Random Forest Algorithm in Machine Learning
Overview
The random forest algorithm is a popularly used machine learning algorithm. It is a supervised machine-learning algorithm. It can be used for both Regression and Classification problems in ML.
Introduction
The random forest algorithm in machine learning is a supervised learning algorithm.
The foundation of the random forest algorithm is the idea of ensemble learning, which is mixing several classifiers to solve a challenging issue and enhance the model's performance.
Random forest algorithm consists of multiple decision tree classifiers. First, each decision tree is trained individually. Then, the predictions from these trees are taken, and the random forest predicts the average of these results.
What Is Random Forest Algorithm?
Humans tend to take multiple opinions from others while making their decisions.
They go with the majority's choice or average out the suggestions. Well, the random forest algorithm does precisely that. Let's take a real-life analogy to understand this.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
A Real-Life Analogy
Suppose you decide to buy an outfit for yourself and have various options. So you ask multiple people, like your parents, friends, and siblings, about it.
Everyone considers various aspects of the outfits, such as the color, the fit, the price, and so on, while considering which one you should buy. At last, you decide to go for the outfit that the maximum number of people suggest. This is similar to the working of the random forest algorithm.
Assumptions for Random Forest
Some decision trees may predict the proper output, while others may not, since the random forest algorithm mixes numerous trees to forecast the class of the dataset. But when all the trees are combined, they predict the correct result.
Consequently, the following two presumptions for an improved random forest model:
- There should be some actual values for the dataset's feature variable to predict actual outcomes rather than a speculated result.
- Each tree's predictions must have extremely low correlations.
Features of Random Forest
The random forest in machine learning has the following key characteristics.
- Diversity - Since each tree is unique, not all characteristics, variables, or features are considered when creating a particular tree.
- Immune to the dimensionality curse - Because no tree considers every feature, the feature space is condensed.
- Parallelization - Each tree is generated using various data and properties. This implies that we can create a random forest in machine learning by using the CPU to its fullest extent.
- Train test split - There is no need to separate the data into train and test sets in a random forest since the decision tree will never be able to view 30% of the data.
- Stability - Stability results from the outcome being determined by a majority vote or averaging.
Working of Random Forest Algorithm
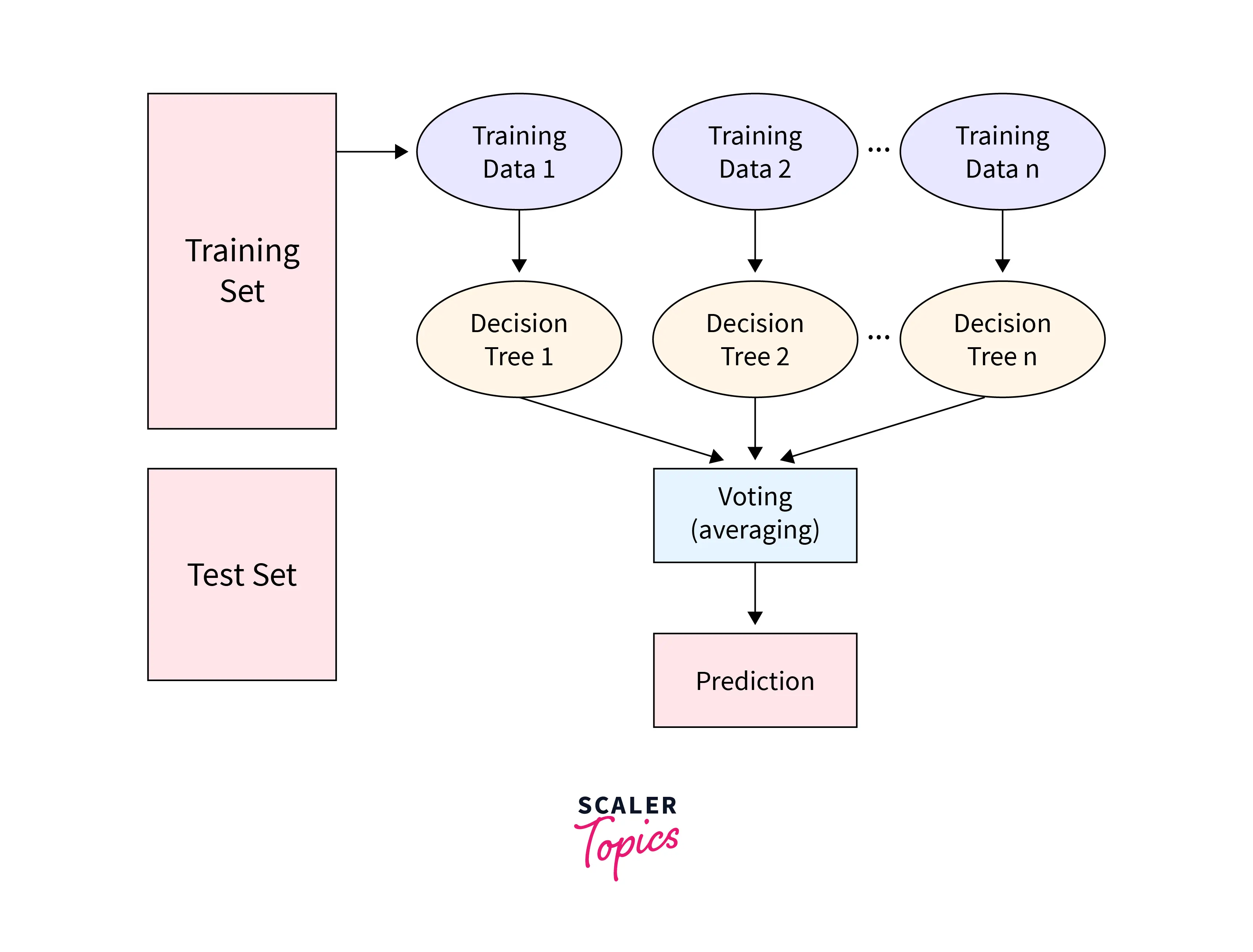
The Random Forest Algorithm's operation is described in the phases that follow:
- Choose random samples from a specified data collection or training set.
- For each training set of data, this algorithm will build a decision tree.
- Voting will be conducted using an average of the decision tree.
- Finally, choose the prediction result that received the most votes as the final prediction result.
Turn Learning into Career Growth
Important Hyperparameters
In the random forest algorithm in machine learning, hyperparameters are used to either speed up the model or improve its performance and predictive ability.
The following hyperparameters increase the prediction power:
- n_estimators - the quantity of trees the algorithm creates before averaging the predictions.
- max_features - top features a random forest algorithm splits a node into.
- mini_sample_leaf - calculates the bare minimum of leaves necessary to split an internal node.
The following hyperparameters quicken the process:
- n_jobs - It specifies how many processors the engine is permitted to use. If the value is 1, only one processor may be used. However, if the value is -1, there is no restriction.
- random_state - regulates the sample's unpredictability. If the model has a fixed value for the random state, the same hyperparameters, and the same training data, it will always yield the same results.
- oob_score - Out of the bag, or OOB. It uses the cross-validation approach of the random forest. In this case, only one-third of the sample is utilized to evaluate the performance of the data rather than train it.
Implementation of Random Forests with Python
Let's implement Random forest in Python. We will use the dataset "Social_Network_Ads.csv" which can be found here.
Here's what the data looks like:
| Index | User ID | Gender | Age | EstimatedSalary | Purchased |
|---|---|---|---|---|---|
| 0 | 15624510 | Male | 19 | 19000 | 0 |
| 1 | 15810944 | Male | 35 | 20000 | 0 |
| 2 | 15668575 | Female | 26 | 43000 | 0 |
| 3 | 15603246 | Female | 27 | 57000 | 0 |
| 4 | 15804002 | Male | 19 | 76000 | 0 |
There are four steps involved in this process:
- Importing and processing the data
- Training the random forest classifier
- Testing the prediction accuracy
- Visualizing the results of the classifier
Step 1 - Importing and processing the data
In this step, we will import the necessary libraries and the data. We will split the data into training and testing sets and perform feature scaling on the same.
Step 2 - Training the random forest classifier
Now we will fit the training set to the Random forest in Python. To fit it, we will import the RandomForestClassifier class from sklearn.ensemble library. In the code below, these are the parameters used:
- n_estimators - the minimum quantity of trees needed for the Random Forest. 10 is the default value. We can select any number, but we must address the overfitting problem.
- criterion - Its purpose is to examine the split's correctness. Entropy has been used in this instance for knowledge acquisition.
Step 3 - Testing the prediction accuracy
We will use a confusion matrix to determine how well our classifier performed.
Output:
As we can see from the above matrix, we have incorrect and correct predictions.
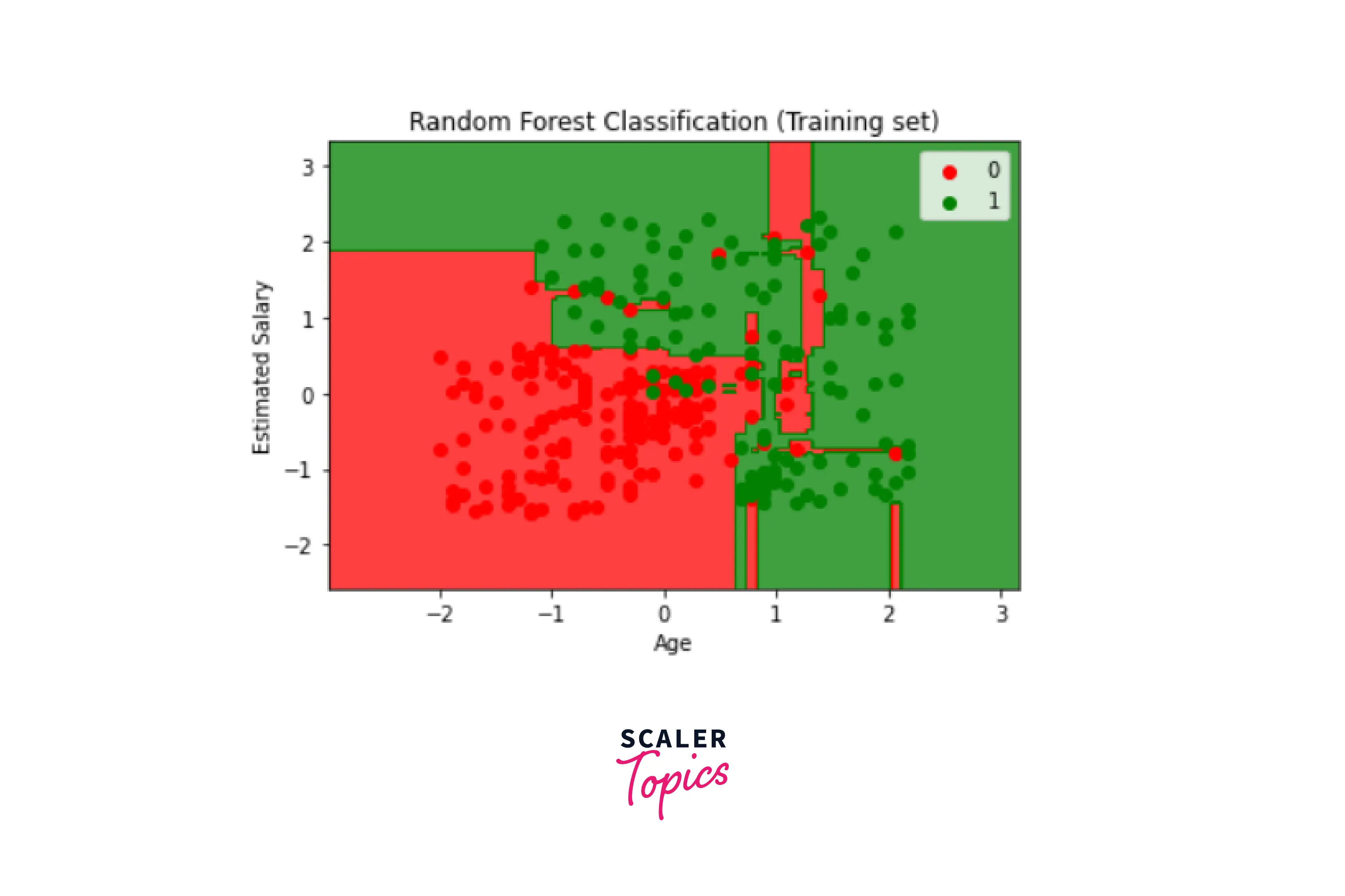
Step 4 - Visualizing the results of the classifier
We'll display the training set result here. Then, we will plot a graph for the Random forest in Python to visualize the results from the training set.
Output:
We will now display the test set results visually.
Output:
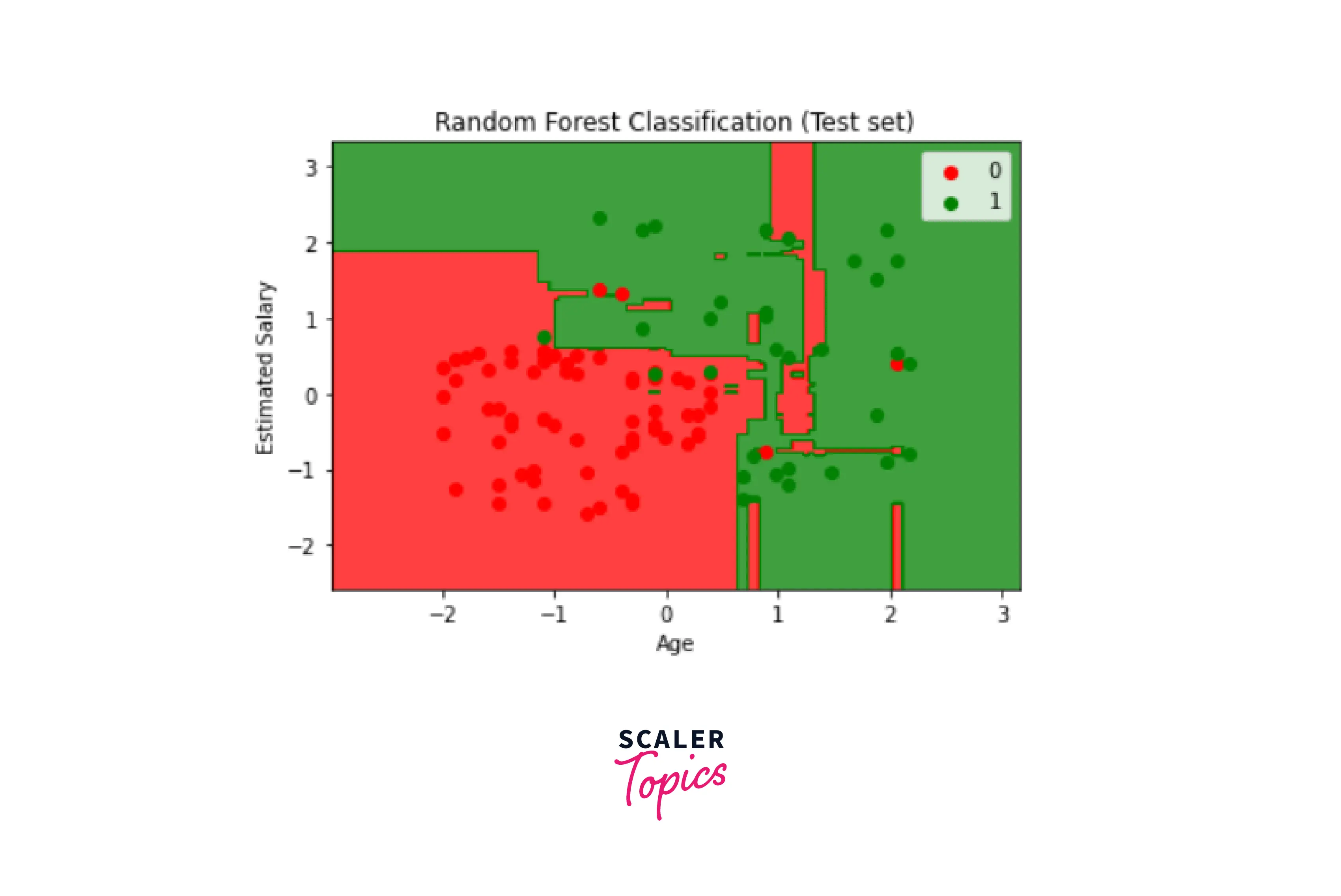
We can obtain varied outcomes by altering the classifier's number of trees.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Applications of Random Forest
The industries that employ Random Forest the most are as follows:
- Banking: This algorithm is mainly used in the banking sector to identify loan risk.
- Medicine: This method may be used to identify illness patterns and risk factors.
- Land Use: We can locate places with comparable land uses using this technique.
- Marketing: This algorithm may be used to find marketing trends.
- Financial analysts: utilize the stock market to locate prospective markets for stocks. They may also recall stock behavior thanks to it.
- E-commerce: Using this approach, e-commerce sellers may forecast client preferences based on previous consumption patterns.
Advantages and Disadvantages of Random Forest
Advantages of Random Forest
- Random Forest may handle both classification and regression tasks.
- It can handle big datasets with lots of dimensions.
- It improves the model's accuracy and avoids the overfitting problem.
Disadvantages of Random Forest
- The Random Forest Algorithm requires more resources to compute with.
- Takes longer than the decision tree algorithm to complete.
- Less logical when we have a large number of decision trees.
- Quite complicated and calls for increased computing power.
Difference Between Decision Tree & Random Forest
| Decision Trees | Random Forest |
|---|---|
| If they are left to develop unchecked, they frequently experience the issue of overfitting. | The issue of overfitting doesn't arise here because they are built from subsets of data, and the outcome is based on average or majority ratings. |
| Comparatively speaking, a single decision tree is faster to compute. | It is slower. |
| When a feature-rich data collection is used as input, they apply certain criteria. | Random Forest builds a decision tree from observations that are chosen at random, and then the outcome is determined by majority voting. Here, formulas are not necessary. |
Elevate your machine learning proficiency with our Maths for Machine Learning Free Course. Get started today!
Conclusion
- We have covered the answer to what random forest is in machine learning and its step-by-step work.
- It is better to use the random forest algorithm when we have large datasets with high dimensionality but best to keep a smaller number of trees in this case.
- Random forest deals with the overfitting problem that the decision trees could not handle.