Dealing with Text Data in Machine Learning
Overview
Machine learning continues to advance rapidly in computer science, driven by the increasing amounts of data being generated everyday. Machine learning offers a powerful solution to make sense of this data and uncover valuable insights. But text data can pose unique challenges in machine learning. This article explores the complexities of working with text data in machine learning and how to overcome them.
Pre-requisites
To get the best out of this article, the reader:
- Must be familiar with basics of NLP (Natural Language Processing).
- Must be familiar with basic linear algebra concepts.
Introduction
As we discussed earlier in this article, there is much data to deal with. Social media applications, cybercrime cells have reported around 1TB of data generated everyday in 2022. Yes, everyday! Since most of this data is in text format, we cannot apply the general methods of generating insights as we do for numeric data. Getting information from text data requires some mathematical computation to convert words and sentences into arrays and matrices.
How do we do that? Let's unravel that mystery right away!
Basic Text Pre-processing of Text Data
The dataset generated by social media applications is not in a condition to be used directly. If we use them as they come, the accuracy of our models would be disheartening. Hence, basic preprocessing of text is required.
Lucky for us, we don't need to be experts in the field of Natural Language Processing (NLP) to be preprocessing data. For implementation purposes, we'll be using the Twitter Sentiment Analysis dataset.
Lowercasing
The first step in preprocessing our data would be to convert tweets to lowercase. This helps us by creating uniformity in our dataset.
Output
Punctuation Removal
We will remove all of the punctuations in the "tweet" column by using the replace() function.
Output
Stopwords Removal
Stopwords are common words in a language that are often excluded from text analysis as they do not add significant meaning to a sentence. Examples of stopwords include "the," "a," "an," "at," and so on.
Output
Frequent Words Removal
Removal of common words is necessary, as they usually don't provide any insight to us.
Output
Rare Words Removal
Just as we removed the most common words, we'll remove the rare words too.
Output
Spelling Correction
All of us have seen tweets with numerous spelling errors. In addition, our timelines are often cluttered with hurriedly sent tweets that are sometimes scarcely readable. In this sense, spelling checks are a helpful pre-processing step because they enable us to cut down on word duplication.
Output
Tokenization
Tokenization is the process of breaking up a text passage into a series of words or sentences. In our example, we first turned our tweets into a blob using the textblob library before turning them into a string of words.
Output
Stemming
As the name suggests, stemming is the removal of suffices from a word. Suffices may include “ing”, “ly”, “s”, etc. We would use PorterStemmer in this scenario.
Output
Lemmatization
Lemmatization converts a word into its root. In practice, lemmatization is preferred over stemming because lemmatization turns the term into its root word rather than only removing suffices. Hence, it is a more efficient method than stemming. It uses the lexicon and does a morphological analysis to find the root word.
Output
Representation of Text Data
Now that we have understood basic preprocessing, we'll use some concepts of NLP to extract features from our dataset.
N-Grams
N-grams are formed when several words are combined and used. Unigrams are Ngrams with N=1. Similar structures include bigrams (N=2), trigrams (N=3), and so forth.
The fundamental idea behind n-grams is that they represent the language structure, such as what letter or word will most likely come after the supplied one. The more background you have to work with, the longer the n-gram (the larger the n).
Output
Term Frequency
The ratio of a word's frequency to the length of the sentence is known as term frequency. To simplify,
Output

Inverse Document Frequency
Inverse document frequency (IDF) is based on the idea that a word is not very useful if it appears in all of the documents.
As a result, the log of the ratio of the total number of rows to the number of rows in which each word appears is the IDF for each word.
;
where X-Total number of rows, N-Number of rows where the word was present.
Output
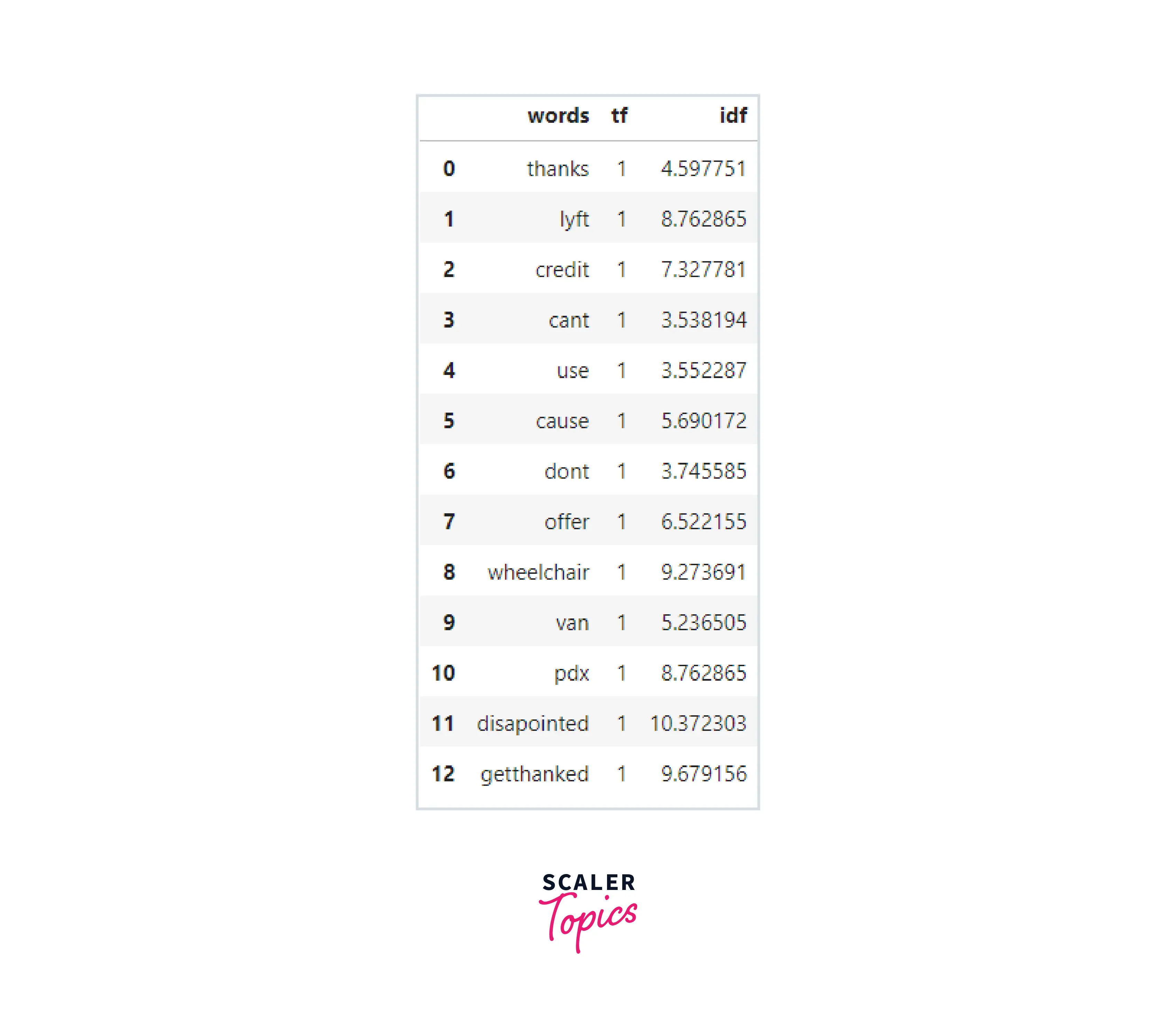
Term Frequency-Inverse Document Frequency (TF-IDF)
The product of the TF and IDF that we calculated earlier is called TF-IDF. We can see that because "don't," "can't," and "use" are frequently used words, the TF-IDF has penalized them. However, "disappointed" has received a lot of weight because it will be crucial in figuring out the tweet's emotion.
Output
Bag of Words
Bag of Words (BoW) is a term used to describe a text representation that indicates the presence of words in text data. The reasoning behind this is that two text fields that are comparable to one another will likely contain words of a similar nature and hence have a similar collection of words. Furthermore, we can infer something about the document's significance from the text alone.
Output
Conclusion
- In this article, we understood the basic-preprocessing methods of text in Machine Learning.
- Apart from this, we also covered the basic feature extraction techniques using NLP (Natural Language Processing).