Dealing with Unclean Data - Imputing Missing Values
Overview
Missing values may get introduced due to different reasons in data. Sometimes data is not appropriately collected due to collection and management errors or intentionally omitted. Human error also contributes to missing data. Most machine learning models don't allow missing values. Hence, one must impute the data before feeding it to a machine-learning model. There are several ways to impute the missing value in data. Based on different parameters, one must judiciously choose the imputation technique. Otherwise, it will affect the model's performance by disturbing the overall distribution of data values. This article will cover different types of missing values, how to find missing values, mean median, knn-based imputation, and statistical imputation techniques.
Prerequisites
Learners must know different metrics for performance measurement of machine learning algorithms like precision, recall, f1 score, etc. Knowledge about Mean, median, and other statistical measures is required. Ideas about KNN learning algorithms are also required.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Introduction
Missing values in machine learning datasets may occur due to different reasons. Sometimes it is due to information loss, or the user feels uncomfortable sharing information(exp. salary). However, one can not run a model in the absence of any feature value. Hence it is required to impute missing cells with specific values. Before we move into imputation methods, let us learn the nature of missingness in data.
Types of Missing Data
Broadly, types of missing data can be divided into three categories.
Missing Completely at Random (MCAR): When the missing value does not depend on any known/unknown factor of data. For exp. Values for some cells are being dropped randomly.
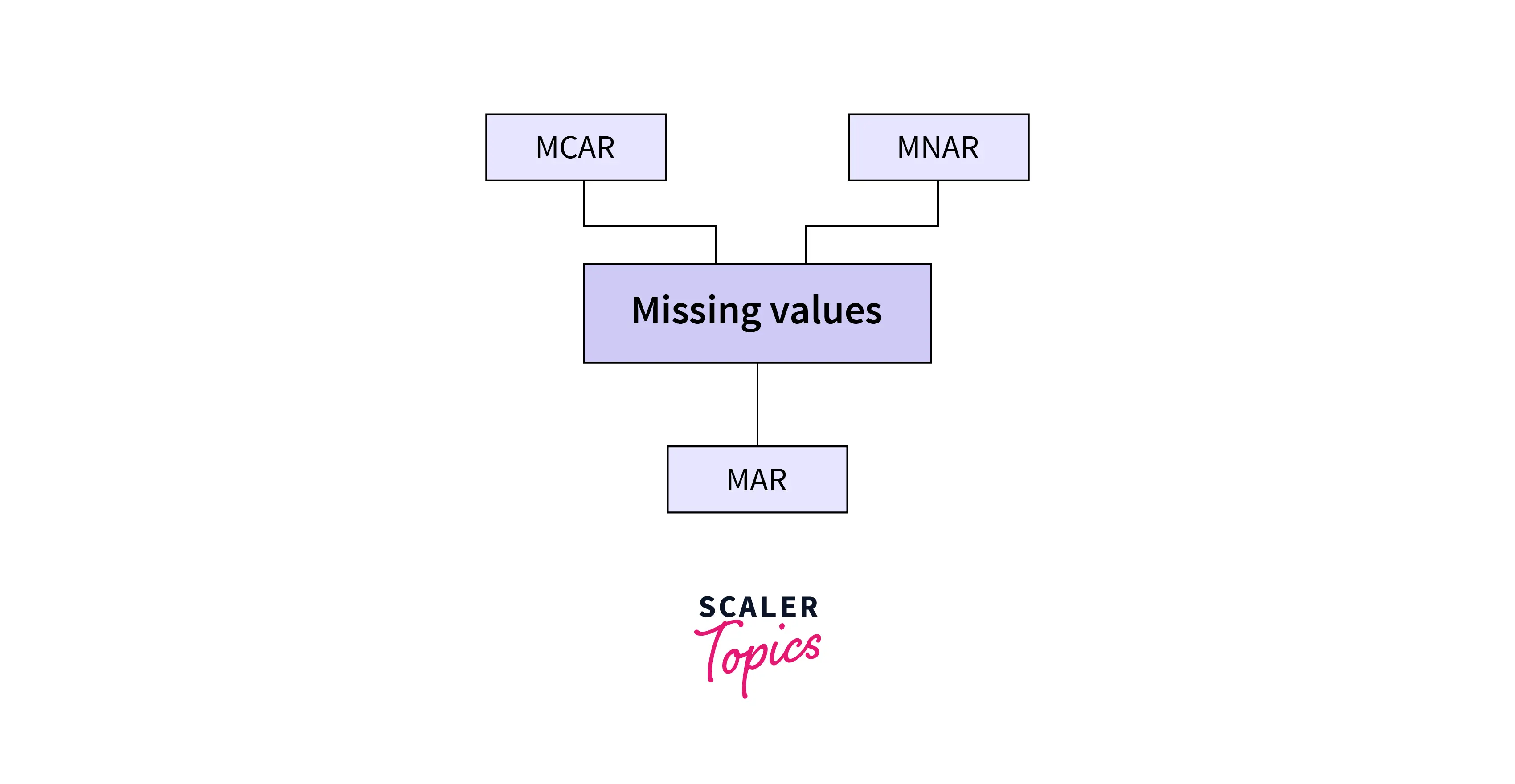
Missing at Random (MAR): Here, an instance of a cell is missing because of some known value in the same sample. For example, a fraudulent builder is not sharing its office zip code for real estate data.
Missing not at Random (MNAR): Here, the value for the missing cell depends on the variable itself. For example, people earning more are uncomfortable sharing their salary.
Based on the nature of the missingness and distribution of a feature, a different imputation technique turns out to be the winner.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
How to Find the Missing Values?
The first step in handling missing values is to look at the data carefully and find out all the missing values. Python snippet 'df.isnull().sum()' will help to find the total number of missing values from the entire Dataset. Many times, yes, the null value will appear as the famous NaN in Python. In those cases, that value will not change the data type for the variable. The above code snippet will help in such a scenario.
Other times, for many reasons, the data can appear under a specific textual notation determined by the person who created the Dataset. One can use, for example, "No Value" as a proxy for the missing value. Or instead, it can be symbols like # or -, ! or anything else. In those cases, the type of the variable will be changed to string. Thus, if you're dealing with another data type, like numbers, it's easier to notice that there's a wrong value in that column. df[df.numbers.astype(str).str.isnumeric() == False ] This will identify such cases.
Let's create a toy dataset to understand this:
This will show the missing value for value columns only.
Output:
To see the output for the numbered (integer or float) column, let's run the below code:
Output:
What is Imputation?
Imputation refers to estimating and filling in missing values in a data set. Where there are errors in the data set, and when these are considered to add no value in the correction process, these values are set to missing and are imputed with a plausible estimate. Alternatively, missing values may already exist in the data, and imputation may be carried out to produce a complete data set for analysis.
We use imputation because Missing data can cause the following issues: –
-
Incompatible with most of the Python libraries used in Machine Learning:- While using the libraries for ML(the most common is skLearn), they don't have a provision to handle these missing data automatically, and can lead to errors.
-
Distortion in Dataset:- A considerable amount of missing data can cause distortions in the variable distribution, i.e., it can increase or decrease the value of a particular category in the Dataset.
-
Affects the Final Model:- The missing data can cause a bias in the Dataset and lead to a faulty analysis by the model.
Methods for Imputation
There are different popular methods people use for data imputation. In this section, we will cover some of them in detail.
Imputed by Mean
Mean imputation (or mean substitution) replaces missing values of a particular variable with the mean of non-missing cases of that variable.

Advantages:
- Mean imputation replaces all missing values; you can keep your whole database.
- Mean imputation is very simple to understand and apply.
- If the response mechanism is MCAR, the sample mean of your variable is not biased.
Disadvantages:
- Mean substitution leads to bias in multivariate estimates such as correlation or regression coefficients. Values that are imputed by a variable's mean have, in general, a correlation of zero with other variables. Relationships between variables are, therefore, biased toward zero.
- If the response mechanism is MAR or MNAR, your variable's sample mean is biased (compare that with point 3 above). Assume that you want to estimate the mean of a population's income, and people with high income are less likely to respond; Your estimate of the mean income would be biased downwards.
Imputed by Median
Median imputation (or median substitution) replaces missing values of a particular variable by the median of non-missing cases of that variable.
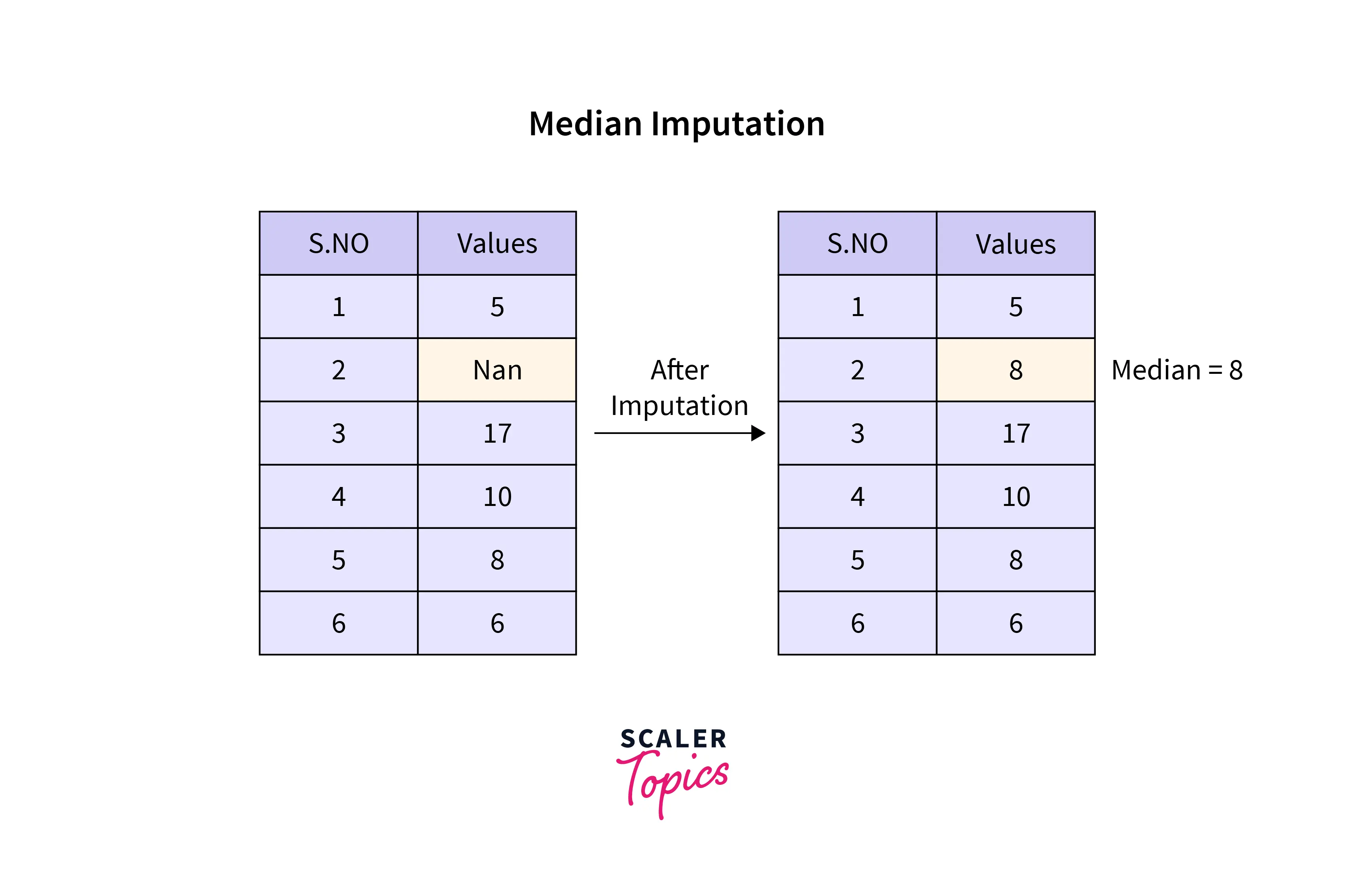
Like mean imputation, median imputation also performs better when data is missing completely at random. It is also easy to implement and is a fast way of obtaining complete datasets.
Turn Learning into Career Growth
KNN Imputation
KNN Imputation utilizes the k-Nearest Neighbors method to replace the Dataset's missing values with the mean value from the parameter 'n_neighbors' nearest neighbors found in the training set. By default, it uses a Euclidean distance metric to impute the missing values. Another critical point here is that the KNN Impute is a distance-based imputation method that requires us to normalize our data. Otherwise, the different scales of our data will lead the KNN Imputer to generate biased replacements for the missing values.
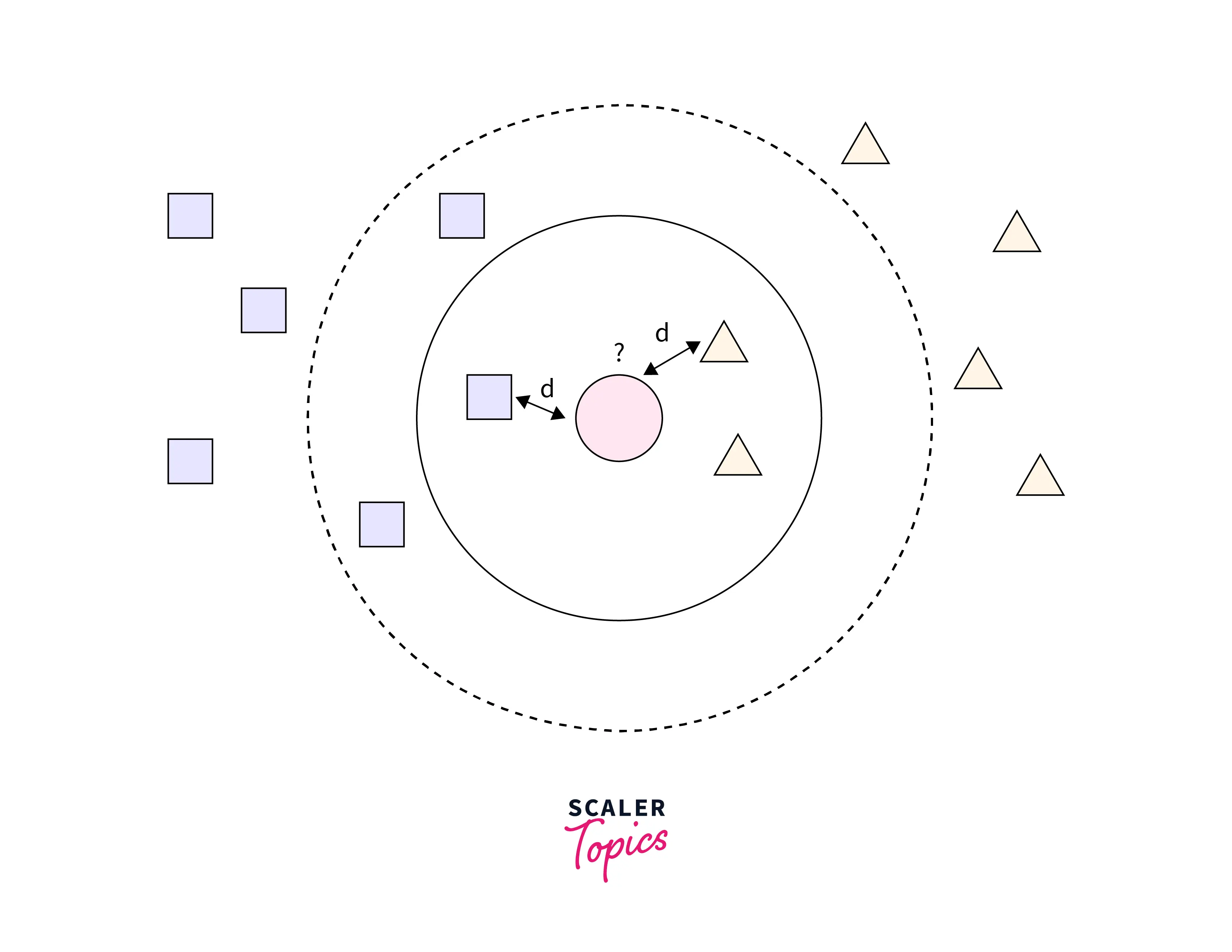
Advantages:
- KNN Imputer maintains the variability of your datasets, yet it is more precise and efficient than the average values.
Disadvantages:
- It is slow for each missing value and calculates the distance with its K neighbor. Hence, it is recommended to refrain from using KNN imputation methods for a dataset with higher percentages of missing values and high dimensional data.
- It requires data scaling.
- It is sensitive to noise and outliers.
Statistical Imputation With SimpleImputer
A scikit-learn class that we can use to handle the missing values in the data from the Dataset of a predictive model is called SimpleImputer class. With the help of this class, we can replace missing value values in the Dataset with a specified placeholder. We can implement this module class by using the SimpleImputer() method in the program.
SimpleImputer Data Transform
To implement the SimpleImputer() class method into a Python program, we have to use the following syntax: SimpleImputer(missingValues, strategy)
Parameters : SimpleImputer() method takes three arguments:
MissingValues : In SimpleImputer() method, Missing values are represented using NaN and hence specified. If it is an empty field, missing values will be specified as ".
Strategy : It specifies the method by which the missing value is replaced. The default value for this parameter is 'Mean'. You can specify 'Mean,' 'Mode,' Median' (Central tendency measuring methods), and 'Constant' values as input for the strategy parameter of SimpleImputer() method.
FillValue : If the strategy parameter of SimpleImputer() method is constant, the constant value is specified using the fillvalue parameter in such a scenario.
SimpleImputer class is the module class of Sklearn library. Before using this class, one must install the Sklearn library in the system if it is not installed.
Python code is given below for SimpleImputer data transformation using a toy dataset:
Output:
Explaination:
As we can see in the output, the imputed value dataset has mean values in place of missing values, and that's how we can use the SimpleImputer module class to handle NaN values from a dataset.
SimpleImputer and Model Evaluation
Evaluating machine learning models on a dataset using k-fold cross-validation is recommended. To correctly apply statistical missing data imputation and avoid data leakage, it is required that the statistics calculated for each column are computed on the training dataset only, then applied to the train and test sets for each fold in the Dataset. This can be achieved by creating a modeling pipeline where the first step is the statistical imputation, then the second is the model. This can be achieved using the Pipeline class.
Python code for the same is shown below:
Output:
Comparing Different Imputed Statistics
Different imputation strategy is compared in the code below.
Output:
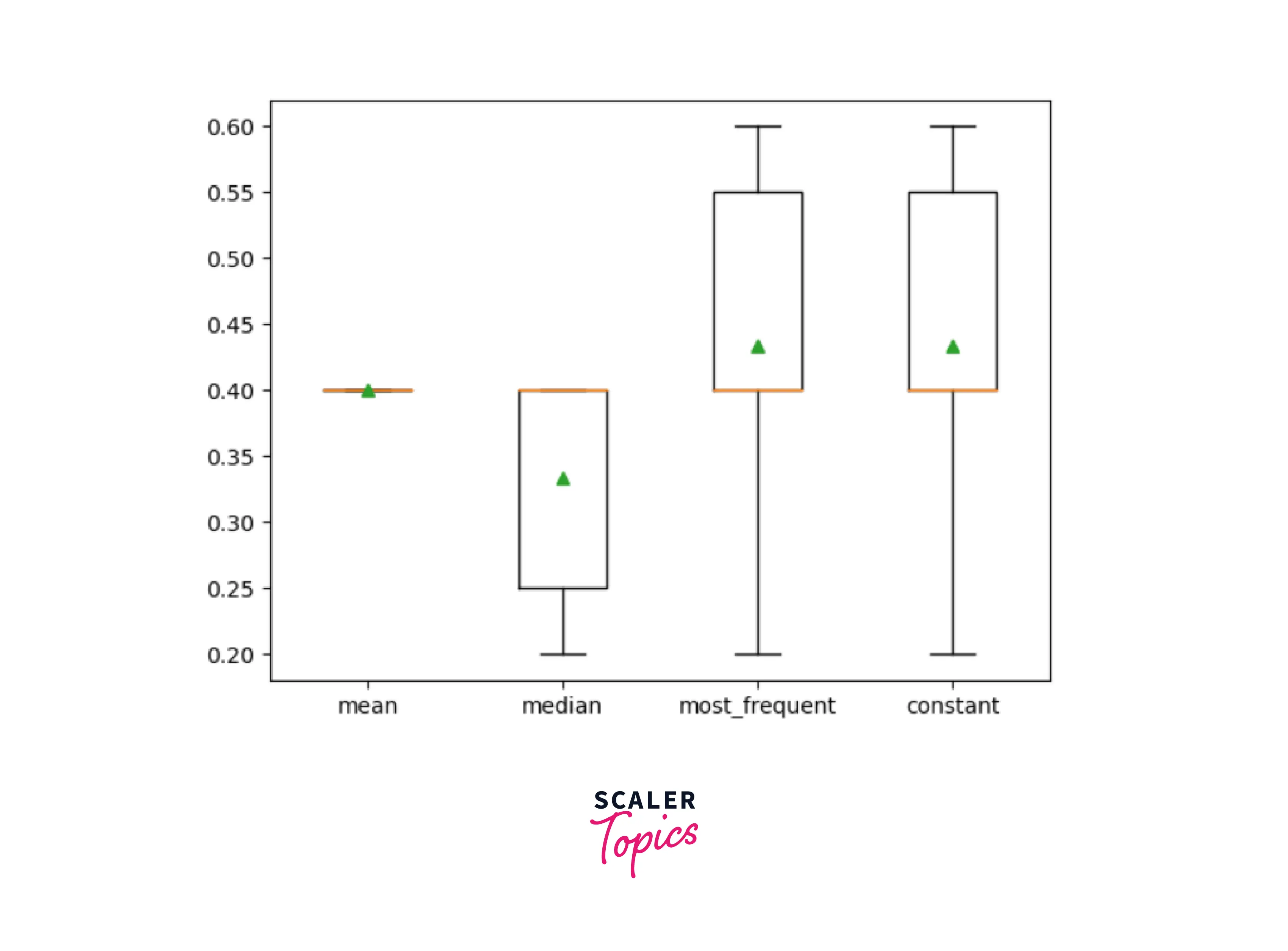 Clearly, imputing with constant value and most frequent value returns the best result in this scenario.
Clearly, imputing with constant value and most frequent value returns the best result in this scenario.
SimpleImputer Transform When Making a Prediction
Suppose we are interested in creating a final modeling pipeline with the constant imputation strategy and random forest algorithm and then predicting the class label against new data. It can be achieved by defining the pipeline and fitting it on all available data, then calling the predict() function and passing new data in as an argument.
Python code for the same is shown below
Output:
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Conclusion
- Missing value in machine learning may occur due to several reasons. Handling missing matters in machine learning is crucial for machine learning, and it is an essential step before feeding the data into the model.
- You have learned about different types of missingness in the data.
- Different imputation techniques like Mean, median, KNN, and statistical imputation techniques are covered here.
- Python code for statistical imputation is also presented for a better understanding of the readers.