Random Search in Machine Learning
Overview
Optimizing hyperparameters is the most challenging aspect of developing machine learning and artificial intelligence models. Predicting the ideal parameters while developing a model is difficult, at least in the first few attempts. So, how does one determine the best hyperparameter values? One technique is to use random search in machine learning.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Pre-requisites
- A basic understanding of what hyperparameters are in machine learning is required.
- Knowing about hyperparameter search is beneficial.
- To code along, an understanding of Google Colab is sufficient.
Introduction
In machine learning, random search is a strategy that uses random combinations of hyperparameters to identify the optimal answer for the established model. Because the parameters are chosen randomly, and no intelligence is utilized to sample these combinations, chance plays a role.
Hyperparameter search is one of the best techniques to find the most suitable values for your hyperparameters. There are various methods by which you can implement hyperparameter search. One of them is Random search in machine learning.
What is Random Search?
The random search in machine learning involves generating and evaluating random inputs to the objective function. It is effective because it does not assume anything about the structure of the objective function. This can benefit problems with a lot of domain expertise that may influence or bias the optimization strategy, allowing non-intuitive solutions to be discovered. The drawback of random search is that it yields high variance during computing.
The graphic below depicts the random search pattern.
Turn Learning into Career Growth
The Algorithm
So, how does random search work? The search begins by initializing random hyperparameter values from the search space. Let's call this point x. Next, it calculates the value of the cost function at x. Then it takes another set of random hyperparameter values, let's call it y, and calculates the value of the cost function at y. If the value of the cost function at y is lower than that at x, then it repeats these steps by assigning x = y as the new start. Else it continues from x. This process is repeated until a requirement set by the user still needs to be fulfilled.
The following steps describe the algorithm of random search in machine learning.
- Set x to a random place in the search space.
- Repeat until a termination requirement, such as multiple iterations completed or appropriate fitness achieved, is met:
- Take a new position y from the hypersphere with a given radius around the current position x.
- If f(y) < f(x), then assign x = y as the new position.
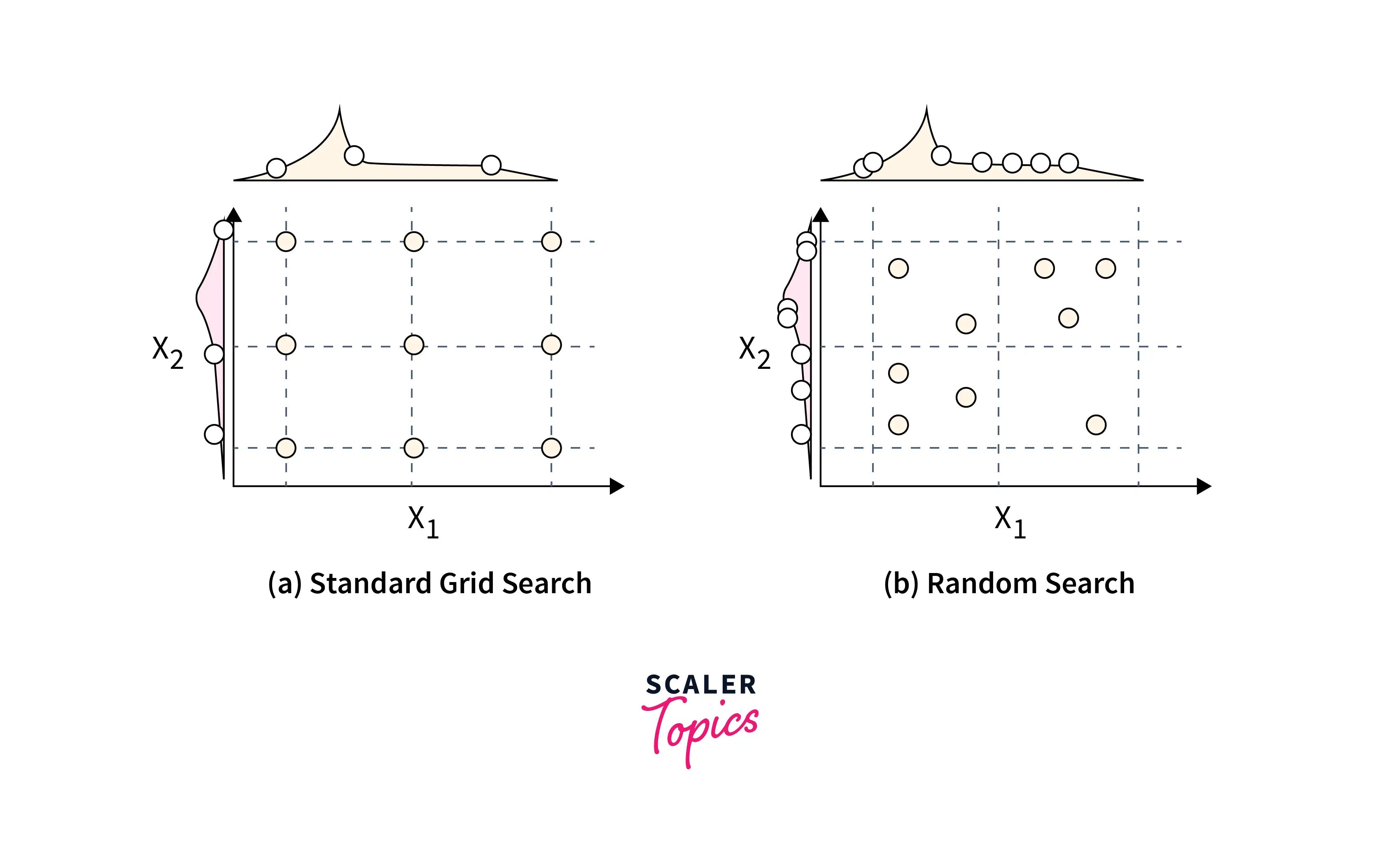
Advantages of Random Search Over Grid Search
These are the few advantages of random search in machine learning over grid search.
- Random search gives better results than grid search when the dimensionality and the number of hyperparameters are high.
- Random search in machine learning allows us to limit the number of hyperparameter combinations. Whereas in grid search, all the varieties of hyperparameters are checked.
- The random search usually gives better results than the grid search in fewer iterations.
Code example
For this code demonstration, we will use the Heart Disease dataset, which can be found here.
- Building a base model We will build a default decision tree classifier, use this as our base model, and compare this to the results obtained after hyperparameter tuning.
Output:
As the output indicates, our basic model could be more effective. It learns well from the training data. However, it fails to generalize to the test set.
- Python Implementation of Random Search
The RandomizedSearchCV function from Scikit-learn may be used to construct Random Search in Python.
These are the parameters for random search in machine learning:
- param_distributions - Defines the search space.
- n_iter - The number of random hyperparameter combinations to be chosen.
- scoring - The method of scoring used to assess the model's performance.
- random_state - Controls the randomization of the sample of hyperparameter combinations obtained at each execution.
- n_jobs - This specifies the number of parallel jobs that will be run when the search is executed.
- cv - The number of cross-validation folds.
The total number of iterations, in this case, is 100. Therefore, (10 x 10). n_iter=10 indicates that it will task a random sample of size 10 with ten distinct hyperparameter combinations. As a result, the random search needs only to train ten different models.
Output:
- Python Implementation of Grid Search
The GridSearchCV function from Scikit-learn may be used to construct Grid Search in Python. The parameters are similar to that of random search in machine learning with the difference that param_distributions is referred to as param_grid here.
Our search space is three-dimensional, with 576 (9 x 8 x 8) possible possibilities. This indicates that we used Grid Search to train 576 distinct models, much higher than the ten models trained in a random search.
Output:
- Comparison
In this situation, both grid search and random search have similar results. Keep in mind the strength of random search in machine learning, though. It is 44 times (22.5/0.51) quicker in this situation. So if the random search takes one minute to complete, the grid search will take around 44 minutes! As a result, when the search space is high-dimensional and contains many distinct hyperparameter combinations, it is advised to utilize random search.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
Conclusion
- Random search in machine learning is a hyperparameter search technique commonly used when the search space has high dimensionality.
- Random search performs better than grid search but does not always guarantee to find the best hyperparameters.
- Random search in machine learning replaces the concept of an exhaustive search by selecting the values randomly.