Standard Practices for Model Evaluation
Overview
Machine Learning is the most intuitive and booming field of information technology in the present day. They help computers to understand and interpret data as a human would. They teach computers to learn from past experiences and deal with future scenarios. But, the machine learning model is only as good as its quality. The higher the evaluation metrics such as accuracy, the better the ML model. This article revolves around the standard practices of model evaluation.
Introduction
For any task in machine learning, such as classification, regression, etc., there are many algorithms to choose from. Linear Regression, Logistic Regression, Decision Tree, Naive Bayes, K-Means, and Random Forest are some common ML algorithms/models we use. But we don't pick any one ML model and predict our data. Sometimes, we use more than one algorithm, and then we continue with the one that makes better predictions on data. Model evaluation techniques tell us how accurate our model is and help us to judge the accuracy of the model. By using different performance evaluation methods, we could improve the overall predictive power of our model.
Transform Your Career
Choose from our industry-leading programs designed for career success
Modern Software and AI Engineering Program
Master full-stack development with AI integration

Modern Data Science and ML with specialisation in AI
Advanced data science techniques with AI specialization
Advanced AIML with Specialisation in Agentic AI
Deep dive into AIML with focus on Agentic systems
DevOps, Cloud & AI Platform Engineering
Build and manage AI-powered cloud infrastructure
AI Engineering Advanced Certification by IIT-Roorkee
Premier AI engineering certification from IIT-Roorkee
Hold Out Sets
What is a Hold Out Set?
Hold out is when you split up your dataset into a train and a test set. The training set is what your model is trained upon, and the test set is used to judge how your model trains on unseen data. Usually, the split used in the hold-out method is 80% for the training data and 20% for the testing data.
Why Having Both Validation and Test Sets is Important?
Validation set, like any other set is a part of the dataset. Like the test set, it is also used for model evaluation but not the final one. A machine learning model may have a lot of hyperparameters `that need to be fine-tuned to achieve the best performance.
The training set is the largest part of the dataset on which the model is trained. The parameters of the ML model are learned by fitting the model to the training dataset.
However, training a model is not a one-time process. We have to train multiple models by trying different combinations of hyperparameters. Following this, the evaluation of the performance of each model is done on the validation set. Hence, the validation test is useful for hyperparameter tuning or selecting the best model out of different models.
After we get our best possible model, we test the model on unseen data, i.e., the test.
How to Split Data Before Training?
We use sklearn's train_test_split for this purpose. Let's say we have "X" as the independent variable and "Y" as the dependent variable with "n" number of instances. The training and test set is obtained by:-
The test_size parameter above decides the split percentage. Here the split percentage is 20%.
We can use the same function above for the validation set.
The random state hyperparameter in the train_test_split() function controls the shuffling process.
Turn Learning into Career Growth
Cross Validation
When to Use Cross Validation?
Cross-validation is used to test the ability of a machine-learning model to predict new data. It also detects problems like overfitting or selection bias. Cross-validation is a technique for validating the model efficiency by training it on the subset of input data and testing on a previously unseen subset of the input data.
The three steps involved in cross-validation are as follows :
- Reserve some portion of the sample data set.
- Using the remaining dataset to train the model.
- Test the model using the reserved portion of the dataset.
Leave One Out Cross Validation(LOOCV)
In this cross-validation technique, if n data points are in the dataset, n-1 will be used for training and 1 for testing or validation. This process repeats for each data point. Hence for n samples, we get n different training sets and n test sets.
Advantages The bias is minimum as all the data points are used.
Disadvantages
- This method leads to higher variation in the testing model as we are testing against one data point, especially if the data point is an outlier.
- It takes a lot of execution time as it iterates over n number of times.
Scaler Placement Report and Statistics
Scaler learners achieved 2.5x salary growth with average post-Scaler CTC reaching ₹23L.
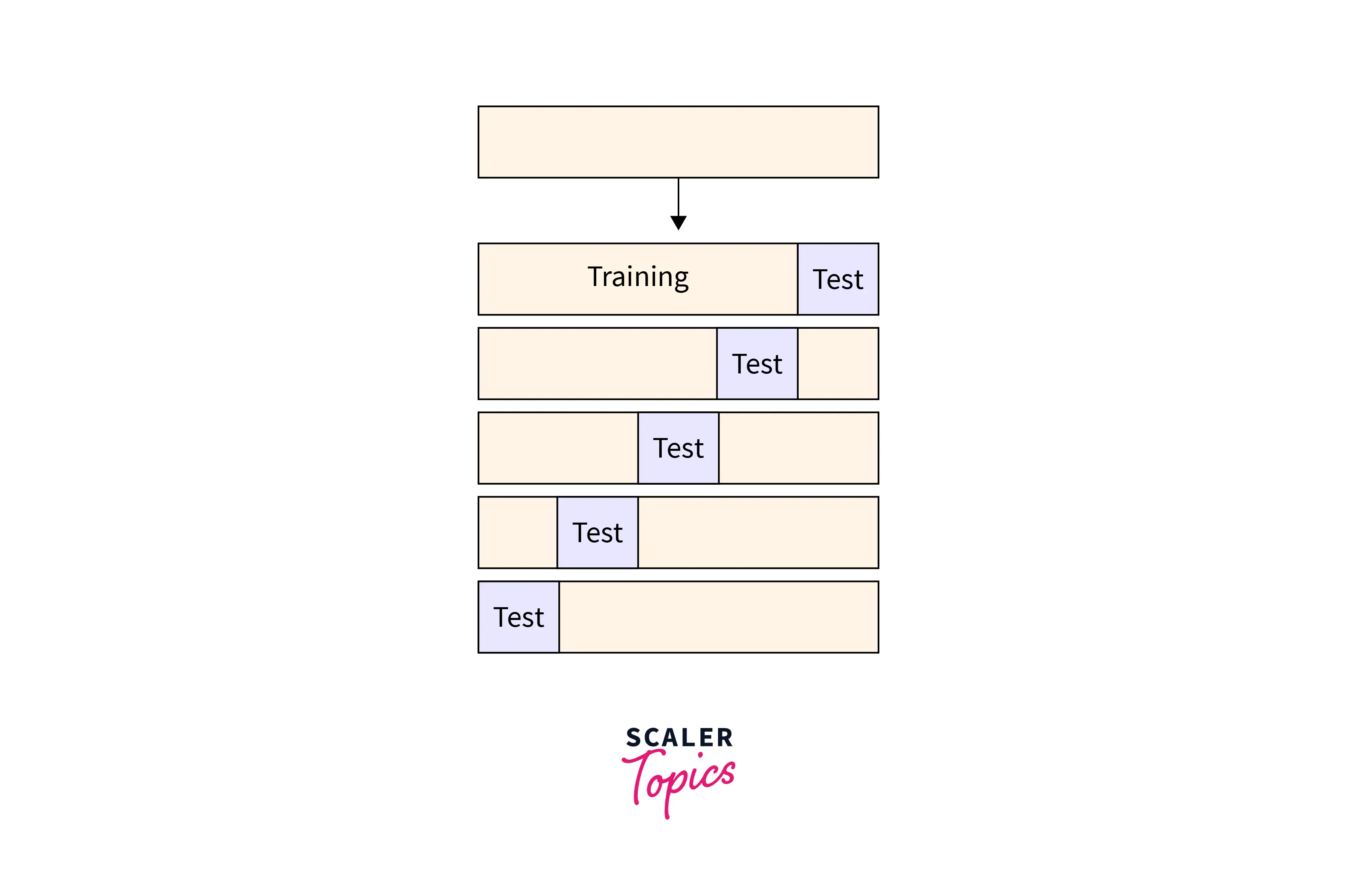
K-fold Cross-Validation
This method is an upgradation over the above one. In this method, we split the dataset into k number of subsets called folds and then we perform training on all the subsets but leave the one(k-1) subset to evaluate the trained model.
The higher the value of K, the closer we go toward the OOCV method.
Implementation
This method overcomes the disadvantages of the LOOCV method.
Conclusion
The key takeaways from this article are:-
- Model evaluation methods help us to build the best possible ML model out of the available models.
- Validation sets are important as they help fine-tuning the parameters.
- K- fold cross-validation is one of the most useful cross-validation techniques that give us the best value for the evaluation metrics.