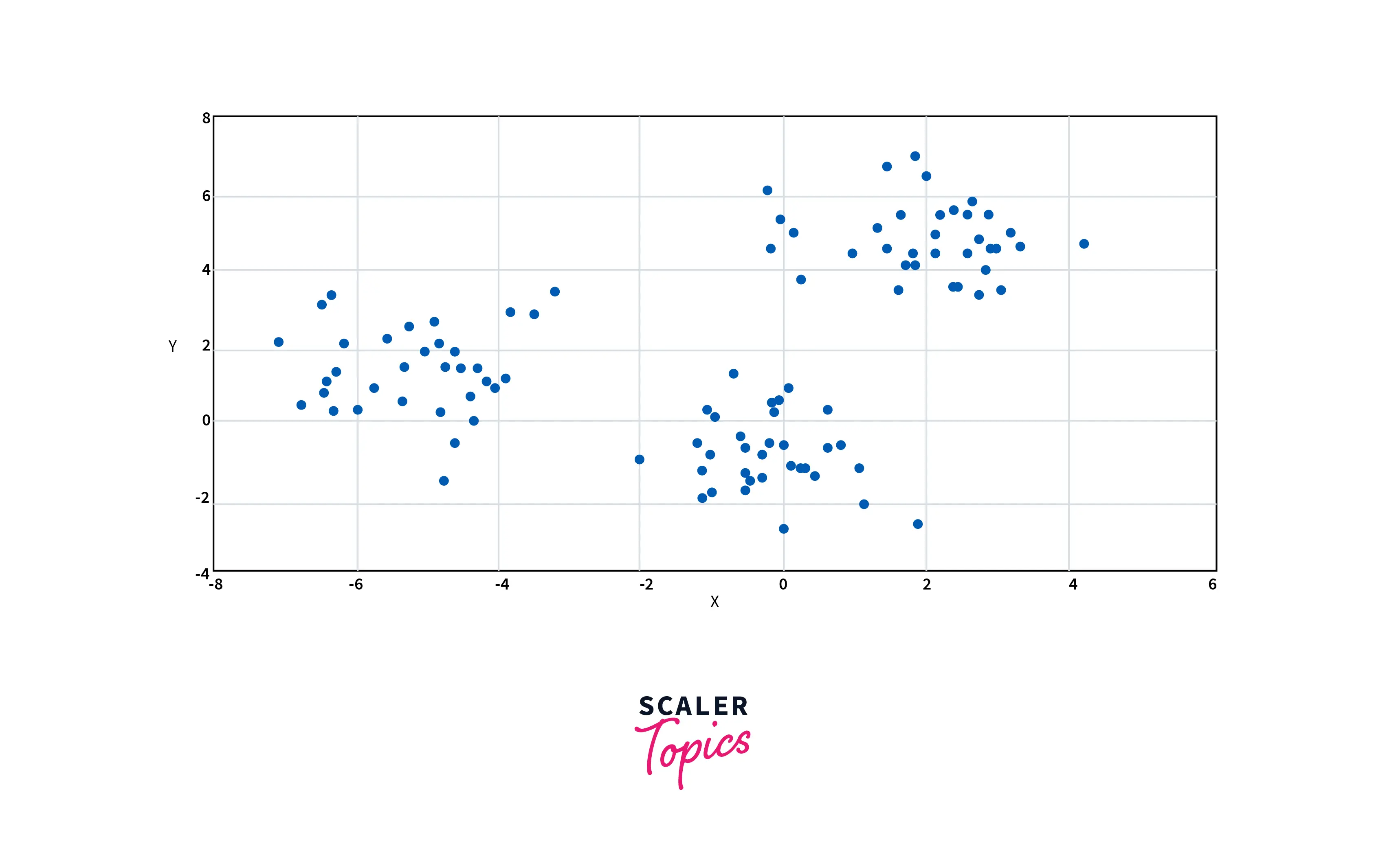
The above figure clearly shows that the points' distribution is forming 3 clusters. Now, let's see the plot for the loss function for different values of K.
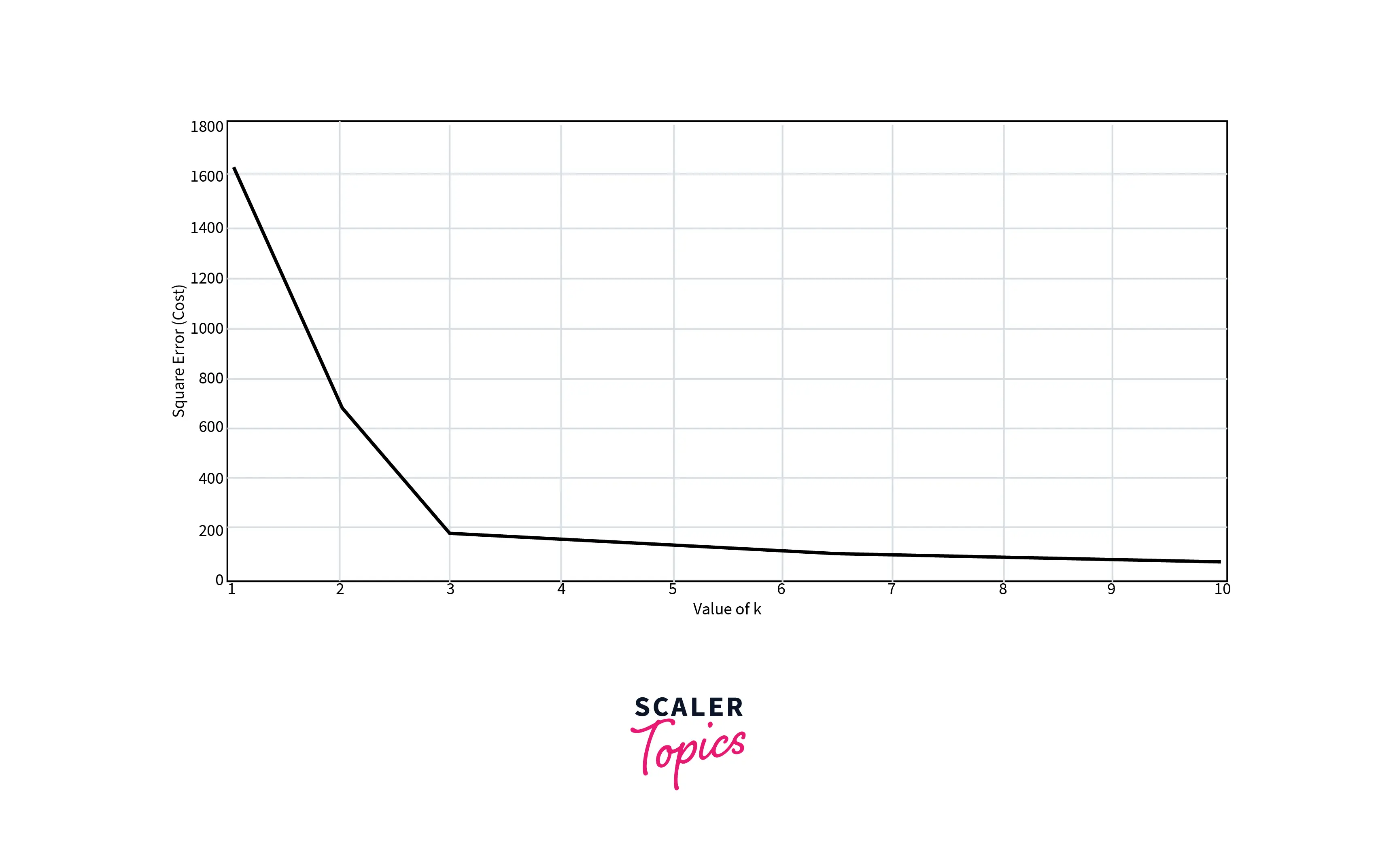
The elbow is forming at K=3. So the optimal value will be 3 for performing K-Means.
Python Implementation of K-means Clustering Algorithm
The code for building the K-means clustering model is shown below:
The below code is for testing the K-means clustering in machine learning against the digit dataset.
The output for the above code is shown below:
Applications of K-Means Clustering
-
Customer Segmentation: K-means clustering in machine learning permits marketers to enhance their customer base, work on a target base, and segment customers based on purchase patterns, interests, or activity monitoring. Segmentation helps companies target specific clusters/groups of customers for particular campaigns.
-
Document Classification: Cluster documents in multiple categories based on tags, topics, and content. K-means clustering in machine learning is a suitable algorithm for this purpose. The initial processing of the documents is needed to represent each document as a vector and uses term frequency for identifying commonly used terms that help classify the document. The document vectors are then clustered to help identify similarities in document groups.

-
Delivery store optimization: K-means clustering in machine learning helps to optimize the process of good delivery using truck drones. K-means clustering in machine learning helps to find the optimal number of launch locations.
-
Insurance fraud detection: Machine learning is critical in fraud detection and has numerous applications in automobile, healthcare, and insurance fraud detection.
K-Means clustering in machine learning can also be used for performing image segmentation by trying to group similar pixels in the image together and creating clusters. The different clusters formed are other objects in a photo. K-means clustering can also be used in recommendation engines; for example, in a music streaming application, similar types or genres of songs are grouped for a user based on their listening patterns, and the application can recommend the most similar songs.

Enhance your machine learning skills by mastering the mathematics behind it. Join our specialized Maths for Machine Learning Course now!
Conclusion
- In this article, we have covered K-means clustering in machine learning, how it works, and how to choose the number of clusters for K-means clustering.
- We have presented a python code for a better understanding of the learners.
- Some applications of K-means clustering are also presented in this article to demonstrate the importance of K-means clustering in machine learning.
- Other variants of the clustering algorithm, like hierarchical clustering, will be covered in subsequent articles.